互联网时代高校就业信息垂直搜索模型
2021-09-13严慧琳
严慧琳
黎明职业大学 商学院,福建 泉州 362000
大学生就业问题属于高校人才培养急需解决的问题,该问题在社会上的关注度很高[1]。在互联网时代下,高校就业信息搜索模型水平的要求也逐渐增加,通过高校就业信息搜索模型实现就业信息的采集,解决大学生就业困难的问题,促进大学生对口专业就业的精准性[2-4]。
通用搜索模型是对全部互联网信息实施采集与索引,因此该模型的查全率较高,但其覆盖的信息较为广泛,这导致该模型信息分类的精准性较低,不能满足用户高查准率的信息搜索要求。垂直搜索模型通过一定的策略实现遍历深度与广度的干预,使模型能够遍历所有和主题有关的网页,再筛选出合理的遍历结果,垂直搜索模型具有更为专注、精准与深入的优点。谢晓晖等研究了基于深度神经网络的搜索引擎点击模型构建[5],程煜华研究了基于D-S 证据理论的信息检索模型[6],这两个搜索模型的准确率与搜索效率均不高。
1 高校就业信息垂直搜索模型
高校就业信息垂直搜索模型主要通过5 个步骤实现信息搜索,分别为URL(Uniform Resource Locator,统一资源定位符)、信息采集、信息去噪、构建索引与信息搜索,图1 为具体步骤流程图。

图1 互联网时代高校就业信息垂直搜索模型
步骤1:以门户网站就业信息板块与权威就业信息网站的URL 为就业信息集的获取途径,通过人工发现方式获取URL 初始就业信息。
步骤2:利用深度就业信息方法结合网络爬虫技术,获取URL 就业信息网页与包括就业信息的超链网页信息,采用 DOM (Document Object Model,文档对象模型)技术分析与提取各个URL 就业信息网页,包括就业信息的超链接网页信息内的就业名称与地址等信息。
步骤3:基于节点权重去噪处理URL 就业信息网页,包括就业信息超链网页的就业名称与地址等,去除无效与干扰信息,存储于URL 资源库。
步骤4:通过排序策略对资源库内的网页构建索引,形成索引库。
步骤5:采用基于超链接和标记文本算法实现高校就业信息搜索。
1.1 就业信息采集
利用深度服务信息自动采集算法实现高校就业信息采集。图2 为深度服务信息采集流程。
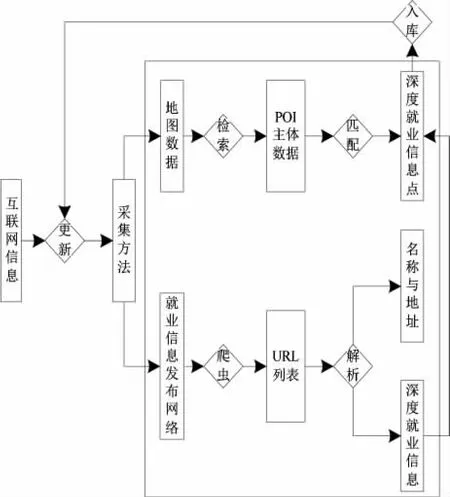
图2 深度就业信息采集方法
采集方法流程步骤如下:
步骤1:通过原地图矢量数据对POI(Point Of Interest,信息点)的分类编码搜索就业信息名称与地址等POI 点数据,依据定义结构形成深度就业信息点,就业信息字段空缺。
步骤2:利用网络爬虫获取就业信息类网站上发布就业信息的服务地点URL,利用DOM 技术分析与提取各个URL 内就业信息的名称与地址。
步骤3:计算步骤1 内获取的各个深度就业信息点内的名称、地址等字段和步骤2 内得到的各个URL 相应的名称、地址等字符串相似度,选取最优URL 页面的深度就业信息[7,8],利用编辑距离与最大公共子序列算法补充步骤1 内空缺的就业信息。
1.2 就业信息去噪
1.2.1 算法基本思想
基于节点权重的去噪算法以VIPS(Visionbased Page Segmentation,基于页面视觉分块算法)为基础,将VPIS 形成的基本视觉块树转换成样式树,通过样式树节点内的样式特征,先将叶子节点划分为细粒度的样式树,然后权重标注样式树,最后依据权重标注实施剪枝,形成去噪后的URL 就业信息[9]。图3 为URL 就业信息的去噪流程。

图3 URL 就业信息去噪流程
一般情况下,所形成的样式树没有权重表示,可以属性节点为基础,加入权重节点的概念。FT代表权重节点T,可记为F,(k,u,t,m),k为当前节点内链接数与总链接数的比值,也叫链接比;u为当前节点和容器节点在树形结构中的距离,也叫树路径距离;t为总文本中当前节点的所占比例,也叫文本比;m为节点私有属性的权重系数。利用节点的标签数量n归一化值R(Fj),可确保R(Fj)值处于[0,1]之间,公式如下:
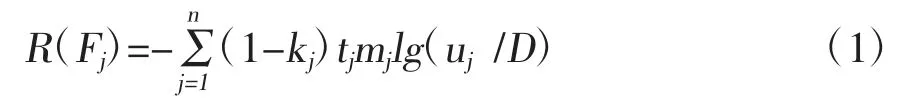
式(1)中,第j个标签的链接比是kj;第kj个标签的文本系数是tj;第j个标签的树路径距离是uj;权重树内的节点路径和是D。
1.2.2 视觉块树细粒度化
VIPS 形成的视觉树,仅是大概提取URL 就业信息页面的基本布局信息,粗粒度的视觉块树先将噪声与正文整合在同一个块内,再实施细粒度化。利用样式节点与属性节点对形成的样式树实施标注。通过子元素的相似度分析已完成标注的块节点。二元组

在相关系数比较小时,需要分裂子节点,通过从上至下的层次遍历方式,实现初步分裂视觉树。
1.2.3 细节树剪枝
通过上述方法获取的是一颗基于样式的视觉树,对于样式与基本属性方面,已经不能细分,以基于样式的视觉树为基础,实施噪声的判断[10,11]。通过统计大量线上URL 就业信息页面发现,噪声区域的链接比通常多于正文区域,文本比较低,树距离较浅。这需要加入权重节点的概念,以从上至下的方式标注细粒度化的视觉块树,再剪枝处理权重低的节点。初次遍历时,可删除具有样式树节点内存在的键值对 position:fixed 与 display:none 的节点,实施一次简单的预处理,position:fixed 在网页内属于悬浮窗,display:none 在网页内属于不做显示的元素,根据观察很多网页的经验发现,position:fixed与display:none 均是判断噪声节点的主要依据。
剪枝算法的步骤为:
步骤1:得到样式树,假设Tj为样式树。
步骤2:循环处理样式树的各个节点Fj。
步骤3:如果一个节点的css(Cascading Style Sheets,层叠样式表)属性内存在position:fixed 与display:none 等键值对,就需要删除这个节点。
步骤4:计算出文本比与节点的距离深度后,计算权重值R(Fj)。
步骤5:循环处理样式树的各个节点FT。
步骤6:去除平级节点内权重较小的节点。
1.3 信息搜索算法
1.3.1 算法描述
利用基于超链接和标记文本的算法实现高校就业信息的搜索,具体步骤如下:
另一方面,销售成本的增加以及销售收入的降低都将导致企业毛利率的下降,米奥会展2016年较2015年度平均销售单价上涨14.79%,而平均单位销售成本上涨30.69%,其中单位宣传推广成本上涨136.98%;2017年较2016年度平均销售单价下降1.23%,同期平均单位销售成本上涨3.14%,单位宣传推广成本下降0.60%。由此可见,宣传推广成本的增加也是导致境外自办展毛利率下降的主要因素。
步骤1:将索引库内的就业信息网页当作图G,图G内各个文档B均有Authority 与Hub 两个值。其中,Authority 表示一个权威URL 就业信息网页的入度值,就是该URL 就业信息网页被其余网页引用的数量。一个网页的入度值与Authority 值成正比。Hub 表示一个URL 就业信息网页的出度值,就是该URL 就业信息网页指向其余网页的数量,可获取指向权威网页的链接集合。某一个网页的出度值与该网页的Hub 值成正比,Hub 网页具有隐含说明某一个就业话题权威网页的作用。优质的Hub 网页为指向很多存在很高的Authority 值的网页,优质的Authority 网页为通过数个很高的Hub 值所指向的网页。用A[B]代表Authority 值,用H[B]代表Hub值其中,网页集合是V。
步骤 2:初始化A[B]与H[B],获取A[B]=1 与H[B]=1。
步骤3:内容匹配,匹配所搜索关键字和链接中的标记文本,若匹配,那么对链宿网页赋予标记,再计算得到这个网页的权值weight(B),若不匹配,那么扫描在这个网页内的全部内容,再计算得到对应的权值weight(B)。
步骤4:归一化权值weight(B)。
步骤6:计算Authority 值与Hub 值的权值为
H[B]=weight(B)×H[B]
步骤7:归一化处理所计算得到的A值与H值,即
步骤8:如果A值与H值没有收敛的情况下,转到步骤5。
步骤9:设置Y为门槛值,同时选出A值与H值超过Y的全部网页和赋以标记的网页,按照排序输出搜索结果[12-14]。
1.3.2 文档相关度权值的计算
文档的相关度权值就是文档和搜索条件的相似程度,权值与相似程度成正比,权值越高,和文档相关性越高[15]。在搜索条件和超链接中标记的文本匹配情况下,依据N层向量空间模型算法,在逻辑上将一个文档划分成N个相对独立的文本段,通过文本段的内容构建文本特征向量与文本权值向量。超链接属于一个独立的文本段,能够通过N层向量空间模型算法计算各个URL 就业信息网页的权值,计算公式为:

式(3)中,G网页特征项hG的权值是WG,链接中标记文本的长度是L,G网页特征项hG在链接中出现的频率是hf G,那么第a条匹配的超链接权值为:

式(4)、(5)中,匹配的超链接条数是b,搜索条件内不同特征项数量是e。
在搜索条件和标记文本不匹配的情况下,扫描URL 就业信息网页全部内容,利用TF*IDF 方法计算文档的相似度,公式为:
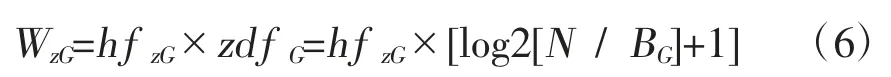
式(6)中,特征项hG表示文档dz的能力大小是WzG,特征项hG在文档dz内出现的频率是hf zG,文档集合中的文档个数是N,文档集合中出现特征项hG的文档个数是BG,特征项hG反比文档频率是zdf G。
根据式(6)发现,hf zG与WzG成正比,BG与WzG成反比,表示特征项可以代表文档的内容。
利用余弦公式计算全部URL 就业信息网页权值,第z篇文档和搜索条件Q的相关性是S(dz,Q),公式如(7)所示:
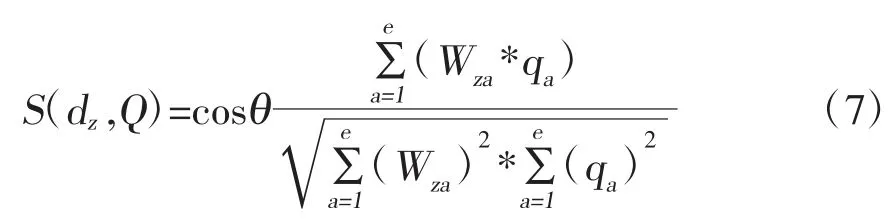
2 实验分析
从互联网中下载1 000 个网页为实验对象,将其平均分为10 组,每组包含50 个属于高校就业信息的网页,分析本文模型搜索高校就业信息的性能。
2.1 采集性能
采用本文模型与文献[5]模型、文献[6]模型在1 000 个网页中采集有关高校就业信息的网页,其中基于深度神经网络的搜索引擎点击模型构建与基于D-S 证据理论的信息检索模型研究,分别是文献[5]模型与文献[6]模型,表1 为三种模型的采集结果。

表1 三种模型的采集结果
根据表1 可知,本文模型能够有效采集到有关高校就业的网页,准确性更高。
2.2 去噪性能
利用可以同时兼顾准确率与召回率的F-measure 作为综合评价指标,测试三种模型对网页去噪处理的准确率,准确率公式为:

式(8)、(9)中,当前网页被抽取出的正文块是λ0;当前网页内全部的正文块是λ1;正文内抽取出来的信息块是λ2。
在F-measure 公式内β用于调整准确率与召回率的权重,实验中只需考虑网页抽取的准确率与召回率,故选择1 为β值,判断去噪效果的公式为:

利用三种模型对1 000 个网页实施去噪处理,图4、图5 与图6 分别为三种模型的去噪处理准确率、召回率与F-measure 值。
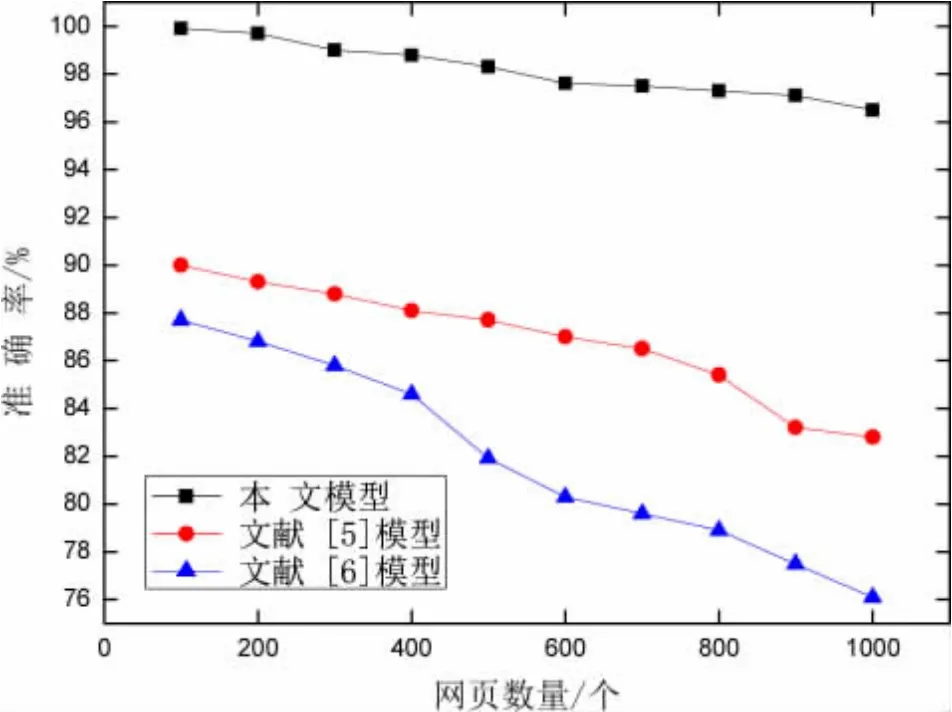
图4 三种模型去噪处理的准确率

图5 三种模型去噪处理的召回率

图6 三种模型的F-measure 值
根据图4、图5 与图6 可知,本文模型能够有效对所采集的高校就业信息网页实施去噪处理,去噪准确性更高。
2.3 搜索性能
评价就业信息搜索模型性能的主要指标是查全率与查准率。查全率为搜索到的相关高校就业信息网页和全部符合条件的高校就业信息网页数量的比例;查准率为搜索到的相关高校就业信息网页和搜索到的所有网页的比率。
利用三种模型搜索100 个文本文件中的高校就业信息,测试三种模型在Authority 值与Hub 值情况下的查准率与查全率,表2 与表3 分别是两种值情况下的查全率与查准率。

表2 Authority 值情况下的查全率与查准率

表3 Hub 值情况下的查准率与查全率
根据表2 与表3 可知,三种模型均是随着查全率的不断提升,呈现查准率逐渐降低的趋势。实验证明:本文模型的查全率与查准率均高于其余两种模型,能够有效克服主题偏离情况。
为分析本文模型的搜索性能,测试三种模型的排序误差率与查询速度,分别如图7 与图8 所示。

图7 三种模型的排序误差率
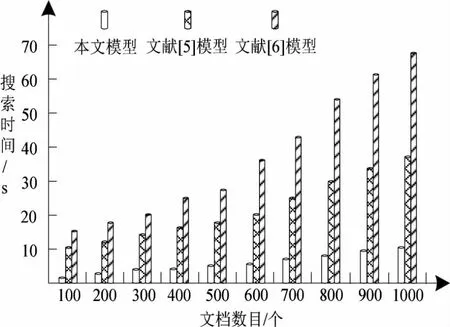
图8 三种模型的搜索时间
根据图7 可知,三种模型的排序误差率均随着文本文件数量的增加而增加,本文模型排序误差率的增加幅度明显低于其余两种模型。
根据图8 可知,随着文本文件数目的不断增多,三种模型的搜索时间均有所增长,本文模型的搜索时间增长得比较平缓,其余两种模型的搜索时间的增长幅度较大。
3 结论
搜索模型属于互联网中重要的信息采集工具,垂直搜索模型是第四代搜索模型,属于针对指定领域的搜索模型,比通用搜索模型更为专业。互联网时代高校就业信息垂直搜索模型,仅对垂直搜索模型实施了初步研究,日后在保证搜索准确率与搜索效率的同时,还可深入研究大学生的查询记录,挖掘大学生潜在的求职意向,优化搜索的排序结果。
