基于文本挖掘的影视弹幕情感分析研究*
2021-09-08邹墨馨辛雨璇
邹墨馨,辛雨璇
(牡丹江师范学院 计算机与信息技术学院,黑龙江 牡丹江 157000)
在当今网络高速发展的时代,观看电影成为人们解压、寻求快乐的主要方式之一。其中大部分用户对电影的概况、评价等信息也存在一定的需求,但是用户通过搜索引擎搜索得到的电影评价信息一方面可能存在较大误差,另一方面搜索得到的数据也可能存在限制,因此无法准确搜集得到有关该影视作品的有价值信息。随着时间的流逝,影评数据具有大数据规模,比如在动态弹幕的评论数据中,虽然人们可以看到所有的弹幕评论,但是太多的弹幕文本存在相互遮挡、移动速度快等问题,从而使用户无法看到完整的弹幕评论信息,最终导致无法准确对电影做出整体评价。因此,本文在基于大数据的背景下,采用文本挖掘技术[1]对弹幕文本数据进行爬取,从而找到海量评论下隐含的情感问题。
1 数据收集处理和可视化设计
1.1 数据获取
本文的数据来源于某视频的弹幕文本,首先对网页进行页面分析,找到网页发送弹幕的异步请求包,并分析目标网页的URL变化,通过观察分析发现页面遵循的规律,利用变化规律就可以快速实现数据的分段爬取处理。其次对目标网页结构进行分析之后,找到数据的接口,由于网页返回的数据是JSON格式,我们可以利用json.loads对数据进行直接解析,最后进行数据的存储。其中存储的数据内容包含用户名、会员等级、评论内容等字段。
1.2 数据清洗
其中数据清洗[2]是情感分析中的一个重要环节,主要是对原始数据进行处理。比如:缺失值的处理、重复值的处理等。首先把数据全部读取进来,然后把读取完成的数据进行去重处理、表情删除等清洗,最后将清洗之后的数据重新进行存储,共计处理了4万多条弹幕文本数据。
2 数据可视化
数据获取和处理完毕之后,利用Python中的第三方库Pyecharts库、WordCloud库等进行数据可视化分析,以《哪吒之魔童降世》为例,本文通过电影情感计算值折线图和电影评论分析词云图进行可视化展示。
电影情感计算值折线图可以显示随时间变化的趋势或按顺序分类的走向,并可以使用数据点来表示单个数据值。根据评论的时间段,让有关数量之间的关系更加直观、鲜明。使用Pyecharts库中的Line模块实现折线图的设计。电影情感计算值折线图如图1所示。
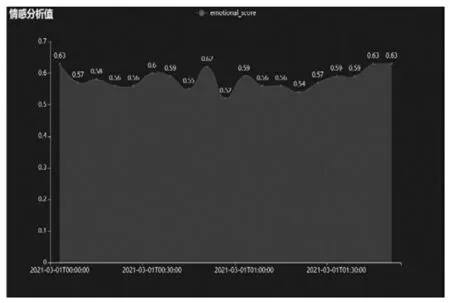
图1 电影情感计算值折线图
电影评论分析词云图首先要对爬取的评论信息进行处理,使用jieba.cut()方法把文本进行分词,然后进行文本的分析,根据词语出现的次数生成词频统计,最后在wordcloud模块,设置词云图显示词语的个数、字体等,最终将生成的词云图保存到指定路径中。电影评论分析词云图如图2所示。

图2 电影评论分析词云图
3 基于Bi-LSTM情感倾向性分类模型
3.1 Bi-LSTM模型原理
Bi-LSTM模型是一个双向的LSTM结构,该模型把捕获到的正向和反向信息合二为一输出。也就是说Bi-LSTM[3]模型是把两个时序相反的LSTM网络连到同一个输出上,从获取输入序列上看,正向LSTM能得到上文信息,反向LSTM能得到下文信息。比如“多”“支持”“国产”“动漫”是Bi-LSTM所捕获的正向编码信息,同时该模型还包含“动漫”“国产”“国产”“多”的反向编码信息,最终把这两个编码信息合并成一个输出。其中基于Bi-LSTM的情感分类模型如图3所示。在t时刻,也就是输入会提供两个反向的LSTM网络,然后分别进行独立计算,最后在一起合并输出[4]。其中在基于更加细粒度的分类时,Bi-LSTM模型能够更好地捕获语句中上下文信息,所以该模型对带有主观描述的中文文本进行情感极性类别分类时有更好的判断能力,可以计算出准确的情感倾向相应的分值。
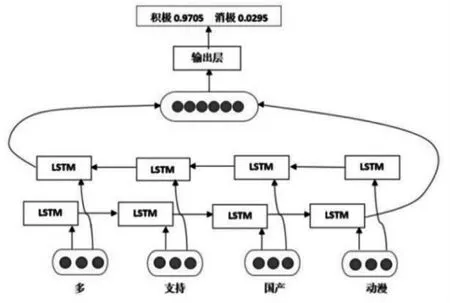
图3 基于Bi-LSTM的情感分类模型
在20世纪90年代末,Hochreiter[5]等人提出LSTM模型,其中LSTM模型[6]是一种时序模型,含有三个门结构,分别为遗忘门、输入门、输出门。在t时刻时,Wf、Wi、Wc是权重矩阵bf、bi、bc、bo是偏置矩阵,Ut、Ui、Uc、Uo表示上一层输出Wf、Wi、Wc,Ht-1在这一层各个部分的权重矩阵。其中LSTM模型单元结构如图4所示。
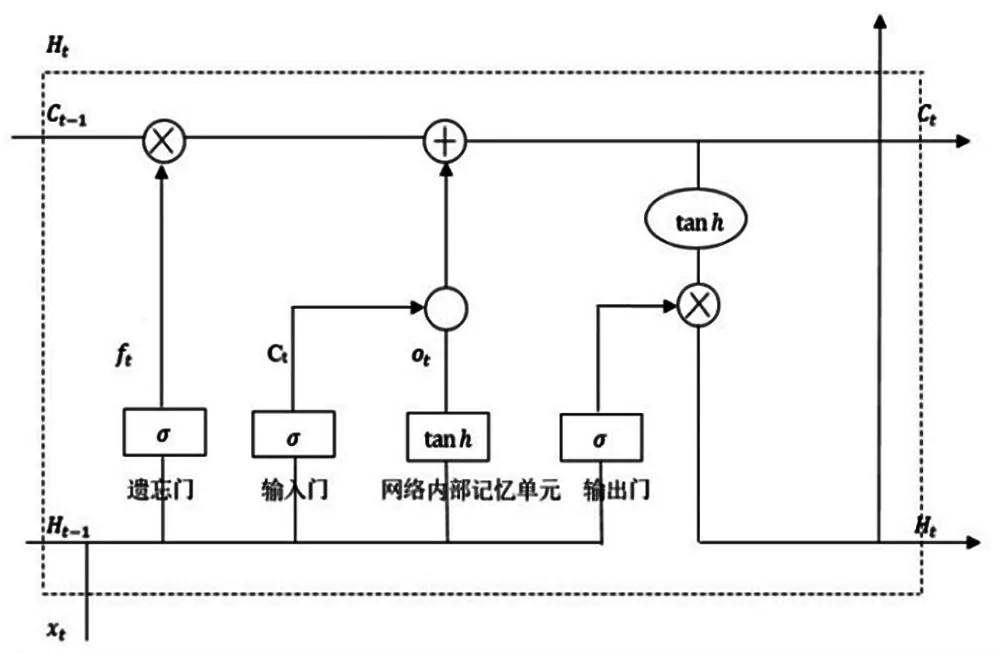
图4 LSTM模型单元网络结构
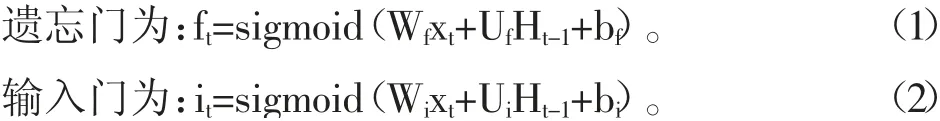
网络内部记忆单元:
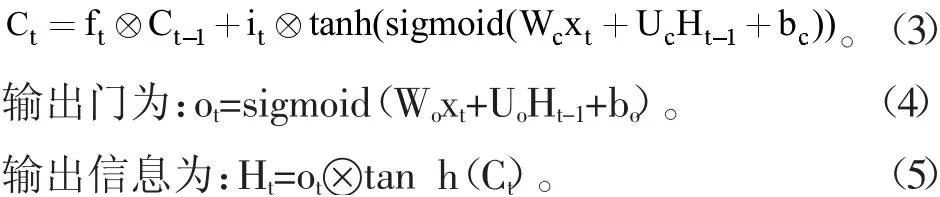
3.2 实验数据集
本文利用python网络爬虫技术爬取的原始弹幕数据共计46441条,经过一系列数据的预处理之后,得到的数据为45579条,其中得到二分类中积极的评论有29173条,消极的评论有16406条。
3.3 实验结果展示与分析
本文首先对弹幕文本数据进行读取,然后进行一系列数据清洗、分词等操作之后,把处理好的弹幕文本数据通过Bi-LSTM的情感分类模型进行情感分类计算。如表1所示(部分)的情感分值以及情感类型的判断,其中0代表消极,1代表积极。
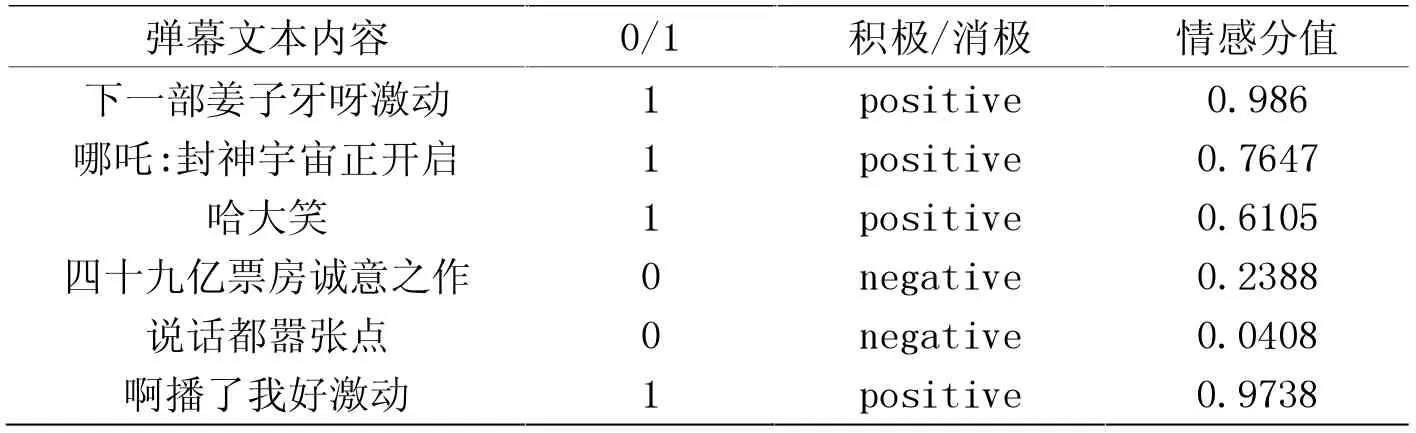
表1 情感倾向分值表
通过计算分析发现该影片整体的情感分值在0.5以上如图1所示,说明用户对该部影视作品的情感倾向还是比较积极的,总体上看大部分人是持比较满意的态度。情感分值的发展趋势则是从视频刚开始表现升高,然后再降低,最后再升高。从情感分值高于0.5的积极评论可以推测出,整体给予评价较高的原因是相比较以前的国产动漫而言,这部作品不仅在人物形象上下足了功夫,而且在观影质感以及所想要传承的中国传统文化精神等各个方面都表现的非常出色。对于用户而言,印象最深刻的就是真切的感受到国产动漫的巨大进步,背后都是工作人员的辛苦付出,才会收获现在的成绩。从情感分值低于0.5的消极评论可以推测出,少部分人对故事中的一些情节产生不满,所以评论用户对此发表了一些比较消极的评论。
4 结论
本文将基于文本挖掘技术进行弹幕文本分析,通过对弹幕文本数据的情感倾向性分析得到该电影的整体评论,最终得出该电影评论比较中肯的见解。在情感分析中,首先利用python网络爬虫技术对弹幕文本进行爬取,经过一系列数据预处理之后,进行了直观的词云展示、柱状图展示等,然后采取Bi-LSTM模型对弹幕评价进行情感分类处理,最后计算出情感倾向性分值。目前,在大数据的背景下,对于用户选择哪部电影是否值得进行观看提供比较中肯的意见,有助于帮助用户了解该影片,同时也可以帮助影视公司了解用户的喜好、分析热点话题等问题,从而可以给影视公司提供一些有效的策略。
