基于粒子群算法的番茄酱成分检测及品质分析
2021-09-10李繁
李 繁
(新疆财经大学,乌鲁木齐 830012)
番茄酱是一种深受消费者喜爱的调味品,其品质直接影响消费者的健康状况。对番茄酱的成分检测和品质分析具有重要意义,番茄酱品质检测分析方法主要包含理化指标检测、成分检测、微生物检测以及感官评价,检测过程复杂,且需要耗费大量的时间,对检测样品具有较大的破坏性,检测成本高,无法满足食品安全检测过程需求[1-2]。随着光谱成像技术的发展和快速检测的需求,利用光谱成像技术对番茄酱进行无损检测,并采用粒子群算法对检测数据进行混合优化,实现番茄酱成分的快速检测,同时对番茄酱品质进行预测,成为食品安全检测过程的重要手段[3-4]。
番茄酱营养成分丰富,以番茄为原材料进行浓缩加工,其中的可溶性固形物和番茄红素是影响番茄酱口感和品质的关键因素,也是评价番茄酱品质的重要指标[5]。
番茄酱中可溶性固形物含量测试复杂,且影响因素较多,番茄酱中糖类物质、有机酸物质和其他相关物质的代谢均会影响番茄酱的可溶性固形物含量[6]。番茄红素是番茄酱中的关键着色物质,在食用过程中,番茄红素具有较好的抗氧化性,能够抑制人体中氧化性自由基的产生,同时消除人体中的氧化自由基,减少皮肤受外界辐射的影响[7-8]。
对番茄酱中可溶性固形物含量的测定主要采用折射仪,对番茄酱中番茄红素的检测方法主要为分光光度计和高效液相色谱相结合的方法,检测过程具有较高的准确性,但需要消耗大量的试剂,试验成本高,难以进行快速、有效的检测。本文采用多光谱成像技术对番茄酱中的可溶性固形物含量和番茄红素含量进行检测,并利用粒子群算法建立番茄酱品质预测模型,为番茄酱品质检测提供了理论依据。
1 番茄酱成分预测
本文采用8种不同的番茄酱样品,按照不同的比例进行混合,制作成120种新的番茄酱样品,选取其中的80个番茄酱新样品作为校准集,剩余的40个番茄酱新样品作为预测集。采用多光谱成像技术对新制作的番茄酱样品进行图像采集,并对图像进行阈值分割,获取有效的番茄酱光谱图像,并提取出光谱信息。
称取40 g新制备的番茄酱待检测样品,放置于烧杯中,并加入100 mL蒸馏水,搅拌均匀后煮沸,并冷却至室温。间隔20 min,对冷却后的样品进行称重,并进行过滤,留取滤液进行遮光率测定,采用折光仪对滤液的遮光率进行检测,并计算番茄酱样品中可溶性固形物含量。
式中:η表示番茄酱中可溶性固形物含量,D表示溶液中可溶性固形物质量分数,m1表示稀释后的滤液质量,m0表示稀释前的滤液质量。
称取0.2 g新制备的番茄酱待检测样品,置于10 mL容器中,加入甲醇,立即搅拌均匀,抽取溶液中的黄色素,重复以上步骤,直至黄色素被完全提取,保留残渣备用。向残渣中加入甲苯,提取残渣中番茄红素,采用高效液相色谱法进行番茄红素含量的测定。
2 番茄酱成分数据分析
实验测得8种番茄酱样品中可溶性固形物和番茄红素含量,见图1和图2。8种番茄酱样品平均光谱数据见图3。
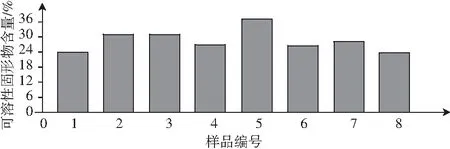
图1 番茄酱中可溶性固形物含量Fig.1 The content of soluble solids in ketchup
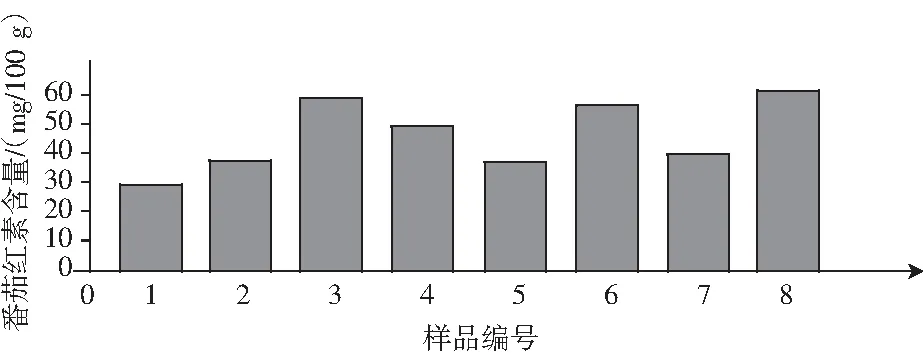
图2 番茄酱中番茄红素含量Fig.2 The content of lycopene in ketchup
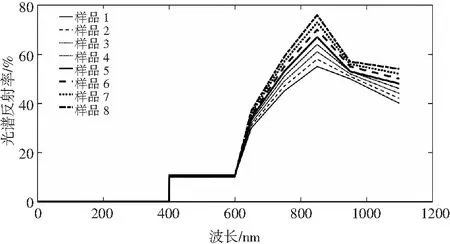
图3 番茄酱样品平均光谱曲线Fig.3 The average spectral curves of ketchup samples
由图3中曲线可知,不同的番茄酱样品,光谱曲线变化趋势相似,但不同番茄酱样品光谱之间具有微小的差异,该差异可用来研究番茄酱成分差异。番茄酱光谱变化区域范围在波长650~950 nm之间,因此通过番茄酱光谱数据能够有效进行可溶性固形物和番茄红素含量的定性测定,当进行大量的数据测定时,光谱曲线之间会造成重叠。为有效进行番茄酱中可溶性固形物和番茄红素含量的定量测定,本文对番茄酱光谱数据进一步进行多变量分析。
3 预测模型的建立
番茄酱样品中可溶性固形物和番茄红素测定完成后,分别采用偏最小二乘法、偏最小二乘法支持向量机算法以及粒子群算法建立成分定量预测模型。
偏最小二乘法是一种多元统计分析方法,通过选取潜在变量,构成番茄酱光谱数据现象组合,并采用影响因子确定分析物比例[9-10]。偏最小二乘法预测模型可表示为:
式中:X表示光谱矩阵,Y表示浓度矩阵,P表示光谱矩阵的主成分矩阵,EA表示最小二乘法拟合输入值误差矩阵,EC表示最小二乘法拟合输出值误差矩阵。
偏最小二乘法支持向量机算法能够同时进行线性分析和非线性分析,可根据多元输入因素,快速回归出预测结果[11-12]。偏最小二乘法支持向量机算法预测模型可表示为:
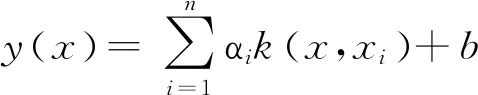
式中:n为样品数量,αi为拉格朗日乘数,k(x,xi)为核函数,b为偏置向量。
利用粒子群算法模型进行分析过程中,首先对控制参数和粒子群规模进行优化,再计算出粒子群最佳位置和速度,使优化目标达到最小值时,选取样本方差的粒子群适应度函数[13-14]。
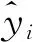
粒子群算法是一种智能随机优化算法,通过迭代的方式寻找最优解,操作简单,使用广泛。粒子群算法迭代更新过程可表示为:
式中:Pij表示第i个粒子在第j维上的最佳位置,Pgj表示第g个粒子在第j维上的最佳位置,mbest表示个体最佳位置中心点,mbestj表示维最佳位置中心点,M表示粒子群规模,Pi表示第i个粒子最佳位置,PCij表示Pij和Pgj之间的随机位置,α为控制参数,u,φ⊂(0,1)。
4 番茄酱品质预测
通过对3种模型中校准绝对系数、预测绝对系数、校准均方根误差、预测均方根误差以及相对预测误差进行比较,选取出番茄酱成分的最佳预测模型。番茄酱可溶性固形物预测结果对比数据见表1。番茄酱中番茄红素预测结果对比数据见表2。
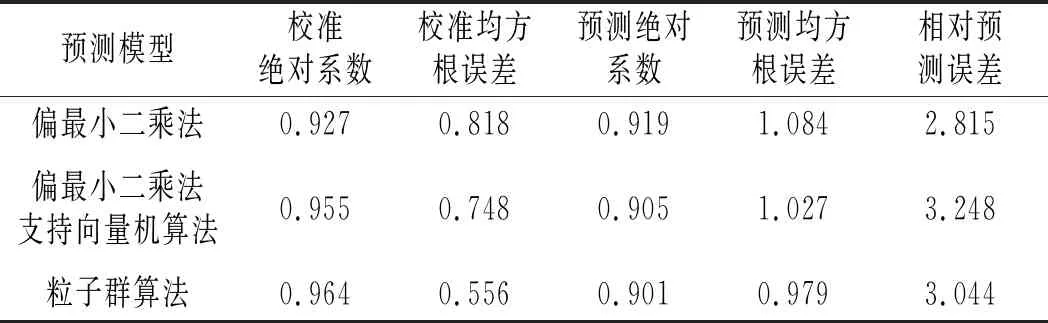
表1 番茄酱可溶性固溶物预测结果数据对比Table 1 Comparison of predicted results of soluble solids in ketchup
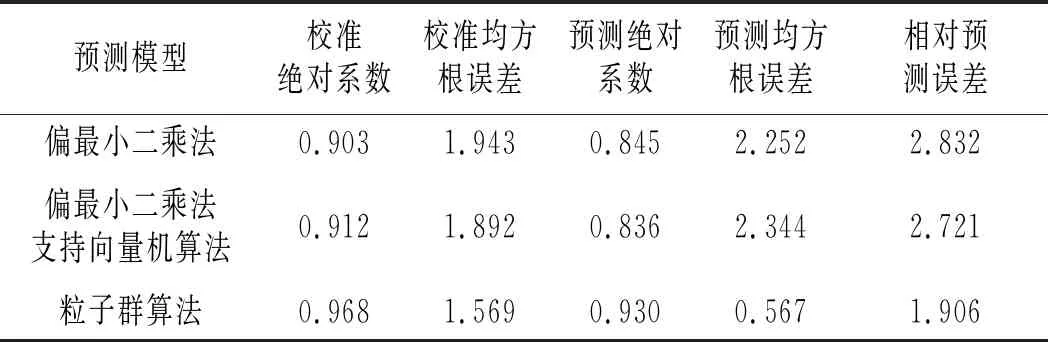
表2 番茄酱中番茄红素预测结果数据对比Table 2 Comparison of predicted results of lycopene in ketchup
由表1可知,采用偏最小二乘法、偏最小二乘法支持向量机算法和粒子群算法3种模型的校准绝对系数分别为0.927,0.955和0.964,偏最小二乘法的校准绝对系数略小于其他两种预测模型;偏最小二乘法的校准均方根误差和预测绝对系数均优于其他两种预测模型;偏最小二乘法的预测绝对系数略高于其他两种预测模型。结果表明,偏最小二乘法预测模型的预测性能低于偏最小二乘法支持向量机算法和粒子群算法两种预测模型。偏最小二乘法支持向量机算法和粒子群算法两种模型的预测性能接近,且粒子群算法模型的相对预测误差低于偏最小二乘法支持向量机算法模型。表明在进行番茄酱可溶性固形物含量预测时,粒子群算法模型是一种更接近实际应用的预测模型。
由表2可知,采用偏最小二乘法、偏最小二乘法支持向量机算法和粒子群算法3种模型的校准绝对系数分别为0.903,0.912和0.968,粒子群算法的校准绝对系数高于其他两种预测模型;粒子群算法的预测均方根误差和相对预测误差分别为0.567和1.906,均小于其他两种预测模型;偏最小二乘法和偏最小二乘法支持向量机算法的预测绝对系数均小于0.85,对应相对预测误差均大于2.7。表明在进行番茄酱番茄红素含量预测时,粒子群算法模型是一种更接近实际应用的预测模型。
5 结论
本文通过多光谱成像技术,获取番茄酱样品的光谱图像,并分割出能够对番茄酱样品光谱进行检测的有效区域,实现对番茄酱中可溶性固形物和番茄红素的快速检测,提取出番茄酱的光谱图像信息,同时利用偏最小二乘法、偏最小二乘法支持向量机算法和粒子群算法建立3种预测模型,通过对比方式,确定粒子群算法预测模型为番茄酱中可溶性固形物和番茄红素预测最有效的模型,为番茄酱品质快速实时检测奠定了理论基础。
