基于K-means聚类的运动处方推荐方法
2021-09-09李博胡世平贾年
李博,胡世平,贾年
(西华大学计算机与软件工程学院,成都 610039)
0 引言
快节奏、高强度的生活方式使人们出现神经衰弱、精神紧张等亚健康状态,长时间久坐不动又让人们有了颈腰椎疾病、肩周炎、肥胖等慢性疾病。如何通过科学有效的运动处方改善这些症状,是当下人们最关心的问题。但是大多数人对慢性疾病缺少正确的认识,同时对运动处方认识不够,造成尝试了很多处方却达不到预期效果的情况。因此,我们要通过科学、健康、合理的运动处方即通过科学的体育锻炼达到健身的目的,从而使自己的机能水平进一步提高。
运动处方可以理解为:由康复医师、体育教师、私人健身教练等,根据患者或者体育健身者年龄、性别、康复医学检查、运动试验、身体素质测试等结果,按其年龄、性别、健康状况、身体素质以及心血管、运动器官的功能状况,结合主客观条件,用处方的形式制定对患者或体育健身者适合的运动内容、运动强度、运动时间及频率,并指出运动中的注意事项,以达到科学地、有计划地进行康复治疗或预防健身的目的。
针对上述问题,本文提出一种基于K-means聚类的运动处方推荐方法,将个性化推荐技术应用于运动处方推荐,为用户提供个性化的运动处方。
1 理论基础
1.1 K-means聚类算法
K-means的中心思想是要确定常数k,常数k表示最终的类别数。首先随机选定初始点为簇心,并通过计算每一个样本与簇心之间的距离(一般为欧氏距离),将样本点归到最相似的类中,接着,重新计算每个类的簇心,重复这样的过程,直到簇心不再改变,这样就确定了每个样本的类别以及每个类的簇心。
假设待聚类的数据集为:X={xi|xi∈Rp,i=1,2,3,…,m},包含m个数据样本,K个聚类中心分别为:C1,C2,C3,…,Ck。用Wj(j=1,2,3,…,k)来表示聚类的类别[2],具体算法步骤如下:
定义1:两个数据对象间的距离:
(1)
定义2:每个簇中对象的平均值:
(2)
定义3:准则函数:
(3)
(1)从m个数据对象中任意选择k个对象作为初始中心,每个对象代表一个聚类中心;
(2)利用公式(1)计算X中各个样本数据到聚类中心的距离,根据计算得出的最小距离,将样本归入到最相似的簇中;
(3)更新簇的平均值,即通过公式(2)重新计算聚类中心,作为新的簇心;
(4)重复步骤(2)-(3),直到准则函数E取值不再变化为止。
1.2 相似度计算方法
假设有m个用户的集合U={U1,U2,…,Um}和n个项目的集合I={I1,I2,…,I3},rij表示用户i对项目j的评分,则用户评分矩阵如下所示:
余弦相似度:
(4)
其中,计算的结果值越接近1,说明用户的相似度越高。
皮尔逊相关系数:
(5)
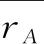
1.3 运动处方相关研究
运动处方内容主要包括运动目的、运动项目、运动强度、运动时间、运动频率、注意事项等。运动目的可以是减肥、健身、预防老年病、增强肌肉力量等,由于每个人的需求不一样,其目的因人而异。为了进行健身的安全、有效,运动项目的制定要经医学检查许可,运动方式、运动强度、运动量应符合本人的体力等。运动强度是衡量运动量的重要指标之一,是运动处方定量化的核心问题,通常情况下通过心率来确定和控制运动强度。对于运动时间,不能一概而定,可以根据运动强度、运动频率、年龄和身体条件具体制定。科学研究表明,每周锻炼3-4次是最适宜的频度,不仅效果可以充分蓄积,也不产生疲劳,如果频率增加到每周4次或者5次,效果也相应提高。
2 运动处方推荐方法
2.1 本文算法简述
本文运动处方推荐的算法主要分为以下几个步骤:
输入:用户—项目评分矩阵R,簇类数目K。
输出:N个推荐项目。
(1)通过以Mi(i=1,2,3,…,k)为初始簇心,将矩阵R通过K-means算法分成k类;
(2)通过公式(1)计算用户和k个簇心的相似度,把用户加入到与其最相似的类中;
(3)计算用户与同类中的用户的相似度,得到最近邻居集合Nj(j=1,2,…,m);
(4)得到用户对推荐项目的预测分。
(6)

算法的执行流程图如图1所示。
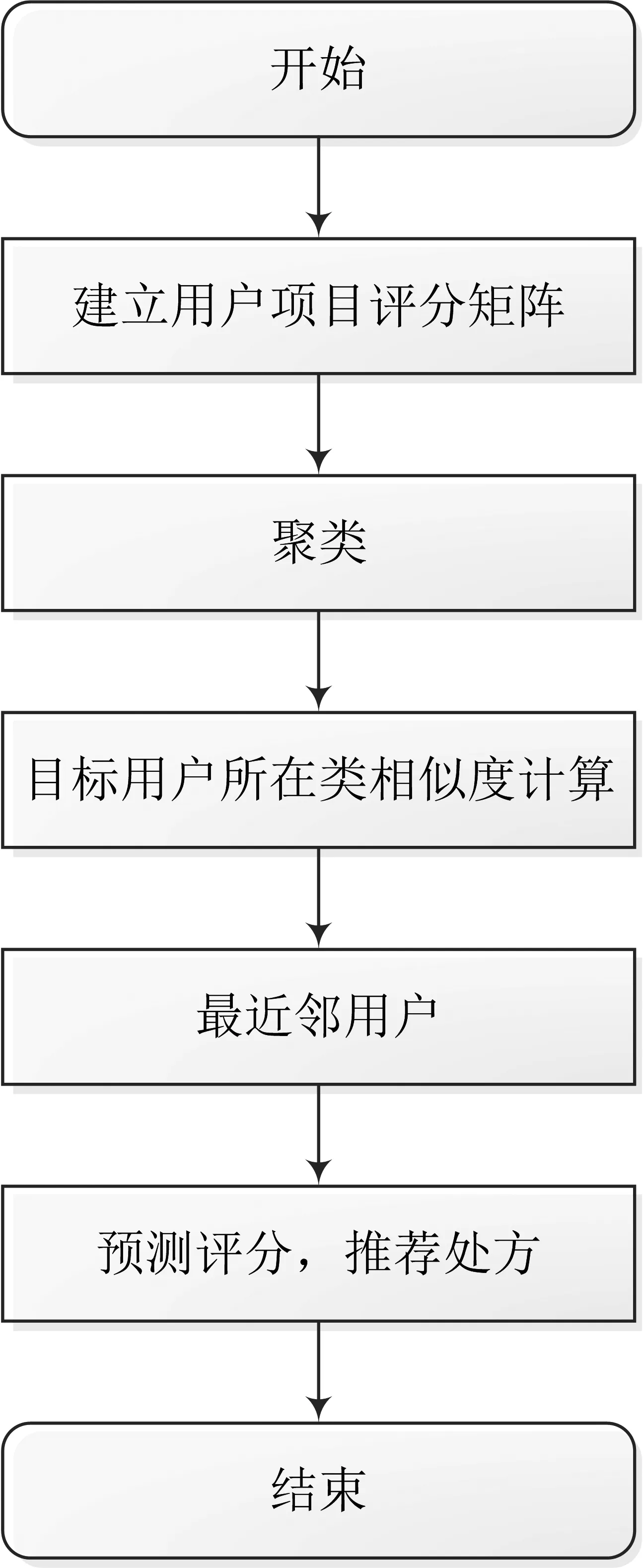
图1 算法流程图
2.2 数据获取
本文数据获取来之四川某高校的大学生信息,主要包括学生个人信息和处方信息。个人信息主要有姓名、身高、BMI、肺活量等数据。处方信息包括学生对运动处方的满意度信息,将满意度设定为5分制,5分为最满意,1分为最不满意,0分代表未对运动处方做出评价。本算法用到的数据有姓名、项目和评分3部分组成。
2.3 用户相似度计算
一般相似度计算的方法常见有两种,一种是皮尔逊相关系数,另一种为余弦相似度。本文采用余弦相似度计算用户间的相似度,即通过公式(4)计算用户的相似性。
(1)通过对搜集到数据进行处理,使用MATLAB将原始评分数据转换成一个用户-项目评分表,如表1所示。
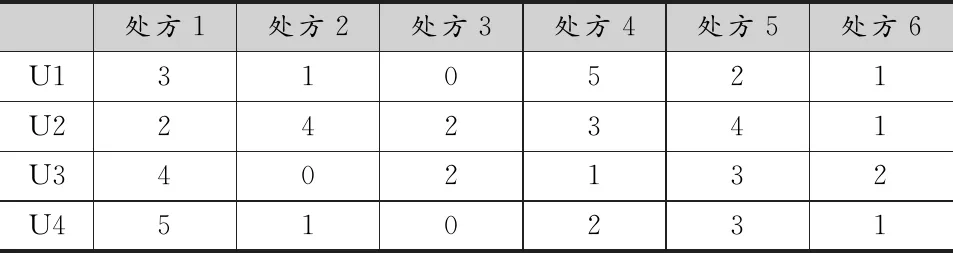
表1 用户-项目评分矩阵
(2)通过计算用户与同类其他用户的相似性,得到用户的最近邻居集合。寻找最近邻居利用公式(4)进行计算。
2.4 预测评分并产生推荐
根据用户的最近邻居集合对项目的评分,通过公式(6)计算用户对项目的预测评分,对评分的项目进行从高到低排序后,把前N个项目推荐给用户。
3 实验结果及分析
本文采用平均绝对误差MAE作为评测标准,验证推荐结果的好坏。MAE是通过计算用户预测评分与实际情况评分之间的误差来衡量准确性的,MAE的值越小,代表推荐结果越准确。其公式如下所示:

最近邻的个数也是影响推荐效果的重要因素之一,本实验通过比较传统运动处方推荐算法和基于聚类的运动处方推荐方法在不同最近邻个数情况下的MAE值,说明推荐的效果。结果如表2。

表2 MAE值比较
通过分析实验结果可以看出,本文推荐方法的MAE值更低,由此可见推荐效果更优,推荐质量更高。
4 结语
本文提出的基于聚类的运动处方推荐算法,与传统的运动处方推荐相比,准确度更高,效果更好,更能符合用户的具体需求。通过本文的推荐方法可以找到适合自己的运动处方进行锻炼,从而提高身体素质。
