基于全卷积神经网络的植物叶片自动分割及表型解析*
2021-09-13王鹤树曹丽英
王鹤树,曹丽英
(吉林农业大学信息技术学院,长春市,130118)
0 引言
植物是人类生存必不可少的物质资源[1]。近年来,植物表型分析解决了诸多相关问题,而图像分析系统被广泛应用于表型分析的研究中[2]。基于图像分析的方法通过分析植株的不同器官图像来进行植物生长监测、形态解析以及表型提取等测量,进一步对植物的性状进行分析预测产量等[3]。针对不同的实验设计和特殊的图像采集场景,提出了各种成像和计算机视觉技术的需求,以求实现非破坏性的植物表型提取目的。
农业学者们在植物图像解析方面已经进行了大量研究[4-7],其中包括植物的病害识别、叶片检测、叶片技术、叶片分割以及长势监测等[8]。现阶段大多数相关工作数据来源都是在受控的实验室环境、温室或者田间进行采集的。吴焕丽等[9]基于改进的K-means图像分割算法实现小麦等细叶作物的覆盖度提取,计算覆盖度准确率在90%以上,但是这种传统图像处理方法需要消耗大量人力和时间。Kumar等[10]提出一种基于图像增强的叶片分割方法,实现了CVPPP数据集中拟南芥植株的叶片分割,其算法精度达到了95.4%,并且可以用于其他圆形叶片植物的分割,但其方法并不能实现大数据的批量化分割,还需要依靠人工交互手段作为辅助。Qian等[11]进行了玉米多光谱图像的精准分割和叶绿素诊断,其提出的局部阈值处理分割算法分割玉米叶片精度达到95.59%,但是提取的光谱特征参数建模R2仅为0.596左右,参数提取精度并不理想。Chen等[12]提出一种基于机器视觉技术的模糊聚类和向量机分割玉米病害叶片图像的病害识别方法,识别率在95%以上,但是这种方法泛化性不足,且多个环节涉及人工交互进行,使得病害识别效率不高。Goclawski等[13]通过神经网络对葫芦叶片染色扫描图像进行分割,进行了非生物胁迫的颜色性状分析,然而他们的模型仅考虑应用了一种反向传播网络,并没有将其提出的解决方案与其他神经网络模型进行对比,因此他们的网络可能并不是最优的体系结构。Ma等[14]运用全卷积神经网络(FCN)实现水稻苗期田间图像中幼苗和杂草的图像分割,其提出的segnet方法平均准确率为92.7%,能够有效地对稻田图像中水稻幼苗、背景和杂草的像素进行分类。
通过对相关工作的分析,发现在叶片分割领域已有的研究中,分割效果大多取决于数据集质量以及背景[15]、光照等环境因素的复杂程度[16],且处理方法多是基于监督学习或者传统的人工分割手段,鲁棒性不高也不能实现高通量地叶片分割。针对这些不足之处,本文提出一种基于全卷积神经网络的深度学习方法进行植物图像的叶片分割,使用小样本量训练得到的模型即可实现植物叶片图像高通量地分割效果,且模型具有很好的鲁棒性。
1 材料与方法
1.1 数据集来源
本文所使用的植物图像来自于CVPPP(Computer Vision Problems in Plant Phenotyping)数据集,该数据集由A1、A2、A3和A4四个文件夹组成。这是一个由CVPR会议公布的用于叶片分割挑战的数据集,图像使用7mp的佳能AD1000 Power-Shot相机拍摄,其中的植物图像均由放置于花盆和托盘中的植物顶部图像组成。其中A1、A2数据集图像是拟南芥植株,A1数据集在白天每6 h获取一次,持续3周,图像的光照强度和背景环境都比较复杂;A2数据集在白天每20 min捕获一次,持续7周,背景环境较为简单,但是植株变化差异较大;A3数据集则由烟草植物图像组成;A4数据集在出苗后每隔一天获取一次,直到植株生长发育完全成熟,数据集中存在20株拟南芥完整生育期的顶视图像。综上所述,该数据集包含了不同种类植物图像、同一植物的不同生长阶段图像以及植物群体和单独植物图像。数据集中的图像在分辨率、场景复杂程度和光照强度等方面均存在差异,其具备复杂性和植物对象多样性,因此该数据集在图像分割方面存在一定挑战性,研究结果也有很强的说服力。部分数据集中图像如图1所示。
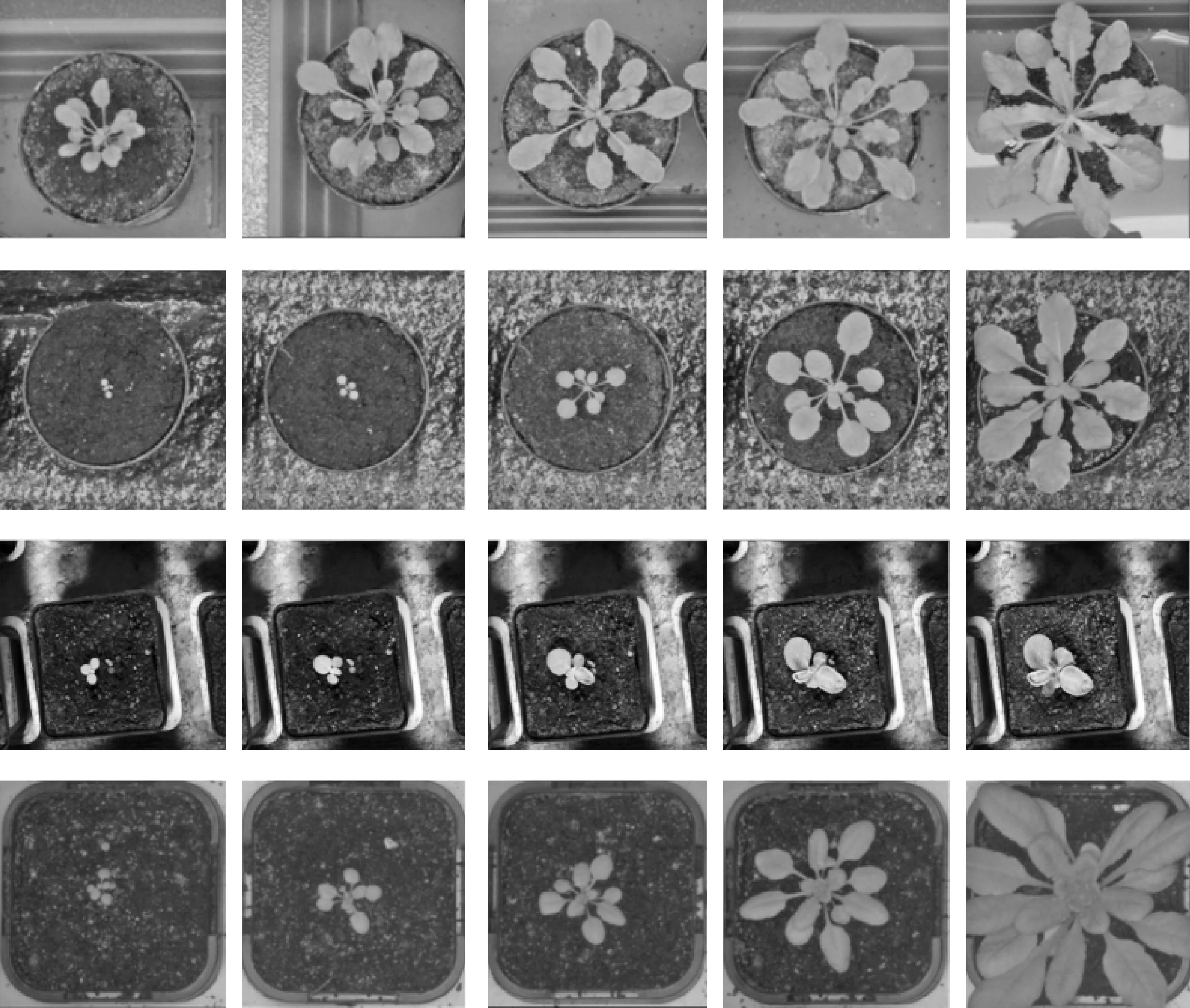
图1 CVPPP数据集中的部分图像Fig.1 Selected images from the CVPPP dataset
1.2 分割网络模型
本文的主要目的是运用深度学习技术实现端到端的图像分割效果,因此选择全卷积神经网络实现植物图像的像素级分割。为了更好的实现图像分割,并降低训练成本,本文网络模型结构参考Olaf Ronneberger的U-net网络模型[17]并加以改进优化,调整了模型框架,修改训练过程中的数据读取方式并且对激活函数和损失函数进行优化。改进后网络模型不仅缩短了训练时间节约训练成本而且分割精度更高和效果更好。具体网络结构如图2所示。

图2 模型整体结构Fig.2 Integral structure of the model
网络左面的前4层为传统的卷积层典型结构,通过逐渐缩减输入数据的空间维度以提取高维特征,1~3层都由2个3×3的卷积层(conv)和1个最大池化层(maxpooling)组成,卷积核数量为32,64,128。位于底部的第4层有需要进行上采样输入,因此仅进行了2个3×3的卷积,卷积核数量为256。网络的右半部分与左半部分呈中心对称,右面的5~7层是反卷积层即向上卷积,每一层除了正常的卷积层用于还会加入上采样。反卷积过程每一层的输入除了与其对应的下采样层输出的局部特征外还有上一层上采样获取的深层次抽象特征,这些特征通过链接的方式实现融合,从而在保证图像空间维度不变的情况下恢复了特征图细节。最后一层使用1×1卷积将每个分量特征向量映射到所需要的分类中。除了最后一层,前面所有层都有加入BN(Batch Normalization)层,对网络层的每一层的特征都做归一化,使得每层的特征分布更加均匀,在提高模型收敛速度的同时又能够提高模型的容错能力。构建的网络参数进行了一定程度的减少,主要为了缓解硬件设备运行压力,在保证分割效果情况下减少训练时间。因为训练样本数量较少,所以适当的加入了dropout层,防止网络过拟合。网络使用最大池化层进行下采样,主要是考虑对边缘特征的最大化识别利用。且在编译模型的顶端加入优化器使模型支持随机梯度下降,支持动量参数等,通过衰减率来改变学习率,对于模型有一定的辅助优化效果。
1.3 主要函数优化
1.3.1 激活函数
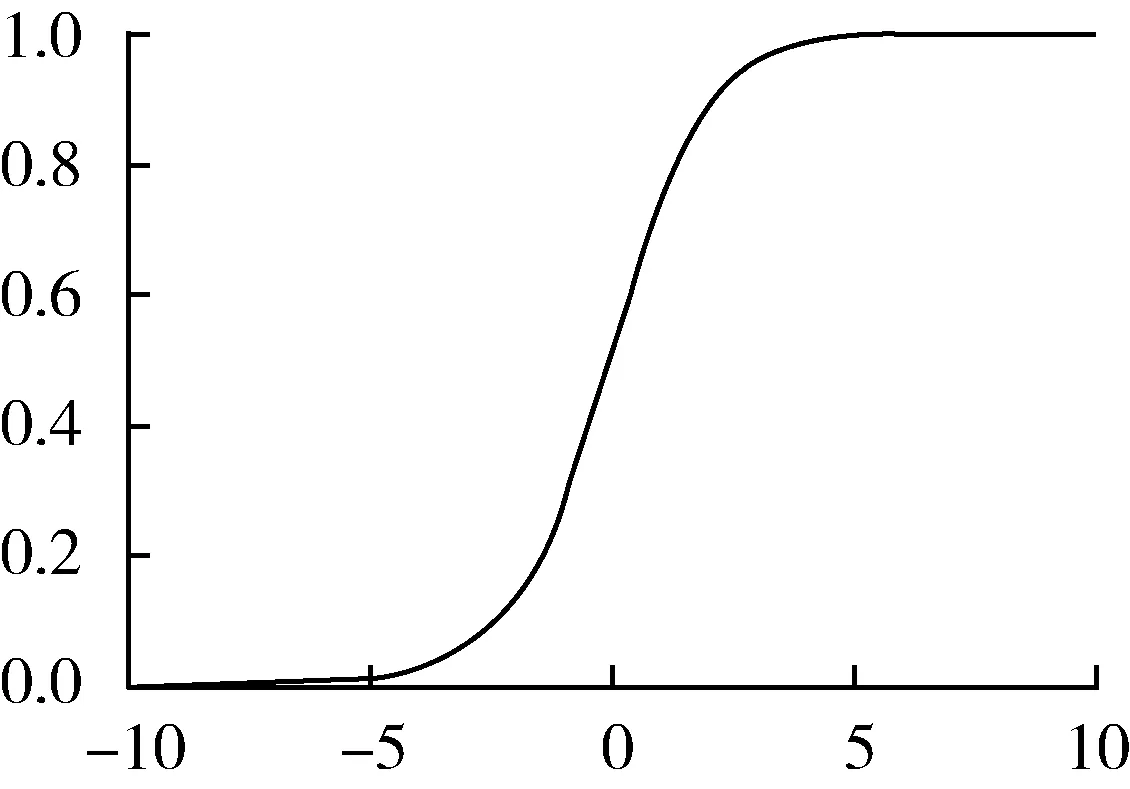
图像分割的本质是对像素点进行逐一分类,而线性模型对于这样的分类任务表达能力不足,因此引入激活函数加入非线性因素解决分类的问题,常用的激活函数有Sigmoid,ReLU,Leaky ReLU和Tanh等,其线性表达如图3所示。
U-net模型的激活函数ReLU属于线性整流函数,数学表达为
f(x)=max(0,x)
(1)
作为神经网络的激活函数,其定义了线性变换wTx+b之后的非线性输出结果。从图3中可以看出,这几种激活函数在输入值大于0的情况下输出值相同,但是在输入值为负值的情况下,ReLU不能激活神经元。这种情况对于传统的卷积神经网络模型中前向传播过程影响不大,但是在存在反向传播的网络中梯度会变为0,导致神经元失活即所谓的dying ReLU problem。
因此需要一种在输入值为负值时仍有输出的激活函数,解决在输入为负值的情况下反向传播过程神经元失活问题。从图3中可以看出相对于ReLU函数,Leaky ReLU和Tanh函数在输入为负值时都有输出,而Leaky ReLU相比于Tanh函数其在负值输出部分线性关系简单,有利于模型的快速收敛。Leaky ReLU为带泄露线性整流,当输入值x为负的时候,其梯度为常数θ∈(0,1),不会判定为0,正值与ReLU一致。选择Leaky ReLU作为激活函数,在输入为负值时仍有输出的函数作为激活函数,这样可以消除反向传播中神经元失活问题。其表达式为

(2)
对于模型的最后输出层,选择Sigmoid作为二分类的输出层激活。Sigmoid可以将一个实数映射到(0,1)的区间,非常适合二分类。在特征比较复杂时效果比较好。神经网络的中间层不选择使用,因为对于深层网络,sigmoid函数反向传播时,很容易就会出现梯度消失的情况(在Sigmoid接近饱和区时,变换太缓慢,导数趋于 0,这种情况会造成信息丢失),从而无法完成深层网络的训练。所以选择Sigmoid函数用于对神经网络输出层的激活。其数学表达为
(3)
(a)Sigmoid
1.3.2 损失函数
对于本文需要解决的拟南芥植株分割这种二分类任务,无需用到复杂的多分类函数,模型中的损失函数是多分类交叉熵函数的一种特殊情况。当多分类中,类别只有两类时,即0或者1,即为二分类,二分类也是一个逻辑回归问题,也可以套用逻辑回归的损失函数。为了配合最后一层sigmoid函数的输出,选择与二元交叉熵函数类似的损失函数,其数学表达式为
(4)
式中:x——像素点;
w(x)——权重图;
log(pl(x)(x))——某一个类别中,像素x位置的经过交叉熵计算只后得到的概率P的对数,pl(x)(x)的下标l(x)表示类别。
1.4 分割精度评估
将模型对数据集图像的分割结果进行了评价,衡量指标选择Mean Intersection over Union(MIoU)[18]和召回率r。在计算机视觉深度学习图像分割领域中,MIoU值是一个衡量图像分割精度的重要指标。MIoU可解释为平均交并比,即在每个类别上计算IoU值。由于模型实现的是二分类任务,类别数量为1,在这种情况下IoU即为MIoU取值。而召回率r则表示覆盖面的度量,度量有多个叶片像素被分割为白色像素。
在图像中,将拟南芥叶片中的像素点标记为1,如果分割后的图像中,该像素点仍然为1,则判定为true positive(TP);如果分割后该像素点被判定为0,则判定为false positive(FP)。原始图像中不属于拟南芥叶片的像素点都标记为0,如果这样的像素点被判定为1,则为false negative(FN);如果这样的像素点也被判定为0,则为true negative(TN)。模型实现的是单株植株冠层图像的二值分割,因此TN情况不影响分割精度评估,暂不列入MIoU评估参数中。为了保证评估参数的鲁棒性,在数据集测试分割图像中随机选取了30组数据TP、FP以及FN的均值作为对应时期的评估参数。此外召回率r,MIoU的计算公式如下。
(5)
(6)
除此之外,分割后的图像还会按照像素精度与人工测量值进行相关性系数比较。
2 试验结果与分析
2.1 模型分割效果
为了测试图3中不同激活函数对模型分割结果的影响,在本文中,分割网络模型被训练多次,每次都设置不同的激活函数。模型是在Windows环境下的开源深度学习框架Tensorflow中搭建的,使用Intel Xeon(R)Gold 6148 CPU 2块、256 GB RAM和NVIDIA Quadro P6000 GPU的PC上,训练时间约为45 min。最终,使用不同激活函数模型的分割效果如图4所示。

(a)原始图像
如图4所示,用于效果展示的测试集图像包含不同叶片大小、不同光照条件以及不同品种植物叶片的分割效果,本文训练的模型可以在不同光照条件下可以对拟南芥植株叶片进行分割,株型的大小也不影响模型的分割效果。在效果展示过程中也包含了A3数据集中的烟草叶片分割效果,证明该方法可以对不同光照条件,不同叶片大小以及不同品种植物的叶片进行分割,有较强的鲁棒性。可以根据研究需求自行获取图像,制作数据集进行精准的表型提取等方面研究。
使用不同激活函数的模型分割试验结果如表1所示,可以看出,以Leaky ReLU作为激活函数的模型分割效果最佳。该模型对于A1数据集图像分割后的召回率r为0.94,MIoU为0.93;A2数据集的召回率r和MIoU分别为0.96和0.95。尽管A1,A2数据集的植株形态结构以及光照条件都不同,但分割精度基本相同。A2数据集图像的分割精度比A1高出2个百分点,可能是由于A2数据集中图像质量高于其他数据集,特征明显,有利于模型识别。对于单张模型的分割时间相同,为1.2 s左右。
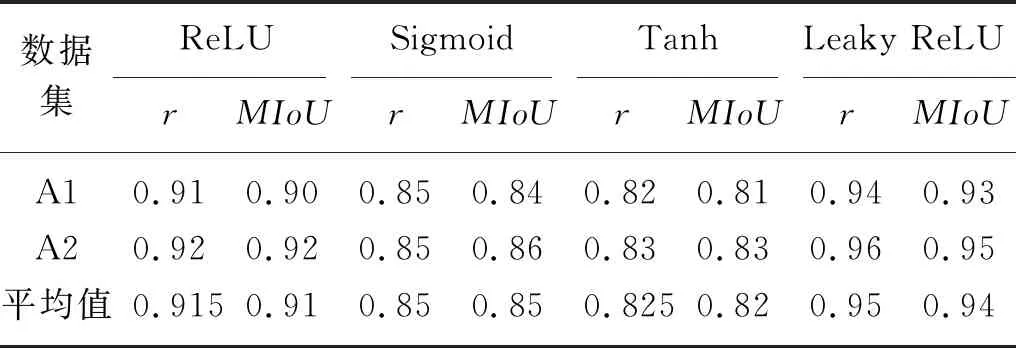
表1 不同激活函数在数据集中的分割精度Tab.1 Segmentation accuracy of different activation functions in the data set
2.2 形态特征提取
在分割后的图像中,使用OpenCV提取了拟南芥植株的形状特征。形态特征的描述主要分为两类,一类是基于轮廓的形状描述,重点描述目标区域边界轮廓;另一类是基于区域的形状描述,主要是通过区域面积、几何矩、偏心率等描述目标区域形状。本文首先计算图像分割后各植株的最小外接圆、叶片中心点、植株边界框以及植株轮廓等4个基本几何特征,如图5所示;然后依据这些基本特征进一步计算出植株的覆盖度、边界框面积、外接圆半径和叶片数量等数字形态学特征,具体计算公式如下。
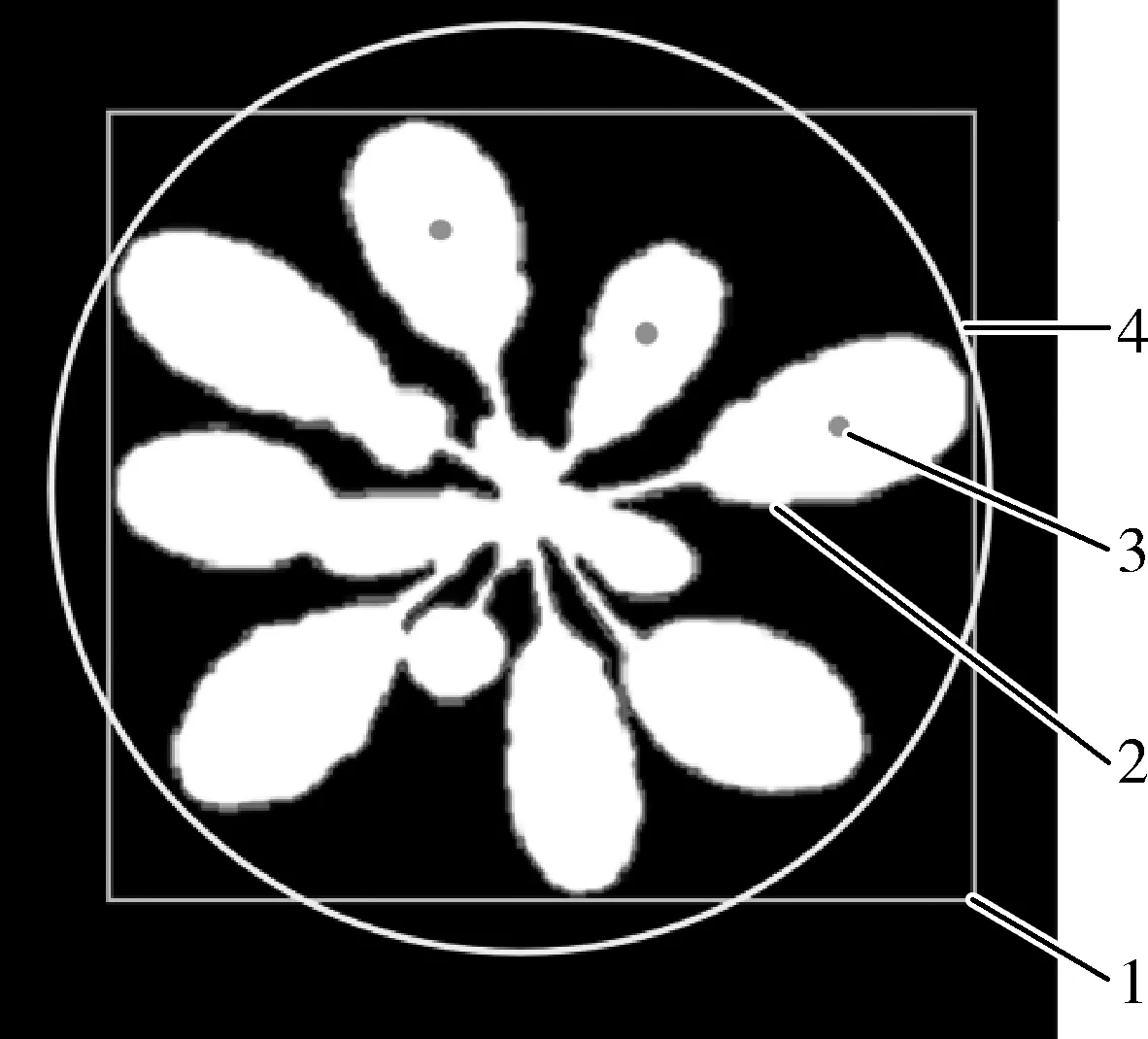
图5 分割结果中表型参数提取Fig.5 Extraction of phenotypic parameters in segmentation results1.植株边界框 2.植株轮廓 3.叶片中心点 4.最小外接圆
1)外接圆半径R:在植株轮廓上,任意两个像素点的最远距离
R=max[dis(Ci,Cj)]/2
(7)
式中:Ci,Cj——植株轮廓上最远距离的两个像素点。
2)边界框面积S:植株边界框中长和宽的值相乘
S=L×H
(8)
式中:L——最小包围盒中x方向的长度;
H——y方向长度。
植株边界框指n个能把目标植株区域包括在内的矩形中面积最小的矩形。
3)覆盖度C:由于分割后的图像是二值图像,因此覆盖度计算选择像素法,即求出目标区域所占像素的总数目。
(9)
式中:k——x轴方向上像素个数;
l——y轴方向上像素个数。
像素法计算公式就是统计f(x,y)=1的像素点的个数。可以根据图像的长、宽数值计算出每个像素点的面积,乘以分割后感兴趣区域总的像素个数即可得到图像中植株覆盖度大小。
2.3 形态特征提取精度及长势分析
为了评价模型的分割性能和表型参数提取的精度,在测试集中选取30张图像,将这30张图像使用本文模型进行分割。在分割结果中提取了覆盖度、外接圆半径、边界框面积和周长等表型参数,与人工分割结果中提取的数值进行了相关性比较,比较结果如图6所示。

(a)覆盖度提取结果比较
从图6可以看出模型的分割数值大多在人工分割值的上半部分分布,说明模型分割出的覆盖度数值整体来说要小于分割结果。造成这种情况主要有两种原因,一是因为模型中存在FP判定情况,叶片边缘的像素点并没有被正确判定[19];同时,图像中部分叶片上纯在粘有土粒、过度曝光以及阴影等情况,影响了模型的识别。当然,也存在极少数模型分割结果大于人工分割结果的情况,这种情况大多是因为拍摄过程中,植株附近存在一些杂草,颜色与叶片相近,模型未能识别。在形态特征提取方面,模型的分割结果与人工分割结果提取的形态特征数值对比结果表明,提取的四种形态学特征参数R2均大于0.96,NRMSE小于10%,证明模型分割精度很高,可以进行进一步的表型提取工作。相比于吴焕丽等[9]的研究,本研究模型不但分割精度高于其改进的K-means算法,在覆盖度提取方面具有一定优势。与Kumar等[10]的研究相比,本文模型可以实现批量化的图像分割,节省大量人力资源。与Goclawski等[13]的方法相比,本文模型的鲁棒性更强,适用于多种作物顶视图像分割。且优化过的U-net全卷积神经网络模型精度高于Ma等[14]研究中提及的FCN模型。
本文以覆盖度为例,进行了植株的长势分析,分析结果如图7所示。
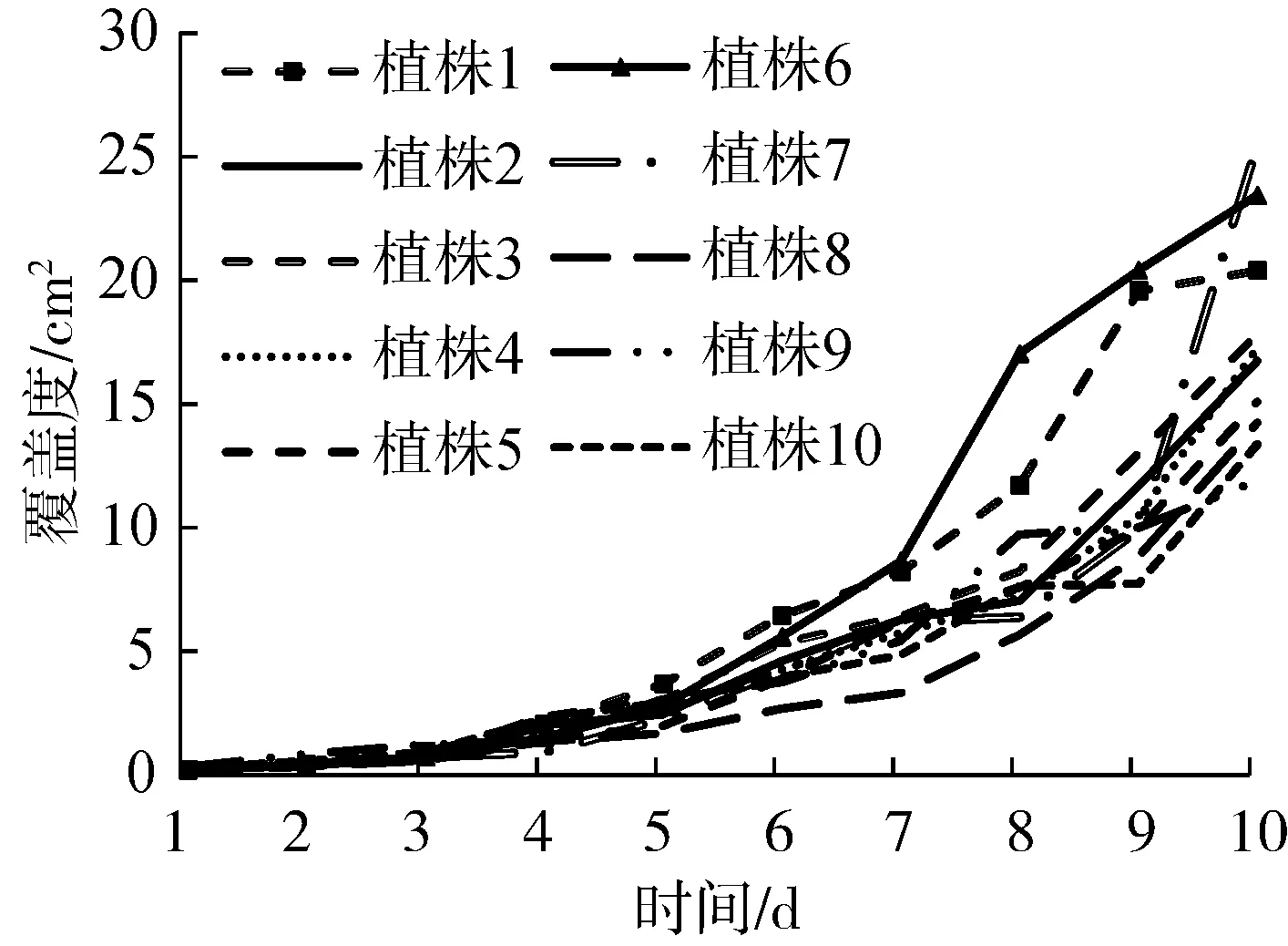
(a)A2数据集中10株不同的拟南芥植株覆盖度
植被覆盖度是指包括农作物、灌木、乔木和杂草在内的所有植物冠层、枝叶在其生长区域地面的垂直投影面积占研究统计区域面积的变分比[20-21]。数据集在处理过程中,进行过规范化裁剪,保证了背景面积大小一致。因此利用分割网络分割出的图像中叶片像素点占总像素点的比例,即为植株垂直投影面积占总背景面积的比例。将上述比例与总面积相乘,所得结果就是同等面积区域内不同品种植株的覆盖度大小。
从图7分析结果可以看出,拟南芥和烟草等莲座植物有着类似的生长趋势,前期存在一定的缓慢发育期,到达一定天数后开始快速生长。拟南芥前五天的生长发育较为缓慢,第5天后开始快速生长,覆盖度明显增加。而烟草植株在第3天开始就进入快速生长时期。
3 结论
本文以U-net分割网络为基础,对模型结构、激活函数和损失函数进行优化调整,设计出新的全卷积网络模型,实现了莲座植物图像的分割。
1)本文设计的分割网络在测试集图像中平均的分割精度达到了0.94,召回率为0.95。模型能够准确的分割出植物叶片,可以显著降低传统手工方法的工作量,提高分割效率;在分割结果中提取的形态学特征参数与人工测量值高度相关(R2>0.96),说明使用模型的分割结果进行形态特征提取满足植物表型提取精度的需求,提取的表型特征参数可以用于植物的长势分析研究。
2)本文的方法可以对温室作物顶视图像分割、表型提取以及评估定量表型性状等方面做出了一定的贡献,也为育种研究提供一种有价值的工具。
