Arrow在分布式查询引擎中的应用与研究
2021-09-09张世同
张世同
(北京云至科技有限公司南京分公司,数据服务产品研发部,南京 211801)
0 引言
近年来,大数据技术领域列式存储成为主流,现代CPU技术借助流水线技术、SIMD(Single Instruction Multiple Data)指令、向量计算,大幅提升处理性能。内存越来越廉价,借助内存提升性能成为可能。数据来源复杂,数据格式多样化,出现了复杂、嵌套数据格式。用户对数据处理效率的要求日益迫切。
以Presto、Drill、Impala、Kylin为代表的查询引擎采用MPP技术,使用SQL的方式,对底层异构的大数据存储进行访问。未来查询引擎向数据发现、数据治理、自助服务的方向发展,即让业务人员在无IT人员的参与下,可以顺利工作,从繁杂的原始数据中,发现数据、聚合数据、形成高质量的数据、发布数据服务。这时,查询引擎的查询、更新性能就变得尤为重要。
本文介绍了一种基于MPP和Arrow内存列存储的数据查询引擎ADE(Agile Data Engine)的设计和实现,ADE有效提升了查询引擎本身的性能和跨系统数据通讯效率,再结合预计算和SQL重写技术能够满足OLAP场景下常规查询和即席查询(1)常规查询在系统设计时是已知的,可以事先通过建立索引、分区等技术来优化。而即席(ad-hoc)查询是用户在使用时临时产生的,系统无法预先优化这些查询,所以即席查询也是一个重要指标的需求。
1 研究现状
1.1 分布式查询引擎的现状
分布式查询引擎的兴起,起源于Google的Dremel,随后Cloudera开源了大数据查询分析引擎Impala,Facebook开源了Presto,Hortonworks开源了Stringer,Apache基于Hadoop原生SQL的HAWQ[9],国内的Kylin、Druid等。Apache基金会的顶级项目Drill是业界比较接受的Dremel的开源实现。文献[5]将这些分布式查询引擎分为基于预计算思想的计算引擎和实时计算引擎两类。
基于预计算思想的计算引擎,通过提前的聚合存储操作,通过SQL重写技术把一个计算任务转换成查询操作,本质上减少计算量,如Kylin[15]。该类查询引擎的缺点:①立方体的构建具有维度爆炸问题,无论对计算能力还是存储能力都提出了挑战。②由于数据查询分析分布具有聚集性,所以,立方体中的大量club从来没有使用过,浪费了计算资源和存储资源。所以对该类查询引擎的研究,主要是立方体物化策略的研究[5]。
实时计算引擎,每次查询都需要对数据进行聚合计算,所以实时性并不是很高不能达到实时的标准[5]。对该类引擎的研究,主要集中在优化执行计划和存储,如位图索引、列式存储[1,3]、查询计划优化[2,6]等。查询计划优化研究,目前有基于规则、成本、运行时的查询计划优化以及基于算法的查询优化等。
1.2 内存列式存储的现状
目前内存数据库已经成熟,常见的内存数据库有SAP-HANA[18]、Ignite、Geode等。SAP-HANA支持行存储和列存储,而Ignite和Geode都是以Key-Value格式存储。它们在分布式内存网络方面,都已经有了成熟的实现和应用。
在大数据MPP计算领域,列存储也已经普遍,如文件列存储格式Parquet、Avro等;内存列存储格式如SAP-HANA、Spark、Drill等都在应用。但是目前内存列存储格式还由各软件自行定义和进行内存管理,没有统一的格式标准和读写接口,这就意味着跨系统数据传输时,避免不了数据序列化反序列化操作。
纽约大学的Pilaf[16]和微软研究院的FaRM[17]采用RDMA(Remote Direct Memory Access)技术,实现内部节点之间的数据通讯和整个分布式系统对外共享内存读写接口,较少序列化反序列化,极大提高效率。
Arrow内存列存储就是为了解决当前内存列存储无标准的问题,它为内存列存储格式和数据读写接口提供了标准,并已经实现了C++、Go、Java、Python、R、Ruby和Rust等多种编程语言,可以有效提升查询引擎的效率又可以实现跨系统数据传输,而无需进行数据序列化反序列化。
2 Arrow技术基础
Arrow是跨语言、跨平台的内存列式存储格式。具备传统列式存储的优势,同时具有内存数据快速访问、复杂格式、内存网格化的优势。Arrow具备以下特征:①充分利用现代高性能CPU的SIMD指令,支持向量计算。②利用内存缓存区, 线性紧凑定义数据结构,提高Cache命中率和CPU读取数据效率。③统一内存格式,避免或减少异构系统之间序列化反序列化。④利用共享内存或者直接内存访问,实现zero-copy。⑤支持复杂数据Schema和动态Schema。⑥易于采用内存网格化技术,实现分布式内存计算,大幅提高性能。
2.1 Arrow内存布局
Arrow内存结构支持基本类型(固定长度)、可变长度二进制、固定长度List、可变长度List、结构体类型、稀疏联合类型、Null类型、字典类型等。这些指的是物理存储类型,所有逻辑数据类型,均使用这些物理存储类型设计。逻辑类型为整型、长整型、日期类型、字符串类型等。

图1 Int32的向量内存布局
Int32向量的内存布局如图1所示,元数据记录向量长度、空值个数,理论最多可以存储231-1元素。Bitmap位图,记录非空值索引,例如示例中有效bitmap为1字节,字节长度对齐为64字节(2)64字节对齐,取决于IntelCPU AVX-512指令集特点,对512位64字节提供更高的性能。。
is_valid[j]->bitmap[j/8]&(1<<(j%8))
(1)
判断位置j是否为有效值is_valid为公式(1):内存缓冲区是一段连续的内存区,按照64字节长度对齐。对于空值,不分配字节值。

图2 字符串向量内存布局
字符串类型的向量内存布局使用可变长度List
slot_position=offsets[j]
(2)
slot_length=offsets[j+1]-offsets[j]
(3)
有些属性列是关联字典,重复存储造成空间浪费、影响检索性能。可以设计成字典类型、通过Int32索引引用字典值。
2.2 Arrow内存模型
Arrow 基于NettyJEMalloc实现了内存分配器Allocator,它基于数据块分配器内存。整个内存结构呈树型结构,如图3所示。

图3 内存分配器(Allocator)的树型结构
树型结构的内存分配器(Allocators),有利于分功能分配、管理、检测、回收部分内存区。每个内存分配器有预留容量(可用于计算)和最大容量。预留容量不会被数据占用,这意味着整个生命周期中都是被计算分配的。Arrow向量数组使用Off-heap堆外内存。手工管理和释放内存区,不依赖于GC。内存负载管理,检测内存溢出风险、检测内存分配器的使用情况,决定是否写入部分数据到磁盘。每个查询计划Operator都创建了一个Allocator,它还可以创建自己的子Allocator,用于对该Operator内的每个数据分片进行处理。
2.3 Arrow数据传输格式
Arrow 以Batch的方式,封装数据及其模式进而进行数据传输。即用Batch的方式把一定数量的数据记录(包括所有属性列)及其Schema封装在Record Batch中。有Dictionary Batch和Record Batch两种形式。数据传输的Message逻辑结构如图4。

图4 数据传输Message逻辑结构
数据模式(Schema)定义了数据的逻辑结构,属性逻辑类型,指定了属性的字典类型编码。字典类型Batch,把字典属性进行编码存储,记录中仅存储字典编码。记录类型Batch分属性向量存储实际数据。
以记录类型Batch为例,其数据分为:数据头、各属性的bitmap区、offsets区、数据区。其中数据头记录该batch的类型(Dictionary batch、Record batch、Schema),各属性向量的长度和空值个数,各属性向量的内存地址。一个属性向量占用连续的物理内存,整个Batch在网络传输时,连续字节传输。一个Batch中可以存储 1-64K条数据记录。
3 ADE架构设计与关键技术
ADE包含Coordinator、Executor两个角色,两者通过zookeeper协调。Zookeeper记录了Coordinator和Executor的节点名称、IP、内存、CPU等信息。Coordinator负责接收用户端SQL请求、解析SQL语法树、生成Logic Plan、获取并存储数据表的元数据、分配Executor节点、执行每个分区数据的Logic Plan,并汇总SQL结果返回给客户端。Executor负责执行在每个分区数据的Logic Plan,发送结果数据给Coordinator。Coordinator和Executor之间通过gRPC进行并行通信。
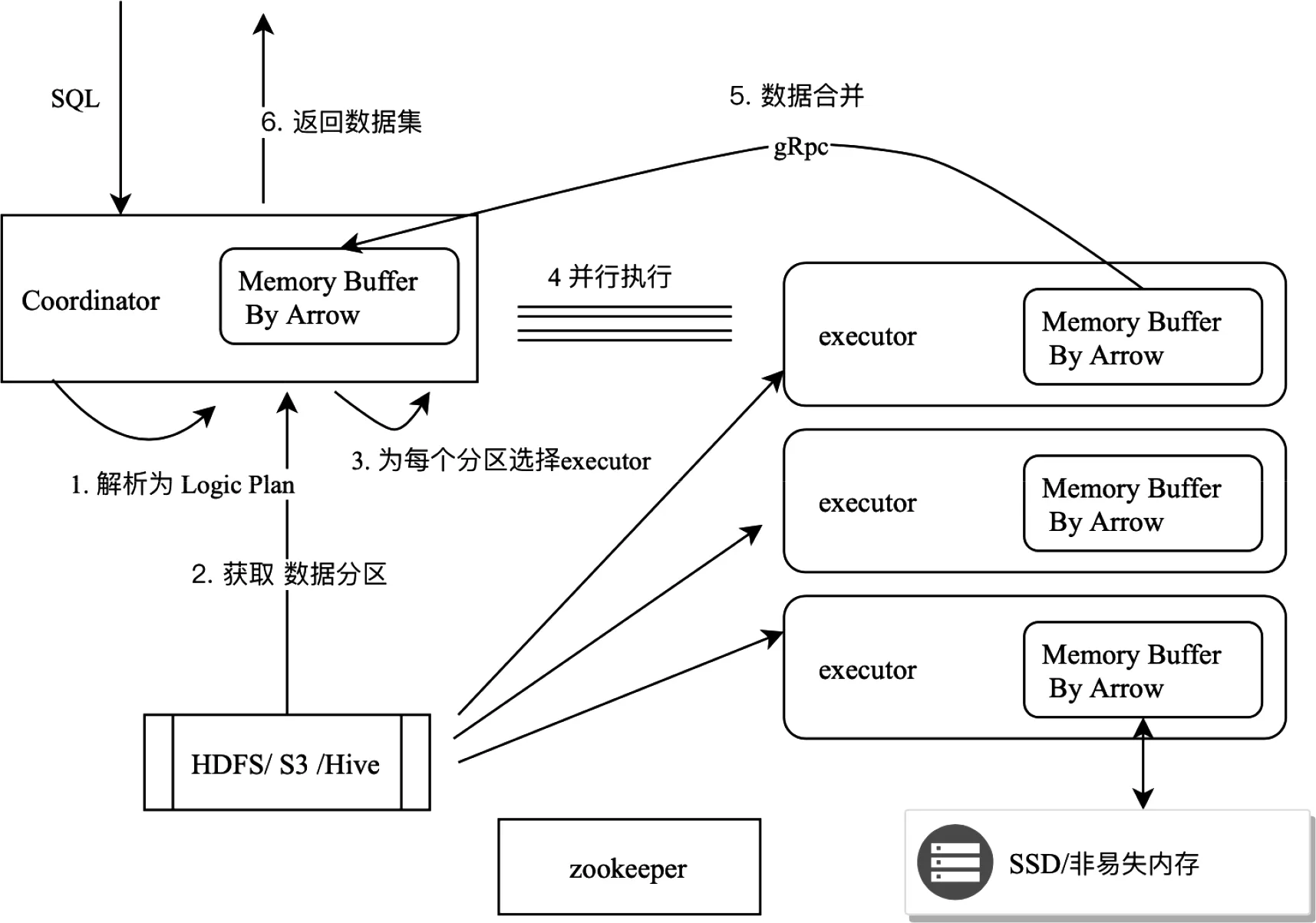
图5 查询引擎ADE的架构设计
3.1 面向向量的执行计划

图6 向量在执行计划Operator之间传输
传统的基于行存储的查询引擎,在查询计划节点之间传递的是行或者Tuple对象。通过调用next方法,逐行的处理数据。在大数据环境下,函数调用上下文切换的时间消耗,不可忽略。而且在OLAP中的聚合运算,往往只需要部分列,Tuple中却包含了所有的列数据。相反,列存储以向量的方式计算和传递数据,向量数据以Record Batch 的格式,在Operator之间传输。向量运算和传递,充分利用了SIMD指令,快速实现FILTER, COUNT, SUM, MIN 。OLAP典型的计算是复杂Join、数据聚合和数据扫描。以如下SQL为例详细介绍ADE查询引擎的工作方式:
SELECT avg(wholesale_cost), avg(list_price) FROM store_sales
Operator的Allocator之间有父子关系,同查询计划的父子关系。父Operator能够访问子Operator的Allocator的数据。Scan算子选择四个字段,扫描数据封装在Record Batch中。Filter算子扫描store_sk向量,过滤出store_sk=7的行,记录在Filter Vector向量中。Filter Vector的格式为4个字节的向量数组,结构为(batch_index,row_index)。其中1-2字节标识Batch的Index,3-4字节标识在该Batch中的位置。如(3,68)。Aggregation算子,通过构建Hash Table来计算Avg平均值。分为两个步骤:

图7 面向内存向量的过滤与聚合运算
扫描Record Batch中Group By字段(item_sk),Avg字段(list_price、wholesale_cost)使用SIMD指令扫描,Item Vector构建新的Record Batch。
对上述Record Batch扫描字段(item_sk)进行转置成行式数据,对所有Keys字段计算Hash值并构建Hash Vector,进而构建Hash Table,在Hash Table中进行Aggregation运算。Hash Table是常用来进行Hash Aggregation/Hash join的数据结构。
3.2 过滤和排序实现
在执行过滤和排序操作时,使用一个索引向量,来标识符合条件的数据行或者使用索引向量顺序标识向量值的顺序。因为一个batch设计为最多64K条记录。所以用Int16整数表示。Batch之内,使用2字节的整型0,12,17表示行索引号。标识多个Batch数据,使用4字节的,区间索引。0-12表示第一个batch的第12行记录。
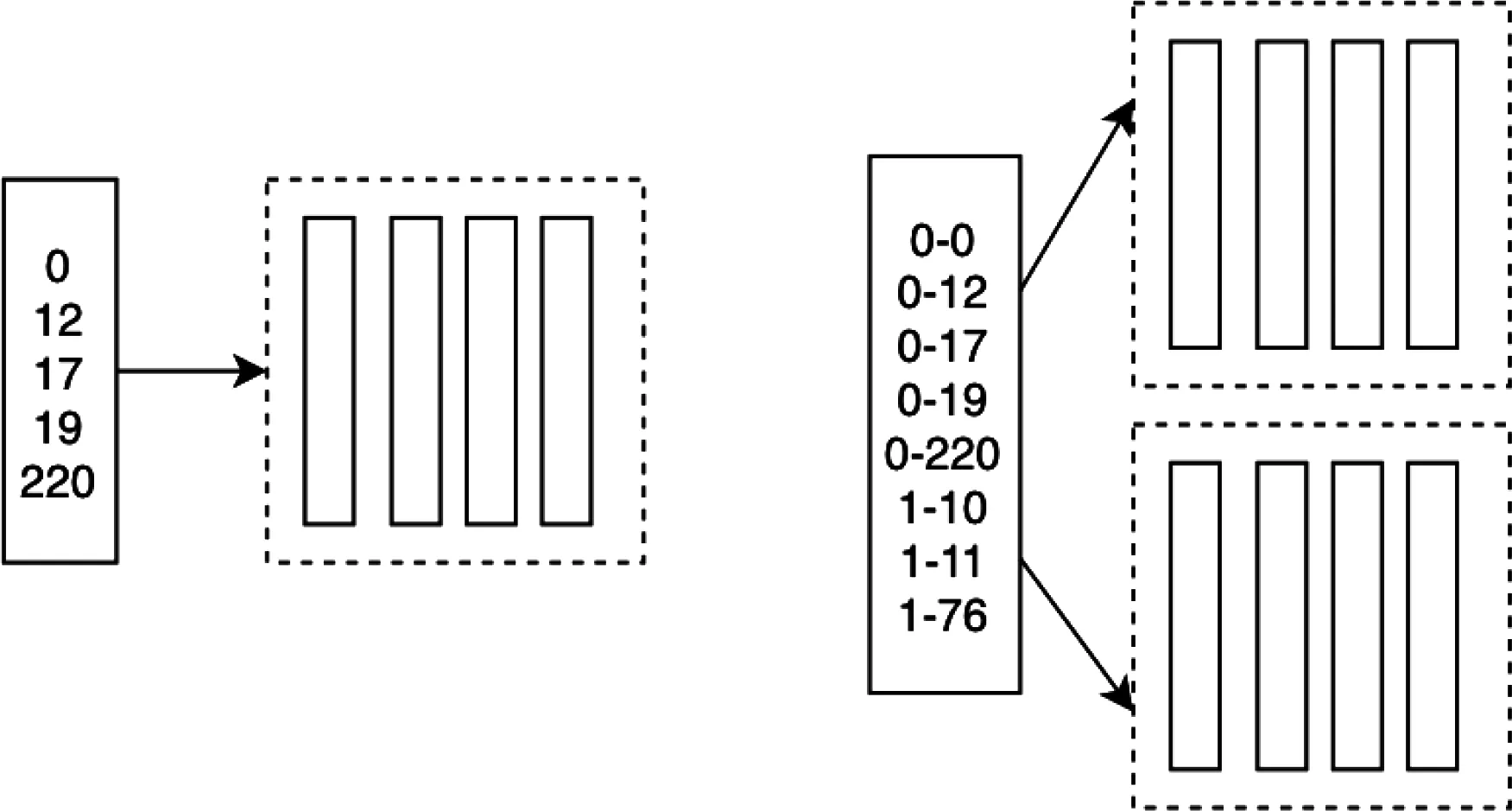
图8 FilterVector实现过滤和排序
执行过滤操作时,一次Scan就能过滤出符合条件的记录,不需要改变原始数据得结构,只需要构建一个索引向量。输出查询结果时,只需要根据这个FilterVector和字段映射选择某些字段向量匹配索引输出即可。
执行排序操作时,使用选择排序算法或者冒泡排序算法,依次把最大到最小值的索引放在FilterVector中。输出查询结果时,只需要根据这个FilterVector和字段映射选择某些字段向量匹配索引输出即可。
3.3 Hash关联与Hash 聚合运算
在实践中发现,列式存储格式,不利于进行HashJoin、HashAggregation运算。因为列式存储对HashTable的插入、查找是低效的。因此,需要在计算之前先转置成行的格式。首先,把GroupBy字段进行转置成行数据,然后构建Hash Table。如图9所示。

图9 数据转置和构建Hash Table
3.4 节点数据迁移优化
节点之间Shuffle数据仍然是按照Record Batch封装,每个Record Batch都开启一个线程进行数据传输,而Record Batch过滤后可能仅有很少的数据,这无疑就增加了上下文交换、任务调度、线程资源开销。为此本文中使用多路复用技术、在发送端重新组装Record Batch。
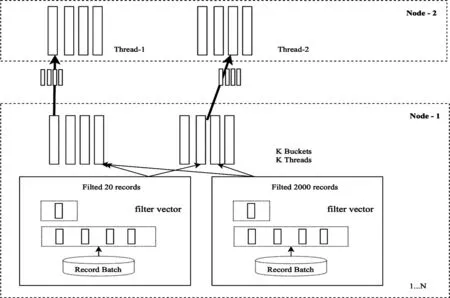
图10 多路复用节点间数据传输
如图10所示,N个RecordBatch最终分配到K个Buckets进行数据传输,K即集群节点数。Filter Vector后的数据,首选对Key进行Hash,生成Bucket Id,为此,每个RecordBatch生成Bucket Vector。然后,所有遍历Record Batch,根据Bucket Vector把数据分配到对应的Bucket,并根据记录数等参数,每个Bucket数据都封装成多个Record Batch。为每个Bucket启动一个线程,进行数据传输。优化前节点间数据交换次数为(K-1)* N,优化后为(K-1)* K。
3.5 动态估算Batch Size
Arrow以Batch的方式存储和传输数据,在内存的数据,往往要比在磁盘上大,因为在磁盘上可以压缩,而在内存中一般不压缩,因为要支持随机读取等操作。Batch是处理数据得最小执行单元。适当的Batch Size有利于集中计算,提高Operator之间数据传输效率,减少上下文交换,减少计算任务调度次数,提升整体效率。Batch Size过大可能会造成Operation之间数据传输异常。Batch Size过小会增多上下文交换、增加线程数量、增大数据处理时内存overhead消耗。除此之外,批次大小还要考虑数据表的宽度、字段数量、平均字节数等因素。
ADE实现了根据表宽、字段数自动调整Batch Size。一般情况下Batch size在127-4095之间。计算公式为:
(4)
其中:bi为第i个字段的固定字节长度,h为行固定开销一般为128字节,C为字段数量。W为表宽的调整因子,当C大于100是为1,当C小于100是为2。使用公式(6)把batchsize计算结果调整到127-4095的范围内。
W=2ifC≤100
1ifC>100
(5)
batchsize=min(max(pre_batchsize, 127), 4095)
(6)
3.6 RPC数据传输协议
Batch的字段内部是连续的内存存储,字段之间的内存区是不连续的。在RPC 传输时,修改传输协议头,一次性连续传输所有字段的数据。并且增加RPC连接失败回调处理方法,发生传输异常时进行重试,而不是简单的异常断开连接。
3.7 数据压缩和优化
使用字典类型进行数据编码和查询优化。例如可以将全国省市字典加载,数据中使用Int32类型表示。原来重复每行记录需要存储的省市名称,现在只需要用一个有限长度的字典向量即可。这样,可以减少数据存储量,压缩数据。同时,把可变长度字段变为固定长度Int32类型,提高计算过滤、分组统计效率。如图11所示。

图11 字典类型向量压缩
3.8 并行查询接口
ADE作为其他大数据组件(如Spark)的数据源,则JDBC访问方式会成为瓶颈。因此该平台设计了并行查询接口,如上图MPP并行计算引擎Spark,如图12所示。ADE和Spark之间,使用Arrow Flight RPC传输数据,详细过程分为三个阶段:①发送SQL语句,ADE开始运行SQL,并生成运行基本数据,包括数据分片、执行节点、各节点的RPC的Endpoint。②客户端向ADE发送doGet命令,请求发送数据,同时建立一个监听器,监听ADE发回的数据。ADE建立数据发送通道,不停地把数据集push到客户端。③ADE发送数据完毕,发送complete指令。或者客户端主动cancel 数据获取动作。如图12所示。
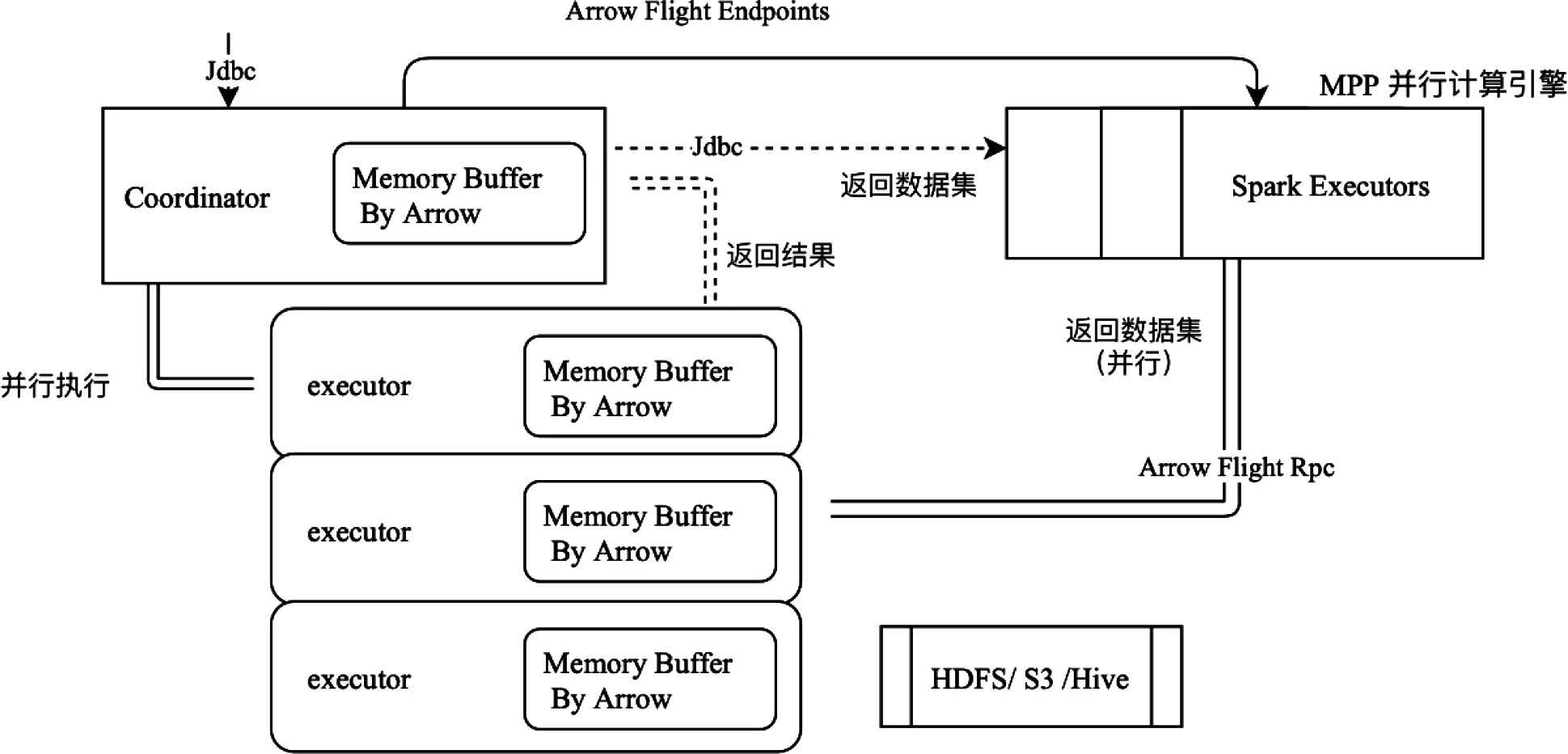
图12 并行查询接口架构
3.9 实验效果分析
该项目采用TPC-DS测试工具集,与Hive on Spark、Apache Drill进行对比验证。Hive on Spark配置为Executor四台(8 Cores、10G内存、500G磁盘);Driver一台(8 Cores、32G内存、500G磁盘)。Drill配置为四台(8 Cores、4堆内存、8G堆外内存、500G磁盘)。ADE配置为Coordinator一台(8 Cores、32G内存、500G磁盘),Executor四台(8 Cores、4堆内存、8G堆外内存、500G磁盘)。
TPC-DS测试工具集生成1GB的数据量,并对数据根据时间分区。使用5线程数据负载测试,每个线程均按照随机顺序运行TPC-DS的84个SQL查询语句(3)TPC-DS有标准的99条SQL语句,该文去除了15个函数不兼容的SQL语句。总体耗时对比结果如表1所示。
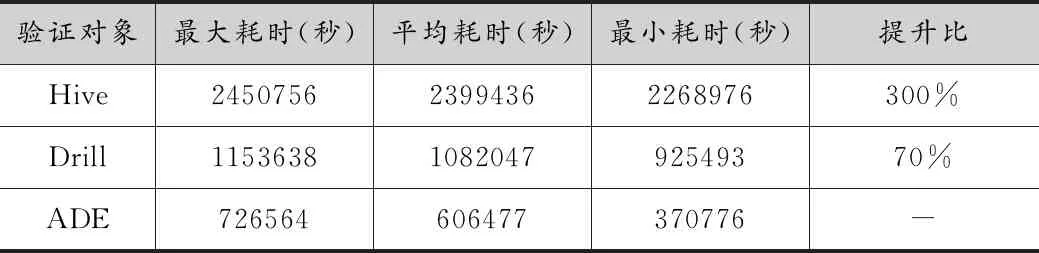
表1 TPC-DS测试数据对比
采集压测过程中84条SQL的耗时数据,分别把ADE与Hive、Drill对比,如图13所示。可见,在大多数SQL语句中,ADE性能大幅提高,比较Hive提升了近300%;比较Drill提升了近70%。在压测过程中,观察CPU负载情况,如图14所示。可见,在SQL并行运行过程中,Hive的CPU负载较大波动,CPU利用率低;Drill的CPU负载相对比较平稳,CPU利用率高;ADE的CPU负载最为平稳,CPU利用率最高。

(a) Hive on Spark 与 ADE SQL耗时对比

(b) Apache Drill 与 ADE SQL耗时对比

(a) Hive on Spark的CPU利用率
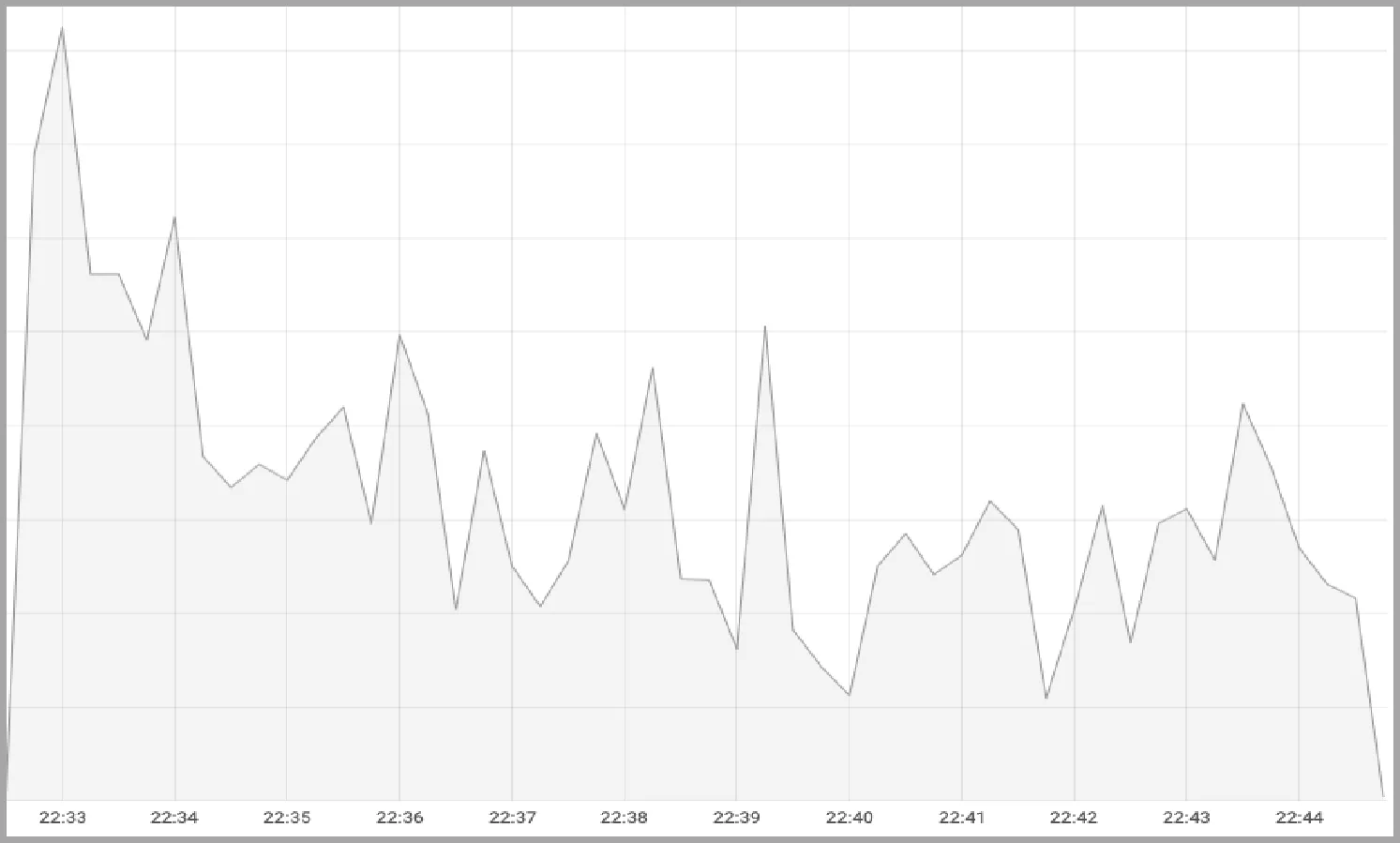
(b) Apache Drill的CPU利用率

(c) ADE的CPU利用率
4 结语
本文介绍了一种基于Arrow技术设计和实现的一种内存列存储查询引擎ADE,详细介绍了SQL查询中向量计算、内存使用的方法,并描述了其中的关键技术及优化策略,包括:过滤排序、节点数据Shuffle、Hash聚合运算、Hash Join、Batch Size估算、并行查询接口等。经与Hive on Spark、Apache Drill的验证对比说明ADE在面向OLAP场景的数据源联合查询中有效提高了查询性能。
进一步的展望,可以着重在SQL的兼容性和预计算技术两个方面。ADE的SQL兼容性应符合ANSI SQL-99标准,并支持大多数的函数运算。ADE结合预计算和SQL重写技术,进一步提高常规查询的性能。
