基于改进FCOS 的拥挤行人检测算法
2021-09-11齐鹏宇王洪元张继朱繁徐志晨
齐鹏宇,王洪元,张继,朱繁,徐志晨
(常州大学 信息科学与工程学院,江苏 常州 213164)
行人检测属于计算机视觉领域一个重要的基础研究课题,对于行人重识别、自动驾驶、视频监控、机器人等领域有重要的意义[1-3]。而行人检测领域在实际场景下面临着行人交叠、遮挡等问题,此类问题依然困扰很多研究者,也是目前行人检测面临的巨大挑战。
在现有的目标检测算法[4]中,两阶段目标检测器(如Faster R-CNN[5]、R-FCN[6]、Mask RCNN[7]、RetinaNet[8]、Cascade R-CNN[9])精度高但速度稍慢,单阶段目标检测器(如YOLOv2[10]、SSD[11])速度快但精度稍低。Zhi 等[12]认为锚框(anchor)的纵横比和数量对检测性能影响较大,在需要预设候选框的检测算法中,这些anchor 相关参数需要进行精准的调整。而在多数的两阶段算法中,由于anchor 的纵横比不变,模型检测anchor 变化较大的候选目标时会遇到麻烦,特别是对于小目标的物体。多数检测模型需要在不同的检测任务场景下重新定义不同的目标尺寸的anchor,这是因为模型预定义的anchor 对模型性能影响较大。在训练过程中,大多数的anchor 被标记为负样本,而负样本的数量过多会加剧训练中正样本与负样本之间的不平衡。基于无预设候选框(anchor-free)的检测算法容易造成极大的正负样本之间不平衡,检测的精度也不如anchor-base算法。而近年来的全卷积网络(fully convolutional network,FCN[13])在众多计算机视觉的密集预测任务中取得了好的效果,例如语义分割、深度估计[14]、关键点检测[15]和人群计数[16]等。由于预设候选框的使用,两阶段检测算法取得了好的效果,这也间接导致了检测任务中没有采用全卷积逐像素预测的算法框架。而FCOS[12]首次证明,基于FCN的检测算法的检测性能比基于预设候选框的检测算法更好。FCOS 结合two-stage 和one-stage 算法的一些特点逐像素检测目标,实现了在提高检测精度的同时,加快了检测速度。
由于拥挤场景下行人目标会出现交叠、遮挡和行人目标偏小等问题,本文提出新的特征提取网络提取更具判别性行人特征。对于FCOS 检测算法,行人检测中行人尺度问题对模型性能的影响较大,针对该问题,本文改进多尺度预测用于检测小目标行人,有效地解决了行人目标偏小、拥挤等场景下行人检测精度不高的问题。
1 相关工作
1.1 FCOS 框架
FCOS 首先以逐像素预测的方式对目标进行检测,无需设置anchor 的纵横比,然后利用多级预测来提高召回率并解决训练中重叠预测框导致的歧义,这种方法可以有效提高拥挤场景下行人检测精度,缓解行人拥挤而导致的检测困难的问题。实际上,诸如Unitbox[17]之类基于DenseBox[18]的anchor-free 检测算法,难以处理重叠的预测框而导致召回率低的问题,该系列的检测算法不适合用于一般物体检测,FCOS 的出现打破这一局面。FCOS 表明,使用多级特征金字塔网络(feature pyramid networks,FPN[19])预测可以提高召回率,提高检测精度。
FCOS 在训练中损失定义如下:

式中:x、y表示特征图上的某一位置;px,y表示预测分类分数表示真实分类标签;tx,y表示回归预测目标位置表示真实目标位置,Lcls是Focal Loss 分类损失,Lreg是IOU Loss 回归损失,并且在预先的实验中发现,拥挤行人检测任务中,I OU Loss效果要稍优于GIOULoss[20]。Npos表示正样本的个数,表示激活函数,当时为1,否则为0。
此外,FCOS 还具有独特的中心度分支预测,可以抑制低质量框的比例。由于逐像素预测,很多像素点虽然处于真值框内,但是越接近真值框中心的像素点预测出高质量预测框的概率也越大,因此提出预测中心度损失函数,如式(2)所示:

式中:l∗、 r∗、t∗、b∗分别表示当前像素点到真值框边界的距离,这里使用开方来减缓中心损失的衰减。中心损失值在范围[0,1],因此使用二值交叉熵(BCE)损失进行训练,将中心度损失加到训练损失函数式(1) 中。当回归中心在样本中心时,中心度损失会尽可能的接近1,而当偏离时,中心度损失会降低。测试时,通过将预测框的中心损失与相应的分类分数相乘来计算最终分数,且该分数用于对检测到的预测框质量进行排序。因此,中心度可以降低远离目标中心的预测框的分数,再通过最终的非极大值抑制(non-maximum suppression,NMS)过程可以过滤掉这些低质量的预测框,从而显著提高行人检测性能。相比基于预设候选框的一类检测算法,FCOS 算法实现更好的检测性能。
1.2 原始FCOS 特征提取网络
如图1 所示,FCOS 算法的特征提取网络采用主干网络(Backbone) 加上FPN,Backbone 选用ResNet[21]提取特征,在FPN 中,P3、P4、P5分别由C3、C4、C5横向连接产生,P6、P7由P5、P6通过步长为2 的卷积产生。每层检测不同尺度大小的目标,Pi层检测当前像素点处满足条件的目标,目标公式定义如下:
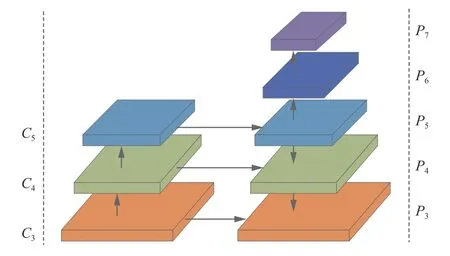
图1 FCOS 特征提取网络Fig.1 FCOS feature extraction network

式中:l∗、r∗、t∗、b∗分别表示当前像素点到真值框边界的距离;[mi−1,mi]表示Pi层回归目标范围,m2、m3、m4、m5、m6和m7分别设置为0、64、128、256、512 和 ∞,其中 ∞ 表示无穷大。这是一个非常有创造性的想法,这样的设计使得FCOS 检测算法是一个多尺度的FPN 检测算法。
2 基于FCOS 的行人检测
2.1 主干网络VoVNet
深度学习中,特征提取网络对于模型有着非常大的影响,针对不同的数据集可以直接影响其检测性能。针对ResNet 不足,本文运用VoVNet作为行人特征的提取网络。
DenseNet[22]在目标检测任务上展示出了较好的效果,特别是基于anchor-free 的目标检测模型,这是因为相比于ResNet,DenseNet 通过特征不断叠加达到好的效果,其缺点是在后续特征叠加时,通道数线性增加,参数也越来越多,模型花费时间增加,影响模型速度。
VoVNet 认为在特征提取方面,中间层的聚集强度与最终层的聚集强度之间存在负相关,并且密集连接是冗余的,即靠前层的特征表示能力越强,靠后层的特征表示能力则会被弱化。VoVNet[23]针对DenseNet 做出改进,提出一种新的模块,即一次性聚合(one-shot aggregation,OSA) 模块。OSA 模块将当前层的特征聚合至最后一层,每一卷积层有两种连接方式,一种方式是连接至下一层,用于产生更大感受野的特征,另一种方式是连接一次至最终输出的特征图上,与DenseNet 不同,每一层的输出不会连接至后续的中间层,这样的设计使得中间层的通道数保持不变。VoVNet采用更加优化的特征连接方式,通过增强特征的表示能力,提高特征的提取能力,进而提高模型的检测性能。
2.2 SE 模块
本文为了更好地契合复杂的行人特征,在VoVNet上使用SE 模块[24]加强特征表示能力,并且在特征图上使用SE 模块进行权重分配,使得深度特征更加多样化。
SE 模块首先依照空间维度来进行特征压缩,将每个二维的特征通道变成一个实数,输出一个二维空间,它的维度与特征通道数相等,即二维空间表示对应特征通道上的分布结果。之后生成一个具有权重的二维空间,表示特征通道间的相关性。最后将对应的特征图乘上权重特征,实现一个特征的权重分配,突出重要的特征,完成在通道维度上对原始特征通道上重要性的重标定。
SE 模块类似于注意力机制,本文将其使用在VoVNet 上,如图2 所示,在每层特征下采样时,将特征进行SE 权重分配。根据VoVNet 的特征连接方式添加SE 模块权重机制,本文方法可以提供更加多元化的特征,使得行人特征更好地表达,提高行人检测的精度。并且SE 模块可以在几乎不增加模型时间复杂度的情况下提升模型的检测性能。
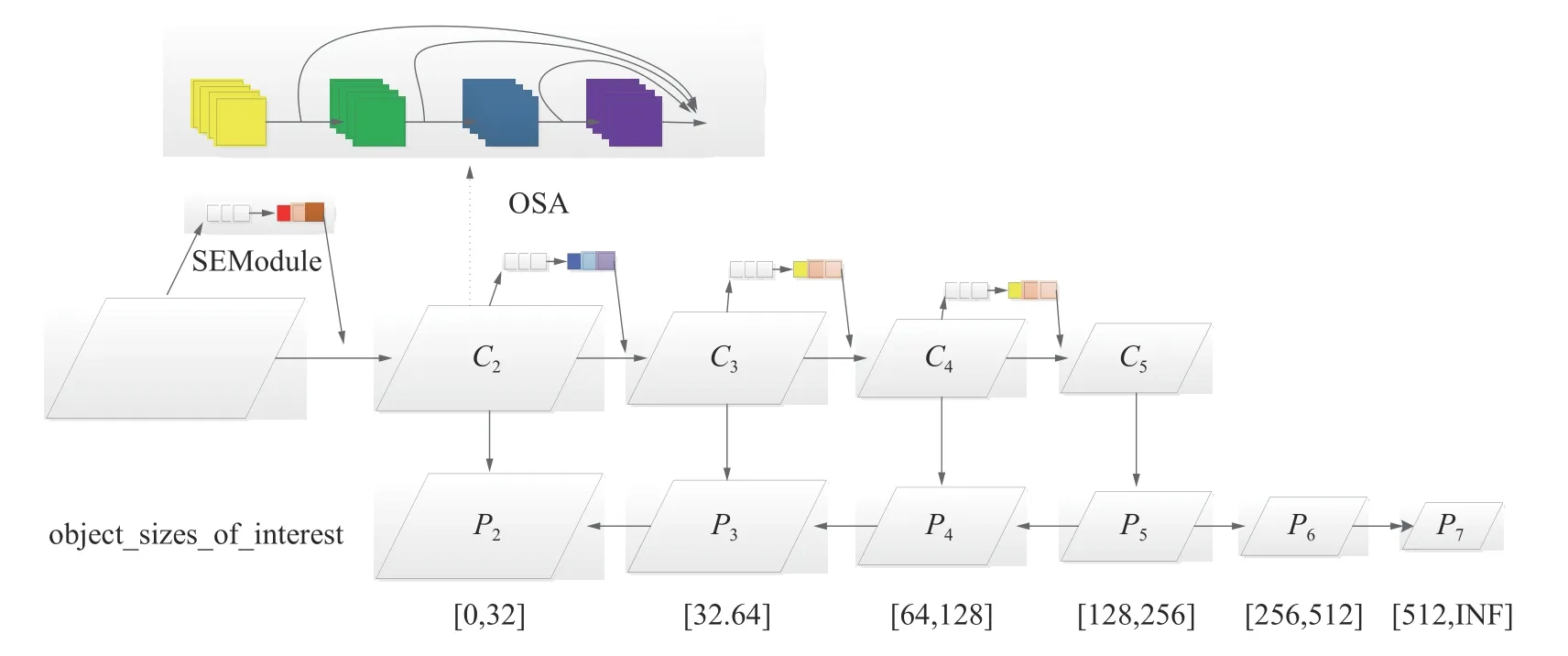
图2 修改后框架Fig.2 Update framework
2.3 多尺度检测
原始模型FPN 采用5 层不同尺度回归目标,这5 层尺度回归的目标大小分别为[0,6 4]、[64,128]、[128,256]、[256,512]和[512,∞],分别对应FPN 中的P3、P4、P5、P6和P7。针对行人目标的特点,本文发现,不论是在常用的行人数据集中,还是在真实检测场景中,行人检测的难点在于拥挤行人和小目标行人的检测。对于FCOS 模型,每层每个像素点都会回归固定尺度大小范围内的目标。相对地,如果目标行人拥挤在某个尺度范围内,将会使得检测层的任务过重,导致检测效果降低,此问题也是影响模型性能效果的原因之一,在多目标检测场景中会导致FCOS 模型的检测性能稍有降低,同时也说明,当检测任务复杂,检测目标数量较多时,本文提出的多尺度检测会使FCOS 检测性能提高。
如图2 所示,减小P3层的回归尺度,设置P3层回归尺度为[32,64],减少P3层的检测任务量;增加P2层,P2层由C2层横向连接和P3层向下连接组成,P2层回归尺度为[0,32]的目标,这样的网络设计既能减少P3层的回归目标数,也能更好地利用特征检测小目标行人,提高行人检测精度。在最终的FPN 上,本文的方法在FPN 上拥有6 层特征图以检测6 个不同尺度范围的目标。
总体网络框架如图3 所示,相较于未改进FCOS 算法,预测特征图由5 个增加到6 个,而后对特征图上每个点进行逐像素预测,每个点均需预测目标回归框、目标类别、目标中心度,以上3 种预测结果对应图3 中3 个预测分支,假设当前特征图大小为W×H,则有W×H像素点需要进行预测。

图3 总体框架Fig.3 Final framework
3 数据集和评估
本文实验主要使用CrowdHuman[25]和Caltech 行人数据集。行人数量多、场景拥挤是行人检测中一个巨大的挑战,针对这一问题,旷视发布CrowdHuman 数据集,用于验证检测算法在密集人群行人检测任务中的性能。CrowdHuman 数据集中15 000、4 370 和5 000 个图片,分别用于训练、验证和测试。针对CrowdHuman 数据集,本文只使用全身区域标注用于训练和评估,由于还未公布测试集,参考相关文献[25-26]后,实验结果在验证集上进行测试。Caltech 行人数据集时长约为10 h 城市道路环境拍摄视频,数据集中随机分配训练集、测试集、验证集,其对应比例为0.75∶0.2∶0.05,3 个集相互独立,测试集图片约为24 438 张。
本文采用MR−2(miss rate)和AP 的评估准则,MR−2表示在9 个FPPI(false positive per image)值下(在值域[0.01,1.0]以对数空间均匀间隔)的平均丢失率值,FPPI 定义如下:

式中:N表示图片的数量;FP 表示未击中任意一个真值框的预测框数量。MR−2是目前衡量行人检测一个非常重要的指标,也是本文主要采用的评价指标。其数值越低说明行人检测模型性能越好。
AP 表示平均精度,PR(Precision-Recall)曲线所围成的面积即为AP 值大小,AP 值越大检测精度越高,其中AP、Recall、Precision 计算公式如下:

式中:TP 是检测出正样本的概率;FN 是正样本检测出错误样本的概率;FP 是负样本检测出正样本的概率。
4 实验
本文实验环境为Ubuntu18.04、Cuda10 和Cudnn7.6,使用4 块2080Ti 的GPU,每个GPU 有11G 内存,由于FCOS 算法要求较高,存在内存不够的问题,实验通过线性策略[27]调整了batch_size 大小和IMS_PER_BATCH 的数量。其余参数沿用FCOS 在COCO 数据集上基础参数配置,算法基于detectron 框架。
4.1 CrowdHuman 数据集实验结果
如表1 消融实验所示,其中6stage 表示多尺度检测方法,SE 表示SE 模块。在FCOS 上采用VoVNet 作为Backbone 起到了极大的提升作用,相较于主干网络为ResNet,AP50提升11.2%。在FPN 中多添加一个尺度的回归层,对于行人检测的效果有极大的提升,这是因为密集的行人检测受尺度变化影响较大。相较于原始FCOS 方法,本文方法在指标AP50上提升了15.0%。针对于不同主干网络,S E 模块在指标A P50上有0.2%~0.3%的提升,说明SE 模块能增强行人特征提取能力。模型由5 个尺度增加到6 个尺度,指标AP50提升3.5%,并且对于模型检测小目标行人有着极大的提升,可以看到指标APS提升8.5%,实验结果也印证多尺度改进能有效地提升模型检测小目标行人的性能。

表1 CrowdHuman 数据集APTable 1 AP on CrowdHuman
CrowdHuman[25]数据集中采用指标MR−2,本文采用相同指标并对比了CrowdHuman[25]中部分实验,表2 可以看到,在CrowdHuman 数据集上,通过消融实验表明:采用VoVNet 相较于采用ResNet,指标MR−2降低26.91%。拥有SE 模块的检测模型相较于没有SE 模块的检测模型,指标MR−2降低0.9%。改进多尺度回归后的检测模型相较于未改进的检测模型,指标 MR−2降低6%。本文提出的方法相较于原始方法,指标MR−2降低了33.62%。实验结果证明,本文的方法在拥挤场景下的行人检测效果提升较为明显。

表2 CrowdHuman数据集MR−2Table 2 MR−2onCrowdHuman
如表3 所示,针对CrowdHuman 数据集,NMS 的IOU 阈值设定也是不同的,原始FCOS 算法在COCO 数据集上IOU 阈值设置为0.7,而针对拥挤行人场景,本文发现IOU 阈值设置为0.5 时,模型整体性能较好。图4(a)表示PR 曲线图,图4(b)表示MR-FPPI 曲线,可以清晰地看到本文方法总体上提升较大。在采用了VoVNet后,对模型性能有了极大的提升,说明VoVNet 更加适合于FCOS 在拥挤场景下提取行人特征。多尺度检测方法在拥挤场景下的行人检测也是有效的,提升效果明显。
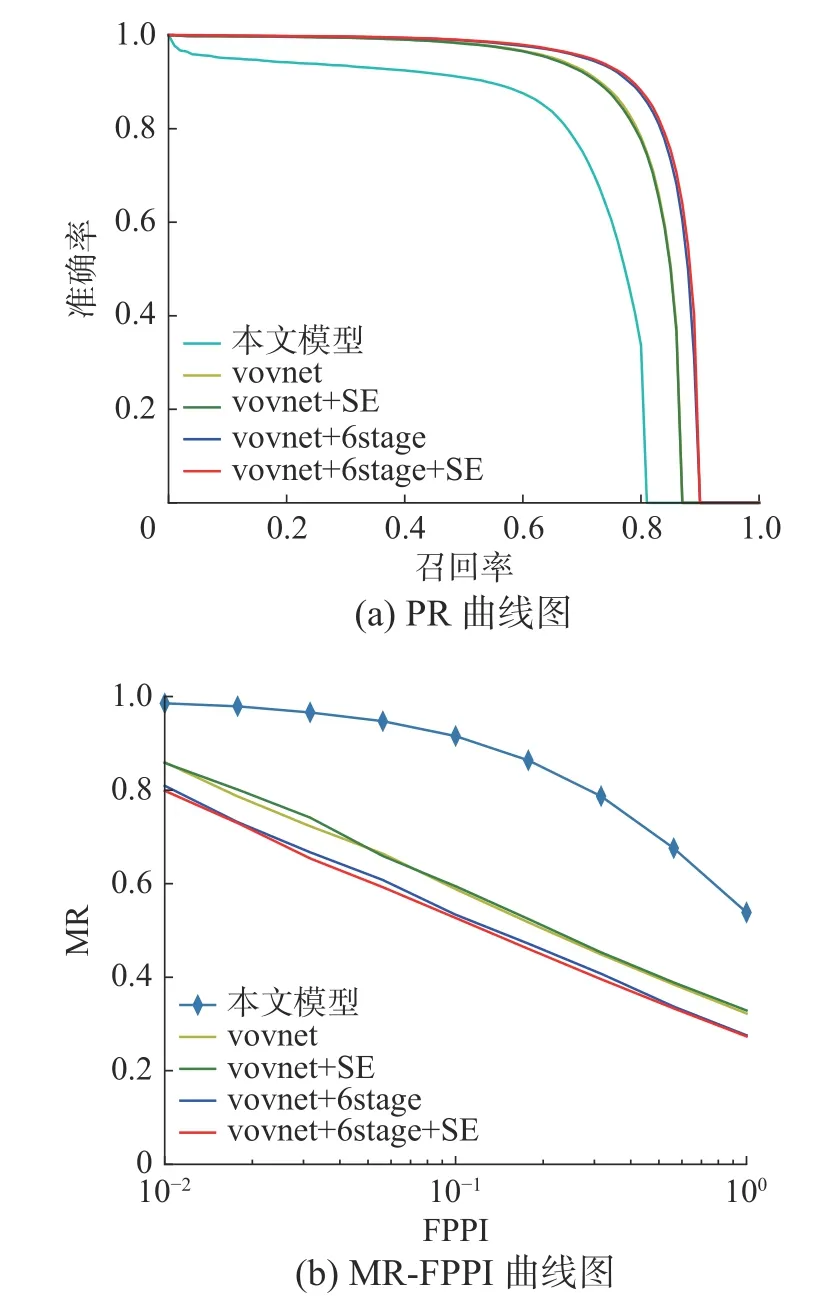
图4 CrowdHuman 曲线图Fig.4 CrowdHuman curves
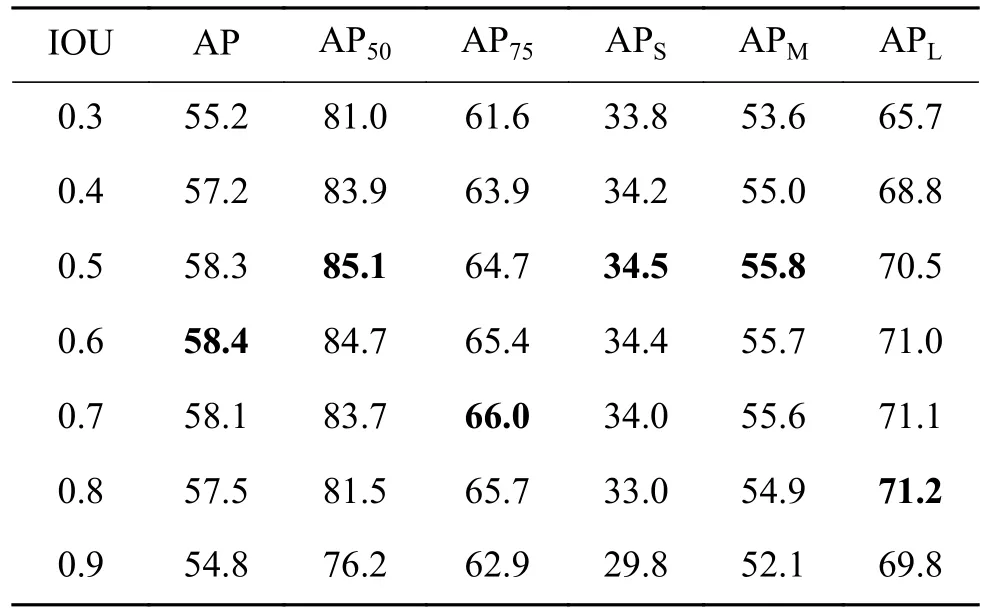
表3 CrowdHuman 数据集IOU 阈值Table 3 IOU threshold on CrowdHuma
4.2 Caltech 数据集结果
如表4 所示,在车载摄像头的行人数据集Caltech 上本文提出的方法也有一定提升,相较于原始YOLOv2 方法,AP 实现了2% 的提升。在Caltech 数据集上的提升,说明本文模型的鲁棒性较好。

表4 Caltech 行人数据集Table 4 Caltech pedestrian datasets
4.3 实际场景检测结果
本文的模型使用CrowdHuman 训练集进行训练,在实际场景下的检测也有不错的效果,本文挑选出实际场景下一张室内行人和一张室外行人进行检测。因为本文算法无需设置anchor 的尺寸和纵横比,所以在实际场景中的行人检测鲁棒性较好。如图5 所示,图5(a)、(c)表示原始FCOS 方法在拥挤行人中的效果,图5(b)、图5(d)表示本文方法的最终效果,可以看到,原始FCOS可以较好地检测出图片中的行人,漏检率较低,但是仍存在伪正例,相比于图5(b),可以看到图5(a)右上角小目标行人未检测出来,远处的行人检测效果也不如图5(b)的检测效果,而相比于图5(d),可以看到图5(b) 右边出现置信度为0.64 的错误预测框。本文提出的方法可以较好地检测行人,减少FP 出现的情况,在实际拥挤场景下能较好地检测目标行人。但当行人目标交叠时,或者对于有遮挡的行人,检测的效果大部分仅能检测出可视的部分,无法将全身区域标注出来,导致与真值框交并比的值较低,被视为负类。这也是目前本文方法面临的主要问题之一。

图5 实际场景检测效果Fig.5 Actual scene detection effect
5 结束语
针对行人目标检测中行人拥挤、目标偏小等问题,本文提出一种基于FCOS 框架的行人检测算法。通过融入新的 Backbone 并且在 FPN 中添加一层P2层,实现行人目标的多尺度检测。通过融入SE 模块进行特征的权重分配,更好地提取行人特征,提高行人检测精度。本模型方法无需设置anchor 纵横比等参数,参数设置少。相较于目前先进方法,可以达到有较强竞争力的检测效果。在实验中也发现,本文提出的方法受行人深度特征影响较大,如何在拥挤遮挡等实际场景下进行更高精度行人检测是我们进一步要研究的内容。
