结合注意力机制与时空特征融合的长时程行为识别方法
2021-09-06郝一嘉宦睿智刘佶鑫
孙 宁, 郝一嘉, 宦睿智, 刘佶鑫, 韩 光
(南京邮电大学 宽带无线通信技术教育部工程研究中心,江苏 南京 210003)
基于视频的行为识别一直是计算机视觉领域的研究热点。在早期的工作中,研究思路主要集中在使用人工特征与基于浅层学习的分类器相结合上。文献[1]从90帧图像组成的三维(3D)时空卷(spatial-temporal volume,STV)中提取3D特征,并在这些3D特征上训练最近邻分类器对视频中的行为进行分类。文献[2]提出了密集轨迹(dense trajectories,DT)算法,通过对图像序列中的多尺度密集关键点进行采样和跟踪,构建视频的密集轨迹;接着在每个密集关键点附近提取多种特征[3-5],并利用特征袋(bag of features,BoF)[6]模型对每个密集点构建时空金字塔(spatial-temporal pyramid,STP);最后在STP数据上训练支持向量机(support vector machine,SVM)分类器,学习视频的时空特征进行行为识别。改进的密集轨迹模型(improved dense trajectories,IDT)[7]是对DT算法的改良。IDT使用SURF算子[8]提取关键点,并结合相邻2帧的光流来缓解摄像机运动的影响。在特征编码阶段,采用Fisher向量[9]代替DT算法中的BoF模型。IDT算法能够有效地消除摄像机运动对图像的不利影响,达到更佳的行为识别效果。
与基于人工特征和浅层学习的行为识别方法相比,基于深度神经网络的行为识别方法可以从大量训练数据中学习高度非线性的时空语义特征,大大提高了行为识别的性能。然而,在现有的基于深度学习的行为识别方法中,都是按照某种固定的采样规则对输入视频进行图像帧采样,对于所有的采样图像都无差别对待,没有考虑不同图像帧对于行为识别重要性的不同。一方面,这种策略可能会导致大量冗余数据淹没有意义的行为信息;另一方面,根据人为的规则而不是根据内容语义采样图像可能会导致关键信息的丢失。
针对这一问题,本文提出了一种基于深度学习的视频级行为识别方法,即嵌入注意力机制的时空特征融合网络(attention-embedded spatial-temporal feature fusion network,ASTFFN)。ASTFFN将一个长时程行为视频划分成几个重叠的片段,将RGB图像和相应的光流图像作为每个片段的时空表示。在ASTFFN中,设计了一种嵌入注意力机制的特征提取模块(attention-embedded feature extraction module,AFEM)实现从RGB图像或光流图像中提取注意力加权的时间或空间特征。该模块由一个用于从图像中进行特征提取的三维卷积神经网络(convolutional neural network,CNN)和一个用于对不同图像帧中提取的特征分配重要性权重的注意力机制组成。将由AFEM获得的所有片段的时空分数进行融合,生成整个视频的行为类别预测。基于ASTFFN的行为识别方法可以对整个视频中行为的时空信息进行建模。通过注意机制对每个图像帧进行加权,权值体现了每个周期像帧对于最终行为识别的重要性,最终提升算法的识别性能。
1 相关工作
本节回顾近期基于深度学习模型的行为识别方法。文献[10]提出了一种端到端可训练的CNN。该模型将特征提取与分类结合在一起,用于从连续7帧图像中提取人体行为的时空特征。文献[11]提出的C3D方法在更大规模的深度神经网络上实现了三维卷积运算,可以同时从16帧图像中提取时空特征。C3D方法在6个常用行为识别数据库中得到了当时最优的识别正确率。与二维卷积相比,三维卷积不可避免地会带来更大的计算和存储开销,对于具有更深层的大型深度神经网络模型,该问题更加明显。文献[12]提出了伪三维(pseudo-3D,P3D)模型,将三维卷积解耦为二维空间卷积和一维时域卷积,其中空间卷积对空间信息进行编码,时域卷积对时域信息进行编码。
另一种基于深度学习的行为识别方法是双流模型。文献[13]提出了一种用于行为识别的双流深度神经网络结构,该结构利用2个CNN分别从视频中的1帧RGB图像和10帧光流图像中提取行为的时空特征。通过融合2个CNN的得分来预测行为类别。然而该采样策略过于稀疏,可能会丢失视频中的重要信息。文献[14]提出了用于长时程行为识别的时间段网络(temporal segment networks,TSN)模型。TSN首先沿着时间维度将视频分成几个片段,然后使用双流模型提取每个片段的特征,并进行行为类别预测。通过融合所有片段的预测分数,得到最终的行为识别结果。文献[15]提出了双流膨胀三维卷积神经网络(inflated 3D convnets,I3D),将双流模型与3DCNN相结合进行行为识别。该方法将现有的2DCNN模型进行变换,使其能够接受3D数据。具体做法是沿着时间维度重复2D卷积核N次,并进行归一化。这样,I3D模型可以利用在ImageNet数据库[16]上预训练得到的2D参数来提升网络的特征提取性能。
对于行为视频这样的序列数据进行建模,递归神经网络(recursive neural network,RNN)具有天然的优势。研究人员将CNN与RNN或长短时记忆(long short-term memory,LSTM)相结合,提取长时程视频中行为的时空表征。文献[17]提出的长期递归卷积网络(long-term recurrent convolutional networks,LRCNs)对行为视频在时间和空间2个维度上进行了深度学习。此外,文献[18-19]提出了双流模型和LSTM相结合的行为识别方法。
最近,基于LSTM的注意力机制被应用到深度神经网络中以提升行为识别的性能。文献[20]提出了一种空间注意模型,根据每帧图像中不同区域对整个视频最终行为识别结果的重要性进行建模。文献[21]提出的VideoLSTM方法使用了2种改进的注意力模块来提升行为检测和识别的性能。文献[22]提出了一种新的用于视频行为识别的递归时空注意网络(recurrent spatial-temporal attention network,RSTAN),该方法使用一种新的时空注意机制对行为的外观和运动特征进行融合。文献[23]提出了分级多尺度注意网络(hierarchical multi-scale attention network,HM-AN),将注意机制融入到分级多尺度RNN中,得到行为识别结果。
本文方法基于二维卷积对图像进行处理。与两流模型相比,本文方法增加了注意机制来衡量每个图像帧对最终行为识别结果的重要性,提高了长时程行为识别的有效性和适应性。本文方法采用LSTM作为注意力机制的解码器,根据每帧图像在行为识别中的语义重要性对其进行加权。与现有嵌入注意力机制的动作识别方法相比,该方法实现了基于深度学习的长时程视频中行为的时空建模。对多个重叠片段中的90帧RGB图像和对应的光流图像提取注意加权时空特征,基于全局先预测后融合的方式,对所有片段进行时空预测融合,得到最终的行为识别结果。
2 嵌入注意力的时空特征融合网络
本文提出的基于ASTFFN的行为识别方法包括如下3个步骤:视频预处理、基于注意力机制的长时程时空特征提取和信息融合与预测,该方法的原理如图1所示。

图1 基于ASTFFN的行为识别方法原理
在视频预处理中,将输入的视频划分成Sn个片段,使用每个片段中的RGB图像和对应的光流图像分别作为空间数据和时间数据,然后分别进行时间和空间特征提取。在特征提取中,使用2Sn个AFEM,其中空间AFEM从RGB序列中提取空间特征,时间AFEM从光流序列中提取时间特征,并预测每个片段对应的行为类别。在信息融合中,将所有片段的时空预测分数进行融合,得到整个视频中行为类别的空间共识和时间共识,再将这2种共识进行融合,得到最终的行为识别结果。
2.1 视频预处理
视频预处理包括片段划分和光流提取2个部分。为了从长时程视频中提取时空特征,本文将输入视频分割成Sn个片段。每个片段中的1/3与相邻片段重叠,以保持片段的语义连续性。本文使用文献[24]提出的方法进行光流图像提取。为了满足AFEM中三通道输入的要求,将光流数据的U和V分量及两者的平均值合并成三通道数据作为时间AFEM的输入。视频预处理中光流数据的提取结果如图2所示。

图2 从HMDB51数据库片段中提取到的光流数据
2.2 基于注意力机制的长时程时空特征提取
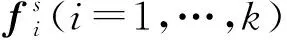
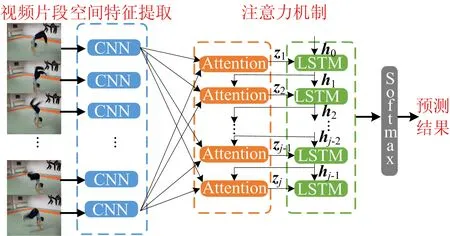
图3 AFEM结构示意图
输入注意力机制模块的d维的特征fi,i=1,…,p。视频片段中的这些特性以加权求和的形式进行聚合,即
(1)
注意力机制的关键问题是学习权重αi。设计了一个函数F来计算特征fi的重要性评分ci。每个特征的得分是基于fi与注意力对象的相关性(识别结果),即相关性越高,重要性得分越高。AFEM采用文献[25]中的基于连接的注意机制,其得分函数为:
(2)

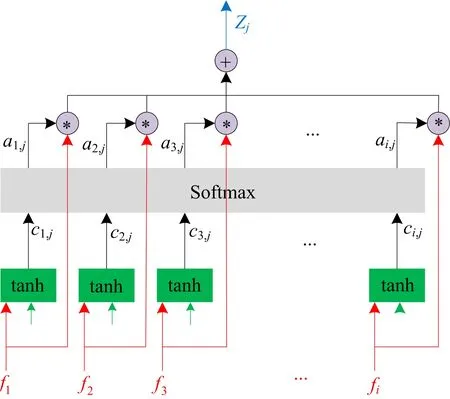
图4 AFEN中注意机制的结构示意图
2.3 信息融合
本文分别研究了2类对RGB图像序列和光流序列进行时空特征融合的方法。根据实现的细节,2类方法又可以细分为4种,如图5所示。第1类为加性先融合后预测和串接先融合后预测,第2类为片段先预测后融合和全局先预测后融合。
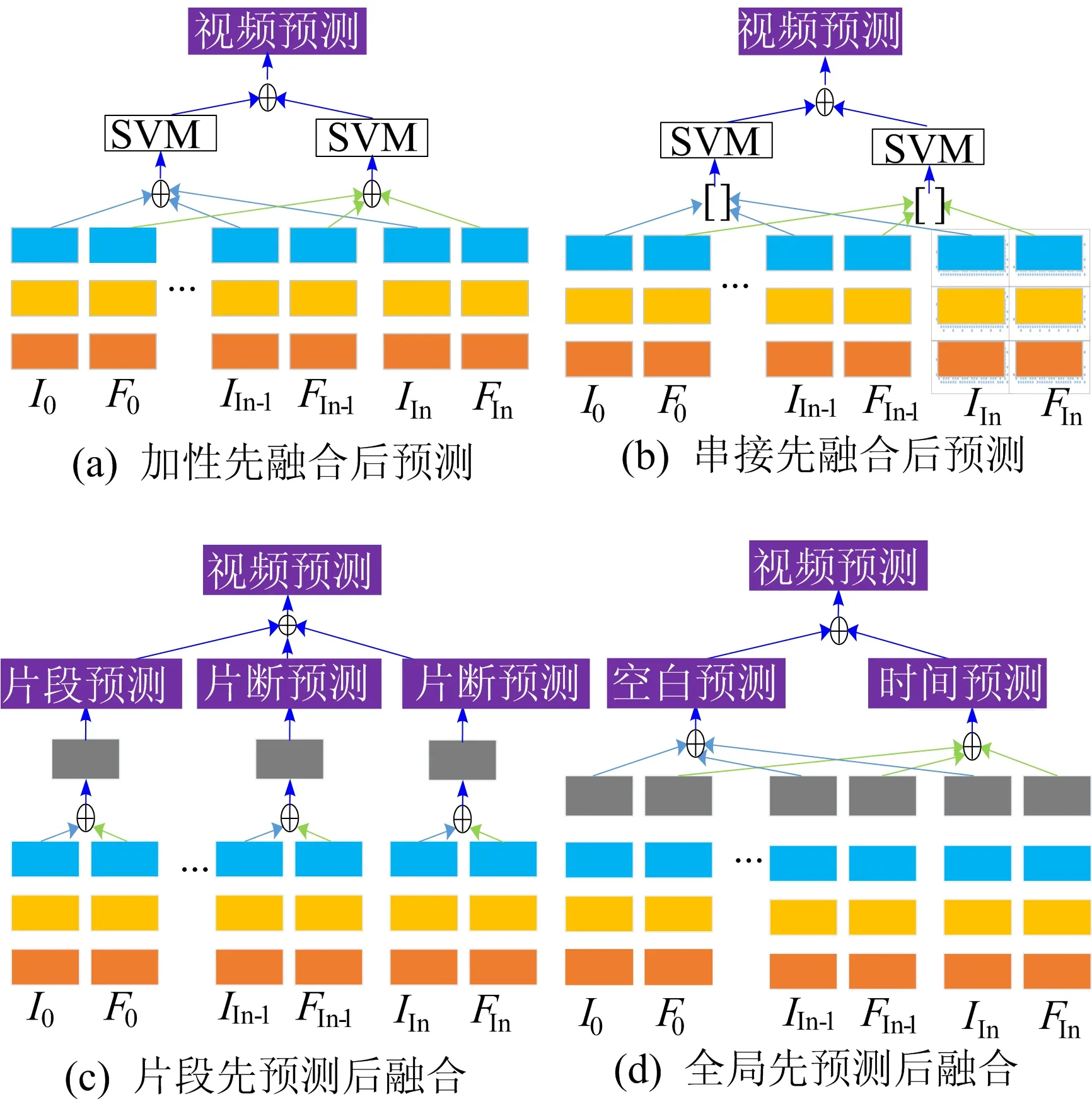
图5 信息融合的4种不同实现
图5中,橙色、黄色、蓝色和灰色框分别表示CNN中的卷积层、池化层、全连接层和softmax层。
先融合后预测首先融合每个片段的时空特征,构建整个视频的全局时空特征。然后基于融合后的全局时间特征和空间特征分别训练2个SVM分类器,对2个分类器的得分进行求和,得到最终的行为识别结果。如果每个片段的特征通过相加得到全局特征,称为加性先融合后预测;如果每个片段的特征进行串接得到全局特征,称为串接先融合后预测。
先预测后融合首先生成片段的预测分数,然后融合所有片段的预测分数,得到最终的行为识别结果。如果将每个片段的时空特征输入到softmax层,从一个片段生成预测,然后对每个片段的预测进行求和,产生最终的融合结果,那么这种方法称为片段先预测后融合。如果先将每个片段的时空特征串接起来再输入softmax层生成预测分数,得到所有片段的时间预测和空间预测,最后将这2种预测相加得到最终的行为识别结果,那么这种方法称为全局先预测后融合。
2.4 本文方法的具体实现
在基于ASTFFN的行为识别方法中,输入视频被分成Sn个片段,每个片段包含In个图像,并将相邻片段的1/3相互重叠。实验中将Sn和In分别设置为4和30。因此,该方法处理的图像序列的长度为90帧。对于小于90帧的视频,复制视频的最后一张图像,得到90帧。对于90帧以上的视频,每个片段均匀采样30帧图像。
在AFEM中,由ImageNet数据库预训练得到的Inception v3模型[26]作为CNN特征提取模块的初始参数,提取尺寸为1 024的Inception v3的顶层全连接层的输出作为输入图像的语义特征。实验中注意机制的时间步长参数TS=10。因此,注意力模块的数量和LSTM时间步长都设置为10。另外,注意力机制中的LSTM是一个具有256个隐藏节点的单层网络。在训练中,时间AFEM基于RGB序列数据进行训练,空间AFEM基于光流序列数据进行训练。测试时,将测试视频中每个片段的RGB序列和光流序列分别输入空间AEFM和时间AFEM,并产生时空预测分数。在信息融合过程中,使用文献[14]的方法将所有时空分数进行融合,形成时空共识。根据输入视频的时空共识,预测输入视频的最终行为类别。
3 实验与分析
本节通过实验对本文方法进行评估。实验中采用UCF101和HMDB51 2个长时程行为识别数据库。其中,UCF101数据库包含13 320个视频剪辑和101个行为类别。这些行为分为人物互动、身体动作、人人互动、演奏乐器和运动5种。HMDB51数据库由6 766个视频剪辑和51个行为类别组成。对于这2个数据库,采用相同的测试规则:采用数据库本身提供的3种划分,最终识别正确率取3种划分实验结果的平均值。此外,为了防止出现过拟合,对训练数据进行了剪切、旋转和尺度变换等数据扩增处理。
在以下实验中,使用带动量的随机梯度下降法(stochastic gradient descent,SGD)训练网络。mini-batch的大小为8,动量为0.9。训练学习率初始化为0.000 01,每10个训练迭代衰减为当前学习率的0.1。训练一共进行200次迭代。所有深度神经网络模型的训练和测试均基于PyTorch框架实现。所有实验均在图像处理工作站上运行,该工作站的主要配置为:Intel Xeon 2.4 GHz 8核CPU、128 Gb内存和2个NVIDIA Titan Xp GPU。
3.1 测试注意力机制不同参数带来的影响
本文方法中注意力机制模块的参数时间步长TS的选择对注意机制的性能有很大的影响。本节实验评估了在从1~20的不同TS时,该方法获得的动作识别的准确性在UCF101数据库和HMDB51数据库上的结果如图6所示。
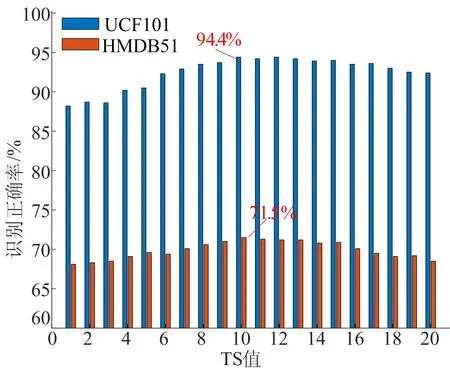
图6 本文方法在不同TS值下的行为识别精度
当TS=1时,仅通过1次迭代即可学习30帧图像中的注意力权重分布,通常只拟合30个图像帧的重要性分布是不够的。随着TS值的增加,识别精度逐渐提高。当TS=10时,本文方法在UCF101和HMDB51数据库上分别达到94.4%和71.5%的最高识别精度。当TS值继续增加时,在一段时间内保持稳定之后,行为识别的准确性就会下降。这是因为随着值的不断增加,展开的LSTM的可训练参数的大小会迅速增加,导致过拟合。因此,本文将注意力机制的时间步长参数TS确定为10。
实验记录了(1)式中的参数αi以显示本文方法中注意力机制对行为识别结果的影响。UCF101数据库中的“篮球投篮”类别和HMDB51数据库中的“握手”类别的2个视频片断及其重要性权重如图7所示。图像序列下方的条形图显示了一个片段中30帧图像的注意力重要性。图7a中篮球投篮视频的内容是从抓篮球到投篮的过程。对应于投篮动作的最后几帧图像的重要性权重明显大于对应于准备投篮动作的图像的重要性权重。前几帧权重高的原因是跳跃和接球的动作类似于投篮的动作。图7b包含握手动作的图像帧的重要性权重明显大于握手开始和结束时图像获得的权重。由图7可知,本文方法中的注意力机制可以根据视频中图像帧与识别结果之间的相关性,有效地为不同图像帧分配重要性权重。

图7 UCF101和HMDB51中的2个片段及其重要性权重
3.2 视频片段数量和片段帧采样数量的影响
视频预处理中有2个与视频划分和采样相关的参数,即片段的数量Sn和在1个片段中采样图像帧的数量In。在UCF101和HMDB51数据库上用不同的Sn值和In值对本文方法进行了测试,结果见表1所列。

表1 不同的Sn和In的值对于识别精度的影响
本文方法在Sn=4和In=30时获得了最高的行为识别正确率,这是由于UCF101和HMDB51数据库中的视频包含的图像一般在100~200帧之间。当Sn=4和In=30时,本文方法通过逐帧采样可以覆盖90帧图像,或是隔帧采样覆盖180帧图像。因此,这组参数最符合2个数据库的情况。随着Sn的增加,识别精度仅略有提高,然而,更多的代码片段会导致更大的计算和内存开销。相反,当In值减小时,2个数据库的识别精度都发生了下降。特别是当In=5时,1个片段中只采样5帧图像帧,过于稀疏,无法在视频获取足够的行为信息时,导致了较低的识别准确性。
3.3 评估不同融合机制的影响
实验使用2.3节中描述的4种不同的信息融合方式来测试本文方法的性能。实验结果见表2所列。
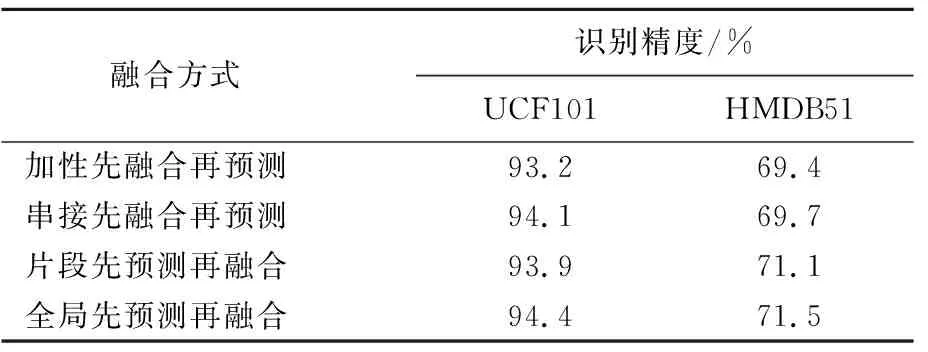
表2 不同信息融合方式下的识别精度
对于加性先融合后预测,融合特征的维度为1 024。在融合的空间特征和融合的时间特征上采用一对多多类策略训练2个线性SVM分类器,并生成空间预测和时间预测得分。将空间预测得分与时间预测得分相加,得到整个视频的最终行为识别结果。
对于串接先融合后预测,融合后的特征维数为4×1 024=4 096,后续的处理与加性先融合后预测相同。从表2可以看出,先预测后融合的表现普遍优于先融合后预测,且主要原因是先预测后融合中的特征提取和预测通过一个端到端可训练的神经网络模型实现,而在先融合后预测中特征提取和预测是分为2个步骤进行的。当存在大量可利用的训练数据时,端到端训练的性能通常要优于多步训练的性能。此外,全局先预测后融合取得了最高的识别正确率,比片段先预测后融合的结果更好。这说明全局先预测后融合方式所获得的时空特征互补性要强于片段先预测后融合所获得的时空特征互补性。
3.4 与最新的行为识别方法对比
本文方法与其他行为识别方法在UCF101和HMDB51数据库上获得的识别精度见表3所列。从表3可以看出,本文方法获得的识别精度优于大多数最新的行为识别算法。与经典的两流模型相比,本文方法在2个数据库上的正确率分别提高了6.4%和12.1%。与LRCN[17]等基于CNN+LSTM的行为识别方法相比,本文方法在UCF101数据库上的识别正确率提高了11.8%。与基于片段时空融合的TSN[14]方法相比,本文方法的正确率分别提高了0.2%和3%。结果表明,通过注意机制对视频图像帧进行重要性加权显著提高了行为识别的正确率。
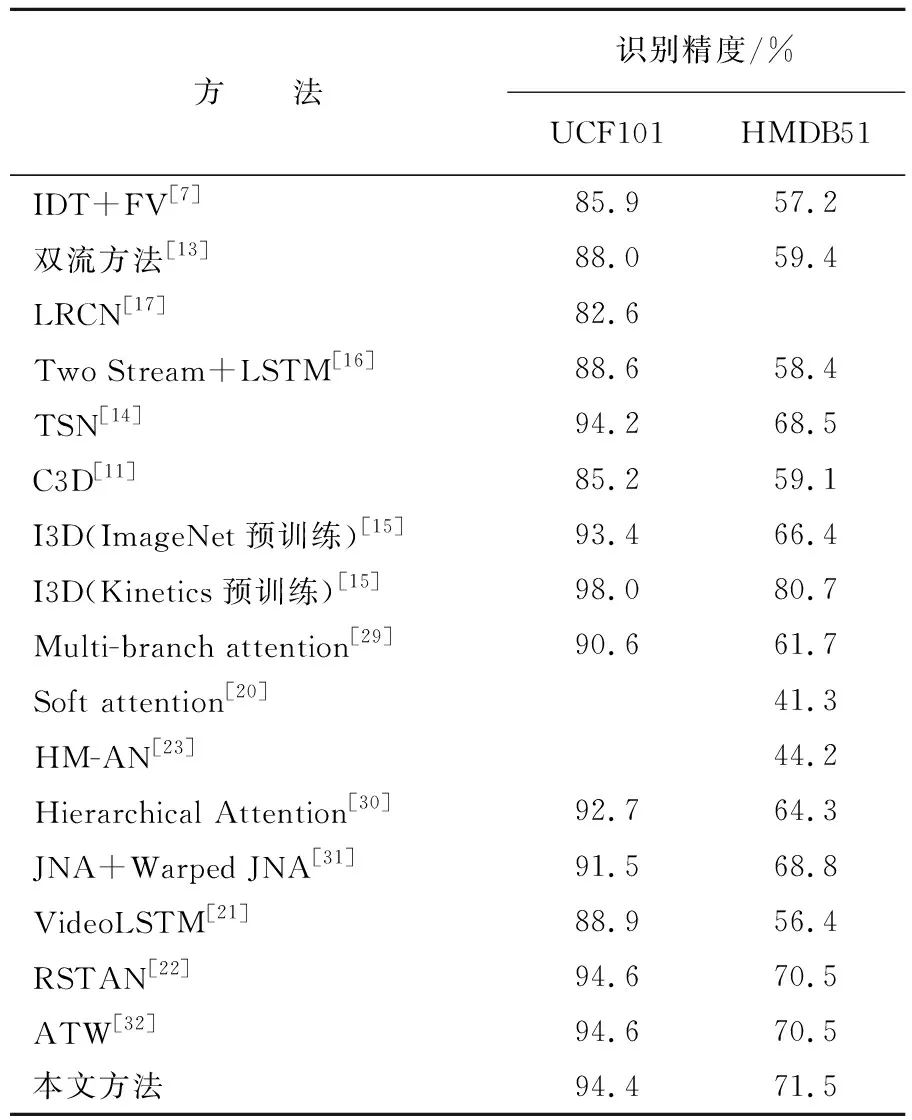
表3 本文方法与最新的行为识别方法的比较
与其他嵌入注意力机制的行为识别方法相比,本文方法在HMDB51数据库上的识别正确率最高(71.5%),在UCF101数据库上也获得了有竞争力的识别性能(94.4%)。结果明显优于经典的Multi-branch attention方法、Soft attention方法、HM-AN方法和Hierarchical Attention方法,仅比RSTAN和ATW等方法低了0.2%,表明本文方法中将合理的长时间视频密集采样策略与有效的信息融合方式相结合,可以进一步提高嵌入注意力机制的行为识别方法的识别性能。
与基于三维卷积的识别方法相比,本文方法的识别精度明显高于C3D方法和在ImageNet上预训练的I3D方法,但要弱于在Kinetics数据库上预训练的I3D方法。与基于3D的方法相比,使用相同的数据库进行预训练,本文方法可以获得更好的识别效果。如果在更大规模的行为识别数据库上进行预训练,那么I3D方法的时空表达能力会进一步增强,从而具有更高的识别正确率。
另外也有一些文献报道了深度学习模型与浅层学习模型的融合结果,如文献[21]中的VideoLSTM+iDT+Objects和文献[22]中的RSTAN+iDT-FV。由于多模型的融合效果一般要优于单一模型,为进行公平的比较,这里仅在表3中列出了单一基于深度学习方法的结果。
4 结 论
本文提出了一种嵌入注意力机制的时空特征融合网络ASTFFN,并将其应用在行为识别中。该方法将长时程图像序列分割成多个重叠的片段。密集采样RGB序列作为片段在空间维度上的表征,相应的光流序列作为片段在时间维度上的表征。将空间和时间数据分别输入由CNN+LSTM+注意力构成的嵌入注意力机制的AFEM中,进行特征提取、重要性加权和预测。上述片段预测进行融合得到最终的行为识别结果。利用2个长时程行为识别数据UCF101和HMDB51进行了大量的实验来测试本文算法,评估本文方法在注意力机制、分割、采样和融合模式等不同参数配置下的识别性能。实验结果表明,基于ALSTFFN的行为识别方法能够有效提取出长时程图像序列的时空特征,并通过注意机制对视频中不同图像赋予重要性权重。与最新的行为识别方法相比,本文方法具有明显的优势。
