一种针对侧信道建模攻击中数据不平衡的新方法*
2021-09-14郑梦策南杰慧罗志敏胡红钢
汪 平, 郑梦策, 南杰慧, 罗志敏, 胡红钢
中国科学技术大学 中国科学院电磁空间信息重点实验室, 合肥230027
1 引言
侧信道攻击(Side Channel Attack, SCA) 是一种利用运行加密算法的物理设备所泄露的侧信息来恢复秘密信息的攻击[1]. 常用的侧信息包括时间、能量消耗、电磁辐射等. 侧信道攻击主要分为建模攻击和非建模攻击, 其中建模攻击近年来得到了迅速的发展, 尤其是与深度学习(Deep Learning, DL) 的结合.建模攻击主要包括建模阶段和攻击阶段. 在建模阶段, 假设攻击者有一个与目标设备相同且完全控制的建模设备, 然后通过建模算法对建模设备的泄露特征进行刻画并构建模板, 攻击阶段直接利用模板来恢复目标设备的秘密信息.
模板攻击(Template Attack,TA)[2]可以看作是最早的建模攻击,其原理是利用多元高斯正态分布对泄露噪声进行建模. 随着建模攻击的发展, 一系列基于机器学习(Machine Learning, ML) 的建模攻击被提出, 其中两个比较常用的模型是支持向量机(Support Vector Machine, SVM)[3]和随机森林(Random Forest, RF)[4], 在攻击无防护和有防护的密码实现上都取得了不错的成果[5,6]. 近年来, 随着DL 的发展,更多基于DL 的建模攻击被不断提出, 其中Maghrebi 等人最早尝试将DL 应用在建模攻击上[7]. 相比于传统建模攻击, 无需进行兴趣点选取、对齐等预处理操作, 并且某些网络结构具有天然的抵抗侧信道防护的性质, 比如卷积神经网络(Convolutional Neural Network, CNN) 的平移不变性可以减轻轨迹抖动带来的影响[8]. 后续又有很多研究者对于深度学习在建模攻击上的应用做了很多优化工作[9,10].
在建模攻击中, 我们通常要选择泄露模型来计算每条轨迹对应中间值的标签, 比如说汉明重量、汉明距离以及最低最高有效位等. 假设针对的是一个8 位S 盒, 其输出结果范围是0 到255, 如果直接使用该S 盒输出作为标签, 那么数据就是平衡的, 因为在采集轨迹时通常输入的是随机明文, 所以S 盒输出可以看作是均匀分布的. 而如果使用HW/HD 这样的泄露模型来计算标签, 就会导致数据不平衡问题. 这里我们以HW 为例, 当HW 为0 或8 时, 那么只有当S 盒的输出为全0 或全1 时才满足, 而这样的数据只占1/256; 同样的, 当HW 等于4 时, 数据占有最高的比例70/256. 当我们在这样的不平衡数据集上进行建模时, 就会导致模型的类别预测比例也不平衡[11,12], 降低模型的攻击效果. 需要说明的一点是, 尽管使用HW/HD 这样的泄露模型存在数据不平衡的问题, 但其缩减标签空间的高效性是不可忽视的, 假设中间值是16 位, 如果直接使用中间值作为标签, 那么就有65 536 种类别, 而使用HW/HD 计算的标签只有17种, 当数据的类别过多时, 不仅会大大增加计算代价, 也难以训练出有效的模型. 另一方面, 在适用的场景下HW/HD 能量模型可以准确刻画泄露的差异性, 从而更有效地构建模型.
解决这种不平衡问题的方法有多种, 一种比较常见的方法就是利用数据扩张来构建平衡的数据集.Picek 等人使用多种数据采样的方法, 尤其是合成少数类过采样技术(Synthetic Minority Oversampling Technique, SMOTE) 取得了不错的效果[12]. 当然也有其它类型的方法, 比如可以利用分层建模的方式来缓解这种不平衡问题[13]. 本文将继续延伸数据扩张技巧在侧信道建模攻击中数据不平衡问题上的应用,我们首次提出使用生成对抗网络来生成轨迹, 并利用生成轨迹扩张原始的不平衡数据集, 从而提高训练模型的攻击效果. 实验结果也表明相比于直接利用原始轨迹来合成的轨迹, 由生成对抗网络所生成的轨迹,能够更有效地降低数据不平衡问题对攻击结果的影响, 减少攻击成功所需的轨迹条数.
本文的章节安排如下: 第2 节介绍相关背景知识, 第3 节介绍条件生成对抗网络的原理, 以及生成轨迹时训练集的构建方法, 第4 节为实验结果与分析, 第5 节为本文结论.
2 背景知识
2.1 侧信道建模攻击

使得似然得分最大的猜测密钥就是我们认为正确的密钥:

通常我们所使用的侧信道评估指标猜测熵(Guess Entropy, GE)[14]就是指猜测密钥对应似然得分所构成的降序向量中, 正确密钥k∗所处的位置.
2.2 数据扩张
数据扩张(Data Augmentation, DA)[15]是一种正则化的技巧, 用来处理模型在训练过程中出现的过拟合现象, 从而构建更健壮的模型. 当然, 这一方法更多的还是运用在图像领域, 比如对图像做平移和反射, 改变图像通道的强度等操作有效地降低了错误率[16]. 而在侧信道领域中, 近几年来也有一些研究者将DA 引入到建模攻击中, Eleonora Cagli 等人最早利用DA 这一技巧来减少模型的过拟合, 主要是通过对轨迹平移和添加抖动来合成新的轨迹[8]. Picek 等人通过数据采样的方法, 来缓解数据不平衡问题对建模攻击的影响[12]. 此外, 还有一些其它相关的工作[17,18].
2.3 条件生成对抗网络
生成对抗网络(Generative Adversarial Network, GAN) 是由Ian J. Goodfellow 于2014 年提出的[19], 主要作为一个生成模型来学习数据的分布. 为了学习真实数据x的分布pdata, 我们需要通过一个非线性函数G(z;θg) 将一个先验噪声分布pz(z) 映射到pdata, 而这个非线性函数G就是生成器, 假设生成器学习到的数据分布为pg, 我们的目标是尽可能的让pg接近pdata.
判别器同样是一个非线性函数D(x;θd), 给出一个样本来自pdata而不是pg的概率. 然后我们交替的训练判别器和生成器,并调整判别器的参数θd和生成器的参数θg,使得logD(X)最大,log(1−D(G(z)))最小. 这一训练过程可以看作生成器G和判别器D之间的最大最小游戏, 使用一个目标函数表示就是:
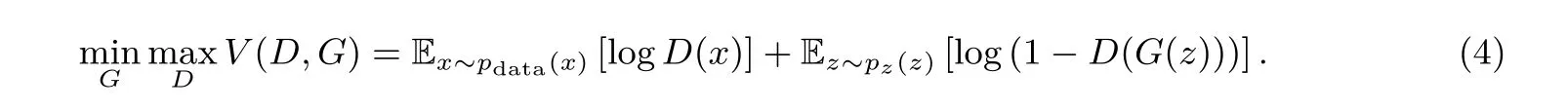
我们在基于ML、DL 进行侧信道建模攻击时, 训练集中每条轨迹都有对应的label, 而GAN 本身是无监督学习, 生成的轨迹是没有标签的. 所以使用有条件的GAN 即CGAN[20]来生成轨迹, CGAN 与GAN 的不同之处就在于, 在训练G和D时, 需要加入额外的信息y, 可以是数据的label, 也可是某一分布下的数据. 此时的目标函数则变成了:
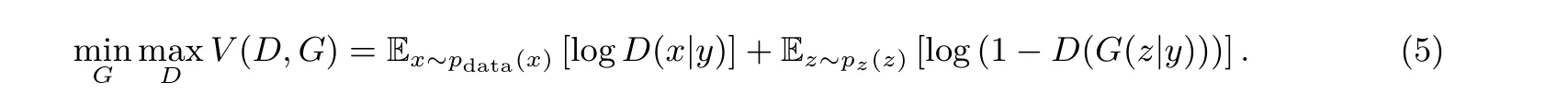
图1 展示了CGAN 的简单架构, 生成器G的输入为噪声和指定label, 判别器D的输入为真实轨迹和生成轨迹及其对应label.
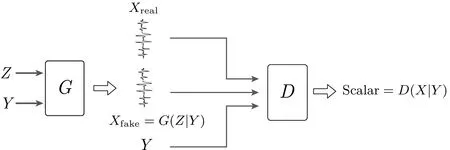
图1 条件生成对抗网络Figure 1 Conditional generative adversarial network
3 CGAN 在建模攻击中数据不平衡问题上的应用原理及方法
3.1 网络结构
3.1.1 CGAN
我们所使用生成器和判别器的主体构成是全连接网络, 当然也可以使用其它类型的网络结构, 比如基于卷积的. 这里给出两者的整体结构, 以ASCAD.h5 数据集所使用的模型为例, 如图2 所示.
对于图2(a) 的生成器, 首先是通过embedding 层将标签编码成与噪声维度相同的向量, 接着通过multiply 层将噪声与标签结合起来(也可以使用其它的实现方式, 比如通过numpy 中的concatenate 函数来直接拼接两个向量), 然后输入到Sequential 中, Sequential 代表的是生成器的主体部分, 可以看到输入是100 维, 输出即为轨迹的维度700. Sequential 由(Dense, LeakyReLU, BatchNormalization) 这三层按顺序重复堆叠N次,N的选取依据具体的数据集. 图2(b) 的判别器的输入部分是类似的, 只不过标签要变成与轨迹维度相同的向量, 然后与轨迹相结合, 中间层类似, 而输出是一个标量, 代表对输入轨迹真假的判断得分. 对于ASCAD.h5、AES_HD、AES_RD 三个数据集, 我们在训练CGAN 模型时, 使用的优化器是Adam, 训练参数学习率、迭代次数、批处理尺寸依次为[(0.0001, 100, 100), (0.0001, 150, 200),(0.0001, 100, 200)], 这里给出的是直接使用不平衡数据集生成轨迹的训练参数, 3.2 节将要提到的另外三种方法在训练CGAN 时对应的训练参数有微小的差异, 需要进行微调. 关于生成轨迹的更多细节, 包括轨迹的质量评估等请参考我们的另一篇文献[21].
注1 embedding、multiply、Sequential 等这些都是Keras 深度学习开源库(keras-2.2.4) 中的相关函数.
3.1.2 攻击模型
这里我们所选取的攻击模型是多层感知机. 对于ASCAD 数据集, 模型使用了文献[9] 中对应的超参数; 而AES_HD、AES_RD 两个数据集, 则是使用10 折叠交叉验证来选取模型的超参数, 包括结构参数和训练参数. 10 折叠交叉验证的含义是, 将建模集划分成训练集和验证集(每次划分是不一样的), 然后分别训练10 次, 并将10 次在验证集上的结果取平均. 数据集ASCAD.h5、AES_HD、AES_RD 对应模型的隐藏层和每层神经元个数分别为[(200, 200, 200, 200, 200), (200, 200, 200, 200, 256), (200,256,256, 256, 200)]. 中间层和最后一层的激活函数分别为ReLU 和Softmax. 三个模型对应的训练参数学习率、迭代次数、批尺寸依次为[(0.0001, 100, 200), (0.00001, 150, 256), (0.00001, 100, 200)], 所使用的优化器都是RSMProp. 另外, 要补充的一点是当我们将生成的轨迹加入到原始训练集后, 重新训练模型时,有可能之前的超参数此时并不是最优的, 因此可以进行简单的微调.
3.2 构建CGAN 训练集的不同方法
在使用CGAN 生成轨迹的时候, 如果我们直接使用原始的训练集来生成轨迹, 那么CGAN 模型同样会受到数据不平衡问题的影响, 可能会导致生成的轨迹更偏像于主类轨迹, 所以我们设计了四种不同的方法来构建CGAN 的训练集, 减少这一问题带来的影响, 方法如下:
(1) 直接使用原始不平衡的数据集来生成轨迹(generate with imbalanced data).
(2) 考虑到label = 4 的轨迹所占比例最高, 而且通常不平衡数据下所训练模型对测试集的预测也更偏向label = 4, 甚至大多数时候模型对测试集的整体预测精度在27%[11]左右, 而这一精度实际上也是label = 4 的轨迹所占比例, 因此label = 4 是不平衡问题中最主要的影响因素, 所以我们将label = 4 的轨迹单独拿出, 然后将剩余的轨迹作为CGAN 的训练集(generate without label= 4).
(3) 选择类别占比相同的轨迹作为一个训练集, 比如说, label= 0, 8 对应的轨迹组成一个CGAN 的训练集, 生成轨迹对应的label 也等于0 和8, 因此, 我们需要分别将label = 0, 8、label = 1, 7、label = 2, 6、label = 3, 5 对应的轨迹分成四组训练集, 然后分别生成轨迹(generate with two labels).
(4) 将所有类别的轨迹数量减少到占比最少的类别对应的轨迹数量, 然后构成CGAN 的平衡训练集,举个例子, label = 0 的轨迹在原始训练集中有128 条, 然后我们从其他类别中也分别取128 条轨迹, 构成一个平衡的训练集(generate with balanced data).
3.3 生成轨迹的质量评估方法
生成轨迹并不像生成图片一样, 即使看起来与原始轨迹相似, 但无法观察到是否包含了与原始轨迹一致的泄露. 我们通常使用相关能量分析(Correlation Power Analysis, CPA)[22]对轨迹进行兴趣点选取也即泄露分析, 这一方法同样适用于生成轨迹. 因此, 结合生成轨迹与原始轨迹的CPA 结果并对比两者的泄露位置以及强度, 可以有效的对生成轨迹进行简单评估[21]. 经过CPA 评估后, 需要将生成轨迹加入到原始训练集中, 重新构建攻击模型, 验证是否能改善攻击结果. 除此之外, 利用差分能量分析(Differential Power Analysis, DPA)[23]同样可以评估生成轨迹, 只不过是非线性的.
3.4 扩充原始训练集
在文献[8,12] 中, 虽然都使用了数据扩张的方法, 但对于如何扩张原始数据的实现细节并未给出. 在本文中, 我们以主类label = 4 的轨迹数量为基准, 扩充其它类别的轨迹数量. 这里以label = 0 为例, 假设所有类别的轨迹数量共有1000 条, 依据汉明重量分布(1/256, 8/256, 28/256, 56/256, 70/256, 56/256,28/256, 8/256, 1/256), 可以得到类别为0 和4 的轨迹分别约有4 和273 条, 那么我们需要生成269 条label 为0 的轨迹并加入这1000 条轨迹集中, 使得label 为0 和4 对应的轨迹数量相同. 实际场景下, 训练集中各类别的数量是接近这个分布的, 没有必要去计算每个类别的真实数量, 结合汉明重量分布, 直接使用总的轨迹数量来估算每个类别对应的轨迹数量, 就像我们上面的举例. 因此, 除了label = 4 对应的轨迹不需要生成, 其它类别的轨迹都需要生成.
此外, 在扩充原始训练集时, 并不是加入的生成轨迹越多越好. 因为生成轨迹的分布与原始轨迹的分布仍然存在差异, 当我们加入的生成轨迹越来越多, 会导致模型所学习的泄露分布偏向生成轨迹, 反而使得模型的攻击效果降低.
3.5 攻击流程与结果评估
首先, 分别训练原始训练集和扩充后的训练集并构建模型, 接着对测试集进行100 次攻击, 然后取平均作为最终的攻击结果, 并对比平衡前与平衡后的模型攻击效果. 每次测试集中的轨迹都是从攻击集中随机选取的一个子集, 对于AES_RD 数据集, 因为整个攻击集中的轨迹都作为测试集, 因此我们通过打乱轨迹的顺序来保证平均结果的可靠性.
4 实验
4.1 实验数据
首先要说明的一点是, 我们并未攻击无防护的AES 软件实现, 主要的原因是对无防护的AES 进行建模攻击确实要容易很多. 所以, 在不平衡的数据下训练出来的模型也可以使用很少的轨迹完成一次成功攻击, 那么即使用了一些平衡数据集的技巧, 攻击结果并不会有太明显的提升. 这一点我们从文献[12] 中对DPAv4 的攻击结果也可以看出来.
4.1.1 AES_HD
首先, 我们对一个无防护的AES 硬件实现进行攻击测试, 因为AES 的硬件实现, 有很多并行操作, 所以信噪比很低, 攻击难度很大. 该AES 算法是由VHDL 编写并在带有Xilinx Virtex-5 FPGA 的Sasebo GII 上实现. 能量轨迹通过放置在电源线上解耦电容的高灵敏度近场电磁探针来完成采集, 并由Teledyne LeCroy Waverunner 610zi 示波器进行采样. AES_HD 共包含了100 000 条轨迹, 每条轨迹有1250 个样本点, 并且适合攻击的地方是最后一轮中将密文写入寄存器时:
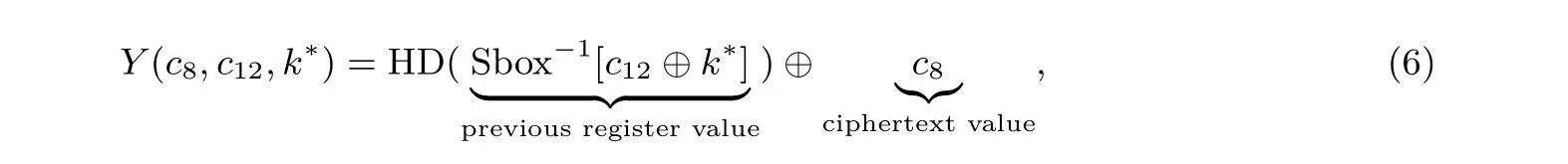
这里c12和c8都是子密文. 求c12与密钥k∗异或值的S 盒逆, 实际上是求c12所在寄存器上一次写入的值, 因此有一个寄存器跳变的关系, 所以适合的泄露模型为HD.
注2 AES_HD 轨迹集可以在https://github.com/AESHD/AES_HD_Dataset 上获取.
4.1.2 ASCAD
接着, 我们针对有一阶掩码防护的AES 实现进行攻击, 测试带有高阶防护的轨迹. ASCAD 是由Prouff等人提供的一个公开数据集[9], 旨在为未来基于深度学习的测信道相关工作提供一个评估基准. 该数据库中的轨迹来自于带有一节掩码防护的AES 软件实现, 包含了对齐与非对齐两种类型的轨迹. 这里我们使用了对齐的轨迹集ASCAD.h5, ASCAD.h5 由两部分组成, 建模轨迹集50 000 条和攻击轨迹集10 000 条. 每条轨迹包含了700 个样本点, 并且对应于第一轮的第三个S 盒执行过程. 结合HW 泄露模型, 我们的建模对象是:
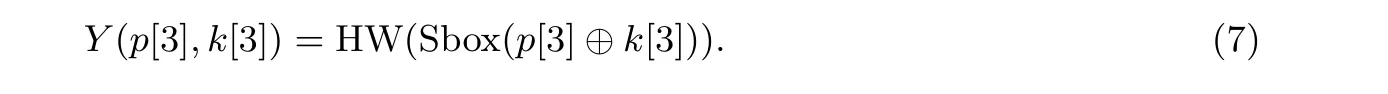
注3 ASCAD 轨迹集可以在https://github.com/ANSSI-FR/ASCAD 上获取.
4.1.3 AES_RD
最后, 我们测试了带有非对齐防护措施的AES 软件实现. 该加密算法是在一个有8 位Atmel AVR微控制器的智能卡上实现, 同时加入了随机延迟的防护措施[24], 此防护的目的是使攻击者所采集到的轨迹是非对齐的, 增加攻击的难度. AES_RD 数据集共有50 000 条轨迹, 每条轨迹有3500 个样本点, 攻击的对象是第一轮的第一个S 盒:

注4 AES_RD 轨迹集可以在https://github.com/ikizhvatov/randomdelays-traces 上获取.
4.2 实验结果
4.2.1 ASCAD 攻击结果
ASCAD.h5 共有50 000 条训练集, 我们按照汉明重量分布对label 从0 到8, 不包括label = 4, 分别生成了对应数量为(13 450, 12 100, 8200, 2700, 2700, 8200, 12 100, 13 450) 的轨迹, 然后加入到原始训练集中, 攻击结果如图3 所示.
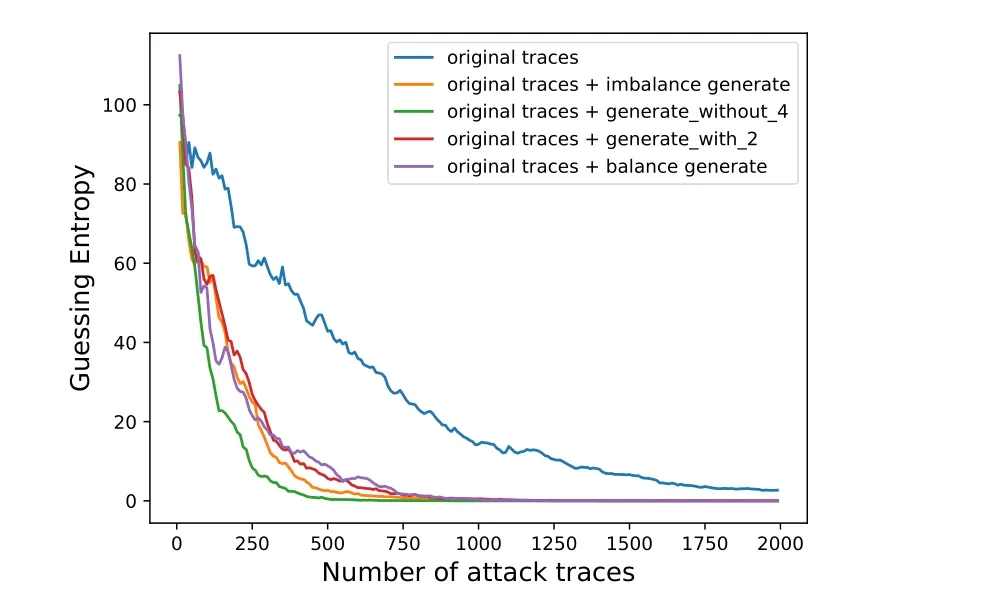
图3 ASCAD.h5 的攻击结果Figure 3 Attack results of ASCAD.h5
从图3 的攻击结果可以看到, 对原始训练集进行平衡, 有效地减少了成功攻击所需的轨迹条数, 其中由3.2 节方法(2) 构成的训练集所生成的轨迹加入到原始训练集后, 训练出的模型具有最好的攻击效果,仅需约700 条轨迹就能够恢复出密钥, 而原始训练集构建的模型需要2000 条以上的轨迹才有可能成功恢复密钥, 在文献[9] 中, 其关于使用HW 作为标签的攻击结果中可以看出在使用1000 条轨迹后GE 收敛到0 仍然需要不少的轨迹. 其它三种方法需要约1100 条轨迹可以进行一次成功的攻击.
4.2.2 AES_HD 攻击结果
对于AES_HD 数据集, 我们同样是使用了50 000 条轨迹作为训练集, 各类别的轨迹所生成的数量与ASCAD 实验中是一致的, 具体的攻击结果如图4 所示.
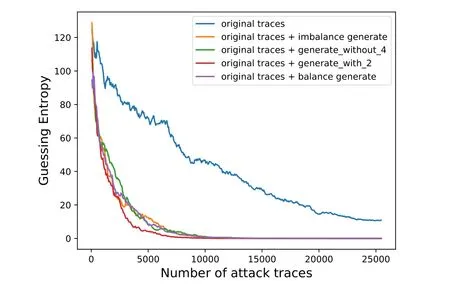
图4 AES_HD 的攻击结果Figure 4 Attack results of AES_HD
从图4 可以看到, 原始不平衡训练集得到的模型在25 000 条轨迹内是无法恢复出密钥的, 而我们的方法, 最少只需用约11 000 条轨迹就能够进行一次成功的攻击, 对应的CGAN 训练集构成方法为同比例类别的轨迹两两组合来生成轨迹. 在文献[12] 中同样是基于MLP 模型, 对AES_HD 进行攻击, 使用了SMOTE 技巧, GE 是在约15 000 条轨迹后收敛到零. 相比之下, 我们的方法对不平衡问题具有更好效果,或者说CGAN 生成的轨迹能够为模型带来更多有用信息.
4.2.3 AES_RD 攻击结果
AES_RD 数据集共有50 000 条轨迹, 我们使用了25 000 条轨迹作为训练集, 按照汉明重量分布, 对各类别添加的轨迹数量为(6725, 6065, 4100, 1350, 1350, 4100, 6050, 6725), 攻击结果如图5 所示.
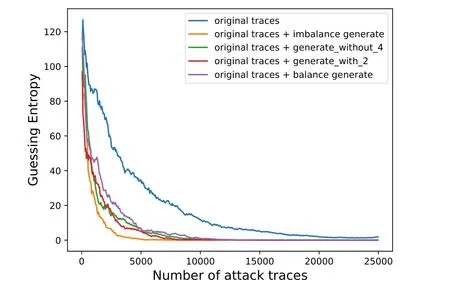
图5 AES_RD 的攻击结果Figure 5 Attack results of AES_RD
在文献[12] 中, 对应的攻击结果在25 000 条攻击轨迹下, 即使用SMOTE 技巧来平衡原始训练集,GE 仍然无法收敛到零. 而我们的方法能够带来显著的提升, 四种方法在25 000 条轨迹之内都能够成功恢复密钥, 并且只需使用将近一半的攻击轨迹. 其中最好的结果是只需约7500 条轨迹, 对应的方法是直接基于原始训练集来生成轨迹.
4.3 实验结果分析
(1) 尽管可以看到我们的方法对于攻击结果有明显的改善, 但只从攻击结果上无法看出是如何改善不平衡问题的. 因此, 这里我们以ASCAD 的实验为例, 分别绘制出使用原始不平衡训练集所构建模型以及优化后模型的类别预测比例, 两次攻击都使用相同的3000 条轨迹. 图6(a) 中正确预测的类别label = 4 所占比例最高, 其它正确预测的类别个数很少, 甚至label = 0, 1, 7, 8 对应的轨迹没有一条被正确分类. 而通过CGAN 所生成的轨迹对原始训练集平衡后, 模型的类别预测比例有了明显的改善, 其中label = 2, 3, 5, 6 的对应轨迹被正确预测的数量大幅增加, 并且原始训练集中占比很少的类别也出现了被正确预测的轨迹, 比如label = 1, 7. 从整个混淆矩阵来看,优化后模型的类别预测比例更加平衡, 而不是只集中在像label = 3, 4, 5 这样的主类上.
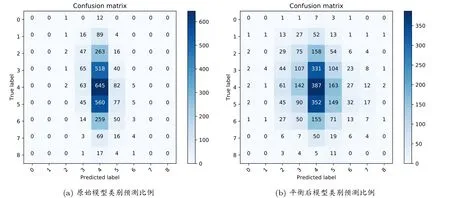
图6 ASCAD 攻击结果的混淆矩阵Figure 6 Confusion matrices for attack results of ASCAD
(2) 关于四种构成CGAN 训练集的方法, 从上面的三个实验中, 可以看到没有哪一种方法是绝对的好, 要实际测试过后才能确定. 比如上面的关于ASCAD 的实验, 去除主类label = 4 对应的轨迹来构成CGAN 的训练集是最好的方法, 我们从其原始训练集对应模型的类别预测比例可以看出, label = 4 对模型的影响很大, 因此直接拿掉label = 4 的轨迹来做轨迹生成, 效果更好. 而在AES_RD 的实验中, 我们也看到直接使用不平衡的原始训练来生成轨迹, 效果更好, 这也说明在某些情况下, CGAN 的训练集需要由所有类别的轨迹来构成. 因此, 在使用CGAN 生成轨迹解决不平衡问题时, 要尽可能多尝试几种构建其训练集的方法.
(3) 对比Picek 等[12]的相关工作, 我们的方法显然更加有效. 直观上来看, 两种方法都是利用原始训练集中的轨迹来合成新的轨迹, 从信息论的角度来说, 信息并未增多, 但实际上合成的轨迹能够增加信息的完整性. 简单地说就是, 某一少数类别的轨迹都来自同一分布, 由于相应的轨迹数量过少, 无法表现出这一分布下的全部信息. 相比于SMOTE 中的轨迹合成方法, CGAN 是通过学习输入轨迹所包含的分布, 尽可能使所生成的轨迹靠近原有分布, 这样生成的轨迹显然能够体现出原有分布中的更多信息, 更好地对少数类别样本缺失的信息进行弥补.
5 结论
本文研究了在基于机器学习和深度学习的侧信道建模攻击中, 使用HW 和HD 作为标签带来的数据不平衡问题. 我们首次提出使用条件生成对抗网络来生成轨迹, 从而构建平衡的数据集. 实验结果表明, 由平衡后的训练集所构建的模型具有更好的类别预测比例, 能够有效减少成功攻击所需的轨迹条数, 在有一阶掩码防护软件实现、非对齐防护软件实现以及无防护硬件实现的三种AES 数据集上均有很好的攻击效果.
致谢
感谢中国科学技术大学信息科学实验中心提供的软硬件服务.
