不平衡数据下基于CNN的网络入侵检测
2021-09-08冯英引师智斌
冯英引,师智斌
(中北大学 大数据学院,山西 太原 030051)
0 引 言
作为机器学习的重要组成部分,深度学习在文本处理、 图像分类、 语音识别等复杂领域取得了巨大进步,同样在网络入侵检测研究中表现出良好的分类性能. 文献[1]直接把原始流量转换为图片输入卷积神经网络CNN进行学习,得到的分类器效果接近实际应用水平; 文献[2]针对UNSW-NB15数据集的原始流量包使用独热编码进行维度重构,利用GoogLeNet对重构数据进行特征学习,实验结果优于其他基于特征数据的深度学习方法; 文献[3]结合CNN和LSTM两种深度学习算法,学习网络流量数据的时空特征,在CICIDS2017数据集上的总体准确率达到99.57%; 文献[4]基于SMOTE-Tomek采样结合卷积神经网络构建模型,提高了模型的二分类和多分类效果.
综上所述,采用超声诊断急性阑尾炎的准确性较高,且可对患者疾病类型予以明确诊断,还可为患者疾病诊治提供可靠影像学依据。
爱国主义是一种民族精神,是团结一心、自强不息。习近平总书记指出:“爱国主义是中华民族精神的核心。”[注]习近平:《在纪念中国人民抗日战争暨世界反法西斯战争胜利69周年座谈会上的讲话》,《人民日报》2014年9月4日,第2版。中华民族的民族精神以爱国主义为核心,爱国主义是中华民族的精神基因,爱国主义深深植根于中华民族心中。作为民族精神核心的爱国主义,它既是中华民族团结一心的精神纽带,也是中华儿女自强不息的精神动力。
研究表明,深度学习在多个网络入侵检测公开数据集上实验效果很好,但是大多数研究存在的共同问题是未能考虑到类别不平衡问题. 类别不平衡是指同一个分类问题中某些类别的样本数量远大于其他类别的样本数量,将未经处理的不平衡数据集直接输入传统分类器会导致多数类淹没少数类,得不到好的分类效果[5]. 入侵检测样本数据中,往往正常样本数据远多于入侵样本数据,或者攻击类别之间数量差距很大. 针对数据不平衡带来的分类问题,一般从数据和算法两个层面进行处理. 文献[6]使用过采样技术结合Focal Loss损失函数,解决了NSL-KDD数据集类别不平衡带来的问题; 文献[7]在数据层面使用SMOTE和bootstrap分阶段抽样方法均衡类别间数量,在算法层面提出了基于栈式稀疏自编码网络的集成学习方式,明显提升了KDDCUP99数据集上少数类的检测效果. 但是以上两种方法均使用处理后的特征数据集进行学习,未能充分利用深度学习从原始数据中自动提取特征的优势.
综合分析上述文献在网络入侵检测研究中存在的数据集较为老旧、 类别不平衡、 多分类检测效果不理想、 未结合深度学习模型和原始流量等问题,本文提出一种类别重组技术结合FocalLoss损失函数的不平衡类别处理方法,应用于原始入侵流量数据集. 该方法调整了训练过程中入侵流量数据集的不平衡性,并通过Focal Loss损失函数来提高模型对复杂入侵流量样本的关注.
1 网络入侵检测算法
输出:流量灰度图集合IMG={g1,g2,g3,…,gn}
1.1 数据集预处理
UNSW-NB15数据集[8-9]包括9种类型攻击,由于原始流量数据是混合流量,首先利用WireShark工具根据IP地址把流量文件分割为正常流量和异常流量. 流量特有的MAC地址和IP地址信息会影响模型的特征学习,而所有数据包的数据链路层被替换为Linux cooked capture,流量数据是在同一个网络环境下产生的,因此,不需要进行流量清洗. 数据预处理流程分为流量切分、 流量打标、 会话截取和图片生成四个步骤.
步骤1(流量切分):将原始流量数据按照相同五元组(源IP,源端口,目的IP,目的端口,传输层协议)切分成多个会话流量,会话流量文件以五元组属性命名,保存格式为PCAP.
步骤2(流量打标):UNSW-NB15_GT.CSV文件记录了9种攻击类型的详细属性,包括时间戳、 五元组信息、 攻击类别等. 根据真值表的数据记录与会话流量五元组的对应关系,把切分好的会话流量打上标签并分类到对应文件夹中.
4 alpha_choice←tf.gather(alpha,Labels)/*为各类别样本加上类别权重alpha*/
步骤4(图片生成):对每条会话流的前7个数据包进行编码处理. 数据包在链路层上传输时的最终形式是十六进制,将截取部分的十六进制数据转换为十进制数据,每两位十六进制数对应一个灰度图像素值,最大值ff=255,范围0~255. 将像素矩阵保存为PNG图片. 以下为会话流量生成灰度图的伪代码.
算法1 PNG=Session2Png(Session)
输入:会话流量集合Session={s1,s2,s3,…,sn}
本节将详细介绍原始流量数据集的预处理流程,类别不平衡的处理办法以及网络入侵检测算法的整体框架.
1 forf←s1tosndo
2 hex_series←Ø/*hex_series保存会话流量f对应的十六进制字节序列*/
3 packet={p1,p2,p3,…,pn}←editcap(f,1~7)/*使用editcap脚本截取会话流量文件f的前7个分组packet*/
4 for pkt←p1topndo
另外,0号高压加热器抽汽管道的调节阀具备一次调频能力,可以降低汽轮机主蒸汽调节阀节流损失,进一步提高机组热经济性[18]。
5 hexst←getHex(pkt)/*getHex函数得到单个分组pkt对应的十六进制字节序列*/
6 if hexst.length<112bytes
结合这两种改进方法,最终Focal Loss损失函数形式如式(3)所示,将其用于网络入侵检测多分类实验. 其中,p代表把样本识别为对应类别的概率;α代表样本的类别权重,样本个数越多其权重越小,范围在(0,1]之间;γ是一个大于0的常数,与类别无关.
8 hexst←hexst[0∶112]/*取前112字节*/
9 hex_series←hex_series+hexst/*合并数据包十六进制数序列hexst,用hex_series保存*/
10 endfor
11 if hex_series.length<784bytes
12 thenhex_series←padding(hex_series)/*长度少于784字节,则用0x00补足*/
13 mat←getMatrix(hex_series)/*将784字节十六进制数序列hex_series转换为对应十进制28*28的数值矩阵*/
14 g←img.save(mat,png)/*28*28二维矩阵保存为PNG灰度图像*/
15 endfor
经过数据预处理流程,一共生成82 825条流量图片数据,类别样本数量见表1. 由于正常流量数据过于庞大,本文只随机选择一个pcap文件中的正常流量作为Normal样本进行预处理.

表1 流量预处理结果
1.2 类别不平衡处理方法
1.2.1 类别重组技术
类别重组技术对流量样本进行均匀采样,使得训练集内各攻击类别相对均衡,以下为实现类别重组的具体方法.
“好!”颜晓晨依旧分不清东南西北,却立即答应了,就如被五百万砸中的人,即使蒙到完全不知道该如何应对飞来横财,却一定会先紧紧抓住了。两个确认了恋爱关系的“亲密恋人”,却一点没有亲密的姿态,更没有喜悦的表情。沈侯沉默着,好像不知道该再说些什么,颜晓晨也沉默着,是真不知道该说什么。
1) 对10类流量图片各随机采样8/10作为基础,得到不均衡的10类随机流量列表;
2) 计算每个类别样本数量,记录最大样本数为MAX_LIST;
高校开展武术散打课程是综合素质教育下的观念,是促进教学体系进一步完善,是高校为提升校园文化内涵的一种措施。为学校提供了培养人才的新观念,在修养方面,武术散打运动课程在理论思想学习上可以切实提高学生的道德和修养,使学生不仅能掌握以巧智取、顺势借力等技击原则,还能传承中国人礼让为先、有礼有节、刚强而不狂野,注重内外兼修的文化传统。由此可以看出武术散打在教育上并不是单单地传授技术练习,更加注重对学生道德品质的完善和提升,对促进学校综合教育质量有重要的作用。
3) 为每个类别产生一个随机排列列表random_list,种子数为MAX_LIST;
钟志英等发现芪参益气滴丸具有明显的促进鸡胚尿囊膜(CAM)血管新生的作用,在大、中血管增生效果更为明显,对HUVECs具有增殖影响。
4) 用random_list中的随机数对各类别的样本数取余,得到对应索引值列表index_list;
5) 根据各类别的index_list列表,利用索引值提取流量图片,生成该类别的图片随机列表img_list,大小和最大样本数MAX_LIST相同;
6) 所有类别的img_list连在一起随机打乱次序,得到最终流量图片列表all_img_list,每类样本数目均等.
在利用卷积神经网络学习流量样本时,保证batch从类别分布均匀的all_img_list生成的train.tfrecords文件中随机选择样本. 随着迭代次数的增加,整体输入网络的流量样本趋于类别均衡.
1.2.2 Focal Loss损失函数
2004年,英国曼彻斯特大学的Geim和Novoselov首次采用机械剥离法,成功制备出单原子层的二维晶体——石墨烯,震撼了物理界[1]。石墨烯是由纯碳原子组成的六元环平面结构构成的二维材料,是其他维数碳材料(富勒烯、碳纳米管和石墨等)的构筑单元。因其独特的物理化学性质,如大理论比表面积、高机械强度、高电导率、良好的生物兼容性及易功能化等,石墨烯成为电化学传感器的理想材料,其在传感器领域的应用也得到了越来越多的关注。
Focal Loss主要是为了解决one-stage目标检测中正负样本比例严重失衡的问题,该损失函数降低了大量简单负样本在训练中所占的权重.
Focal Loss在标准交叉熵的基础上进行修改. 式(1)为标准交叉熵,pt代表把样本识别为正类的概率. 大量简单负样本的loss值会主导梯度下降的方向,淹没少量正样本的影响. 为了平衡正负样本,为标准交叉熵添加一个权重因子α. 负样本越多,权重越小,降低了负样本的影响. 针对简单样本和复杂样本之间的不平衡,定义了Focal Loss损失函数形式,如式(2)所示.γ是一个大于0的常数,简单样本pt比较大,γ使其权重减小; 复杂样本pt比较小,γ使其权重增大,网络倾向于利用这类样本进行参数更新.
ESP教学教师应既有专业素养,又能用流利的英语表达和分析专业知识。Dudley Evans和St.John(1998)指出一个合格ESP教师应扮演的五种角色:很高的英语水平的英语教师;可以更具需要设计课堂教学的课程设计者;能搞与专业教师与学生合作的合作者;随时关注本领域最新发展的研究者;根据学生学习情况进行分析和总结的测试评估者。对照国外ESP教师衡量标准,笔者认为现阶段国内ESP师资的短板主要表现在高水平教师和研究者这两种角色上。
CE(pt)=-log(pt),
(1)
7 Loss←mean(tf.multiply(weight, tf.log(prob)))/*依据式(3)计算batch内部的平均Loss*/
(2)
7 then hexst←padding(hexst)/*hexst长度少于112字节,则用0x00补足*/
伴随信息化和现代化的不断发展,我国保险公司的财务风险管控也越来越受到社会关注,这不仅关系着国民经济的发展,也牵扯着社会关系的和谐与否。因此,建立完整的财务风险预警体系是当务之急。利用财务风险预警体系,可以在实际运行中为保险公司提供实时的风险动态,同时也能对潜在的风险进行预警通报以做好防控措施。可以有效降低财务风险发生的可能性,同时也能在风险真的发生之时以最有效的措施应对,减少因财务风险引起的企业财务损失。
FL(p)=-α(1-p)γlog(p).
(3)
算法2 Focal Loss损失函数
输入:网络计算输出值Logits={o1,o2,o3,…,on}
样本真实标签Labels={b1,b2,b3,…,bn}
输出:平均损失Loss
1 alpha←[α1,α2,…,α10]/*初始化alpha向量,即各类别样本权重*/
2 softmax←Softmax(Logits)/*归一化,计算单个样本属于每一类的概率值*/
3 prob←getprob(softmax,Labels)/*得到batch中每个训练样本属于各个类别的概率*/
步骤3(会话截取):对10个类别文件夹中的会话流逐个进行处理. 为了实现对会话流的实时检测,只保留每条会话流的前七个数据包,利用editcap工具进行截取操作.
陈远景副厅长到永嘉缙云调研(省厅执法监察局〈监察总队〉) ...................................................................12-12
5 weight←pow(tf.subtract(1., prob), gamma)
6 weight←multiply(alpha_choice, weight)
FL(pt)=-(1-pt)γlog(pt).
1.3 整体框架
网络入侵检测算法基于卷积神经网络模型进行实验,在LeNet[10],AlexNet[11],GoogLeNet[12]3类模型上进行学习.
GoogLeNet在建立更深网络结构的基础上,引入了Inception模块,增加了网络宽度,提升了网络性能. 本文中使用InceptionV4版本进行训练. Inception V4模型包括1个Stem 模块,3个 Inception 模块和2个Reduction模块. Stem模块对进入Inception模块前的数据进行预处理,利用多次卷积操作加上2次池化操作,把 299*299*1的输入转换为35*35*384的输出,减小了对图片压缩的精度损失; Reduction 模块借鉴Inception 的设计,使用并行结构避免了特征表示的瓶颈问题并能实现降维功能,把 35*35 的网络尺寸改变为17*17,8*8,降低了 Inception 模块之间的网络尺寸. Inception 结构采用不同大小的卷积核学习不同尺度特征并进行特征融合,可提高深层卷积神经网络的图像识别能力.
图1 为基于卷积神经网络的网络入侵检测算法流程.
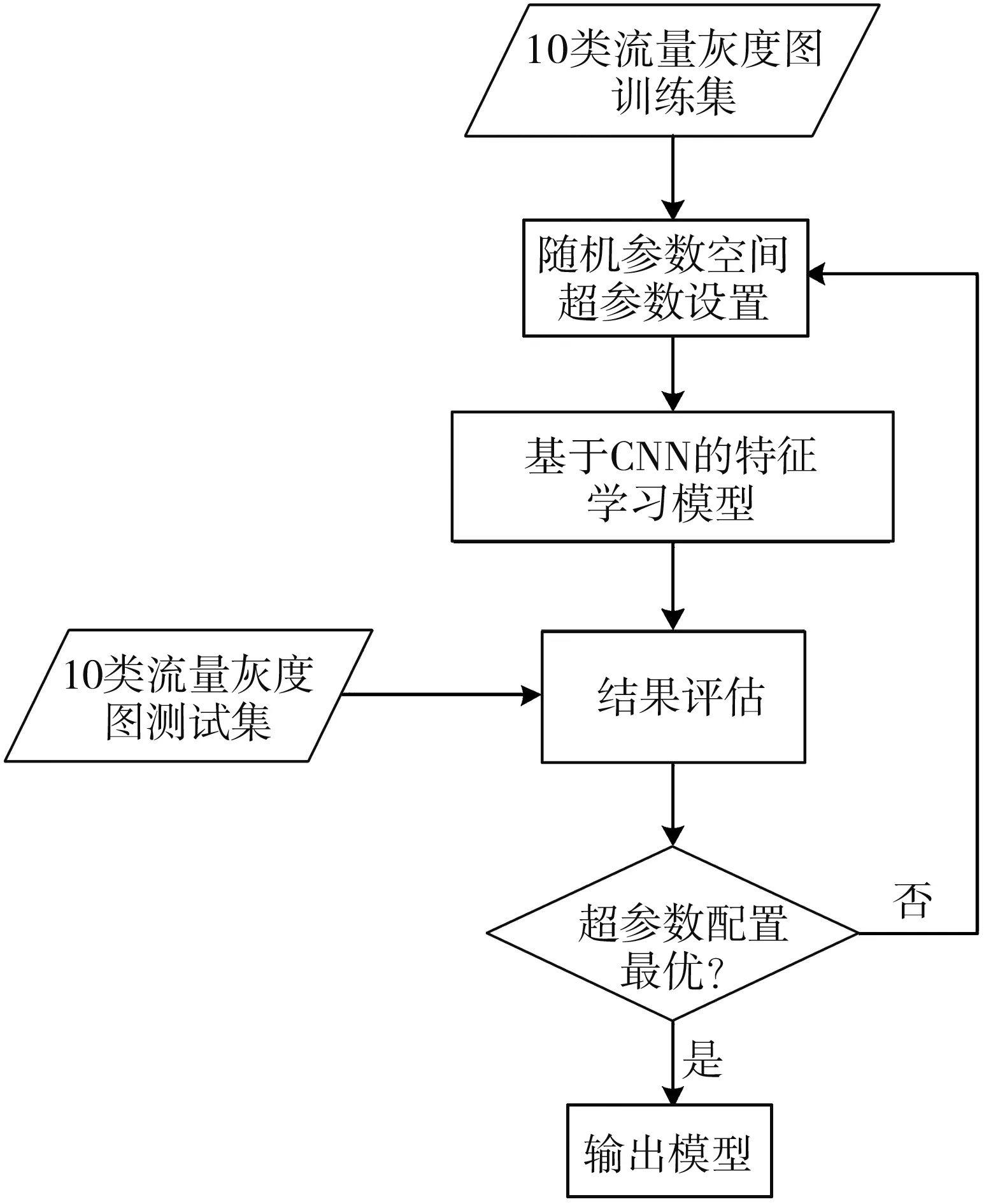
图1 网络入侵检测算法整体框架
在特征学习模块分别使用三种CNN模型进行特征提取和表征学习,通过调整重要参数值,使每种模型的学习能力达到最优.
2 实验与分析
2.1 数据集描述
实验所用原始流量UNSW-NB15是澳大利亚网络安全中心(ACCS)于2015年在实验室采集的现代网络正常活动和综合攻击活动的混合流量. 研究人员利用IXIA PerfectStorm工具模拟了9种攻击类别产生的异常流量,包括Analysis,Backdoors,DoS,Exploits,Fuzzers,Generic,Reconnaissance,Shellcode,Worms.
事情总算圆满解决了。三十来万的损失,几经周折,终于尘埃落定,小俩口再不用愁眉苦脸了。不管历经多少坎坷,不管饱受多少折磨,如今皆是过眼云烟。小俩口觉得很幸福,很轻松。不过玉敏心里仍不是个滋味,缠着要和小虫谈谈。玉敏说很对不起姑父,让他破费了。小虫调侃道,姑父破费就对了,这是正当消费,没花冤枉钱,享用无偿消费心里并不踏实。玉敏点点头。小虫伸过胳膊,将玉敏搂住,两人再度把幸福感推向了高潮。
本文只用到了原始流量数据和记录攻击事件的真值表UNSW-NB15_GT.CSV. 在网络入侵检测多分类实验中,用到的训练数据集如表2 所示. 可以发现训练集的攻击类别数目相差很大.

表2 多分类数据集
2.2 实验配置及评价指标
使用的软件框架是TensorFlow,运行在Ubuntu16.04 64位操作系统中. 实验硬件方面,CPU是12核Xeon E5-2678 2.50 GHz,内存是125.8 GB. 此外,使用一块Nvidia GeForce RTX 2080 Ti GPU作为加速器. 随机挑选2/10作为测试数据,剩余8/10作为训练数据. 训练时,mini-batch尺寸是64,优化方法为TF内置的AdamOptimizer,学习速率为0.000 1.
针对网络入侵检测实验采用的评价指标为准确率(Accuracy),精确率(又称为查准率,Precision),召回率(又称为查全率,Recall)和F1值.
式中:TP表示被正确识别出的目标流量数目;TN表示被正确识别出的其他类别流量数目;FP表示被错误识别出的目标流量数目;FN表示未被识别到的目标流量数目.
2.3 实验1
实验1对比了 LeNet,AlexNet 和 GoogLeNet 3种模型对于网络入侵检测数据集的分类效果,采用不同深度、 不同结构的CNN网络对数据集进行特征提取和分类. 3种CNN模型基于Tensorflow平台搭建,基于相同的训练集进行特征学习,数据集中训练集与测试集比例为8∶2. 具体以f1-score分数作为评估参数来衡量分类效果,如图2 所示.

图2 不同CNN分类效果
由图2 可知,随着模型结构的改进,对于每一类别的识别效果越来越好,整体识别效果为GoogLeNet>AlexNet>LeNet. Inception V4凭借更深更复杂的网络结构,通过多种不同尺寸的卷积核获取多种图片信息,分类效果更加准确.
2.4 实验2
2.4.1 样本数量与分类效果分析
以LeNet模型的分类结果为例,比较训练集中攻击样本数量和类别识别精度之间的关系. 如图3 所示,Exploits,Fuzzers,Normal,Reconnaissance的识别效果很好,与其样本数量成正相关关系; Backdoors,Generic,Shellcode的样本数量较少,但是其识别效果很好,说明训练集中的样本都极具代表性,可以很好地表征该类别; Dos类别的识别效果与其样本数量不匹配,可能是由于其特殊性质,使CNN学习模型并不适用于检测Dos攻击类别; Analysis,Worms样本识别率很低,造成这一结果的主要原因是类别不平衡.

图3 类别样本数量与识别精度的关系
2.4.2 方法有效性分析
激光淬火技术作为一种新型的热处理工艺,与传统表面淬火技术相比,具有加热速度快、所得组织细密、淬硬性高、不变形等特点,并且技术适用性广,不受感应器制作难度的限制。本文首先将对激光淬火工艺技术作一详细说明,其次对工厂生产的缸筒进行了局部激光淬火,最后提出了生产中存在的主要问题及一些改进措施。
网络流量数据集存在的类别不平衡问题以及样本的复杂性会导致少数类识别效果较差,尝试使用类别重组方法结合FocalLoss损失函数进行改进.
在数据层面,使用类别重组技术使得训练集内各类别样本分布相对均衡; 在算法层面,Focal Loss损失函数中预定义向量α根据样本比例来反向推导,样本数量越多类别权重越小. 由于训练集已做均衡处理,因此,向量α=[1.00,1.00,1.00,1.00,1.00,1.00,1.00,1.00,1.00,1.00]. 文献[10] 进行参数对比实验时,γ分别取值0,0.5,1,2,5,本实验中同样把γ分别取值0,0.5,1,2,5来比较FocalLoss损失函数在三种CNN模型上的应用效果,其中base表示非平衡数据集结合标准交叉熵损失函数的模型识别效果,γ=0表示平衡数据集结合标准交叉熵损失函数的模型识别效果.
宜兴市湖父镇地处我国江苏省、浙江省、安徽省的交界位置,因“太湖第一源”、“太湖之父”而得名,更以“竹的海洋”、“茶的绿洲”、“洞天世界”、“紫砂源地”而名闻遐迩。其中有国家级风景名胜区6个,其中国家AAAA级景区3个。著名景点有竹海、张公洞、灵谷洞、陶祖圣境、玉女山庄、磬山崇恩寺等。

表3 不同γ参数值下LeNet实验的结果

表4 不同γ参数值下AlexNet实验的结果

表5 不同γ参数值下GoogLeNet实验的结果
如表3~表5 所示,使用类别重组技术平衡训练集后,三种CNN模型上的整体学习效果均有提高,macro- f1分别提高了6.98%,1.27%,3.66%; 针对单个模型,FocalLoss损失函数γ的不同取值会略微影响模型的学习效果. 相较于γ=0的情况,在LeNet模型上,γ=0.5时学习效果最好,macro-f1分数提高了2.27%,少数类Analysis,Worms的f1-score分别提高了 16.67%,16.67%; 在AlexNet模型上,γ=2时学习效果最好,macro-f1分数提高了0.38%,少数类Analysis,Worms的f1-score分别提高了 8.00%,7.69%; 在GoogLeNet模型上,γ=1时学习效果最好,macro-f1分数提高了0.6%,少数类Analysis的f1-score提高了5.17%,Worms略有下降. 实验结果表明:类别重组技术可以使类别间保持相对均衡,有效提高了模型的整体识别效果; FocalLoss损失函数能够提高复杂样本的识别效果,可以进一步提高少数类的识别精度. 两种方法的结合对于处理网络入侵检测中数据类别不平衡带来的问题有一定的改进效果.
3 结束语
深度学习可以从大量流量数据中自动学习各类攻击样本的特征表示,有效提高了网络入侵检测的整体检测率. 实验表明模型结构越复杂越高级,对于攻击流量的识别能力越好. 针对网络入侵检测中存在的类别不平衡问题,利用类别重组结合Focal Loss损失函数的混合方法在多个CNN模型上进行实验,均可有效提高少数类样本的识别精度,证明了该方法的可行性. 然而有些攻击类别比如DoS攻击,由于其特性,在样本数量较大的情况下也总是难以识别,因此,未来的工作将注重于多分类场景下对DoS攻击的检测.
