基于深度学习和词汇相似度的个性化新闻推荐系统设计
2021-09-10江涛
江涛


摘 要:对网络上庞大的新闻资讯,如何发展一个个性化的新闻推荐系统,自动地推荐使用者感兴趣的新闻,是一个备受重视的课题。文章提出一个个性化新闻推荐系统,此系统将建立一个新闻本体,并通过深度学习计算使用者偏好,以此达到推荐个性化新闻的目的。此新闻本体以分析新闻的词汇为基础,并参考专家的分类。其中,每个类别包含特定数量的代表性词汇,而这些词汇以时事新闻进行TF-IDF统计而得。对每一则新闻,系统将计算该则新闻所包含的词汇与新闻本体中代表性词汇的相似度,定义为新闻的特征向量,并将此特征向量输入多层次类神经网络进行深度学习计算得出新闻推荐值。实验结果显示,相较于随机推荐,文章所提出的方法可以较大地提升推荐成功的比率,神经网络将由推荐值来判断是否推荐给使用者,若是使用者未点击阅读此新闻,判断为使用者不喜欢此篇新闻,神经网络将会进行修正,使之越来越接近真实的使用者偏好。
关键词:使用者偏好;新闻推荐;深度学习;TF-IDF
0 引言
在网络新闻普及的今天,大量的新闻网站如腾讯新闻、网易新闻、中国青年电子报等众多媒体平台的普及,配合智能手机、平板与5G网络技术的发展,人们也越来越依赖智能型设备在任何时间、地点,通过网络来从事各式各样的活动,例如:可以使用手机浏览器阅读网络新闻,部分新闻媒体也推出专属手机 APP 以供阅读,新闻的即时性已然与过去的一日一报大不相同。也就是在这新闻资讯爆炸的时代,人们有太多新闻可以浏览阅读,因此一个好的个性化新闻推荐系统,对大多数使用者将是非常有用的。
本文将以词汇相似度为基础结合深度学习推荐个性化新闻:首先,参考专家分类,将新闻分为多个类别,并将其对应的时事新闻进行分析,取出其中的代表性词汇,加入其对应的类别,以此作为新闻本体。之后,由网络爬虫获取新闻,利用中文断词系统将该新闻的词汇取出,然后利用TF-IDF(Term Frequency-Inverse Document Frequency)方法来计算出本文代表性的词汇,再将这些词汇与新闻本体中的代表性词汇进行 NGD(Normalized Google Distance) 相似度計算,其结果定义为此新闻的特征向量。最后,将新闻的特征向量输入多层次类神经网络进行深度学习计算,依据使用者真实的点击记录修正各层神经元传导路径的权重值以及神经元偏权值,从而由神经网络判断是否推荐给使用者。
1 相关研究
1.1 新闻本体
“本体”源自于哲学,是一个探讨物体存在的哲学分 支[1]。在信息科学中,本体论的观念被应用在知识表达上,也就是对特定领域之中某套概念及其相互之间关系的形式化表达,通过描述一项事物与其他词汇的从属关系来代表该事物。在本研究中所建立的新闻本体由数个类别组成,各类别下又具有特定数量的代表性词汇,这些代表性词汇是通过TF-IDF统计方法计算而得。
1.2 Term Frequency–Inverse Document Frequency (TF-IDF)TF-IDF是一种用来评价词汇与文章关联程度的统计方法[2]。词汇的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。
单一词汇ti的词频(Term Frequency, TF),可由式(1)计算得知,其中ni,j,nk,j分别表示词汇ti,tk在文件dj出现的次数,分母即为文件dj中所有词汇出现次数之总和。
逆向文件频率(Inverse Document Frequency,IDF)是一个计算词汇重要性的方法。某一特定词汇的IDF,可以由(2)式得到,其中∣D∣是语料库中的文件总数,表示包含词汇ti的文件数目。
1.3 Normalized Google Distance(NGD)NGD是一种词汇相似度的计算方式,利用搜索引擎搜寻词汇后,回报的搜寻结果数来计算两个词汇之间的相关度。两个相似的词汇会有较小的NGD值,而较不相关的词汇会有较大的NGD值。NGD的计算公式如下:
(4)
其中x,y是欲计算相似度的两个词汇,f(x)是词汇x的搜索结果,f(x,y)是合并词汇“x”“y”搜寻的结果数,N是Google 搜寻引擎的总索引数。
2 关键问题
2.1 系统架构
新闻推荐系统架构如图1所示,推荐系统主要分为两部分:新闻分析系统及深度学习。
2.2 新闻分析系统
2.2.1 网络爬虫
网络爬虫是一种自动浏览探索网络的程序,被广泛用于网际网络搜寻引擎或其他类似网站,以取得或更新这些网站的内容和检索方式。它们可以自动采集所有其能够存取到的页面内容,以供搜寻引擎做进一步处理,而使得用户能更快地检索到他们需要的信息。本研究利用爬虫快速地搜集新闻数据,用以建立新闻本体以及深度学习训练。
2.2.2 断词系统
断词系统是一种将一句话或一段文章分成词汇以便后续处理的系统。通过断词系统可以将前述网络爬虫所获得的新闻数据,使用TF-IDF统计方法取出该篇新闻的代表性词汇[3]。
3 深度学习
本研究采用深度神经网络,使用反向传播算法进行学习训练,以新闻的特征向量作为输入,隐藏层的激活函数是采用线性整流函数(Rectified Linear Unit),ReLU相较于其他激活函数能更快收敛,也可以有效处理梯度消失的问题,并依据使用者真实的点击记录修正各层神经元传导路径的权重值以及神经元偏权计算,以得出使用者是否对一篇新闻有兴趣。
4 建立新闻本体
参照搜索引擎新闻分类的方式,系统先用网络爬虫从固定的几个中文网络新闻平台撷取相关类别的新闻。另外,在参考Google新闻平台的建议词汇及百度搜寻热门词汇后,发现大部分词汇都属于名词,因此收集完新闻文章,利用断词系统断词后,将只取名词词类来进行下一步计算。利用TF-IDF把该类别中最常出现的多个代表性词汇记录下来,与原本的类别连接,建构新闻本体。如:假设旅游类别的新闻中最常出现的词汇是“故宫”“庐山”“九寨沟”,则将其定为旅游类别下的3个代表性词汇。
5 计算新闻特征向量
在建立了新闻类别与代表性词汇之间关系的新闻本体之后,假设所建立的新闻本体中有n个类别(如旅游、体育等),其分别以C1,C2,…,Cn表示,而每个类别有m个代表性词汇,并以TCi,j,1≦i≦n,1≦j≦m表示第i个类别的第j个代表性词汇。对某一新闻N,假设经过断词分析后,得到其内含有s个代表性词汇(以TNh,1≦h≦s来表示),目标是利用这些词汇来得出此新闻N与新闻本体每个类别C1,C2,…,Cn的相似度,因为NGD值代表词汇之间的相似度,所以可以通过新闻N中所有词汇(TNh,1≦h≦s)与某类别Ci中的所有代表性词汇(TCi,j,1≦j≦m)任两者间的NGD值,来计算出新闻N与Ci的相似度,其公式定义如下:
经由(2)的计算可得出一新闻N与本体中所有类别Ci(1≦i≦n)之间的相似度,这些值可以用来定义新闻N的特征向量,亦即假设U代表新闻N的特征向量,则
6 进行深度学习训练
由(5)式可以得到一篇新闻的特征向量,以此特征向量代表新闻,并取数则新闻分批作为深度学习的训练数据输入神经网络,然后依每次通过神经网络所输出结果,由反向传播算法计算其值与真实使用者选择之间的误差有多少,来修正神经元路径权重值以及神经元偏权,经过不断训练来学习使用者兴趣。
7 试验以及评估
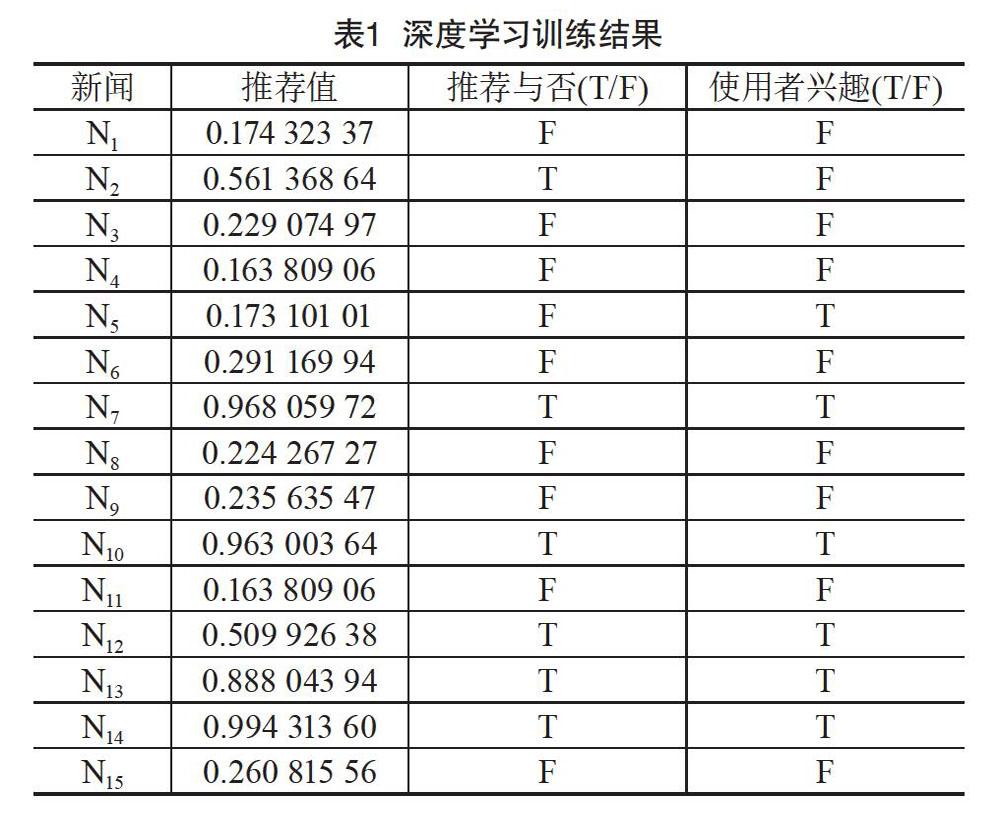
表1为实验初步训练成果,实验采用3层隐藏层。
准确率计算如(7)式,计算结果为85%,由此可以看出深度学习具有较好的推荐效果。
(7)
8 结语
本文考察了现今新闻平台多数区分类别的特性,并建立新闻本体,新闻本体能够将新闻内容的抽象概念具體化,再通过NGD计算新闻词汇与新闻本体的相似度,来建立一则新闻的特征向量,让计算机可通过数值化的新闻来进行深度学习训练,从而计算新闻推荐值,并依照推荐值进行推荐,由于深度神经网络是可以不断训练的,本系统可以不断进行学习,根据实验证明,采用深度学习,已具备不错的推荐效果,未来研究也将进一步调整深度学习网络的各项参数,使新闻推荐系统推荐出更符合使用者偏好的新闻。
[参考文献]
[1]黄立威,江碧涛,吕守业,等.基于深度学习的推荐系统研究综述[J].计算机学报,2018(7):1619-1647.
[2]彭菲菲,钱旭.基于用户关注度的个性化新闻推荐系统[J].计算机应用研究,2012(3):1005-1007.
[3]邓存彬,虞慧群,范贵生.融合动态协同过滤和深度学习的推荐算法[J].计算机科学,2019(8):28-34.
(编辑 王永超)
