基于深度学习的教师课堂提问分析方法研究
2021-09-14马玉慧夏雪莹张文慧
马玉慧 夏雪莹 张文慧
[摘 要] 课堂提问是教师课堂教学行为的关键组成部分,是师生进行课堂交互的主要方式。对教师课堂提问进行分析,是提升教师课堂教学水平的关键。视频分析法是目前进行课堂提问分析的主要方法。但该方法需要花费大量的时间和人力,导致无法进行大规模应用。近几年,随着人工智能技术的不断成熟,越来越多的领域开始利用人工智能替代人工操作。为使课堂提问分析能够高效、大规模地应用,本研究提出基于深度学习的课堂提问自动分析方法。研究采用卷积神经网络(CNN)及长短时记忆网络(LSTM),对80节课的9090条课堂教师提问文本进行分类。实验结果表明,CNN模型具有更好的分类效果,其在提问内容和提问类型两个维度上的整体准确率分别是85.17%和87.84%。应用该方法训练的模型,可替代传统的视频分析法,能够实现大规模的教师课堂提问话语的自动分析。
[关键词] 课堂提问; 自动分类; 深度神经网络; 深度学习
[中图分类号] G434 [文献标志码] A
[作者简介] 马玉慧(1974—),女,辽宁锦州人。副教授,博士,主要从事人工智能教育应用的研究。E-mail:799493385 @qq.com。
一、引 言
课堂提问是教师课堂教学行为的关键组成部分,是师生进行课堂交互的主要方式。有效的课堂教学提问不仅能够吸引学生的注意力,激发学习兴趣,而且能够引导学生深入思考,及时评价教学效果[1-2]。对教师的课堂提问进行质性研究,是区分新手教师与专家教师,促进教师专业发展的有效途径之一[3-5]。现有的教师课堂提问研究,多采用视频案例分析法,即对课堂教学进行录像,课后反复观看录像,并将教师教学行为转录为文字,再进行编码统计分析[6-8]。这种分析方法可以较好地对教师课堂提问进行深入的量化与剖析,确定教师课堂上的提问数量、提问方式、提问类型及提问所在教学环节等[9-11]。但该方法面临的主要问题是需要大量的人工操作,导致该方法无法大规模推广使用。
深度学习(Deep Learning)是当前人工智能技术发展的主流方向。近几年人工智能技术在众多领域的广泛推广与使用,大多归功于深度学习技术的发展。深度学习几乎成了人工智能的代名词。随着训练数据的不断增多,算力大幅提升,算法的创新与改进,深度学习训练得到的智能体越来越多地应用在不同领域,替代人类自动完成各项耗时、耗力的繁杂工作,将人们从大量的重复性工作中解放出来,将更多精力集中于创造性的工作中。
近几年,深度学习技术已开始应用于教育领域[12-14],教育研究者期望用机器自己学习得到的模型替代部分人类工作,减轻研究者和教师的工作负担,实现智能教育。在本研究中,针对现有基于视频分析法进行教师课堂提问研究的不足,本文提出了利用深度学习技术,对教师的课堂提问进行研究的方法,解决视频分析无法大规模使用的问题,同时为基于深度学习的教师课堂分析提供研究思路与方法的借鉴。
二、研究现状
(一)教师课堂提问的分类及分析方法研究
课堂提问是教师课堂教学中最普遍的教学行为之一,是教学过程中师生进行沟通和交流的主要方法。课堂提问是教学质量的重要保障,但若能在课堂上进行有效的提问绝非易事[15]。已有研究表明,新手教师在课堂提问方面,与专家型教师存在较大差异[5,16]。因此,对新手教师的课堂提问进行研究,发现新手教师与专家教师在提问环节的差异,对于新手教师提高教学质量,促进专业发展具有重要作用[17]。
在现有课堂提问的研究中,教师提问分类问题是众多研究者关注的重点之一。于国文等对不同国家中学数学教师的课堂提问进行了研究,将教师数学课堂提问分为三个维度:提问对象、提问内容和提问水平。进一步地,将提问对象分为个别学生、小组和全班同学;提問内容分为知识点类、题目信息类和管理类;提问水平分为低水平的回忆型、理解型和应用型,高水平的分析型、综合型和评价型[18]。顾泠沅将提问类型分为常规管理性问题、记忆性问题、推理性问题、创造性问题和批判性问题五类[19];涂荣豹将提问类型分为回忆性提问、理解性提问、分析综合性提问和评价性提问[20]。叶立军等根据教师提问的作用,回答所对应的认知水平,将提问分为管理型提问、识记型提问、重复型提问、提示型提问、补充型提问、理解型提问、评价型问题7种类型[4]。已有研究的提问分类维度为实现教师课堂提问的自动分析提供了很好的研究基础。
目前常用的课堂提问分析方法是视频分析法。张文宇等对我国首届全日制教育硕士学科教学(数学)专业教学技能决赛的33名参赛学生的视频进行视频分析,由此发现这些职前教师在课堂提问环节的不足[10]。叶立军等同样采用视频分析法,对两位从教二十年教师的课堂视频实录进行分析。除了对两位教师的课堂提问类型进行统计分析外,还对提问的总共用时、学生回答的次数、回答的总时长进行了统计分析[4]。于国文等采用基于NVivo对中国、澳大利亚、法国、芬兰的专家型教师的课堂教学视频中的课堂提问进行了比较分析,探究不同国家教师课堂提问的各自特点[18]。
通常,课堂教学的视频分析法的具体步骤如下:(1)将课堂实录视频转录为文字,生成原始素材;(2)将素材导入视频分析软件(如NVivo软件等);(3)构建课堂提问分类编码体系,并进行信度和效度验证;(4)基于提问分类编码体系,人工进行编码;(5)利用SPSS软件进行编码的统计分析。
视频分析法能够有效地对教师课堂提问进行分析,但也存在显著的不足,即整个分析过程需要投入大量的人力和时间,导致该方法无法大规模推广应用,无法对更多教师的课堂提问进行精准分析。为此,在人工智能时代,采用自动分析法替代视频分析法成为大规模促进教师专业发展的切实有效途径。
(二)基于深度学习的文本分类在教育中的应用
深度学习最早由加拿大多伦多大学教授希顿(Hinton)等提出。深度学习模型的结构模拟了人类大脑神经系统的结构原理,通过多层神经元之间的信息传递,实现不同特征的提取,最终形成数据的分层特征表示。理解深度学习,可以从“深度”和“学习”两个方面着手。“学习”是指深度学习完成任务所需的“知识或技能”并非来源于人们预先编写的程序规则,而是从大量数据中自动学习获得。也就是说,深度学习获取知识的途径来源于海量数据。“深度”是相对于机器学习的“浅层”而言的。机器学习中的逻辑回归、支持向量机、最大熵方法等模型,都是基于浅层结构来处理数据的。这些模型只有1层或2层非线性特征转换层,而深度学习是一个具有多层隐层节点的神经网络。多层隐层节点的结构不仅能更好地刻画大量数据中隐含的复杂特征,而且通过逐层初始化,降低了神经元数量和训练的难度。此外,相对于浅层学习而言,深度学习还有一个显著优势,通过多层隐层的模型结构,再加上海量的数据,能够自动学习隐藏在数据背后的更有用的特征,无须浅层机器学习所必需的特征工程,从而能够更精准地进行预测和分类[21-22]。
文本分类是深度学习在自然语言理解领域的一个主要应用场景之一。基于深度学习文本分类的一般流程大致为文本预处理、文本表示、基于深度学习模型的文本分类三个部分。不同领域的中文文本分类的应用和研究,其文本预处理的方法大体相同,基本包括中文分词、去停用词、规范化等。文本表示是将文字转换成计算机能够进行处理运算的数字或向量。深度学习中多采用词嵌入方法,如Word2Vec、Bert等方法将文本表示成多维的向量,用于后续的基于向量的分类。基于深度学习文本分类的不同应用研究,其主要的不同在于采用了不同的深度学习模型。目前,常见的深度学习文本分类模型有卷积神经网络CNN[23]、长短时记忆网络LSTM[24-25]、雙向长短时记忆网络Bi-LSTM[26]、基于注意力机制的双向长短时记忆网络BiLSTM-Attention[27]等。
目前,基于深度学习的文本分类技术已开始应用于教育领域,并取得了一定的研究成果。例如冯翔等为自动识别在线学习过程中学生的学业情绪,构建了基于LSTM模型的学业情绪预测系统。该系统通过爬虫程序获取10万余条在线学习中学生的反馈文本数据,利用LSTM模型实现学习者的学业情感的识别与分类,模型预测的准确率达到89%[14]。甄园宜等人收集了16047条学生在线协作学习过程中的交互文本数据,基于CNN、LSTM、Bi-LSTM模型,将学生在线协作学习过程中的交互文本进行分类,再根据交互文本所属类别有针对性地进行在线协作学习的实时监测和干预[12]。研究的实验结果表明,相对于CNN、LSTM模型而言,Bi-LSTM具有更高的准确率,为77.42%。罗枭应用Bi-LSTM结合CNN实现了试卷主观题的自动评分。采用的方法是将之前主观题的连续评分(如满分6分)改为分成3个分数段,相当于将主观题分为3类(0~1分为第1类,2~4分为第2类,5~6分为第3类),这样就将主观题的评分转换成文本分类问题,在SST-2数据集上其准确率为89.7%[28]。
综上所述,基于深度学习的文本分类能够帮助人类减少大量重复、繁杂工作,是实现教育智能化的有力抓手之一。目前该基于深度学习的文本分类在教育领域中的应用尚处于起步阶段。不同的应用情境,分类的准确率会受到数据集质量、深度学习模型的选定,以及分类歧义程度等诸多因素的影响。如何挖掘教育领域中的文本分类的教育问题,选择适当的深度学习模型,是目前我们进行深度学习文本分类教育应用的关键所在。
三、基于深度学习的教师课堂提问分类方法
教师课堂教学提问分析本质上是文本分类问题。采用基于深度学习的文本分类方法对教师的课堂教学提问进行分析,能够很好地解决传统视频分析方法无法大规模应用的问题。基于深度学习对教师的课堂提问进行分类,首先要构建分类体系,再利用深度学习的分类方法进行分类。下面以初中数学课堂为例,阐述基于深度学习的教师课堂提问分类方法。
(一)数学课堂提问的分类
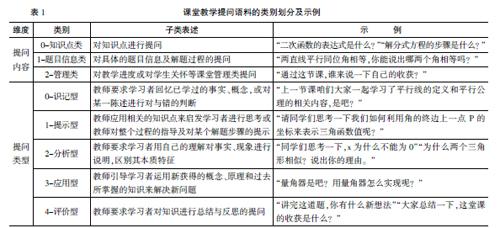
本文主要在于国文等关于数学课堂提问分类研究的基础上[18],将数学课堂提问分为提问内容和提问类型两大类。提问内容主要是“提问什么”,提问类型则依据布鲁姆的教学目标分类,从提问认知层级的视角进行了进一步划分。具体地,将提问按提问内容分为知识点类提问、题目信息类提问和管理类提问;将提问类型分为识记型提问、提示型提问、分析型提问、应用型提问、评价性提问。具体的类别划分及示例见表1。
(二)基于深度学习的课堂提问分类的流程
基于深度学习的课堂提问分类主要包括数据收集、语料标注、数据预处理、数据表示、模型的选择与训练、预测六个步骤。
1. 数据收集与整理
数据收集是进行深度学习模型训练的第一步,也是很关键的一步。数据集的数量、各类别数据量的均衡程度,都会对分类效果产生影响。教师课堂提问的数据多来源于课堂实录,因此要先利用语音转换软件,将视频中的语音转换成文本。
2. 语料标注
将收集的数据以句子为单位进行标注。在本研究中将提问按其对应的提问内容分别标注为0、1、2三类,按提问类型标注为0、1、2、3、4五类。例如,将“解分式方程的步骤是什么?”按提问内容标注为0,按提问类型标注为0;“为什么两个三角形相似?说出你的理由”按提问内容标注为1,按提问类型标注为2。
3. 数据预处理
数据预处理的目的是将收集的数据集转换成符合深度学习模型训练要求的数据。本研究中的预处理包括去除过长或过短语句、打乱语料顺序,以及数据采样。去除过长或过短语句,用于减少课堂语料数据集的噪声。打乱语料顺序即乱序学习,是在送入程序之前打乱语料的顺序,使得深度学习效果更好。为避免各类别中训练样本的数据不均衡,本研究采用合成少数类过采样与下采样相结合的混合采样方式,以降低因各类数据不均衡而导致的分类误差。
4. 数据表示
数据表示一般有词向量与字向量表示。词向量是以词为单位的向量表示,字向量是以字为单位的向量表示。在不同应用场景中,基于词向量与字向量的深度学习会有不同的应用效果[29]。由于本研究的数据量不大,因此采用字向量进行数据表示。
5. 模型的选择与训练
从常用的深度学习模型中选择模型作为分类器进行训练,本研究选取CNN模型和LSTM模型作为课堂提问文本的分类器模型。
(1)CNN模型。CNN模型是卷积神经网络(Convolutional Neural Networks)的简称。典型的CNN模型的结构包括输入层、卷积层、池化层、全连接层和输出层。其中卷积层是CNN模型的核心。这些卷积层具有小尺寸但可以在整个矩阵上移动的过滤器,即卷积核。卷积计算作为一种有效提取特征的方法,每一个步长卷积核会与输入矩阵出现重合区域,重合区域对应的元素相乘、求和再加上偏置项得到输出特征的一个像素点;池化用于减少卷积神经网络中的特征数据量;全连接层中每个神经元与前后相邻层的每一个神经元都有连接关系,输入是特征,输出为预测结果。CNN模型的基本原理:假设一个k维向量,首先将每个字的字向量拼接形成句向量送入神经网络;之后使用卷积核对句子进行卷积操作,形成新特征;然后设置卷积核步长,得到句子矩阵的特征集;最后对特征集作最大值池化计算,找出最大的特征值与某一特定卷积核作对应,最终得到分类结果。
(2)LSTM模型。LSTM模型全称长短时记忆网络(Long Short-Term Memory),是一种特殊的循环神经网络模型(RNN),它通过三个门结构(遗忘门、输入门和输出门),较好地解决了循环神经网络的梯度消失、梯度爆炸,以及无法处理序列中长距离依赖问题。目前,LSTM已广泛应用于不同领域的序列预测。LSTM模型的基本原理是通过三个门结构控制信息的输入、更新和输出,也就是通过门结構,有选择地决定应丢弃、更新和输出哪些信息。具体地,LSTM利用遗忘门,将前一时刻的隐藏状态ht-1和当前输入xt,经过Sigmoid函数δ,决定保留或丢弃前一时刻记忆单元Ct-1中哪些信息,计算方法为:ft=δ(Wf·[ht-1,xt]+bf),其中ft表示信息遗忘值,ft=0表示全部舍弃,ft=1表示全部保留。Wf和bf分别表示遗忘门的连接权重和偏置。输入门决定了在当前节点中应添加哪些信息,输入门先通过一个Sigmoid函数,用于控制要更新的信息it,it=δ(Wi·[ht-1,xt]+bi),Wi和bi分别表示输入门的连接权重和偏置,再经过tanh函数生成候选向量■■,■■=tanh(WC·[ht-1,xt]+bC),WC和bC分别表示更新值连接权重和偏置值,则当前记忆单元的状态Ct=ft*Ct-1+it*■■。输出门决定了最后输出什么信息,确定具体的输出信息。最后的输出经过了Sigmoid函数和tanh函数,Ot=δ(Wo·[ht-1,xt]+bo),ht=Ot*tanh Ct,Ot表示输出门状态,Wo和bo分别表示输出门的权重和偏置,ht表示最终输出值,Ct表示当前记忆单元状态。确定好模型后,应用经过预处理的数据对模型进行训练,并调整模型参数,直至模型在测试集上的评价指标不再增加。
6. 预测
选择具有更好分类效果的模型作为分类器,将待分析的提问句子经过数据表示转换后输入到模型中进行分类,达到最终的分类结果。
四、实验及结果分析
(一)实验数据集
表2 各提问类型语料分布表
本研究收集80节初中数学优秀课堂实录,共收集到9090条课堂提问语料。为保证课堂提问数据的有效性和数据均衡性,本研究删除了部分数据。将调整后的教师课堂提问语料分为训练集、验证集和测试集,即分别选取每类数据中的60%作为训练集、20%作为验证集和20%作为测试集。数据集在提问内容、提问类型维度上的分布情况见表2。
(二)评价标准
本研究通过绘制准确率(Accuracy)和损失率(Loss)变化趋势图来直观得知模型训练过程表现情况。使用精确率(Precision)、召回率(Recall)、F1值和准确率(Accuracy)作为课堂教师提问分类效果的评价指标,并延伸二分类的评价标准。计算公式如下:
Precision = ■ (1)
Recall = ■ (2)
F1 = ■ (3)
Accuracy = ■ (4)
其中,TP表示预测正确的正样本数量,FP表示预测错误的正样本数量,TN表示预测正确的负样本数量,FN是预测错误的负样本数量。Precision针对预测结果而言,表示在被所有预测为正样本中实际为正样本的概率,即精确率;Recall针对原样本而言,表示实际为正样本中被预测为正样本的概率,即召回率;精确率和召回率又被叫作查准率和查全率,F1分数同时考虑精确率和召回率,让两者同时达到最高,取得平衡,即对分类器的性能进行综合评判。Accuracy表示预测正确的结果占总样本的百分比,代表整体的预测准确程度,包括正样本和负样本。
(三)实验模型设置
实验的硬件环境为Intel(R) Core(TM)i7-9700K CPU、64GB内存,操作系统是64位Windows10。采用Keras框架来搭建基于深度神经网络的两个分类模型。其中“epochs”设置为100轮、“batch_size” 设置为64、“dropout”设置为0.2、“learning_rate”设置为1e-3。模型的其他参数的设置为:(1)CNN模型。使用256个大小尺寸为5的卷积核来提取文本特征,经过全局最大值池化操作后,全连接层神经元的个数是128,最后使用Softmax函数对提问文本分类。(2)LSTM模型。使用128个LSTM隐藏层的神经单元进行语义信息学习,连接2个隐藏层层数进入全连接层,使用Adam方法进行优化,最后使用Softmax函数对提问文本分类。
(四)实验结果与分析
使用训练集对上述两个文本分类器模型进行训练,经由验证集调整参数后,获得的分类模型在测试集上进行分类测试的各项指标见表3。
表3 提问内容分类的实验结果
表4 提问类型分类的实验结果
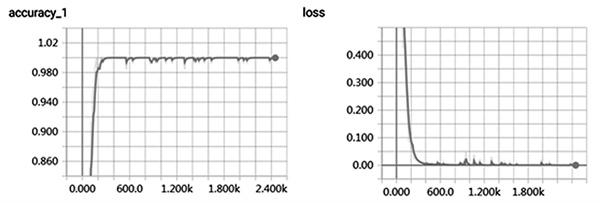
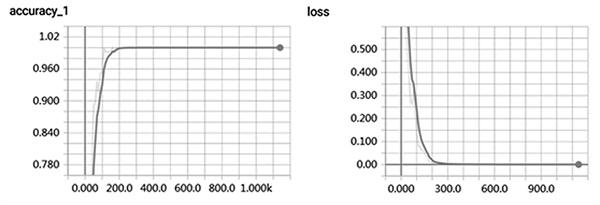
观察表3和表4可知,CNN模型的整体准确率较LSTM模型高。其中,在提问内容维度上相较于LSTM模型提高了5.27%;在提问类型维度上相较于LSTM模型提高了4.59%。结果表明,在课堂内容维度及提问类型维度的分类中,CNN模型可以更好地提取短文本信息。此外,CNN模型在训练集和验证集中的准确率和Loss值的变化曲线如图1和2所示。可知,CNN模型在训练数据集的过程中,模型准确率逐渐升高,Loss值逐渐缩小,模型的训练过程表现良好。
五、结 语
课堂提问是教师课堂教学的重要教学技能之一,是教师专业发展中的关键环节。现有的视频分析法,通过人工编码和看视频,能够对教师的课堂提问进行分析,挖掘课堂上教师提问的数量、提问的类型以及提问的内容等。但这种方法耗时耗力,无法进行大范围推广与应用。本研究提出了基于深度学习文本分类技术的教师课堂提问分析方法。该方法先收集教师课堂提问数据,经过预处理后对深度学习模型(卷积神经网络和长短时记忆网络)进行训练,使得深度学习模型能够自动对课堂提问进行预测分类。从实验结果的评价指标上看,该方法可以替代基于人工的视频分析方法,能够对教师课堂提问分析进行大规模应用,有助于促进教师专业发展。本研究的实验结果表明,基于深度学习的智能文本处理方法可替代,或部分替代原有的人工操作,成为助力教师专业发展,乃至整个教育领域发展的利器。
[参考文献]
[1] 洪松舟,卢正芝.我国有效课堂提问研究十余年回顾与反思[J].河北师范大学学报(教育科学版),2008,10(12):34-37.
[2] 卢正芝,洪松舟.教师有效课堂提问:价值取向与标准建构[J].教育研究,2010,31(4):65-70.
[3] 陈薇,沈书生.小学数学教学中深度问题的研究——基于专家教师课堂提问的案例分析[J].课程·教材·教法,2019,39(10):118-123.
[4] 叶立军,郑欣.专家型数学教师代数复习课提问行为研究——以一次函数和反比例函数为例[J].数学教育学报,2018,27(2):46-49.
[5] 郑友富.专家型教师与新手教师课堂提问的比较研究[J].教育科学研究,2009(11):57-60.
[6] 葉立军,斯海霞.基于录像分析背景下的代数课堂教学提问研究[J].教育理论与实践,2010,30(8):41-43.
[7] 周莹,王华.中美中学数学优秀教师课堂提问的比较研究——以两国同课异构的课堂录像为例[J].数学教育学报,2013,22(4):25-29.
[8] 胡启宙,孙庆括.初中数学教师课堂提问的方式和反馈水平实证研究——基于三位教师课堂录像的编码分析[J].数学教育学报,2015,24(4):72-75.
[9] 叶立军. 数学教师课堂教学行为比较研究[D].南京:南京师范大学,2012.
[10] 张文宇,范会勇.基于 NVivo10 分析的数学教育专业硕士课堂提问研究——以首届全国全日制教育硕士学科教学(数学)专业教学技能决赛视频为例[J].数学教育学报,2019,28(1):92-96.
[11] 叶立军,周芳丽.基于录像分析背景下的教师提问方式研究[J].教育理论与实践,2012,32(5):52-54.
[12] 甄园宜,郑兰琴.基于深度神经网络的在线协作学习交互文本分类方法[J].现代远程教育研究,2020,32(3):104-112.
[13] 魏艳涛,秦道影,胡佳敏,姚璜,师亚飞.基于深度学习的学生课堂行为识别[J].现代教育技术,2019,29(7):87-91.
[14] 冯翔,邱龙辉,郭晓然.基于LSTM模型的学生反馈文本学业情绪识别方法[J].开放教育研究,2019,25(2):114-120.
[15] 邵怀领.课堂提问有效性:标准、策略及观察[J].教育科学,2009,25(1):38-41.
[16] 黄会来,王迎.数学高效与低效教师课堂提问教学行为的案例比较[J].数学教育学报,2011,20(3):90-92.
[17] 黄友初.教师课堂教学行为的四个要素[J].数学教育学报,2016,25(1):72-74.
[18] 于国文,曹一鸣.“中澳法芬”中学数学课堂教师提问的实证研究[J].数学教育学报,2019,28(2):56-63.
[19] 顾泠沅,周卫.课堂教学的观察与研究——学会观察[J]上海教育,1999(5):14-18.
[20] 涂荣豹.数学建构主义学习的实质及其主要特征[J].数学教育学报,1999(4):16-20.
[21] 余凯,贾磊,陈雨强,徐伟.深度学习的昨天、今天和明天[J].计算机研究与发展,2013,50(9):1799-1804.
[22] 张建明,詹智财,成科扬,詹永照.深度学习的研究与发展[J].江苏大学学报(自然科学版),2015,36(2):191-200.
[23] 冯帅,许童羽,周云成,赵冬雪,金宁,王郝日钦. 基于深度卷积神经网络的水稻知识文本分类方法[J]. 农业机械学报,2021(2):1-13.
[24] 赵明,杜会芳,董翠翠,陈长松.基于word2vec和LSTM的饮食健康文本分类研究[J].农业机械学报,2017,48(10):202-208.
[25] 曾谁飞,张笑燕,杜晓峰,陆天波.基于神经网络的文本表示模型新方法[J].通信学报,2017,38(4):86-98.
[26] 翁洋,谷松原,李静,王枫,李俊良,李鑫.面向大规模裁判文书结构化的文本分类算法[J].天津大学学报(自然科学与工程技术版),2021,54(4):418-425.
[27] 冯斌,张又文,唐昕,郭创新,王坚俊,杨强,王慧芳.基于BiLSTM-Attention神经网络的电力设备缺陷文本挖掘[J].中国电机工程学报,2020,40(S1):1-10.
[28] 罗枭. 基于深度学习的课程主观题自动判卷技术研究与实现[D].杭州:浙江农林大学,2019.
[29] 刘敬学,孟凡荣,周勇,刘兵.字符级卷积神经网络短文本分类算法[J].计算机工程与应用, 2019,55(5):135-142.
