卷积神经网络在中医舌象分类中的应用研究
2021-09-10于飞
摘要 目的:探索将卷积神经网络技术应用于舌象照片分类任务的方法,从而实现机器学习模型对中医临床舌诊行为的模拟。方法:使用人工标注后的舌象照片数据集分别对YOLO和EfficientNet卷积神经网络模型训练。我们在训练过程中综合调试了各类校正算法与超参数,两模型成功提取图片数据中的模式特征并形成不同特征映射, 使YOLO和EfficientNet分别实现实时舌体识别和中医学舌象特征分类的功能。结果:深度学习模型对部分舌象特征典型的舌诊照片识别精度较好,对芒刺舌、裂纹舌、齿痕舌的识别精确率分别为0.86、0.75和0.72。结论:卷积神经网络模型对几种特征性舌象的识别能力较好,但对舌色、舌形、津液情况多分类的识别尚不理想,尚需进一步改善使用舌诊照片训练卷积神经网络模型的方法。
关键词 中医学;人工智能;机器学习;深度学习;卷积神经网络;舌诊;舌象
随着人们保健意识日益增强,人们期望能够随时随地了解自己的健康情况,移动医疗的研发项目也大量应运而生。近年来医疗信息数据库的逐步建立和完善,网络传输的信息吞吐量提升,计算机硬件运算能力的提高,数据分析(Data Analysis, DA)与机器学习(Machine Learning, ML)算法的更新,都使移动医疗从概念走进现实。
中医药学在治未病(亚健康状态)领域经验丰富,在症状的识别与保健方法上具有独特优势。疾病或亚健康的治疗及保健效果都需建立在可靠诊断的基础上,中医诊断中历来强调四诊合参、辨证论治,也就是说,诊断的确定需建立在望、闻、问、切四种方式获得的临床资料之上。舌诊是望诊的组成部分,医生舌诊时所见的舌体及舌苔特征称为舌象,舌诊照片保存了舌象全部的资料,是我们本次研究的数据来源。医生根据舌象对病情判断的准确度与判读人员的经验、知识水平和视觉敏感度相关,不同医生对同一舌象的判读结果可存在较大差异0。对主观因素对临床资料解读影响程度的评估方法,一直是中医诊断客观化的难题。
本次研究尝试通过将DA与ML等数据处理技术,对舌诊照片中潜在的数据特征进行识别和提取,计算机图像处理研究人员发现,卷积运算可保证图像中浅层特征充分识别和提取的前提下,大幅降低计算复杂度,现已成为计算机视觉常用的图像特征提取方法。人工智能近年来的突破都与人工神经网络(Artificial Neural Network, ANN)的发展密切相关,ANN由大量的人工神经元联结、计算有关,ANN在输入数据信息后,不断自适应地根据输入数据的统计学特征非线性地改变内部权重,构造出局部或全局最优的模型。本研究以ANN与卷积运算结合后的卷积神经网络(convolution neural network,CNN)为基础,通过有监督的ML数据建模。因此,用于图片对象识别和分类任务的模型权重调整不仅依赖于图像语义特征的运算结果,还会受人工标注者主观因素的影响。模型训练完毕后,我们将评估卷积神经网络模型自主舌诊图片识别和分类的精确度,分析不足之处,为进一步完善模型的配置和训练方式奠定基础。
近年来,中医药学与卷积神经网络技术结合应用于舌诊机器分类的试验研究已获得一定进步,董竞方0通过将CNN网络ResNet50应用于对442例肿瘤患者舌象图片的学习,获得齿痕舌、瘀斑舌自动识别模型,F-1达到91.88%。刘梦0通过Faster R-CNN与微调(fine tune)技术应用于构建齿痕舌、裂纹舌识别模型,对裂纹舌识别F-1为97.1%,对齿痕舌识别F-1为85.1%。
1 资料
研究的舌象照片来自网络爬虫程序,共计6373张。将全部照片分为两个数据集,分别用于舌体识别模型与舌象分类两个模型的训练与测试。识别模型数据集3500张,分类模型数据集共2873张。
2 方法
2.1数据预处理
2.1.1标准化 为了保证全部图片符合CNN模型输入尺寸要求,我们对舌象照片给予等比例缩放,并对照片的留白部分灰色填充。
2.1.2归一化 为保证模型的稳定性和训练效率,我们对图片数据进行归一化处理,参考ImageNet图库中的统计数据,RGB三个通道均值为0.485、0.456、0.406,标准差为0.229、0.224、0.225。
2.1.3数据扩增 为了降低模型权重对训练集中数据的过拟合风险,增加其泛化能力,可对数据集中数据进行多重处理,增加图片中信息的离散性,使训练集中数据更加贴近现实的情况。
2.1.4数据集分割 我们采取打乱数据集中图片顺序后,按比例分割的方法对数据集分割为训练集、验证集和测试集。舌体识别模型训练集:验证集为17:3,舌象分类模型训练集:验证集:测试集为4:1:1。
2.2 CNN模型 YOLO-v4和EfficientNet模型是当前先进的图像处理卷积神经网络模型,其架构先进,与多种先进算法适配,无论在性能和精度上均处于先进水平。其中,YOLO-v4模型運算速度快,分类精度差,适用于舌体识别,EfficientNet-B2模型分类精度高,运算速度慢,可用于舌象分类。CNN可以很好地对图像信息的特征进行提取和层层处理后,计算某图片对不同分类的多重Logistic回归结果,从而获得概率估值,估值与阈值结合后判断图片的分类结果。
2.3 模型训练 为了提高训练效率并充分利用模型初始权重所包含的预训练集数据信息,训练过程联合使用转移学习与冻结学习的方法,YOLO-v4模型训练的第1~10期(epoch)冻结浅层,第11~200期解冻全层。
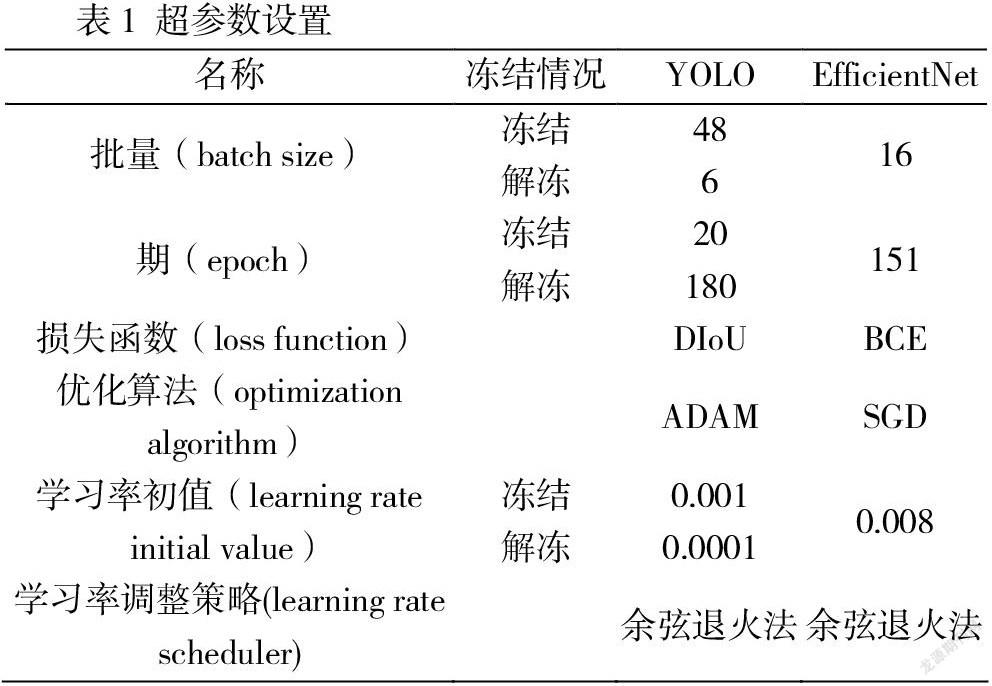
2.4 超参数设置
批量(batch size)是数据集每次批量输入模型的一次性样本量,每次迭代模型内权重更新的方向和参数受每批数据信息影响,批量较大时模型权重调整更准确,批量较小时,损失函数可能出现难收敛的问题。在满足计算机元件满载运行的前提下,适当提高批量至合适的大小。损失函数(loss function)是用来计算评估所建立数学模型与现实世界数据间差距的函数。优化算法(optimization algorithm)是通过调整模型参数使损失函数逐步逼近最优解的计算方法,包括对前次迭代模型参数数据的处理以及新参数调整幅度的计算。为了保证收敛和效率的平衡,本次试验对两个模型均应用余弦退火法(cosine anealing)的学习率调整策略(learning rate scheduler),利用余弦函数曲线特点,使学习率随训练迭代次数而改变,呈先缓、再速、终缓的速率变化特点。
2.5 训练结束 经反复调试,将第115期的模型权重作为最终权重。
2.6 判定阈值 一般来说,输入图片对某分类的Logistic回归结果越高,图片更可能归属于该分类,概率阈值一般定为0.5。为了保证图片在各分类维度下都有明确的归类,本研究将各分类维度下的最高概率值定为分类阈值。
3 结果
3.1 测试指标 为了评估模型对训练集外舌诊照片的分类精度,反映模型对现实数据集的分类精度,我们对比了模型与普通医生在测试集分类结果上的差异性。精确率(precision)越高,我们对分类阳性结果的把握越大;召回率(recall)越高,我们对阴性分类结果的把握越大,F-1是精确率、召回率的调和平均数,用于综合评估模型分类准确度。
3.2 分类标签 以中医诊断学中的类型划分标准为基础,同时考虑到中医临床辨证的需求后,对舌诊照片的分类标签设置为两层,第一层分类将舌象特征划分为几个维度,分别为舌色、舌形、苔色、苔厚度、津液情况、齿痕舌、裂纹舌、芒刺舌8种。第二层分类在第一层的基础上进一步划分,舌色分为淡白舌、淡红舌、红舌、绛舌、青紫舌5种;舌形分为痩薄舌、正常舌、胖大舌3种;津液情况分为燥苔、润苔、滑苔3种;苔厚度分为厚苔与薄苔;苔色分为黄苔与白苔;齿痕舌、裂纹舌和芒刺舌均分为有、无两类0。
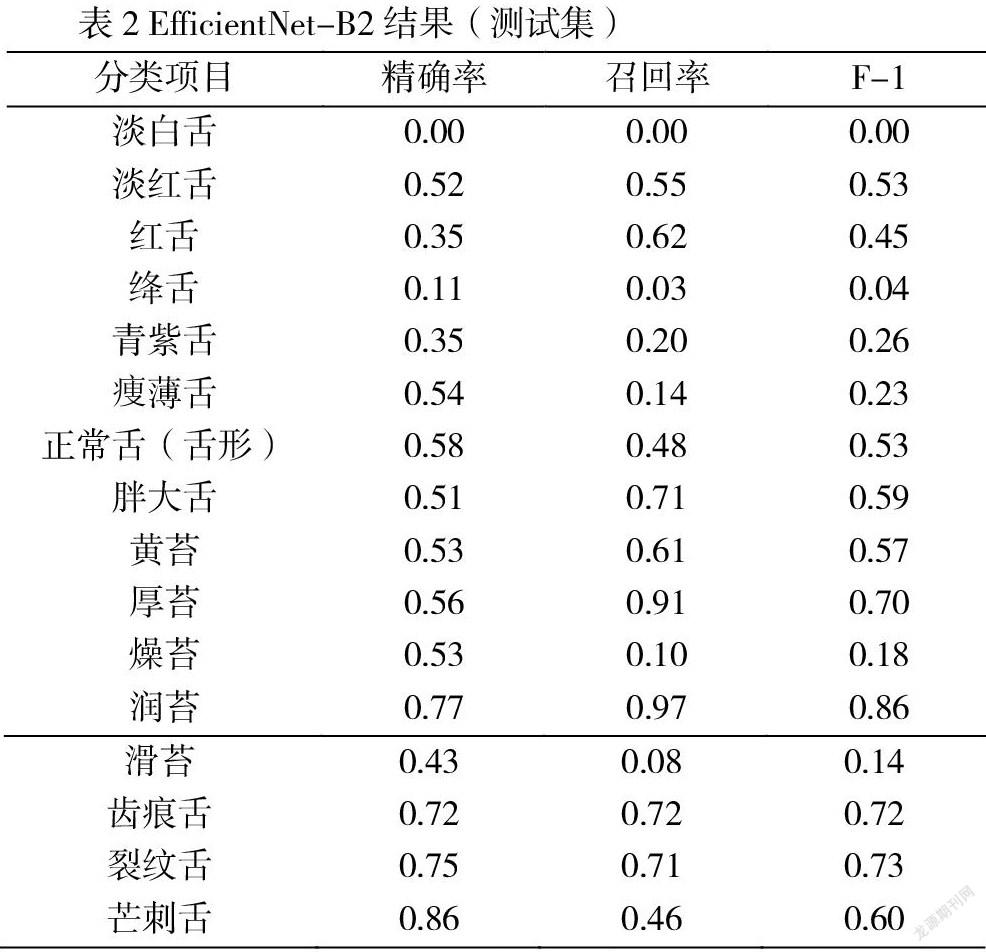
3.3 测试结果
EfficientNet-B2模型对五分类精确率最差,三分类精确率次之,二分类项目精确率最好。模型对舌色分类淡红舌的识别最好(F-1为0.53),但无法识别淡白舌。模型对舌形分类胖大舌的识别最好(F-1为0.59),痩薄舌较差(F-1为0.23)。模型对津液分类润苔的识别最好(F-1为0.86),燥苔、滑苔的识别均不足(F-1分别为0.14和0.18);模型对苔厚度分类的厚苔识别较好(F-1为0.70)。模型对苔色分类黄苔识别较差(F-1为0.57)。模型对齿痕舌、裂纹舌的识别较好(F-1分别为0.72和0.73),对芒刺舌的识别略差(F-1为0.60)。
4 分析与讨论
根据模型不同分类测试结果的差异,分析可能影响结果精确度的因素。
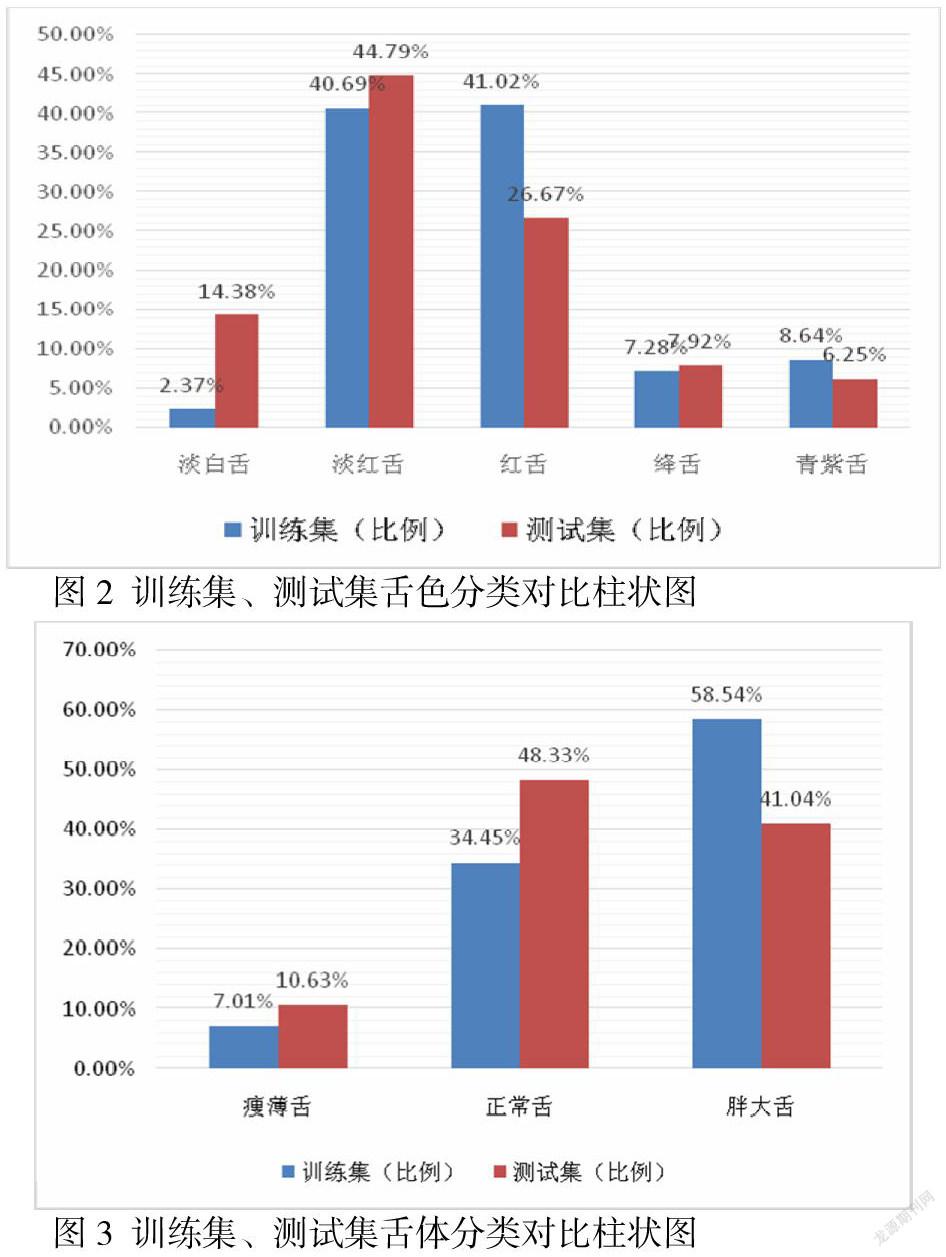
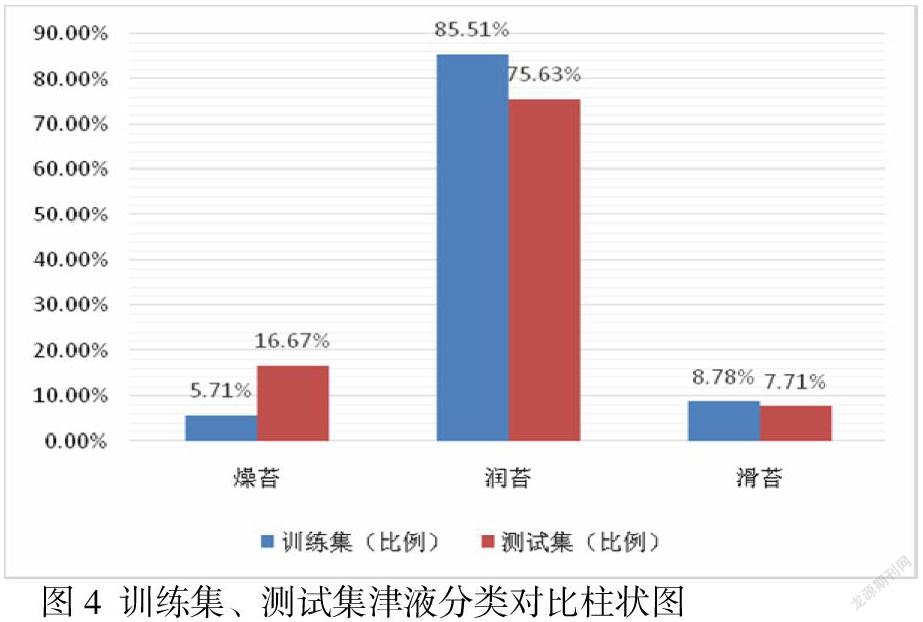
4.1 数据不均衡 模型对舌色、舌形、津液多分类的精确率不足,三分类维度下,模型对淡红舌、正常舌形、润苔的分类精确率都相对较高,这与训练数据集中各分类的样本量分布情况基本一致(图2~4)。根据CNN模型训练原理,训练数据集中占多数的分类会对模型权重产生较多影响,因此导致训练后模型对样本量偏大类别的精确率高于其他分类。
4.2 数据预处理 模型对舌色、苔色的分类精度不理想,这可能是舌色、舌苔图像信息相互干扰的结果。舌诊照片来源广泛,受拍摄时光源、拍摄角度、图片采集设备影响,大量噪声无法避免,模型对数据特征的提取难度增大。有研究0000显示,舌体分割与苔质分离技术可显著提高舌象照片的分类精度,未来模型优化时,可将舌体分割与苔质分离技术用于舌象照片的预处理,降低图像信息信噪比,改善模型分类精确率。
4.3 训练
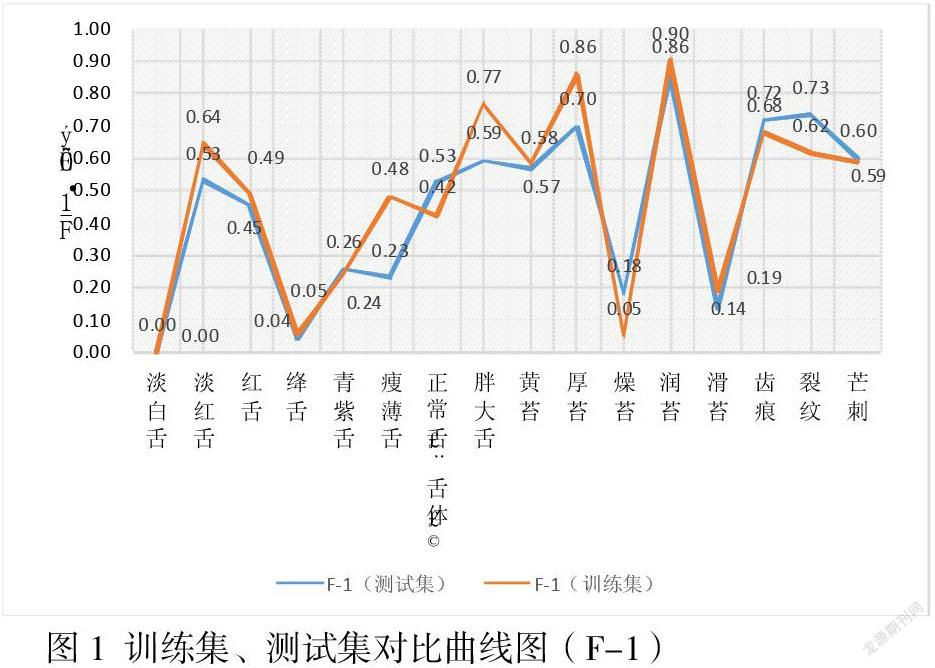
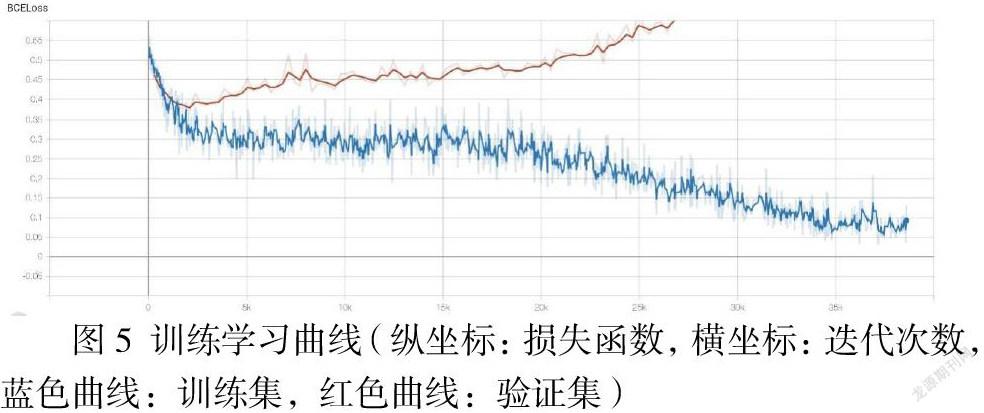
图5中两数据集曲线随迭代次数震荡分离,说明模型对两数据集的分类精确率不同,我们考虑可能存在过拟合(overfitting)。为了使模型对训练集外数据能有较好泛化性,应在训练时同时监测模型对验证集的损失函数,必要时提前停止训练,避免模型对训练集过拟合。但是,提前停止又有模型欠拟合的风险。我们共迭代训练200期,最后选择第115期模型的权重,损失函数为0.5744。
4.4 阈值设置 模型对测试集中照片舌色分类时,训练集和测试集中共140张人工标注的淡白舌照片,没有1张被成功识别,回顾训练后模型对标注为淡白舌照片的Logistic回归结果,其概率一直在0.05左右震荡,远低于其他舌色的阈值,因此无法被正确归类。造成这种结果的原因很多,舌色分类维度下的不同舌色设定不同阈值可能是解决方法之一。
5. 展望
根据试验数据结果,可以发现将ML和AI技术应用于舌诊照片分类任务是存在可行性的,目前模型对舌象照片二分类任务的精确率是相对可靠的。在此基础上,学习与借鉴AI的最新技术,可不断改进舌诊分类AI模型的训练方法包括:确保数据集类别的均衡,使用舌体切割与苔质分离技术对舌诊照片数据集预处理,监测模型训练过程中的损失函数与权重变化,避免训练的过拟合与欠拟合,使用优化算法重新设定阈值。相信在不远将来,必将获得精确率更高的舌诊分类模型。
参考文献:
[1]石强,王忆勤, 郎庆波,等. 13名中医师对69例被观察者苔色观察结果的分析[C]// 全国辨证论治研讨会. 中华中医药学会, 2004.
[2]董竞方、黄金昶、王建云.卷积神经网络算法在肿瘤患者舌象识别中的应用[J]. 北京中医药, 2020, v.39(11):106-109+115.
[3]刘梦,王曦廷, 周璐,等.基于深度学习与迁移学习的中医舌象提取识别研究[J]. 中医杂志, 2019, 60(10):30-35.
[4]覃海松.舌诊定量化中图像处理相关方法研究[D]. 中南大学, 2014.
[5]邵尤伟.基于深度学习的智能舌诊方法研究[D]. 2018.
[6]刘国正.卷积神经网络在中医舌象分类模型中的应用研究[D].
[7]李宗润.基于深度学习技術的舌体分割模型研究与舌象智能化应用探索[D].成都中医药大学,2020.
[8]杜春慧.中医舌质特征的机器学习模型研究[D].电子科技大学,2020.
作者简介:于飞(1984.4-)男,汉族,北京,医学AI研究员,硕士,研究方向:中医文献学。
(深圳市予恩智能科技有限公司 广东深圳 518000)
