基于水厂大数据的混凝投药系统智能模型的构建
2021-09-10李玉宝樊玉芳顾军农
韩 梅,李玉宝,邹 放,刘 畅,樊玉芳,顾军农
(1. 北京市自来水集团有限责任公司,北京市供水水质工程技术研究中心,北京 100012;2. 成都九鼎瑞信科技股份有限公司,四川成都 610000;3. 重庆大学环境与生态学院,重庆 400044)
混凝沉淀工艺一直是净水厂的核心处理单元,而混凝投药的精细化控制更是关乎水质效果和能耗的关键,是水厂一直追求的目标。近年来,随着科技发展的驱动,物联网、大数据、人工智能等多领域的技术和理念已融入水处理领域,混凝投药系统正在从人工控制向智能控制、精准控制迈进。
传统的混凝过程具有时延、滞后的特性[1-3],在水源水质、水量等条件发生变化时,难以实现混凝剂投加量的精准控制,导致水质不稳定,影响后续滤池等工艺的滤程、反洗周期等。智能控制技术准确性高、响应快,能够依据水源水质的变化,及时确定混凝剂的投加量,对建立安全、高效、节能型水厂具有深远的现实意义。而如何通过精准感知,借力大数据、人工智能等新一代信息技术,真正实现混凝加药的智能控制还需不断探索。
目前,XGBoost、LSTM、支持向量机、随机森林等算法已应用于各个领域的信息挖掘、预测等方面,是相对较成熟的算法[4-7]。XGBoost(extreme gradient boosting)算法是Gradient Boosting算法的高效实现版本,可认为是在GBDT算法基础上的进一步优化。首先,XGBoost算法在基学习器损失函数中引入了正则项,控制减少训练过程当中的过拟合;其次,XGBoost算法不仅使用一阶导数计算伪残差,还计算二阶导数,可近似快速剪枝的构建新的基学习器;此外,XGBoost算法还做了很多工程上的优化,例如,支持并行计算、提高计算效率、处理稀疏训练数据等,因而,其在应用实践中表现出优良的效果和效率,被工业界广为推崇[8]。LSTM算法即长短时记忆(long short-term memory),最早由Hochreiter等[9]于1997年提出,是一种特定形式的循环神经网络(recurrent neural network,RNN)。然而,RNN在处理长期依赖(时间序列上距离较远的节点)时会遇到巨大的困难,计算距离较远的节点之间的联系时,涉及雅可比矩阵的多次相乘,会带来梯度消失(经常发生)或者梯度膨胀(较少发生)的问题。LSTM的巧妙之处在于,通过增加输入门、遗忘门和输出门,使自循环的权重发生变化,避免了梯度消失或者梯度膨胀的问题[10]。此外,随机森林(random forest,RF)算法是以决策树为基础的集成学习算法,作为机器学习算法,在处理复杂数据源、数据噪声及有限训练样本方面有较好的表现[6]。支持向量机(support vector machine)是一类按监督学习(supervised learning)方式对数据进行二元分类的广义线性分类器[11]。
本文以大型水厂人工数据和在线数据为基础,通过LSTM、支持向量机、随机森林、XGBoost等分别建立了混凝投药模型,系统比较了各种算法的建模效果,并尝试采用箱线图结合移动平滑的技术对异常值进行处理,使得最终混凝投药模型更精准、适用性更强。
1 试验装置和方法
1.1 水厂数据划分
A、B水厂原水均是南水北调水源,是接收南水的主力水厂,同时,两个水厂均采用机械加速澄清池作为主要除浊工艺。因此,分别以A、B水厂为研究对象,进行智能投药模型的构建。
A水厂粗粒度数据建模以d为单位,训练数据取自2016年7月1日—2018年12月31日,共计914条数据量;测试数据取自2019年1月1日—2019年5月31日,共计151条数据量。细粒度数据建模以5 min为一个粒度,均为在线数据,同样,将数据集分为训练集和测试集。训练集是2015年1月1日—2018年12月31日,共计420 768条;测试集是2019年1月1日—2019年10月15日,共计82 944条。
B水厂数据包括人工数据和在线数据,具体进水量和加药数据选取2015年1月1日—2020年7月6日,数据粒度为h;在线数据包括进水、机加池、炭池和出厂的水质数据,时间为2015年1月1日—2020年6月30日,数据粒度为5 min;此外,氯投加量、臭氧投加量及混凝剂投加数据的时间是2015年1月1日—2020年6月28日,数据粒度为周。将上述数据合并后,共计578 304条,时间为2015年1月1日—2020年6月30日,数据粒度为5 min。经过处理后得到有效数据共计486 252条,训练集为2015年1月1日—2018年12月31日,共计363 684条,测试集为2019年1月1日—2019年10月31日,共计85 992条。
1.2 异常数据的处理方法
细粒度数据的数据量较大,且由于在线仪表维护和检修等会存在一定的异常数据,此外,部分数据大量重复对建模工作不利,需在建模前对数据进行预处理。对A水厂细粒度数据采用了两种方案的异常数据处理方法。方案一是根据经验对水质指标进行约束,限定范围,如直接去除进水浑浊度大于20 NTU的数据、机加池出水浑浊度大于5 NTU的数据、预臭氧大于0.7 mg/L的数据和pH值大于8.6或小于4.66的数据,对于进水电导率大于400 μS/cm或小于100 μS/cm的数据使用电导率的均值替代,对于进水氨氮大于0.24 mg/L的数据使用均值替代,同时,去除部分时间段高度重复的数据;方案二是采用基于滑动均值的异常数据识别技术,本研究窗口大小为200,即某一时刻的滑动均值等于从该时刻开始往前的200条数据的加权平均值,数据的权重呈指数分布,离该时刻越近的数据权重越大。
B水厂异常数据采用箱线图和基于滑动均值的异常数据识别技术相结合的方法处理。如图1所示,箱线图是对数据分布的一种常用表示方法,先将数据从小到大排序,然后找到最小值、1/4位数、中位数、3/4位数、最大值,进而计算最小观察值和最大观察值,如式(1)~式(2)。如果最小值≤最小观察值,则下边缘=最小观察值;反之,最小值>最小观察值,则下边缘=最小值。如果最大值≥最大观察值,则上边缘=最大观察值;反之,最大值<最大观察值,则上边缘=最大值。数据如果落在下边缘和上边缘之间为正常数据,不在这个范围的数据为异常数据。

图1 箱线图说明Fig.1 Description of Boxplots
最小观察值=1/4位数-1.5×(3/4位数-1/4位数)
(1)
最大观察值=3/4位数+1.5×(3/4位数-1/4位数)
(2)
使用箱线图分别对进水流量和进水浑浊度数据进行异常数据的筛分,如图2所示,将数据按照每月分组,分析各自的数据范围,对不在正常范围的数据标记为异常数据直接删除。如图3所示,对聚合氯化铝(PAC)和三氯化铁(FeCl3)采用箱线图筛分,如果PAC大于50,直接剔除该条数据,否则采用滑动均值替换异常值,FeCl3的异常数据采用滑动均值替换异常值的方法进行处理。对水温、pH和机加池出水浑浊度数据也采用类似的方法进行处理。此外,对部分时间缺失字段较多的样本直接删除,对少量缺失数据使用均值、插值填充。

图2 异常数据筛分 (a)进水流量;(b)进水浑浊度Fig.2 Screening of Abnormal Data (a) Inflow Rate; (b) Inflow Turbidity

图3 异常数据筛分 (a) PAC; (b) FeCl3Fig.3 Screening of Abnormal Data (a) PAC; (b) FeCl3
1.3 中试试验装置
将混凝投药模型应用于中试全工艺流程试验系统中(图4)。全流程工艺系统设计产水量为1 m3/h,包括原水箱、进水泵、预臭氧接触池、混凝反应池、斜管沉淀池、砂滤池、臭氧接触池、碳滤池、清水箱等。该试验系统配置全方位的在线水质分析设备,包括UV254、浊度仪、pH、余氯测定仪及臭氧浓度仪。在线仪表将数据传输给中控端PLC,PLC通过远程模块将水质参数和工艺运行参数远传到数据采集终端。采集的数据用于机器学习,最终一方面在混凝投药管控平台上展示,另一方面反馈输出加药指令。

图4 中试工艺系统Fig.4 Pilot Test Process System
2 结果和讨论
2.1 基于A水厂数据对不同算法的建模效果评估
2.1.1 水厂数据探索
要建立加药量的模型,首先对水厂水质数据、工艺运行数据与加药量的相关性做了探索。由于粗粒度数据类型较多,包括水厂日检水质数据,如温度、色度、浑浊度、溶解氧、电导率、氨氮、pH和余氯等;还包括工艺运行参数,如水量、预臭氧投加量、预氯化投加量、PAC投加量、FeCl3投加量等;此外,还包括机械加速澄清池的运行维护参数,如搅拌机转速、排泥时长、沉降比。鉴于后续滤池是直接反馈机械加速澄清池运行效果的工艺,因而,滤池出水阀开度、反洗周期也需纳入考虑范围。由于粗粒度数据水质参数和工艺参数种类较多,为全面分析各种数据之间关系的权重,做了相关性矩阵。如图5所示,以矩阵的形式展示各指标之间的相关性,绝对值越大,相关性越高,发现PAC、FeCl3投加量和进水温度、浑浊度、预加氯、时均水量、排泥时长、滤池出水阀开度、月份和季节等相关性较大。因此,在建模过程中,应对相关水质指标和运行参数重点关注,作为特征值输入。
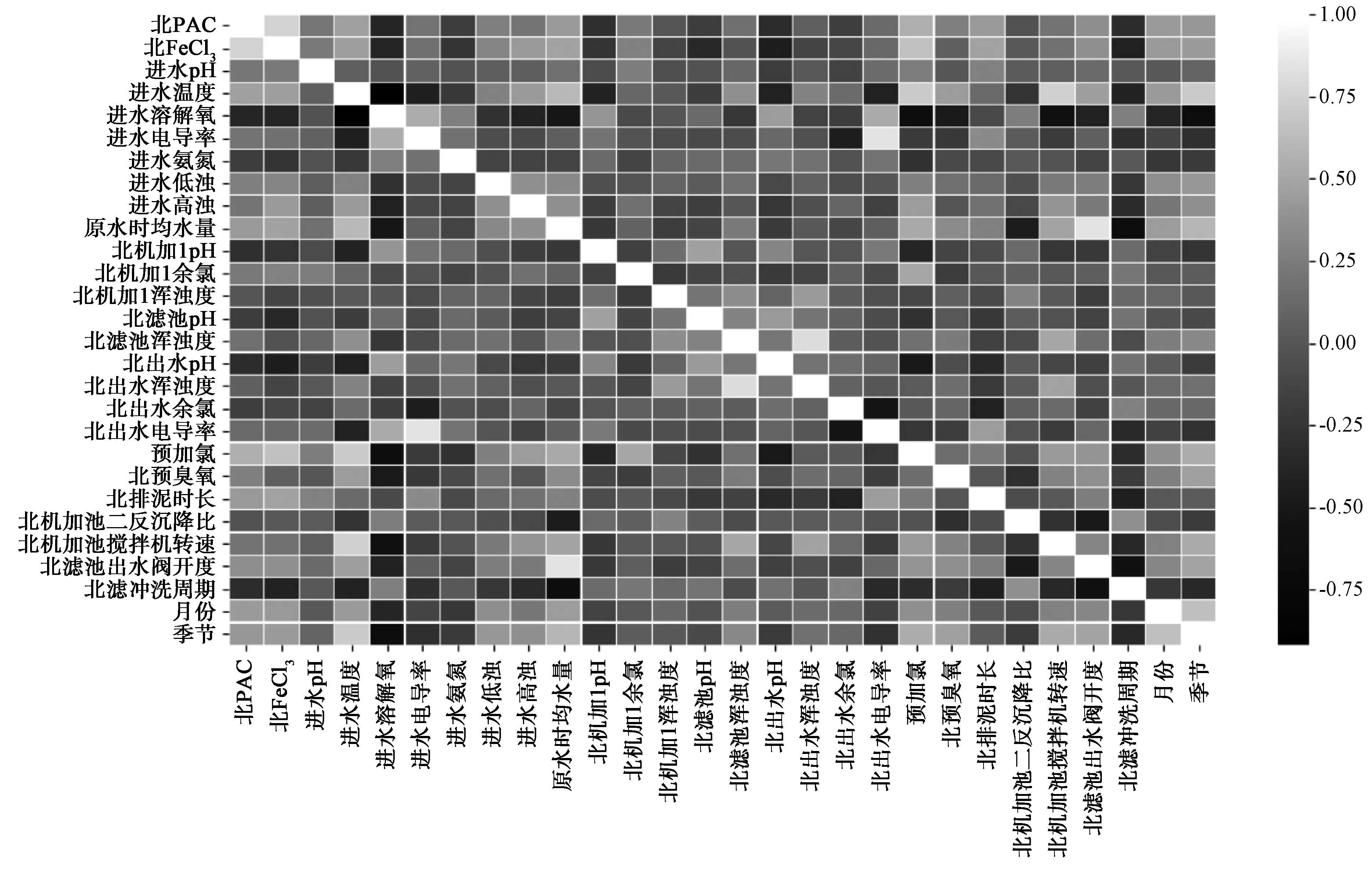
图5 各指标参数间的相关性矩阵Fig.5 Correlation Matrix of Each Index Parameters
2.1.2 建模效果评估
水厂机械加速澄清池采用PAC和FeCl3双药投加的模式,因而,对PAC和FeCl3的投加量分别进行了模型构建。基于A水厂日检的粗粒度数据对PAC的建模,分别尝试采用了随机森林、支持向量机、LSTM、XGBoost算法,各种算法输入的特征具体为[‘原水浑浊度’, ‘炭池浑浊度差值’, ‘原水色度’, ‘原水pH’, ‘预加氯投加率’, ‘温度区间’, ‘季节’, ‘预臭氧投加率’, ‘机加池浑浊度’, ‘炭池出水浑浊度’]。基于水厂日检的粗粒度数据对FeCl3建模,分别尝试采用了随机森林、线性回归、LSTM、XGBoost算法,各种算法输入的特征具体为[‘原水浑浊度’, ‘机加池浑浊度差值’, ‘炭池浑浊度差值’, ‘原水色度’, ‘原水pH’, ‘预加氯投加率’, ‘原水温度’, ‘季节’, ‘预臭氧投加率’, ‘机加池浑浊度’, ‘炭池出水浑浊度’]。
建模的精确性评估标准以平均绝对百分比误差(MAPE)和平均绝对误差(MAE)为指标,如式(3)~式(4),建模的目标是MAPE、MAE越小越好。结果如表1所示,对不同模型的评估值MAPE进行比较,发现采用XGBoost算法对PAC和FeCl3加药量建立的预测模型均最优,其MAPE最小。因此,为进一步优化模型的准确度,需采用细粒度数据做进一步训练模型。

表1 采用多种模型算法预测的评估值比较Tab.1 Comparison of Evaluation Predicted by Various Model Algorithms
(3)
(4)
其中:MAPE——平均绝对百分比误差;
MAE——平均绝对误差;
n——样本数量;
yk——第k个样本的实际值;

为进一步提高模型的预测精度,对A水厂采用以5 min为单位的细粒度数据进行建模。通过粗粒度建模,发现XGBoost算法建模效果最好,此外,LSTM在数据量比较大的情况其算法也具有一定的优势。因此,基于A水厂细粒度数据对XGBoost算法和LSTM做了进一步的比较,同时,也比较了方案一和方案二两种异常数据处理方法在建模效果上的差异(表2)。在细粒度数据支撑下,XGBoost较LSTM模型仍具有较大的优势,评估效果较好。细粒度较粗粒度数据对建立模型的效果更好,如对PAC的MAPE评估值由粗粒度的15.99降到细粒度的8.87;采用基于滑动均值的异常数据识别技术(方案二)与常规异常数据处理方法(方案一)相比,MAPE进一步下降,对PAC的MAPE评估值由方案一的12.38降到8.87,说明模型预测的效果更好。

表2 不同粒度模型效果对比Tab.2 Comparison of Different Granularity Models
2.2 基于B水厂数据构建智能混凝投药精准模型
2.2.1 PAC加药模型的构建
为进一步提升模型的预测效果,将B水厂人工记录和在线数据相结合,并采用箱线图和移动平滑技术相结合的方法对数据进行预处理,提取到小时粒度的水量数据和加药数据,最终以得到的近50万条有效数据进行建模。对B水厂混凝剂投加量的建模分别采用XGBoost、LSTM和随机森林算法进行了比较。模型输入特征为[‘进水pH’, ‘进水温度’, ‘进水流量’, ‘出水温度’, ‘出水浑浊度’, ‘进水浑浊度’, ‘出水pH’, ‘最近1 d PAC投加量的均值’, ‘最近3 h PAC投加量的均值’, ‘月份’, ‘日期’],模型预测值为PAC投加量,其中,采用滑窗统计的方法获得‘最近1 d PAC投加量的均值’和‘最近3 h PAC投加量的均值’。采用XGBoost建模预测结果如图6所示,评估结果MAPE为3.42;采用LSTM建模预测结果如图7所示,评估结果MAPE为8.50;采用随机森林建模预测结果如图8所示,评估结果MAPE为4.20。通过将随机森林建模效果与XGBoost、LSTM做纵向比较,发现XGBoost预测效果最好,随机森林次之,LSTM最差。
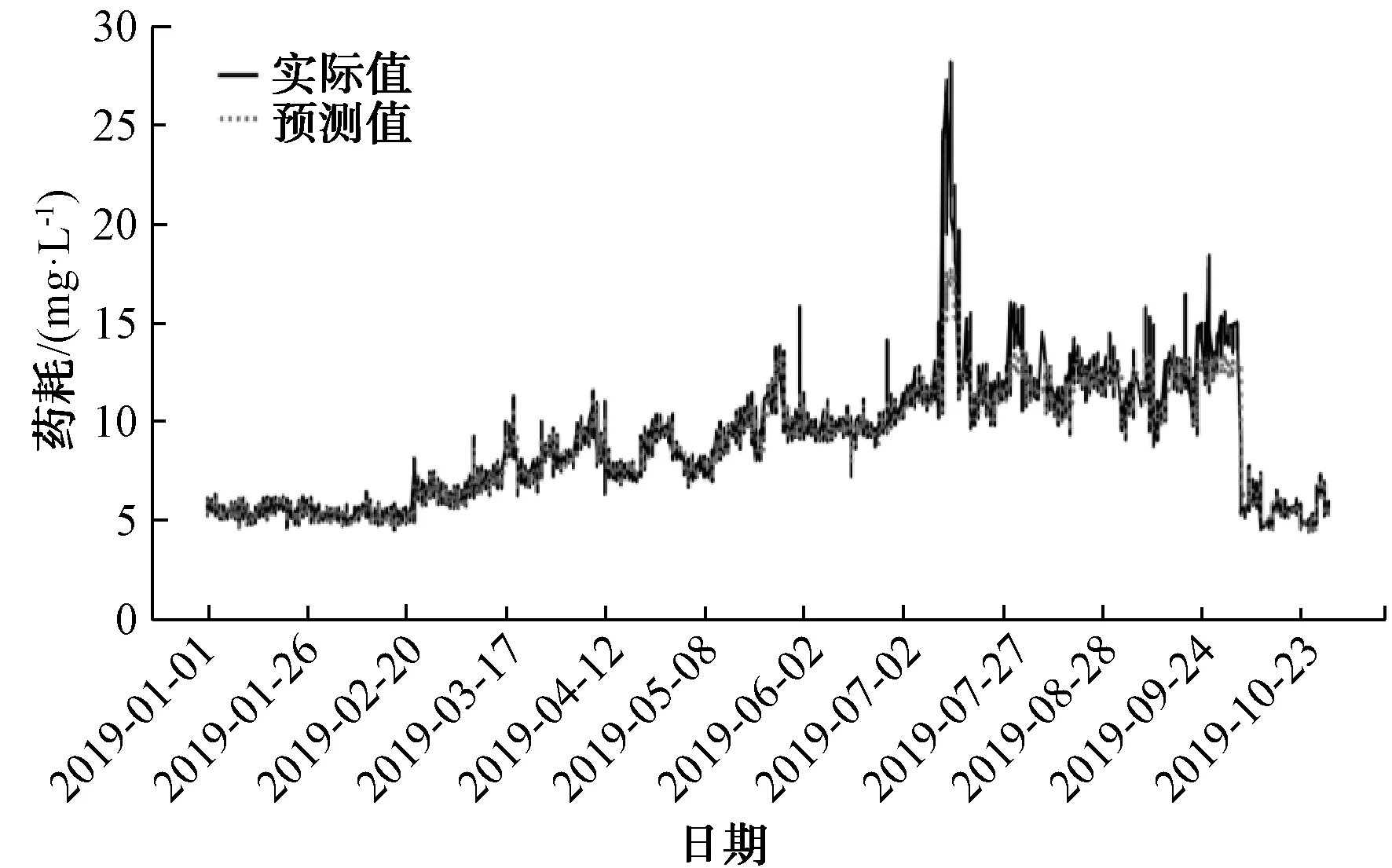
图6 采用XGBoost对PAC的预测效果Fig.6 Application of XGBoost in PAC Prediction

图7 采用LSTM对PAC的预测效果Fig.7 Application of LSTM in PAC Prediction
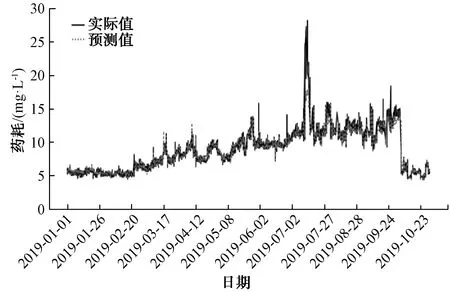
图8 采用随机森林对PAC的预测效果Fig.8 Application of Random Forest in PAC Prediction
2.2.2 FeCl3加药模型的构建
对B水厂FeCl3投加量的建模同样采用XGBoost、LSTM和随机森林算法进行了比较。模型输入特征[‘进水pH’, ‘进水温度’, ‘进水流量’, ‘出水温度’, ‘出水浑浊度’, ‘进水浑浊度’, ‘出水pH’, ‘最近1 d FeCl3投加量的均值’, ‘最近3 h FeCl3投加量的均值’, ‘月份’, ‘日期’],预测值为FeCl3投加量。采用XGBoost建模效果如图9所示,评估结果MAPE为3.72;采用LSTM建模预测效果如图10所示,评估结果MAPE为4.70;采用随机森林建模预测效果如图11所示,评估结果MAPE为5.09。通过将随机森林建模效果与XGBoost、LSTM比较,发现对铁盐的预测与铝盐有差异,但均显示XGBoost预测效果最好,不同的是LSTM次之,随机森林效果最差。

图9 采用XGBoost对FeCl3的预测效果Fig.9 Application of XGBoost in Ferric Chloride Prediction

图10 采用LSTM对FeCl3的预测效果Fig.10 Application of LSTM in Ferric Chloride Prediction
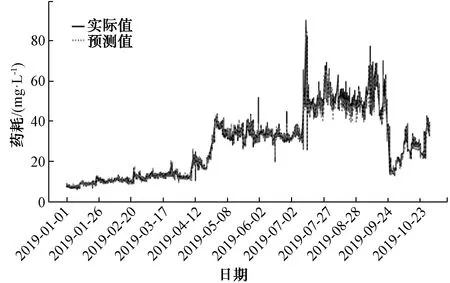
图11 采用随机森林对FeCl3的预测效果Fig.11 Application of Random Forest in Ferric Chloride Predicion
同时,B水厂较A水厂混凝剂投加量变化更频繁,且提取到了小时粒度的水量、加药数据,模型预测的准确性更高。在异常数据处理方面,使用了箱线图的异常数据识别方法,构建了基于滑动窗口的加药历史数据统计特征,模型效果大幅提升。如对A水厂采用XGBoost对PAC投加量建模,最优情况下的MAPE评估值为8.87;而对B水厂采用XGBoost对PAC投加量建模,最优情况下的MAPE评估值仅为3.42,明显低于8.87,可见对模型的效果提升明显。
2.2.3 双药投加的模型构建方法
由2.2可知,采用XGBoost、LSTM和随机森林3种算法对混凝剂投加量分别建模,效果最优的是XGBoost算法,因此,双药投加的建模方法仍采用XGBoost。对双药投加的建模方法尝试采用PAC的预测效果作为FeCl3的输入,即首先预测PAC,预测结果作为特征输入FeCl3预测模型。FeCl3模型输入的特征值为 [‘进水PH’, ‘进水温度’, ‘进水流量’, ‘出水温度’, ‘出水浑浊度’, ‘进水浑浊度’, ‘出水pH’, ‘每d FeCl3投加量的均值’, ‘每3 h FeCl3投加量的均值’,‘PAC预测’, ‘月份’, ‘日期’],预测值为FeCl3投加量。采用XGBoost建模预测结果如图12所示,评估结果MAPE为3.70。采用FeCl3的预测效果作为PAC的输入,即首先预测FeCl3,预测结果作为特征输入PAC预测模型。PAC模型输入的特征值为[‘进水PH’,‘进水温度’,‘进水流量’,‘出水温度’,‘出水浑浊度’,‘进水浑浊度’,‘出水pH’, ‘每d PAC投加量的均值’, ‘每3 h PAC投加量的均值’,‘FeCl3预测’,‘月份’,‘日期’],预测值为PAC投加量。采用XGBoost建模预测结果如图13所示,评估结果MAPE为3.39。
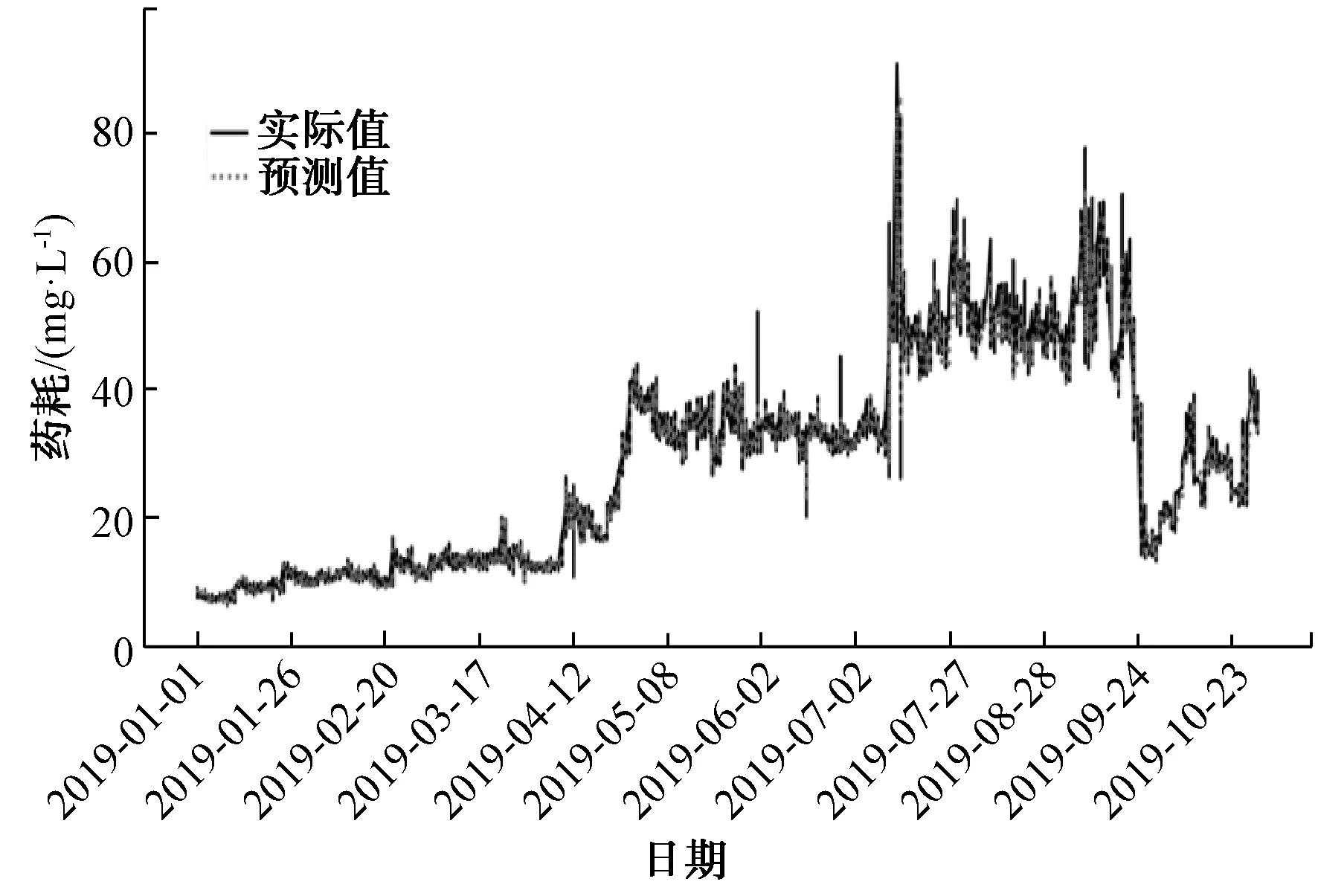
图12 采用XGBoost对FeCl3的预测效果Fig.12 Appliction of XGBoost in Ferric Chloride Prediction
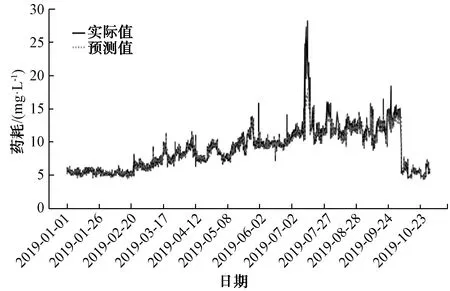
图13 采用XGBoost对PAC的预测效果Fig.13 Appliction of XGBoost in PAC Prediction
对于双药投加,通过将一种药剂的投加量作为另一种药剂预测的特征值输入,与前述各自单独预测药剂投加量相比,模型的预测效果略有提升。
2.3 智能混凝投药模型的应用
为验证模型的预测效果,将采用XGBoost算法建立的混凝投药模型应用于中试系统,对模型的预测加药量与实际加药量进行了效果比对。如表3所示,通过5组数据比较了不同投药量下出水浑浊度、UV254的变化情况,每组数据中包括当天模型预测加药下出水水质与人工加药下出水水质,水质数据均为当前投药量下运行稳定后1 h在线数据(在线数据采集间隔以min计)的平均值。与人工投药相比,采用模型预测投药时,沉淀池与砂滤池出水浑浊度均有不同程度的降低,但对UV254的去除未见差异。将人工投加和模型预测加药量进行药耗对比,以两种投药量下分别运行24 h计,模型预测加药的情况下PAC、FeCl3分别需要3.24、1.09 kg;而人工加药的情况下PAC、FeCl3分别需要3.38、2.13 kg,说明采用模型预测加药能有效节省药剂消耗。

表3 两种加药方式下的水质对比Tab.3 Comparison of Water Quality between Two Dosing Methods
3 结论与建议
1)与随机森林、LSTM、支持向量机等算法相比,基于南水北调水源的水质特征,采用XGBoost算法构建混凝投药模型效果最优,其构建的PAC模型MAPE评估值为3.39,FeCl3模型MAPE评估值为3.89。将混凝投药模型应用于中试工艺系统,提升出水水质的同时降低了药耗。
2)数据采集是构建水厂智能投药模型的基础,原水时均水量、浑浊度、温度、历史加药数据的精细统计对混凝剂投加量的准确预测有重要影响。
3)使用箱线图结合移动平滑的技术进行异常值的处理,小时粒度的水量、加药数据结合在线水质数据对混凝投药模型的构建有大幅的提升。将一种药剂的投加量作为另一种药剂预测的特征值输入的方法,对双药投加模型的预测效果提升有限。
