风力发电机组异常数据检测研究
2021-09-10徐鹤曹彬岳文彦
徐鹤,曹彬,岳文彦
(中节能风力发电股份有限公司,北京 100034)
1 前言
随着中国提出努力争取在2060年前实现碳中和,发展风力发电、太阳能发电等清洁、可持续、可再生能源成为加速能源结构转型的重要举措之一,风电装机规模将持续扩大。而风能具有不确定性,大量的风电接入电网可能会出现大规模功率波动,进而引发电网稳定性问题。为了使风能成为可靠的能源来源,建立高效、准确的风电监测和预测模型尤为重要。
风功率曲线是风力发电机组功率和风速的对应曲线,反映了风力发电机组在不同风速下产生电能的能力,在评价风力发电机组发电性能优劣及风功率预测中发挥着重要作用。而由于弃风限电、通信设备故障、极端天气、叶片污染和风速传感器失灵等原因,实际测量数据中存在大量不符合风力发电机组正常输出特性的异常点,异常数据的识别和剔除是获得风功率曲线的重要步骤,IEC 61400-12-1中关于异常数据剔除做出了明确规定:用于分析的数据均应该是在风力发电机组正常运转情况下采集的,为了确保数据没有损坏,应当排除以下情况中的数据集:(1)除风速外的外部条件超出了风力发电机组的工作范围;(2)由于风力发电机组故障状态导致的无法运转;(3)风力发电机组被手动关机或者处于测试或维修操作状态;(4)测试设备故障或者性能退化(例如,叶片结冰和污染等);(5)风向超出了规定的测量扇区。
国内外研究学者对风功率异常数据剔除、风功率曲线建模做了大量研究,风功率曲线建模的精度不断提升。而风力发电机组的运行数据中蕴含更多信息,除了需要将正常数据与异常数据区分开外,还需要将异常数据产生的原因进一步识别,即风力发电机组运行状态识别。对风力发电机组运行状态的识别是风电监测的重要工作之一。同时,机组运行状态识别结果可以用于排除IEC 61400-12-1中规定的五种数据集,获取风功率曲线。
本文阐述了风速-功率散点图中的异常数据分布特征,总结归纳了常用的异常数据识别方法、风功率曲线建模和风力发电机组运行状态识别方法,重点对各个方法的技术路线、应用情况以及应用效果进行介绍。通过对各个方法机理的分析,逐步梳理其应用范围,找出问题和不足。在此基础上,提出了风力发电机组运行状态识别深入研究的未来发展方向,从而为今后建立高精度的风力发电机组运行状态识别模型提供理论依据。
2 异常数据分布特征
风力发电机组在运行过程中受到湍流、气象因素和零部件故障等影响,运行数据中存在大量偏离正常工作特性的异常点。不同成因的异常点在风速-功率散点图中表现的数据形态不一致。根据风速-功率图中散点分布形态可以将异常数据分为四类,如图1所示。
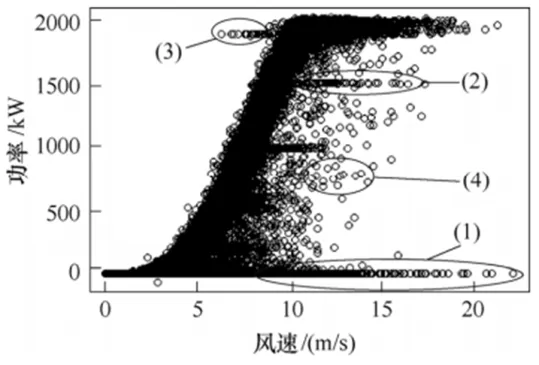
图1 风功率散点图异常数据分布特征示意
(1)底部堆积型异常数据在风速-功率散点图中表现为一条横向密集数据带,功率在零值附近波动,表现为数据堆积。产生的原因包括机组故障、通信设备或测量终端故障、计划外停机检修等情况。
(2)中部堆积型异常数据在风速-功率散点图中表现为在保证功率曲线下横带状的形态,该数据带往往是因为电网限电或者风力发电机组故障无法定位,人为将风力发电机组功率限制在某一值。
(3)上部堆积型异常数据在风速-功率散点图中表现为位于风功率曲线右侧横带状的形态,产生的原因通常是通信错误或风速传感器失灵。
(4)周围分散型异常数据表现为功率曲线附近密度较低的无规律散点。此类异常数据产生的原因为弃风限电、信号传播噪声、传感器失灵、极端天气情况和风向标松动等随机影响因素造成的。
堆积型异常数据通常在时间上存在连续性,往往无法瞬时恢复。分散型异常数据表现为分散分布的形态,通常是随机产生且变化的,可短时间内恢复。
弃风限电的数据可能表现为堆积型数据也可能表现为分散性数据,具体的数据形态与弃风限电的响应方式相关。能量管理系统(Energy Management System,EMS)接收自动发电控制模块(Automatic Generation Control,AGC)限电的指令后,按照内部控制逻辑来控制风电场中每台风力发电机组的功率。AGC的限电命令是实时发送且为动态调整的,往往弃风限电数据在风速-功率散点图上表现为分散型。而如果人工参与限电行为,如为了快速响应限电指令,将某一台或者几台风力发电机组的功率限制在某一值下,此时弃风限电数据在风速-功率散点图上则表现为堆积的横带形态。
3 统计学异常数据识别方法
3.1 组内最优方差法(Optimal Interclass Variance,OIV)
娄建楼等人提出了组内优组内方差的数据剔除方法,该方法首先将风速和功率的原始数据根据风速区间进行划分,记某一风速区间的数据集为W:

vi表示i第个数据样本的风速,pi表示i第个数据样本的功率,pi按照降序排列,即pi<pi-1(i>1)。
然后依次计算前个坐标点中功率的方差值:

si为第个i点的方差,pj为第j个点的功率值;为第i-1个点的功率的平均值。由于是依次计算数据集中i个点的方差,该计算方式类似滑动计算,所以娄建楼等人又将此计算方法称为滑差值计算。
最后,通过给定滑差值的阈值,分离正常点和异常点。这种方法实用、高效,并引入实际的案例证明了该方法能够准确识别出机组异常运行状态。
3.2 变点分组-四分位法
沈小军等人采用变点分组法与四分位法组合的方法。变点是指在一个序列或一个过程中的某个或某些数据突然变化的点,这种突然变化往往反映数据的某种质的变化。变点分组法是在组内最优方差法的基础上计算方差的变化率,采用方差变化率的变点作为分组依据。

ki为第i个点的方差变化率。
然后,采用最小二乘法作为检测方法,对每个风速区间的风力发电机组功率的方差变化率分为前后两段进行回归分析,回归系数发生突变的点即为回归变点,从而得到功率值明显变化的位置。变点分组法准确识别出了风速-功率曲线下方的第一、二类堆积型异常数据和部分分散型异常数据,但是,对风功率曲线上界的第三类堆积型异常数据和部分分散型异常数据无法有效识别。因此继续采用四分位法进行异常数据识别,四分位法是常用的统计学异常数据检测方法,即将全部数据从小到大排列,排列在前1/4位置上的数,即25%位置上的数,称为第一四分位数,记作Q1;排在后1/4位置上的数,即75%位置上的数,称为第三四分位数,记作Q3;排列在中间位置的数即50%位置上的数,称为第二四分位数,记作Q2。将Q3-Q1定义为四分位距,记作IQR。将Q3+1.5IQR定义为上界;将Q1-1.5IQR定义为下界;将大于上界和小于下界的数据识别为异常值。沈小军等人用四分位法有效地识别出了第三类异常数据及部分分散型异常数据。
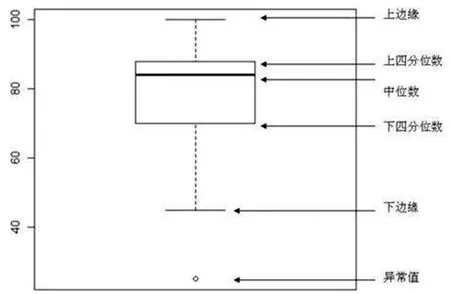
图2 四分位法示意图
4 机器学习异常数据识别方法
4.1 基于聚类的方法
聚类分析是无监督类机器学习算法中最常用的一类,其目的是将数据集分成若干组,也被称为“簇”,使得组内的相似性大于组间的相似性,如果划分适当,则簇应当捕获数据的自然结构,因此聚类分析也常常被用作离群点检测。常用的聚类方法有K-means、层次聚类、Dbscan(Density-Based Spatial Clustering of Applications with Noise)、模糊C均值(Fuzzy C-Means,FCM)等。
Dbscan是常用的基于密度的聚类方法,延平采用Dbscan的方法对风力发电机组运行数据进行分析,根据数据特点将限功率数据、正常运行数据、故障停机数据、降容运行等数据进行区分。该算法将“簇”定义为密度相连的点的最大的集合,并通过考察对象与簇之间的关系,将具有足够高密度的区域划分为一簇,是一种无监督分类的方法。图3为将Dbscan法用于功率-桨距角的聚类效果,图中散点被聚成6类,然后结合风力发电机组运行特性,人为将这六类散点标记为正常运行数据、限功率数据、异常数据和故障停机数据。Dbscan方法虽然在论文所采用的标准数据集上取得了不错的效果,但是,实际运行场景中的风力发电机组数据集往往复杂的多,使用Dbscan方法不能很好地达到论文中的效果。
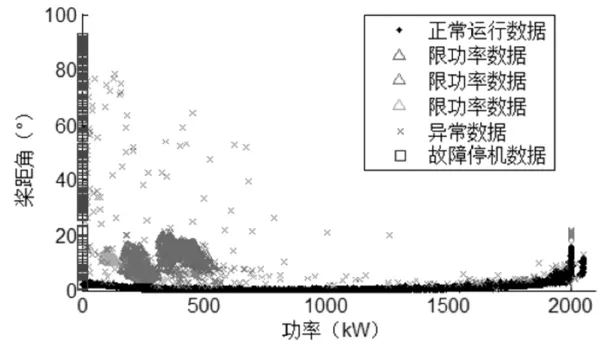
图3 功率-桨距角DBSCAN聚类结果[5]
4.2 深度学习
深度学习本质上是自动特征提取,正常的风力发电机组运行数据特征会有一定的规律,而异常数据往往是个性化的,如果数据量足够多,深度学习也可以用于异常数据的识别。
(1)门控循环单元(Gate Recurrent Unit,GRU)。GRU是循环神经网络(Recurrent Neural Network, RNN)的一种,和LSTM(Long-Short Term Memory)一样,也是为了解决长期记忆和反向传播中的梯度等问题而提出来的。与LSTM相比,使用GRU能够更容易进行训练,并且能够实现与LSTM相当的效果,能够很大程度上提高训练效率。
风力发电机组的数据采集与监视控制系统SCADA包含多个监测量,其中涉及振动量、压力量、温度量、角度量、电气量和速度等,不同风力发电机组品牌和型号的传感器测点个数不一致,一般为几十个到一百多个,图4为常见的SCADA连续监测量。李秋佳根据SCADA系统监测量,构建风力发电机组状态评估的项目层,确定各个项目层的评估指标,并基于随机森林(Random Forest,RF)算法建立了各指标与对应监测量间的联系。然后,选择风力发电机组的状态估计指标并对发电机正常状态下的监测量进行数据预处理,通过克里金法(Kriging)-GRU模型得到各测点评估指标的预测值,给定各指标的残差及劣化度并以此为依据建立相应的标准正态云模型,之后将待估云与标准正态云对比判断风力发电机组运行状态。
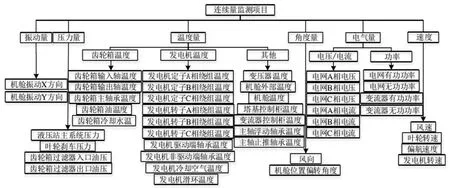
图4 SCADA 连续监测项
(2)深度神经网络(Deep Neural Networks,DNN)。解加盈等人将深度神经网络用于风功率曲线建模,他们首先引入偏最小二乘法(partial least-square,PLS)分析了风力发电机组运行数据中多个变量和风力发电机组功率的相关性,然后,通过交叉有效原则和投影重要性指标(Variable Importance in Projection,VIP)对多个变量进行了降维筛选,最后把找到的最优变量子集作为DNN的输入,最终得到风功率曲线的DNN模型。
5 基于数学表达式的参数化建模
风功率曲线描述了风力机输出功率与风速的关系,反映了风力发电机组的性能。风力发电机组功率曲线的建模有助于风力发电机组的性能监测和功率预测。风功率曲线模型可分为参数模型和非参数模型。非参数模型是指对任何分布的函数形式不作任何假设的模型,本文2、3章中介绍的统计学方法及机器学习方法均是非参数模型。参数化模型是建立在一套数学表达式的基础上,一般采用高级算法求解这套表达式。
5.1 参数化模型
建立参数化模型首先需要确定函数表达式,常用的函数表达式有分段线性模型、多项式拟合、指数、多参数逻辑回归等,本文以线性分段模型和四参数模型来举例介绍。
(1)线性化的分段模型。将风功率曲线进行线性化的分段,如图5所示,利用直线方程实现了分段逼近:
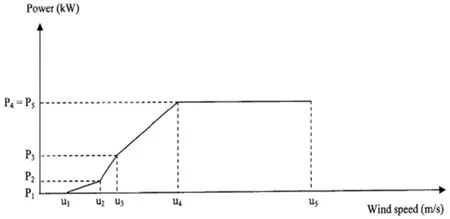
图5 线性分段模型

其中P是风力发电机组功率,为输出变量;u是风速,为输入变量;定义分段的斜率为θ=f(m,c),为常数。
(2)四参数回归模型。风功率曲线的形状可以用带四个参数的逻辑表达式来近似。图6为四参数模型的曲线,其表达式为:
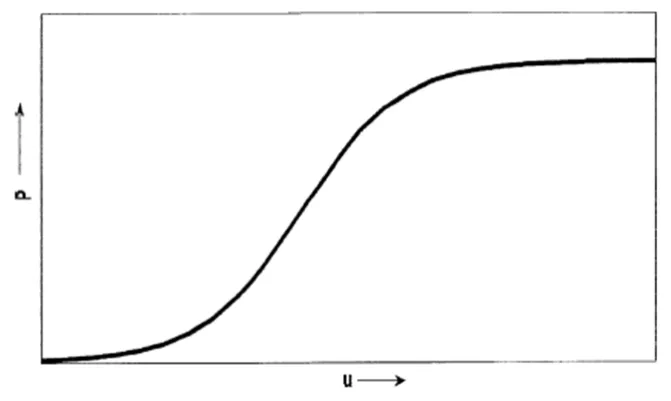
图6 四参数模型
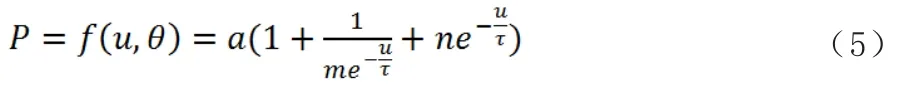
其中θ=f(a,m,n,τ)是决定四参数逻辑表达式的一个矢量参数。
5.2 参数化模型建模方法
参数化模型的参数拟合涉及对数学表达式的一个或多个参数的确定。常用的参数拟合方法有最小二乘法、RANSAC、GA等。图5将功率曲线分为5个线性段,建立功率曲线的线性分段模型后,利用最小二乘法将现有数据拟合到每个线段上。最小二乘法使残差平方和最小,从而得到系数估计值。RANSAC (Random Sample Consensus,RANSAC)算法由Fischler 和 Bolles提出,是一种重采样技术,通过使用估计底层模型参数所需的最小观测值生成候选解决方案,传统的采样技术使用尽可能多的数据来获得初始解,然后继续去修剪离群值,而RANSAC使用尽可能小的集合,并继续用一致的数据点来扩大这个集合,因此,RANSAC方法适用于从噪声点较多的数据集中提取模型。遗传算法是一种基于达尔文生物系统进化理论的搜索技术,通过模拟自然进化过程来搜索最优解,在求解复杂的组合优化问题时,相比常规的优化算法往往可以较快地获得较优的结果。
国内外研究学者对基于数学模型的风功率曲线建模做了大量研究。A.Goudarzi等人研究了330kW、800kW和900kW的风力发电机组风功率曲线建模,使用标准化均方根误差等统计指标来评估所选模型的性能,结果表明,四阶多项式是最精确的数学模型。C.Carrillo等人比较了多项式、指数、立方和近似立方四种模型,他们收集了功率在225kW-7500kW的200台风力发电机组功率曲线,利用确定系数作为适应度指标来评估模型的性能,结果表明,指数逼近和三次逼近的确定系数大,误差小,多项式模型的确定效果最差。Alhassan等人比较九种常用的数学模型,使用相关误差、归一化均方根误差和相关系数等统计标准来评估模型的精度,结果表明,基于功率系数的模型和通用模型是建模风力机功率曲线最精确的数学模型,多项式模型是最不精确的模型。
6 结语
国内外研究学者已经针对风功率异常数据识别和风力发电机组功率曲线建模做了大量研究,风功率曲线建模的精度在不断提升。统计学方法原理较为简单,应用也较广,但是统计学方法严重依赖数据的分布特性,如果数据中存在大量的异常点,将会影响数据分布形态,从而使得统计学识别异常数据的精度下降。机器学习方法适用性较广,但需要大量样本,尤其是深度学习,对样本和计算资源的要求较高。基于参数化模型建模的方法发展较为成熟,但采用不同参数模型获得的功率曲线形态存在差异,使用过程中需要根据具体的数据集选择合适的参数模型。
现阶段将异常数据与正常数据区别划分已经可以实现,但对于异常数据成因识别仍然存在诸多问题。如果能够根据运行数据准确地识别风力发电机组运行状态,将会对风电场运维形成一定的指导作用,从而降低运维成本,提升发电量。因此,从风力发电机组运行数据中挖掘机组运行状态亟待深入探索,主要分为两个方面:一是从技术角度,将更多先进的智能算法应用于风力发电机组状态识别,研究过程中选取真实风电场获取的数据集,除使用电气量、速度量、温度量外,可以加入控制监测量,并且结合风电场地理信息、气象数据等综合考虑;二是从管理角度,推动设备制造商PLC与SCADA更好地配合,并开放保护降容(故障降容、高温降容等)等状态信息,同时应与能量管理平台配合记录限电行为,因为弃风限电数据是降容数据的一部分,特别是在弃风率较高的区域,获取单台机组的限电记录对风力发电机组运行状态识别意义重大。
