一种面向电力的智能分词方法
2021-09-11江苏省电力有限公司张首魁仇晨光李艺丰崔占飞梁文腾李彦柳
江苏省电力有限公司 张首魁 仇晨光 李艺丰 曹 帅 崔占飞 梁文腾 李彦柳
随着信息化水平的不断提升,搜索引擎的不断发展,作为其基础的各种中文分词算法的应用越来越成熟和广泛。目前主流的中文分词方法很多,算法也各不相同。但成功将分词方法应用于电网调度的案例很少,这一方面是由于电网信息系统的安全要求很高,不能直接连接到信息外网,导致很多依赖于互联网的分词算法无法得到应用;另一方面是因为电网调度中所使用到的很多电力词汇、设备命名无法被大众化的分词算法所解析。
1 主流中文分词方法
1.1 主流中文分词现状
中文分词技术属于自然语言处理技术范畴,目前主流的中文分词方法主要包括三种:
基于规则的分词方法是按照一定的策略将待分析的汉字串与一个“充分大的”机器词典中的词条进行配,若在词典中找到某个字符串则匹配成功。其常用的方法包括正向最大匹配法、逆向最大匹配法、最少切分法、双向匹配法等。然而在这种模式下的分词结果精度还远不能满足实际需要,在此基础上还需使用一系列的方法来改进,如特征扫描或标志切分或词类标注辅助决策等,这是目前使用较多的分词方法。
基于理解的分词方法是在分词的同时进行句法、语义分析,利用句法信息和语义信息来处理歧义现象,通常包括分词子系统、句法语义子系统、总控部分。在总控部分的协调下,分词子系统模拟了人对语句的理解过程。这种分词方法需使用大量语言知识和信息。由于汉语语言知识的笼统、复杂性,很难将语言信息组织成机器可直接读取的形式,因此目前基于理解的分词系统还处在试验阶段。
基于统计的分词方法按照字与字相邻共现的频率或概率反映成词的可信度,从而可对语句中相邻共现的各个字组合的频度进行统计,计算它们按照指定顺序共同出现概率,然后提取出出现概率最高的词汇,进一步完成分析。为减少在此过程中识别的无意义词汇,统计分词系统要使用一部基本的分词词典进行串匹配分词,同时使用统计方法识别一些新词,即将统计和串匹配结合,既发挥匹配分词切分速度快、效率高的特点,又利用了统计分词结合上下文识别生词、自动消除歧义的优点。目前任何一个成熟的分词系统来说,不可能单独依靠某一种算法来实现,都需综合不同的算法[1]。
1.2 主流中文分词电力应用
目前,以上所描述的几种主流中文分词方法不能很好的应用于电力系统中,这一方面是由于电力系统的安全性要求,电力分词只能是在局域网的范围内实现;另一方面电力词库是不定的、无意义的、可扩展的,同时分词效率要求很高。以调控智能操作票系统中所使用到的针对电网操作术语为例。以常见的电网操作术语“德安1234线由运行转热备用”进行分词说明,为支撑后续的电网操作校核,需将本术语按照规则“{线路}由{初始状态}转{末状态}”解析出其中所包含的设备、状态、动作信息。
在综合使用常见的分词方法后,在不使用设备库的情况下其分词结果是“德/安/1234/线/由/运行/转/热备用”,设备信息存在错误,这是由于德安1234线是设备名称,并不是常用词汇。在使用设备库作为词库后可得到正确分词结果。然而由于设备库的词汇量太大,一般都在10W 级,造成了分词的效率较低或内存使用率太高,这些都是不合理的,基本不能满足当前电力系统的使用需要。同时,在进行相应的分词后无法对分词的结果进行语义化的分析,获取出其中所需的设备等信息,所以还不足以很好支撑后续的智能化应用[2]。因此需研究一种面向电力的智能分词方法,在电力内网范围内进行智能分词的同时,获取分词结果中各个词汇的语义结果,从而进行后续的分析。
2 电力智能分词实现
2.1 实现目标
本文提出一种基于规则库进行电力语义分析的智能分词方法,在准确、高效的前提下使分词结果中的内容带有语义识别,可在后期进行理解,从而支撑后续的智能化应用。按照电力系统的场景要求,这种智能分词必须做到:
高效。效率是智能分词算法的一个重要评价指标。目前在电力应用环境下,智能分词作为一系列高级应用的基础,在词库无法精确确定的情况下也要求分词结果能在毫秒级实现;设备库可扩展兼容。随着电网的快速发展,越来越多的设备在进行投运、退运等。按照电网设备的命名规则,设备名称基本上都是新的,没有办法在现有任何词库中找到。这是一个持续性的过程,这就需要在本智能分词方法中提供一种设备库的扩展规则,并在设备库扩展变化的同时,对分词的效率基本不能造成影响。
生词自动提醒。在电网进行智能分词的过程中,对一些可能的生词需及时进行提醒,从而促进词库的更新。如“将AB 线由运行转热备用”,在分词完成后需提示用户“AB 线”是否是一个新的设备,如确认后需自动将其作为一个新词进行处理;分词结果含语义。对于智能分词的结果,各个词汇段需要包含其含义,比如操作术语“将AB 线由运行转热备用”进行分词之后,需在结果中将“AB 线”作为设备,“运行”、“热备用”作为状态,“转”作为动作进行处理,从而为后续的模拟演示、高级校核等功能提供更好的支撑。
2.2 分词设计
在电力系统中,与外部系统很不相同的是各种术语都是规范化的、有规律的。因此,在本文中基于电力系统的语言规则设计出一种智能分词方法。分词的步骤如下:读取电力语言规则库,并将其以树形结构进行表达;预处理阶段按照电力规范化词汇将语句中的各类别名等替换成为标准命名,同时将待分词的段落按标点符号打散成句子;将各个句子在树状结构中遍历,进行关键词匹配,从而找到该句所对应的规则;按照该电力规则对语句进行分段,从而得到词汇组,以及该组中各个词汇的属性含义。在这种分词设计中,其字符匹配效率是线性的,同时也是可以随时进行扩展的,分词的结果中各个词汇也都能具备各自的含义。
2.3 分词关键点
2.3.1 电力规则树
在电力语言的智能分词过程中,需读取电力语言的规则库,建立规则树。电力规则的语言描述是使用术语结构,如:“将{线路}由{初始状态}改为{末状态}”、“{开关}由{初始状态}转{末状态}”、“断开{开关}”等。其中“{线路}”、“{开关}”是设备;“{初始状态}”、“{末状态}”是状态;“转”是动作等规则各个分段的含义已经适用分词属性库进行描述。上述规则可以读入到规则树中,规则树的根节点是一个虚拟节点,第一层子节点则是各个规则的第一个部分,后面依次是各个部分。这三条规则在规则树中可以描述如图1。
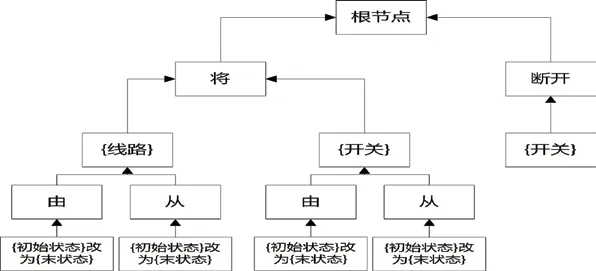
图1 规则树建立
图1所示,在电力规则库读取完成后可形成完整的规则树。在这个树中包含了所有需使用到的电力术语规则,所有的电力系统中需使用到的术语都可在这个树中找到对应的节点路径。
2.3.2 规则匹配
在规则树建立完成后,可将具体的电力语句与规则树中的规则进行匹配。匹配的规则是使用递归的形式进行实现,具体如下:首先读取规则树的第一层节点,与语句的开头进行比较,如果相同,则将语句的开头部分去除之后与该相同节点的子树进行比较。如果没有找到相同项目,则读取规则树中以不规则项如“{线路}”等开头的节点的子树的第二层节点,找到固定项并与本语句中的内容进行比较,找到所有对应项并对每一个对应项的子树与子语句的对应关系进行比较,直到找到最接近项,从而最终实现语句与规则之间的对应。2.3.3 按规则分词
在规则与语句间实现了对应后,可按照规则实现对语句的分词。在此分词的实现过程中可按照关键字进行分段分词,也可与现有依赖于词库的主流中文分词方法进行结合,从而得到对应的分词结果。由于在规则库中已描述了具体规则的每一个分段的含义,所以,分词的同时已完成了生词的识别及分段中内容属性含义的识别。因此分词的结果中已能够包含设备、状态、动作等具体的情况描述,从而更好的支撑电网系统中的各个高级应用[3]。
综上,随着信息化水平的不断提高,电力产品需要实现智能化,但主流中文分词方法在效率、词库建设等方面不能完全满足电力系统的智能化的基础需要。本文提出一种面向电力的智能分词的实现,贴近电力系统的要求,更加高效的为电力系统中的高级智能化应用提供支撑,但该方法的成效还需与实际结合不断进行完善和应用。