基于注意力机制的自监督单目图像深度估计
2021-09-09彭涛胡智程刘军平张自力黄子杰
彭涛,胡智程,刘军平,张自力,黄子杰
(1. 武汉纺织大学数学与计算机学院,武汉 430201;2. 湖北省服装信息化工程技术研究中心,武汉 430201)
0 引言
近年来,随着人工智能技术高速发展,图像深度估计对计算机视觉具有重大研究意义。为了更好地获得场景的深度信息,众多学者已进行了大量研究。2014年,Eigen等人[1]首次引入深度学习的概念,提出使用两个尺度的卷积神经网络结构对单目图像进行深度估计,采用大量带有标注深度信息的数据集进行训练。2015年,Eigen和Fergus改进了文献[1]中算法,在原有的网络基础上加入采样网络[2],加深了网络结构。Jun等人[3]在Eigen等人[2]的多尺度网络基础上加入跳跃连接,加速了网络收敛。Daniel等人[4]通过学习顺序对图像的某些特征进行深度估计,但该方法没有直接估计特征的度量值。上述研究采用有监督的训练方式,需要使用具有真实深度信息的图像数据集作为目标训练,在单目图像深度估计中,很难大规模获取每像素地面真实深度数据。因此,部分学者提出了自监督的单目深度估计方法[5-12]。Garg等人[5]提出了通过全卷积神经网络生成深度图,并使用传统的双目摄像头测距原理重构源输入图像,对比原输入图像,构建目标函数,进而反向训练网络得出深度图结果。Zhou等人[7]把未做标记的单目视频的每一帧图像作为训练集,使用深度估计网络和相机位姿网络对其进行训练。Eldesokey等人[10]提出了自监督的概率归一化的卷积网络,该方法估计了输入数据的不确定度,使得网络可以基于数据可靠性进行针对性的学习,实现了输出不确定度的估计。由于现有的数据集存在物体间遮挡以及物体运动等问题,因此,上述采用自监督方法的研究不仅未能利用好场景中上下文信息,而且深度估计的结果会受到物体遮挡、纹理复制伪影、轮廓不准确等影响。
为了解决上述问题,本文提出在深度网络模型中加注意力机制并结合最小化光度重投影函数,对目标图像前后帧中选择最小误差进行匹配。主要贡献如下:①提出了一种新的深度网络架构,将注意力机制与深度网络相结合,提升了相对远距离物体轮廓显示,同时使得物体轮廓呈现更为精准,提高了准确率;②结合最小化光度重投影函数和自动掩蔽损失,对目标图像前后帧中选择最小误差进行匹配,解决物体被遮挡的问题,减少了物体伪影。③在KITTI数据集[13]和Make3D数据集[14]上的对比实验结果表明,相比于文献[5-8,15-17],本文所提方法结果更优,实现了基于注意力机制的自监督单目图像深度估计。
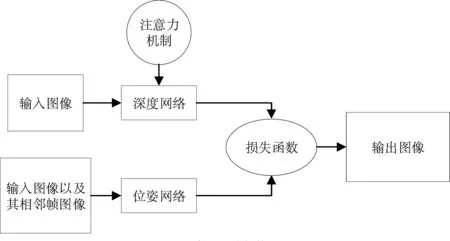
图1 整体网络架构图
1 整体网络框架
本文参考Zhou等人[7]单目深度估计算法的思想,采用深度网络和位姿网络联合工作的网络架构,网络架构图如图1所示。其中,深度网络是由加入注意力机制的深度网络(Attention-UNet)和ResNet18相融合的编码、解码架构结合而成,网络输入的是某时刻的单帧图像。位姿网络[7]参照的是Zhou等人[7]的网络结构,输入的是三帧相邻时刻的图像。本节将从深度网络模型的构造来和损失函数介绍本文提出的自监督单目深度估计方法。
1.1 结合注意力机制的深度网络
注意力机制在分割网络[18]上表现良好,视觉系统倾向于关注图像中辅助判断的部分信息并忽略无关的信息。注意力机制可以选择物体聚焦的位置,能够极大程度上节约资源,使物体特征更具分辨性。而自注意力机制(self-attention)[19]对注意力机制进行了改进,能更好地获取数据和特征的相关性,减少外部信息的干扰。因此,在编解码极端处引入自注意力机制,可以敏锐地关注到更重要的特征信息,合理利用有限的视觉信息进行针对性的处理。加入注意力机制的深度网络结构如图2所示。本文深度估计网络基于Attention-UNet体系结构,在解码时,将编码器输出的部分输入Attention Gate处理后再进行解码,本文使用的自注意力机制模块如图3所示。
其中,将前一隐含层x∈RC×N的图像(C为通道数,N为特征所在的位置数)特征转化为f、g两个特征空间来计算注意:
f(x)=Wfx,g(x)=Wgx
(1)
(2)
公式(1)中Wf、Wg都是网络的参数。公式(2)中βj,i表示在合成第j个区域时模型关注第i个位置的程度。
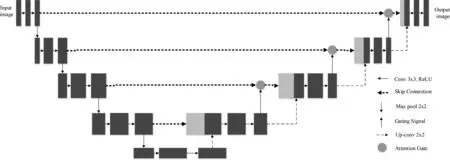
图2 加入注意力机制的深度网络结构图

图3 Self-attention结构
图3的self-attention模块中,self-attention结构自上而下分为三个分支,图片x经过一个第一个分支时,经过一个1×1的卷积,将得到f(x)。依次往下,图中第二个分支,首先经过一个1×1的卷积操作,得到g(x),将转置后的f(x)与g(x)进行矩阵相乘,得到attention map I,注意层的输出为:
ο=(ο1,ο2,…,οj,…,οN)∈RC×N
(3)
其中:
(4)
在最后一个分支,经过卷积核为1×1的卷积层获得h(x),将attention map I转置,转置后每一列权重和为1。将h(x)与转置后的attention map I相乘可以得到某个点的最终值,最终输出特征图yi为:
yi=γοi+xi
(5)
其中γ是一个可学习的参数,并且初始化为0,往后再逐渐增大权重。
在其他条件一致的情况下,对增加注意力机制前后的结果进行对比,对比图如图4所示,从图中可以看出,加入注意力机制后的深度预测比未加的效果要更好,相对远处的物体轮廓更清晰,层次感更强。

图4 加入注意力机制前后对比图
1.2 损失函数
本文的损失函数是参考Godard等人[6]和Zhou[7]的损失函数的方法,对自动掩蔽损失的光度重投影损失函数和边缘感知平滑函数[6]加权求和。本文将目标图像表示为It,每个源视图相对于目标图像的相机姿态表示为It′→t,其中光度重投影误差[6]表达式为:
Lp=∑pe(It,It′→t)
(6)
公式中为pe为光度重投影误差,其定义为式(7),其中∂ 为图片的SSIM相似度所占的比重,SSIM为图片结构相似度函数。为了生成的视差图各个部分能够尽可能地平滑,对∂ 进行L1惩罚。
(7)
最终的每像素最小光度损失表达式为:
Lp=minpe(It,It′→t)
(8)
本文采用自动掩蔽[15]方法解决处理图像的伪影问题,同时,将像素掩码μ损失应用于掩蔽损失,有选择地对像素进行加权,μ∈{0,1}在网络前向传递时自动计算。该函数表达式为:
μ=[minpe(It,It′→t) (9) 最终的训练损失函数为每像素边缘感知平滑函数Ls[6]和结合了自动掩蔽损失的光度重投影损失函数之和,并分别求平均值。 L=μLp+λLs (10) 其中λ为常数,取值为0.001取值参考Godard等人[6]的设置。 本文使用主流的KITTI 2015数据集[13]进行训练,该数据集是是当前最大的自动驾驶场景下的计算机视觉算法测评数据集,包含了城市、住宅、道路、校园和行人。实验中,对KITTI数据集进行了拆分,拆分后的39810张图片用于训练模型,4424张图片用于验证。训练后的模型在KITT2015数据集[13]和Make3D数据集[14]上进测试验证。 本文提出的深度网络基于Attention-UNet体系结构,即具有跳过连接和注意力机制的编解码器网络,既能表示深层抽象特征,又能表示局部信息。本文提出的模型需要进行预训练,训练次数为20,批大小为12,输入/输出分辨率为640×192。本文的实验训练使用GPU为NVIDIA Tesla v100,GTX 2080显卡、64G显存的服务器。系统为CentOS 10。整个输入输出网络采用PyTorch搭建,训练时间为12个小时。 实验使用了Eigen等人[1]的数据分割方法,用单目序列进行训练,遵循Zhou等人[7]的预处理来去除静态帧。在评估期间,按照标准做法将深度限制在80米,并使用每幅图像的中位数地面真值缩放来报告结果。实验数据衡量指标中,平均相对误差Abs Rel、平方根相对误差Sq Rel、线性均方根误差RMSE、对数均方根误差log RMSE的值越小表示结果越好,准确率δ的值越大表示结果越好。 表1和表2是加入注意力机制前后的实验结果对比,实验对比数据结果表明,在深度网络中加入注意力机制后,在KITTI 2015数据集[13]上表现更优异。由大量注意力模块组成的深度网络,能产生注意力感知的特征,同时网络中使用了大量的Skip-Connections,能把所有特征信息融合,加速网络收敛[3],故一些稀少的具有负面作用的特征信息也得到了加强,进而提升了模型的性能。 表1 加入注意力机制前后在KITTI数据集上的误差测度对比 表2 加入注意力机制前后在KITTI数据集[13]上准确率指标对比 表3列出的现有方法与本文方法在KITTI 2015数据集[13]上(使用Eigen等人[1]的数据分割方法)评估的结果可以看出,本文的方法明显优于现有的自监督单目深度估计训练方法。实验结果如图5所示,可以观察到本文的单目深度估计算法在三个场景中的结果明显优于其他算法。例如,场景C中可以看出,Yang等人[15]的实验结果存在明显的伪影,越深处轮廓越模糊,而本文的实验中左侧汽车、右侧柱子与相对远处的车辆轮廓都能够很好地呈现。因此,文中方法所得到深度图轮廓更准确,对场景深度图的边缘处理地更好,可视化效果更理想。 表3 实验结果对比 表4给出了在Make3D数据集[14]上的测试结果。我们采用与Godard等人[6]相同的测试方案和评估标准进行比较。从表4可以看出,本文提出的方法比以前同样基于自监督的方法产生了更好的结果。 图5 KITTI 2015测试集结果对比图 表4 在Make3D数据集上的误差测度结果 本文提出了一种基于注意力机制的自监督单目深度估计方法,通过在深度网络模型中添加注意力机制并结合最小化光度重投影函数,对目标图像前后帧中选择最小误差进行匹配,解决了单目图像深度估计研究中监督学习存在的边界伪影、轮廓不清晰、预测范围较小等问题。本文所提方法模型经过实验验证,相比于目前的单目深度模型算法,在加入了注意力机制后误差测度和某一阈值下的准确率都达到了最优。本文算法相比其他工作达到了最先进的性能,但是本文所提的位姿网络还有待改善。未来工作是进一步改善本文网络结构中的位姿网络,提升网络的精度。2 实验过程
3 结果分析





4 结语
