基于权限聚类的属性值优化
2021-09-08毋文超任志宇杜学绘
毋文超,任志宇,杜学绘
基于权限聚类的属性值优化
毋文超1,2,任志宇1,杜学绘1
(1. 信息工程大学,河南 郑州 450001;2. 中国人民解放军31668部队,青海 西宁 810000)
在新型大规模计算环境下应用ABAC(基于属性的访问控制)面临着属性数量多、来源复杂、质量参差不齐、难以人工修正、难以直接应用于访问控制的问题。针对属性标称值的优化问题,设计了一种基于权限聚类的属性值优化算法,通过将实体表示成对应的权限集合,对实体进行基于密度的聚类,为实体赋予权限对应的类别标签,而后基于粗糙集理论对属性值进行化简与修正。最后在UCI公开数据集上对算法进行了验证,证明应用该算法后,ABAC策略挖掘在真阳性率和1得分上均具有较大的提升。
属性值优化;粗糙集理论;基于属性的访问控制;访问控制
1 引言
在云计算、大数据等新型计算环境下,实体数量繁多、安全需求复杂、权限动态变化,以及传统的访问控制模型难以直接适用于新型计算环境,基于属性的访问控制(ABAC,attribute-based access control)机制以属性作为权限判决的依据,可以较好地满足大规模环境下复杂的访问控制需求[1]。作为权限判决的基本依据,属性质量的高低直接关系到ABAC能否实施及其实施的效率[2]。然而在新型计算环境中,实体的属性来源复杂、质量参差不齐,需要对属性进行预处理以获取优质决策属性集[1]。
属性约简可从属性集中选出完备的较小的属性子集,目前已经有较多关于属性约简的方法,但这些方法无法获取比原属性集更加完备的属性子集,约简后的属性集质量依赖于原属性集中的属性质量,无法修正标定错误的属性。在云计算、大数据环境中,属性数量多、来源复杂、质量参差不齐,人工修正属性标定的难度极大,亟须研究自动化的属性标定质量优化技术。
属性按其性质可以分为标称属性、序数属性、区间属性和比率属性。其中标称属性只对相等和不等操作有意义,性质简单、易于分析,其他类型属性的约束都可以用等价的标称属性约束代替,因此标称属性被广泛应用于ABAC策略挖掘中[3-5]。但真实环境中的属性类型不全为标称属性,属性标定质量良莠不齐,现有的相关研究集中在将其他类型属性转化为标称属性上,缺乏对标称属性值本身进行优化的研究。如果属性标定质量过低,会导致策略臃肿、策略执行效率低,甚至无法构建正确完备的策略。针对该问题,本文提出了一种基于主客体权限关系聚类的属性值优化方案,通过权限信息对实体进行聚类,而后基于聚类中实体属性的分布信息,为低质量的标称属性调优。
2 相关工作
属性预处理是ABAC策略挖掘的重要前置工作,其目标是获取用以访问控制决策的最优属性集。它可以抽象为决策表中属性的约简优化,主要分为两方面:一方面是属性数量约简,目标是从蕴含冗余信息的原始属性集中挑选出最小的属性子集,同时保证该属性集维持原始属性集的权限区分能力[6];另一方面是属性值优化,包括将属性转化为易于处理的类型、合并冗余属性值以及修正错误的属性标定,使属性能够清晰地表达权限关系。
邓大勇等[7]对属性约简准则进行了归纳,证明了以条件属性信息熵为约简准则的约简与绝对约简等价、在一致决策表中以联合熵为约简准则的约简与绝对约简等价;指出了其他类型的约简仅仅不损失本约简准则下的信息,但可能损失条件属性信息熵下的信息。属性约简结果往往不是唯一的,研究者通常使用启发式算法获取其中的一个,而难以从多个约简中选出最优。邓大勇等[8]提出了属性约简重心的概念,从而选择距离重心最近的属性约简作为最优的属性约简,并通过实验进行了证实。张维等[9]提出了一种处理部分标记数据的粗糙集属性约简算法,针对有标记数据获取困难的问题,基于半监督协同学习理论为半监督数据设计了属性约简算法,该算法利用大量无标记数据提高了有限有标记数据属性约简的质量,但损失了约简的性能。曾孝文等[10]提出了一种基于粗糙集理论的属性值约简改进算法,将不相容的决策表划分为若干个相容的子决策表,而后在子决策表中尝试删除属性值来消除不相容,该算法会产生属性语义上的损失。
本文针对传统的属性预处理方法在属性值优化方面存在的问题,提出了一种基于权限聚类的属性值优化算法,对实体按照权限关系进行聚类,而后通过分析聚类内属性值的分布,对属性值进行优化,去除冗余值、修正错误值,使属性能够更加有效地应用于访问控制。
3 问题描述
3.1 属性
属性被用来描述实体的性质,如教师的任教科目、学生的班级、试卷的科目等。研究者通常使用如下性质区分属性的类型。
属性按以上性质可以分为标称属性、序数属性、区间属性和比率属性[11],它们的特点和常见的示例如表1所示。

表1 属性分类
标称属性仅对相等和不相等操作有意义,基于标称属性构造的策略形式最为简单直观,现有的策略构建与验证方法大多依赖于高质量标称属性,在属性质量较低时表现不佳。因此本文针对标称属性值的优化进行研究,从而为策略构建与维护提供有力保障。
3.2 基于粗糙集的属性优化问题
属性优化可以抽象为决策表的属性值优化问题。粗糙集理论是处理不完整、不确定知识的数学工具,该理论认为知识的本质是分辨能力,它也是决策表属性约简的重要工具。本文根据粗糙集理论将属性优化问题定义为信息系统中属性的优化问题。
定义1 信息系统
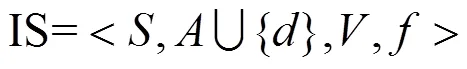
定义2 不可分辨关系
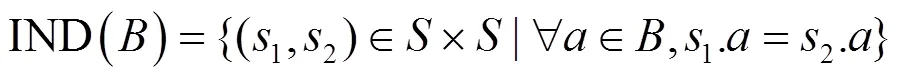
定义3 下近似集
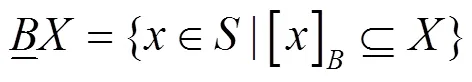
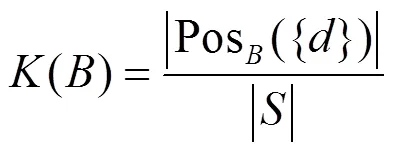
4 基于权限聚类的属性值优化
在ABAC中,属性是ABAC进行权限判决的依据,权限判决可以看作以属性为特征,判决结果为标签的分类过程。但根据权限判决结果分类所得的类别只有两个,难以利用粗糙集理论对属性进行有效的优化。因此本文根据主客体的权限关系中主体对应的权限集合,为主体分类赋予足够的类别标签,以便通过粗糙集理论对主体属性进行优化,使其更加清晰准确地区分主体的权限(客体属性的优化与之相同,将客体按对应的权限集合进行分类,而后优化,下文均以主体属性的优化为例)。
4.1 构造主体的权限集合表示
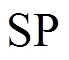
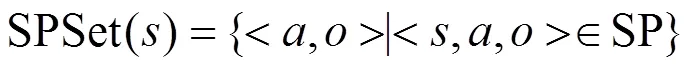

4.2 主体聚类
聚类的目的是为主体分配类别标签,为属性优化提供依据。聚类的依据为主体的权限,即该主体能访问的客体的集合,因此采用Jaccard距离作为距离标准。
定义6 Jaccard距离
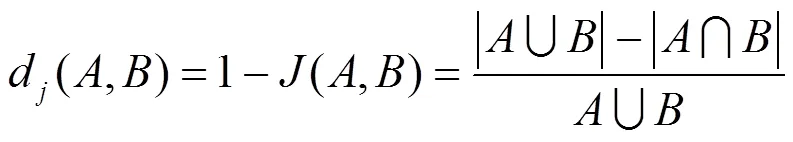
DBSCAN是一种基于密度的聚类算法,它基于中心来定义密度,数据集中某个点的密度通过对该点长eps的半径之内的点计数(包括本身)来估计,每个核心点eps邻域应该具有的最少数据点数由参数min_pts确定。相比于最常用的算法-means,它不需要指定聚类的数目,且对于噪声的容忍能力较强,能够处理任意形状和大小的簇、高效地对主体按权限集合进行聚类。
4.3 属性值优化
属性值可能存在的问题分两方面。一方面是多个相同意义的值导致的冗余;另一方面是属性值错误。因此属性优化值也包含两步:合并冗余值和修正错误值(错误标定的属性值)。
第一步是合并冗余值。实体的属性不可避免地存在相同意义的值,以客体的属性为例,CPU和中央处理器具有相同的含义,但如果在进行策略制定时没有考虑到这一点,就会导致策略臃肿。对于具有相同意义的属性值,直接将其合并。在信息系统中,判断属性值是否具有相同意义的方法是查看属性值区分类标签的能力是否相同,即属性值关于类标签的分布是否相同。
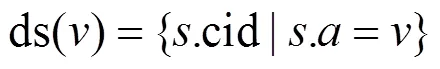
5 算法实现
5.1 主体按权限聚类
将主体按其具有的权限聚类的过程如算法1所示,首先根据主体权限关系,统计出每个主体具有的权限,保存入sor字典(第1行),而后初始化所有主体的聚类标识为UNCLASSIFIED(第3行),存入clusters字典,继而对主体进行基于密度的聚类(第4~18行)。
算法1 主体聚类
5.2 合并同分布属性值
这一步把每个属性同分布的值进行合并,如算法2所示,首先统计每个属性值在哪些聚类中出现过,以及出现的频率(第1行),分别存入ds和freq,将具有相同分布的属性值保存到一起(第3~9行),存入二维列表dealt,然后对同分布属性值进行合并(第10行)。为了加快聚类集合的比较,将ds按聚类集合的长度排序,只比较长度相同的集合。
算法2 同分布属性值合并
5.3 低频属性优化
这一步尝试将频率低于阈值的属性值合并到在同一聚类内出现过的其他值上,如算法3所示,首先初始化保存所有的属性名称(第1行),然后计算去掉某个属性后属性集对聚类标签的支持度,存入AttrKDict(第2行),接着将属性名按照AttrKDict中的支持度从低到高进行排序,存入队列(第3行),进而依次从中取出属性,找出该属性的低频属性值,尝试将其修改为该属性的其余值,若支持度不下降,则将值对存入pairs列表(第5~13行),最后依据pairs对newSar进行更新(第14行)。
算法3 低频属性优化
6 实验验证
6.1 实验环境与数据集
实验环境为Ubuntu 18.04操作系统,配置为Intel Core i7-8750H CPU,16 GB内存;使用Python3.7编写代码,实现了基于Jaccard相似度的DBSCAN算法;编写了基于权限聚类的属性优化算法。
实验数据集为UCI的Amazon Access Samples公开数据集[12],数据集信息如表2所示,其中HOST,PERMGROUP,SYSTEM_SUPPORT为3种不同的客体,值为ID,PERSON_ID为主体ID。
6.2 实验结果
实验1 聚类参数选取
为了保证属性优化的效果,所得的聚类数目必须合适,同时被标记为噪声点的主体不能太多。表3和表4分别为调整参数eps和min_pts对应的噪声点占比情况和聚类数目情况,可以看出,随着eps增大,噪声点占比逐渐下降,聚类数目逐渐减少;随着min_pts增大,噪声点占比逐渐增大,聚类数目逐渐减少;在eps较大时,min_pts变化对噪声点占比和聚类数目的影响都会减小。
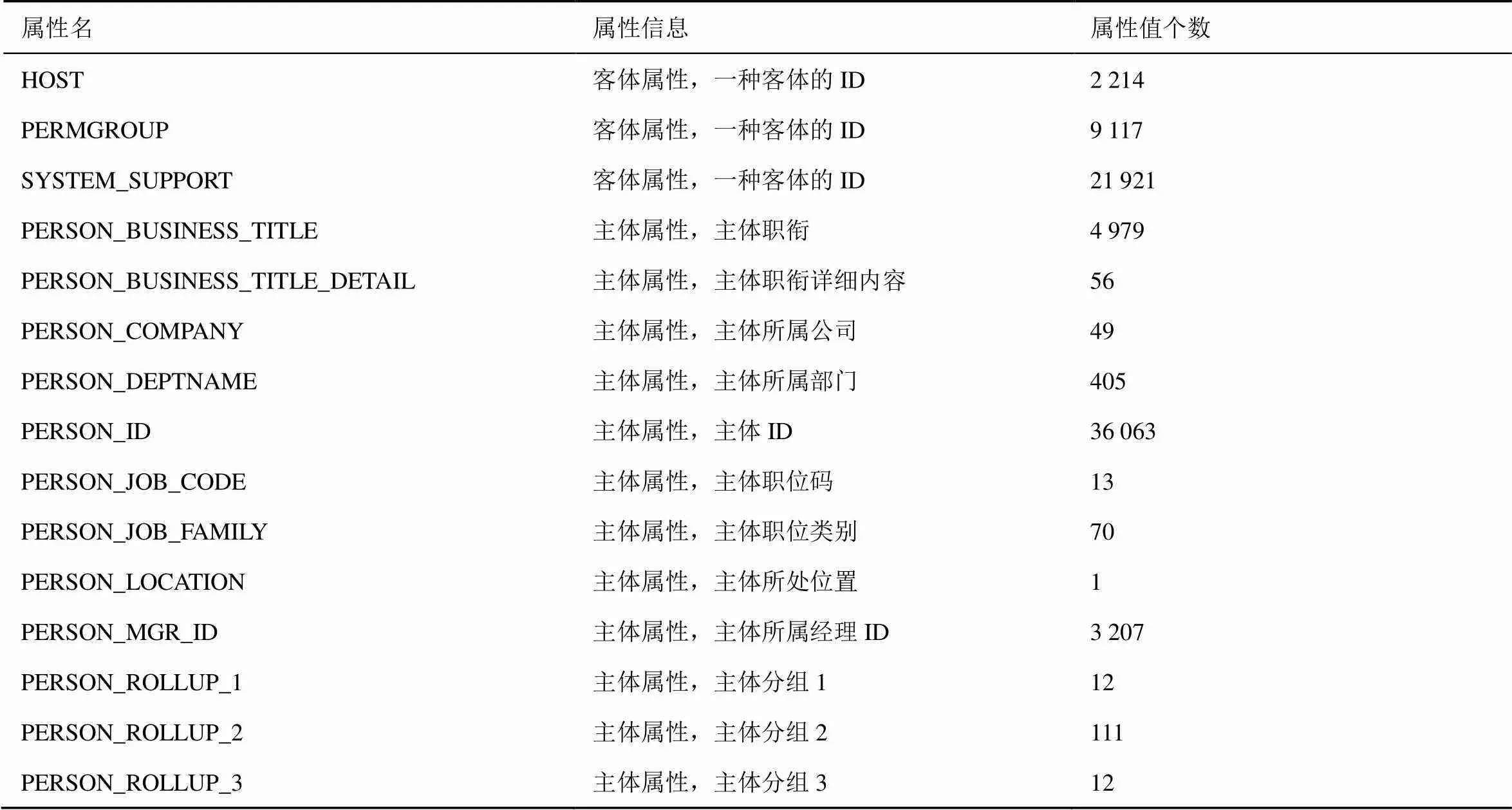
表2 数据集信息
当eps取0.6和0.7时,虽然噪声点占比不高,但聚类数目只有3个,对主体的区分能力太弱;当eps取小于0.5的值时,有超过0.01的主体无法被分类,因此eps取0.5。在eps取0.5的前提下,当min_pts取大于5的值,均有超过0.01的主体无法被分类,对后续优化影响较大,因此min_pts取5。
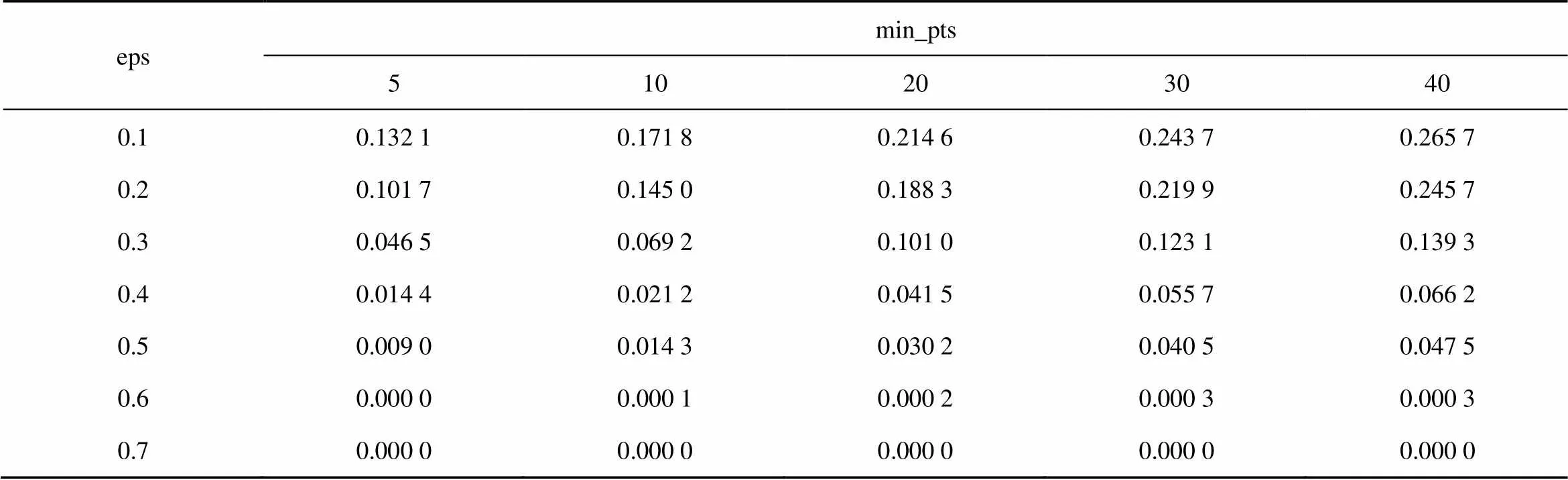
表3 调整参数eps和min_pts对应的噪声点占比情况
实验2 属性优化结果
应用算法完成属性值优化后,利用FPGrowth算法对主体权限关系进行策略挖掘,并比较优化前后FPGrowth算法在真阳性率(TPR,true positive rate)和F1得分等评价标准上的表现。本文使用的数据集中权限关系相比于所有主客体的组合特别稀疏,因此采用对稀疏访问支持更好的关联规则挖掘算法对算法进行验证[4],利用pyfim库[13]中的FPGrowth算法来进行策略挖掘,如图1、图2所示。本文提出的属性值优化算法对FPGrowth算法挖掘授权规则的真阳性率和F1得分有较明显的提升。
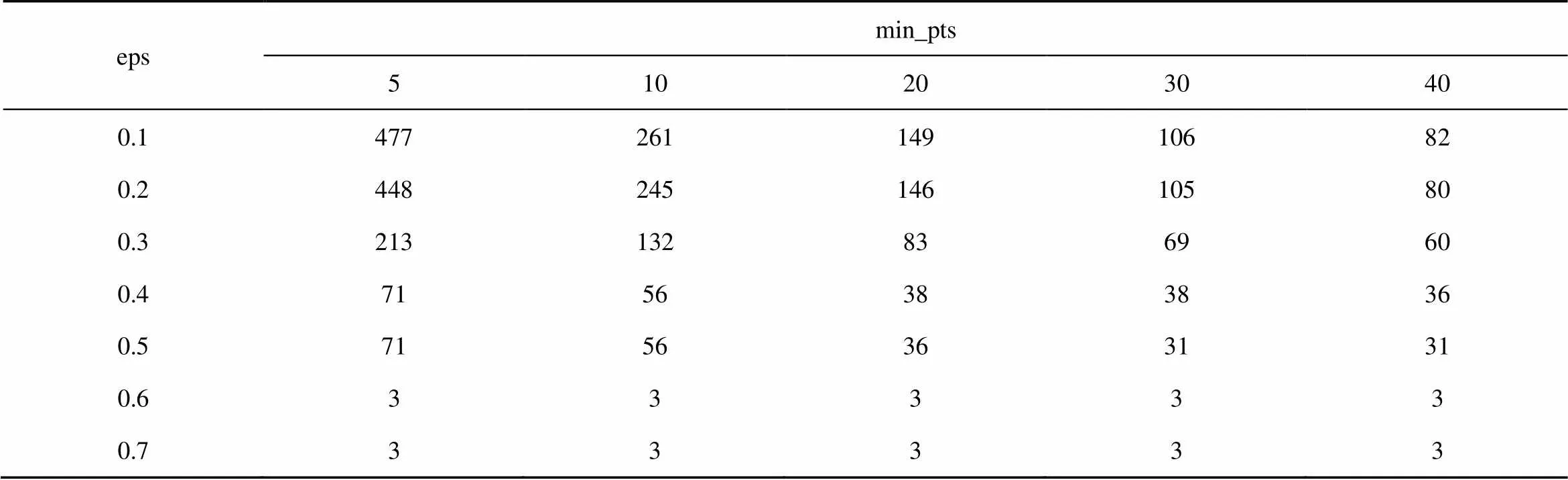
表4 调整参数eps和min_pts得到聚类的数量情况
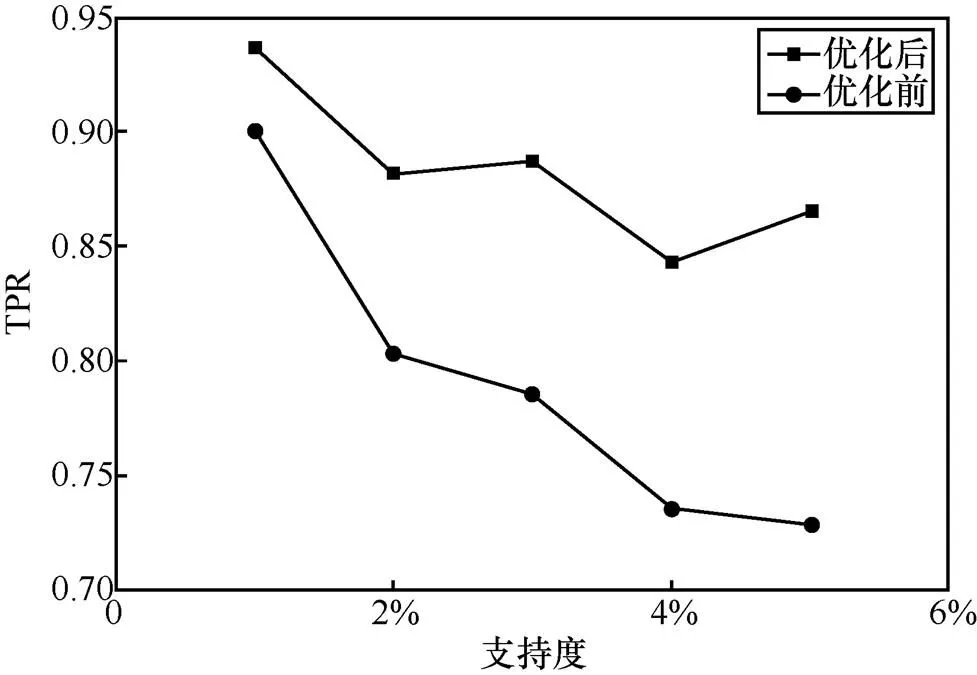
图1 优化前后FPGrowth算法取得的TPR随关联规则的支持度变化情况对比
Figure 1 Comparation of the TPR changes with the support of association rules before and after the optimization
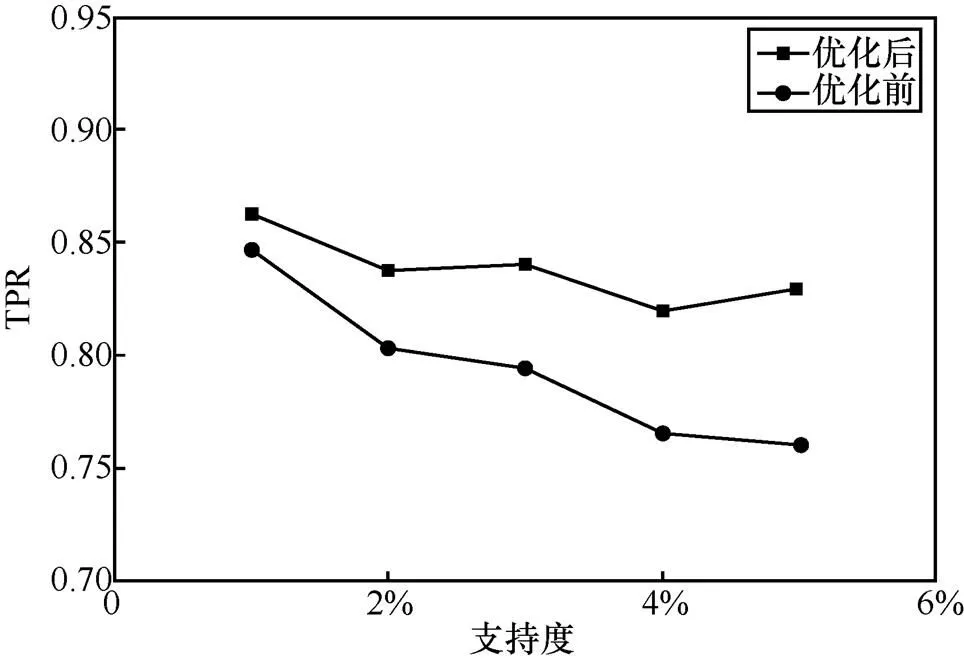
图2 优化前后FPGrowth算法取得的F1得分随关联规则的支持度变化情况对比
Figure 2 Comparation of the F1-score changes with the support of association rules before and after the optimization
实验3 性能分析
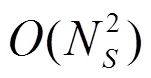
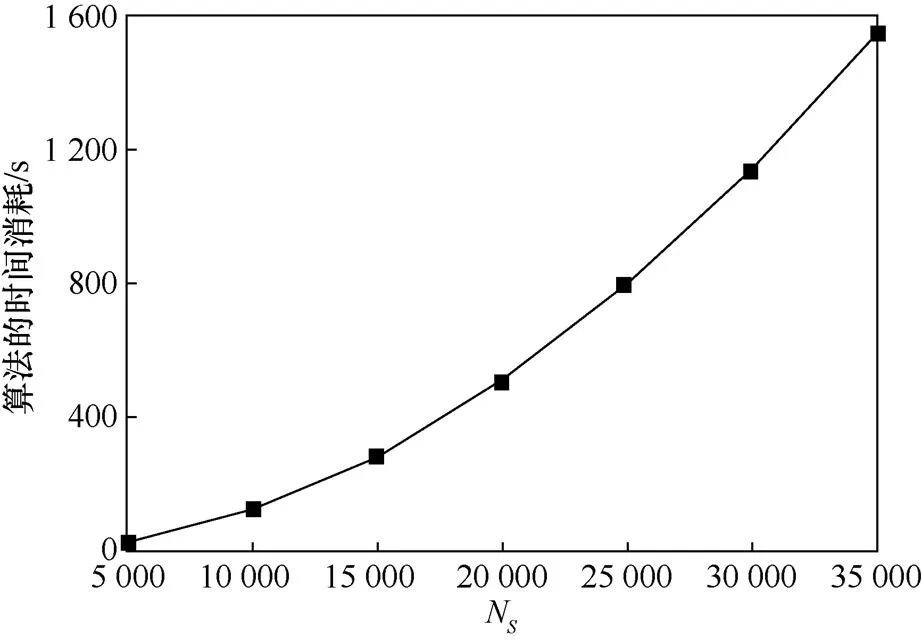
图3 主体属性优化消耗时间随主体数量变化情况
Figure 3 Time consumed by subject attribute optimization changes with the number of subjects
7 结束语
针对新型大规模计算环境下属性繁多、质量差强人意、难以人工修正、难以直接用于ABAC策略构建的问题,本文设计了基于权限聚类的属性值优化算法。首先,基于实体的权限集合表示和DBSCAN聚类算法为实体分配与权限对应的类别标签;接着,基于粗糙集理论对属性值进行化简与修正,使其能够更加清晰有力地区分实体的权限、高效地用以ABAC的实施与维护;最后,在UCI公开数据集上对属性值优化的效果进行了验证,根据本文提出的属性值优化算法对数据集中的主体属性进行优化后,FPGrowth算法挖掘到的ABAC策略质量在真阳性率和F1得分上有较为明显的提升。但是,算法中属性集对类标签的支持度计算复杂度较高,在处理大规模数据集的性能有待进一步优化,下一步计划研究支持度的增量式更新。
[1] 房梁, 殷丽华, 郭云川, 等. 基于属性的访问控制关键技术研究综述[J]. 计算机学报, 2017, 40(7): 1680-1698.
FANG L, YIN L H, GUO Y C, et al. A survey of key technologies in attribute-based access control scheme[J]. Chinese Journal of Computers, 2017, 40(7): 1680-1698.
[2] HU C T, FERRAIOLO D F, KUHN D R, et al. Guide to attribute based access control (ABAC) definition and considerations [includes updates as of 02-25-2019][R]. 2019.
[3] XU Z, STOLLER S D. Mining attribute-based access control policies from logs[C]//IFIP Annual Conference on Data and Applications Security and Privacy. 2014: 276-291.
[4] COTRINI C, WEGHORN T, BASIN D. Mining ABAC rules from sparse logs[C]//2018 IEEE European Symposium on Security and Privacy (EuroS&P). 2018: 31-46.
[5] IYER P, MASOUMZADEH A. Mining positive and negative attribute-based access control policy rules[C]//Proceedings of the 23nd ACM on Symposium on Access Control Models and Technologies. 2018: 161-172.
[6] 张任伟, 白晓颖, 郁莲, 等. 决策表的属性约简算法综述[J]. 计算机科学, 2011, 38(11): 1-6.
ZHANG R W, BAI X Y, YU L, et al. Survey of decision table research of attribute reduction[J]. Computer Science, 2011, 38(11): 1-6.
[7] 邓大勇, 薛欢欢, 苗夺谦, 等. 属性约简准则与约简信息损失的研究[J]. 电子学报, 2017, 45(2): 401-407.
DENG D Y, XUE H H, MIAO D Q, et al. Study on criteria of attribute reduction and information loss of attribute reduction[J]. Acta Electronica Sinica, 2017, 45(2): 401-407.
[8] 邓大勇, 葛雅雯, 黄厚宽. 属性约简簇的优化选择[J]. 电子学报, 2019, 47(5): 1111-1120.
DENG D Y, GE Y W, HUANG H K. An optimizing selection in a family of attribute reducts[J]. Acta Electronica Sinica, 2019, 47(5): 1111-1120.
[9] 张维, 苗夺谦, 高灿, 等. 一种处理部分标记数据的粗糙集属性约简算法[J]. 计算机科学, 2017, 44(1): 25-31.
ZHANG W, MIAO D Q, GAO C, et al. Rough set attribute reduction algorithm for partially labeled data[J]. Computer Science, 2017, 44(1): 25-31.
[10] 曾孝文, 胡虚怀, 严权峰. 一种基于粗糙集理论的属性值约简改进算法[J]. 电子技术, 2017 (1): 1.
ZENG X W, HU X H, YAN Q F. An improved algorithm for attribute value reduction base on rough set theory[J]. Electronics Technology, 2017(1): 1.
[11] TAN P N, STEINBACH M, KUMAR V. Introduction to data mining[M]. Pearson Education India, 2016: 21.
[12] LICHMAN M. UCI machine learning repository. amazon access samples data set[EB]. 2011.
[13] BORGELT C. Frequent item set mining[J]. Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery, 2012, 2(6): 437-456.
Permission clustering-based attribute value optimization
WU Wenchao1,2, REN Zhiyu1, DU Xuehui1
1. Information Engineering University, Zhengzhou 450001, China 2. 31668 Unit PLA, Xining 810000, China
In new large-scale computing environment, the attributes of entities were massive and they had complex sources and uneven quality, which were great obstacles to the application of ABAC (attribute-based access control). The attributes were also hard to be corrected manually, making it difficult to be applied in access control system straightly. To solve the optimization problem of nominal attributes, a novel algorithm of attribute value optimization based on permission clustering was designed, in which entities were presented by the privilege set related to them. So that the entities were tagged by density-based clustering method with distances of their privilege set presentations. Then the attribute values were reduced and corrected based on rough set theory. Finally, the algorithm was verified on UCI data sets, which proved that after applying it, ABAC policy mining was improved in the evaluation criteria, such as the true positive rate and1-score.
attribute value optimization, rough set theory, ABAC, access control
TP393
A
10.11959/j.issn.2096−109x.2021077
2020−04−08;
2020−08−07
任志宇,ren_ktzy@163.com
国家重点研发计划(2018YFB0803603);国家自然科学基金(61702550,61802436)
TheNational Key R&D Program of China (2018YFB0803603), The National Natural Science Foundation of China (61702550, 61802436)
毋文超, 任志宇, 杜学绘. 基于权限聚类的属性值优化[J]. 网络与信息安全学报, 2021, 7(4): 175-182.
WU W C, REN Z Y, DU X H. Permission clustering-based attribute value optimization[J]. Chinese Journal of Network and Information Security, 2021, 7(4): 175-182.
毋文超(1995−),男,河南焦作人,中国人民解放军31668部队助理工程师,主要研究方向为授权管理与访问控制。

任志宇(1974−),女,河南汤阴人,博士,信息工程大学副教授,主要研究方向为网络与信息安全。
杜学绘(1968−),女,河南新乡人,博士,信息工程大学教授、博士生导师,主要研究方向为网络与信息安全、空间信息网络、云计算安全。

