基于主从博弈的智能车汇流场景决策方法
2021-09-02胡益恺庄瀚洋王春香明a
胡益恺,庄瀚洋,王春香,杨 明a,
(上海交通大学 a.自动化系;b.密西根学院;c.系统控制与信息处理教育部重点实验室,上海 200240)
智能车作为当下的研究热点之一,获得了学术界与工业界的广泛关注[1].在车辆的正常行驶过程中经常会遇到上下匝道、车道合并、道路施工等汇流场景,尽管交通法规对这些场景有着一些指导性的规定,但由于场景的独特性和驾驶员不同的理解方式,导致汇流过程成为典型的博弈场景.如何有效提升该场景下车辆通行的效率及安全性,是智能车决策系统开发中的一个关键问题.
近年来,一些学者提出了基于车间协同与车路协同的方法,即运用车辆彼此之间[2-3]以及与道路基础设施之间[4-6]的通信来解决交通冲突.虽然基于车与车通讯(V2V)与车联网(V2X)的策略能够提高路口交通的安全性和效率,但其过度依赖于车间通讯设备以及路侧基础设施,在短期内仍然难以大范围推广.与此同时,大量的研究工作聚焦于对单辆智能车的决策研究,例如:基于可达性分析方法[7],基于学习类方法[8-10]以及基于博弈论的方法[11-13]等.其中,基于博弈的方法被科研工作者视为对理性决策者之间交互建模的合适工具,并被多名科研人员进行讨论与实验验证.文献[11]将存在交互行为的所有决策个体视为非合作博弈中的参与者,以各方的状态改变作为博弈策略,通过构建收益矩阵后求解得到博弈模型的纳什均衡,以作为双方的最优驾驶策略组合.该方法虽在汇流场景中取得了优异的效果,但其并没有考虑汇流场景中路权的差异,忽略了人类驾驶员在实际驾驶中的礼貌因素,并且缺乏对车辆感知范围的合理限制,从而在决策建模时和实际产生偏差,降低了决策方法的稳健性.
本文提出基于主从博弈(Stackelberg-game)理论的智能车辆决策方法框架,该模型结合了两个参与者的不对称角色特性,并赋予了一个参与者相对于另一个参与者的优势[14-15].该决策方法有效地将汇流场景中的路权因素考虑其中,例如在匝道口交替通行路段,满足交替通行规则的车辆拥有较高的路权,可以将其视为主从博弈中的领导者,而未获得交替通行权限的车辆被合理地视为跟随者.同时,本文提出驾驶员合作收益,并考虑车辆的传感器感知范围有限性以提升决策方法的安全性、合理性与稳健性.本文工作可为智能车辆在汇流场景下运用博弈方法解决决策问题的可行性提供理论验证.
1 车辆与环境建模
建立基于主从博弈的车辆博弈模型,并分别从双车博弈以及多车博弈进行讨论.同时,建立环境的参数化模型与以此为基础的车辆轨迹模型,以提升方法的可迁移性.
1.1 车辆博弈模型
选择主从博弈作为基础博弈模型,分别定义al与af为领导车辆和跟随车辆的决策,Al与Af分别为二者对应的决策集合.在博弈中,参与者通过选择合适的策略,最大化收益函数,领导车辆的收益函数以Rl(s,al,af)表示,跟随车辆的收益函数为Rf(s,al,af),其中s∈S,S={(sl,sf)t}为当前时刻t的车辆集合状态空间.根据主从博弈均衡解的概念[15],对两车博弈进行建模,并得到领导车辆的均衡解γl与跟随车辆的均衡解γf,则有:
(1)
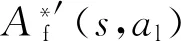
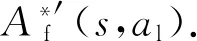
(2)
考虑到该场景下的博弈可以视为完全信息场景,即领导车辆了解跟随车辆的决策方案,从而式(1)的博弈模型可以转化为
(3)
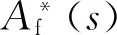
(4)
当环境中出现众多车辆时,现有方法常通过建立两两参与者之间的博弈模型后通过均衡解得到最优决策,但该方法随着参与者数目的增加,计算复杂度将呈指数级增长[17].考虑到驾驶员的视觉感知范围以及智能驾驶车辆的传感器感知范围有限,并结合领导车辆与跟随车辆的从属关系,有效地提高多车博弈模型的求解速度,可以表示为
(5)
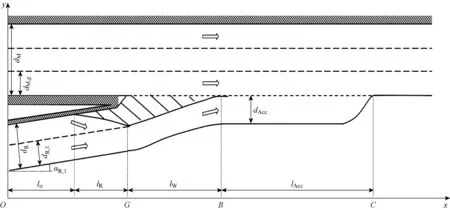
图1 汇流场景参数化建模Fig.1 Parameterized modeling of merging scenario
式中:S(t)为t时刻环境中所有车辆的状态;sp,q(t)为t时刻第p辆车与第q辆车之间的相对状态;leader为领导车辆;follower为跟随车辆;kp为笛卡尔坐标系下第p辆车的极限感知范围;xp为第p辆车的x轴坐标;yp为第p辆车的y轴坐标;ap为第p辆车的决策;Ap为第p辆车的决策集.该多车博弈模型与现实汇流场景中驾驶员的交互行为有较高的一致性,人类驾驶员无论是在加速车道还是在主车道都会对感知视野内不同目标分配不同的注意力进行判断与评估.
1.2 参数化环境模型
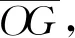
以参数组P表征汇流场景的结构特征:
P={lO,lR,lW,lAcc,dR,1,dR,dM,
(6)
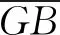
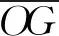
1.3 车辆轨迹模型
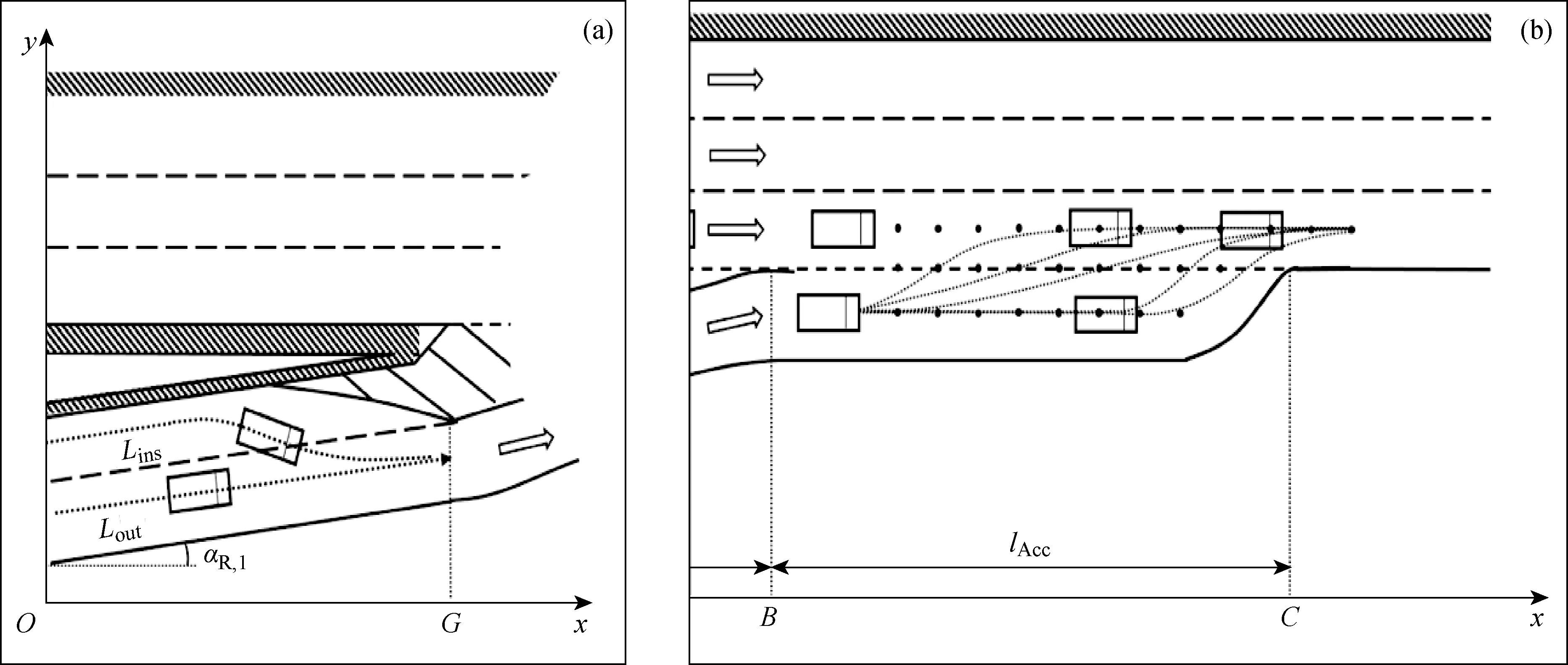
图2 汇流场景中的车辆轨迹模型Fig.2 Vehicle path model in merging scenario
2 收益函数
收益函数将显式地量化博弈参与者的目标,在汇流场景中,驾驶员以及智能驾驶车辆拥有相同的基本目标,可以概括为行驶过程中避免与环境车辆发生碰撞,并与环境车辆保持合理距离;通过并快速到达目标点;控制车辆的加速度,以优化车辆舒适性的控制收益;礼貌驾驶员的合作收益.
在计算收益函数时,运用了模型预测的思想,计算了未来帧的预测收益,从而提高模型的稳健性和安全性.考虑到基于车辆运动学模型的预测过程中会存在预测误差,针对收益函数设计了衰减因子,以提升决策方法的稳定性.
(7)
式中:Ri(t)为t时刻博弈参与者的总收益函数;Ri(st,t+kτ)为总预测收益;RAi(st,t+kτ)为安全预测收益;RTi(st,t+kτ)为时间预测收益;RCi(st,t+kτ)为舒适性预测收益;RGi(st,t+kτ)为合作预测收益;τ为预测时间间隔;k为预测的时间帧数;H为预测推演的时间窗口大小;st为t时刻车辆的状态;ω1、ω2、ω3、ω4分别为4项收益的权重;ξ为衰减因子,其表现形式为预测时间间隔越长的收益在收益项Ri(t)中的占比将会越小.
同时,在对车辆运动学建模的过程中,一般对车辆模型进行简化,采用车辆二自由度模型[18-19]实现在预测时间窗口中的车辆状态更新.

图3 车辆安全收益几何模型Fig.3 Geometric model of vehicle safety benefits
车辆安全是智能车辆行驶中最为重要的收益之一,首先定义车辆的碰撞判定以及安全距离.车辆安全收益几何模型如图3所示.其中:粗实线为车辆碰撞判定区域;粗虚线为安全预留区域;(xt,yt)为t时刻车辆后轴中心在笛卡尔坐标系中的坐标,lcf与lcr分别为车辆前、后边缘距后轴中心的碰撞判定距离;lsf与lsr分别为车辆前、后边缘距后轴中心的行车安全预留距离;wc为车辆的碰撞判定车宽;ws为车辆的行车安全预留车宽;Ac(st,t′)为预测时间帧t′时刻车辆碰撞判定区的重叠面积;As(st,t′)为预测时间帧t′时刻安全预留区的重叠面积.其中,安全预留区域的参数组(lsf,lsr,ws)为车速v(t)的函数.安全收益定义如下:
(8)
式中:ω11、ω12分别为碰撞权重和安全预留权重;vi(st,t′)vj(st,t′)为当前博弈参与者的速度,即二者速度越大,收益项会认为此隐患越危险,从而带来更大的惩罚;I(Ac(st,t′))与I(As(st,t′))为0-1函数,当相应的安全区域出现重叠时取为1,不重叠时取为0.
在保证车辆安全的同时,智能车辆行驶的另一个重要收益是以较短的时间到达目的地,越快的速度将会得到更多的时间收益,从而将每一时刻车辆的速度作为时间收益,收益函数定义如下:
RTi(st,t+kτ)=RTi(st,t′)=vt(st,t′)
(9)
式中:vt(st,t′)为预测时间帧t′时刻研究对象的速度.
乘客的舒适性亦为决策的收益之一,急动度为加加速度,是加速度对时间的求导,为衡量车辆控制平顺度的重要指标,并且直接影响车辆成员对舒适性的感受.车辆的舒适性预测收益可以定义为
RCi(st,t+kτ)=RCi(st,t′)=-J(t′)
(10)
式中:J(t′)为t′时刻车辆的急动度.
考虑到现实驾驶环境中,驾驶员在进行决策时,并不采用完全自私决策,而会考虑到自身决策对环境其他驾驶员的影响.本文提出合作预测收益RG(st,t+kτ),以实现对驾驶员合作行为的量化建模:
RGi(st,t+kτ)=RGi(st,t′)=-|uj(st,t′)|
(11)
式中:uj(st,t′)为参与者在其博弈环节环境中第j辆车辆的加速度,以表征参与者自身决策对环境其他车辆行驶的影响.uj(st,t′)的值越大,代表对其他车辆的影响越大.当车辆所做出的决策会使环境中其他车辆的速度发生变化时,合作收益将会减少.智能车辆在进行决策过程中,将会考虑其对其他博弈参与者带来的影响,从而表现出与实际驾驶相符的礼貌性.
本节从安全收益、时间收益、控制收益以及合作收益4个方面对智能车辆在汇流场景中的决策目标收益进行定义.将式 (7)~(11)与式 (5)结合,可得到决策的显式过程,同时由于收益函数均具有显式物理含义,大大增强了决策方法的可解释性.通过调整收益函数项的权重系数以及具体收益函数中的计算参数,即可实现对期望目标的定向决策优化.
3 决策求解方法
本文所提出的决策求解方法,以当前时刻的环境观测为输入,根据车辆路权确定其在主从博弈中的优先度,随后根据环境观测生成候选轨迹后,计算从当前时刻向前推演的博弈参与者收益,并使用基于主从模型的博弈方法得到决策计算结果:
γ∈A={a1,a2,…,aM}
(12)
式中:γ为博弈参与者的均衡解;ai为车辆的决策,此场景下决策的值为车辆的加速度,ai=ui∈[umin,umax].
决策模块生成的决策结果为当前时刻应采用的车辆加速度,该结果将传递给车辆的控制模块,以实现车辆的纵向控制.车辆的横向控制由路径跟踪模块实现,此处不展开讨论.所提车辆决策方法流程图如图4所示.
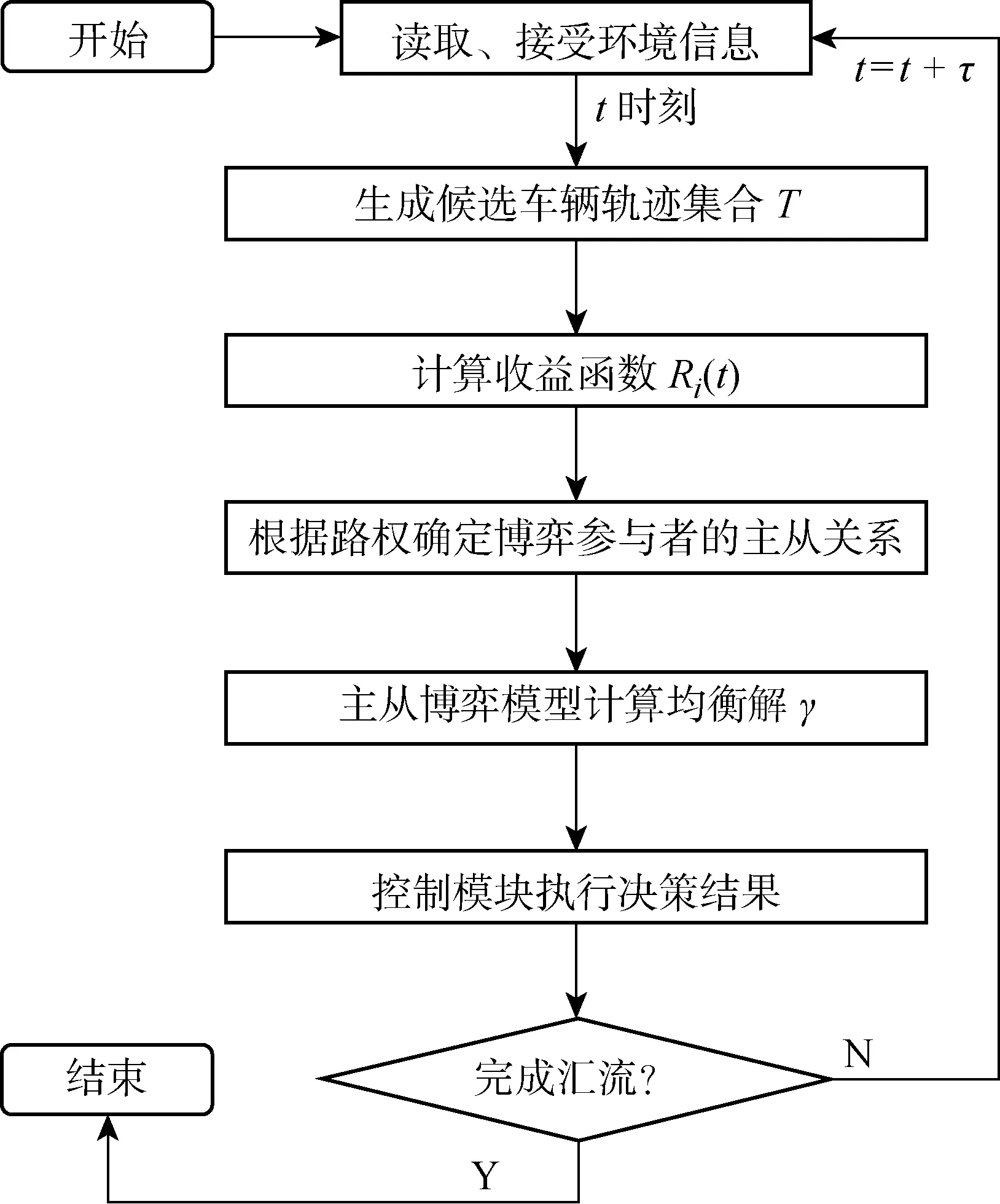
图4 面向汇流场景的决策方法流程图Fig.4 Flowchart of decision method for merging scenario
4 实验结果与分析
本文分别在INTERACTION数据集以及NGSIM数据集上进行了实验.其中,INTERACTION数据集是由加州大学伯克利分校机械系统控制实验室(MSC Lab)等建立的一个具有国际性、对抗性、协作性的数据集[20].其匝道收缩场景及加速车道场景如图5所示.其中:DR_DEU_Merging_MT数据集采集地点位于德国,是一个经典的道路收缩场景;DR_CHN_Merging_ZS数据集采集地点位于中国,该数据集中同时出现了道路收缩以及加速车道汇流的场景;图中数字编号为所采集的车辆编号.

图5 INTERACTION 数据集Fig.5 INTERACTION dataset
NGSIM数据集[21]由美国联邦公路局提供,本文采用文献[11]中所采用的数据集NGSIM-US 101.
采用行为预测准确率(ζ)以及平均绝对误差(MAE)作为决策方法的评估指标.行为预测准确率的定义可以表示为
(13)

(14)
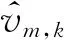
分别基于3个数据集展开了决策实验,并记录了ζ与MAE的具体表现,如表1所示.其中,加粗的数据为决策表现更优的评价结果.通过对比分析可知,本文方法优于文献[11]中所提出的方法.

表1 决策方法行为预测准确率及其MAETab.1 Prediction accuracies of decision-making method behaviours and their MAE
行为预测准确率与车流量的关系如图6所示,其中:V为主路车道车辆数.在不同数据集中,随着主路车道上车流量的增大,本文所提方法与文献[11]方法相比,行为预测准确率的下降趋势较缓,从而论证了本文方法在车流密度较高的场景下有较强的稳定性.
通过实验结果对比分析可知,本文所提出的基于主从博弈的智能车辆决策方法在行为预测准确率方面,在INTERACTION数据集的表现优于文献[11],但在NGSIM-US 101数据集上的准确率略低于文献[11]中的结果,原因是由于文献[11]中针对NGSIM数据集中378对训练数据进行了针对性的参数标定,所以有一定过拟合现象的产生.在决策输出的平均绝对误差方面,本文方法优于对比文献中的方法.同时,随着主路车道上车流量的增大,本文提出的方法在行为预测准确率和MAE两个指标上的变化较少,文献[11]中的指标略有下降,从而体现出本文方法的稳健性.
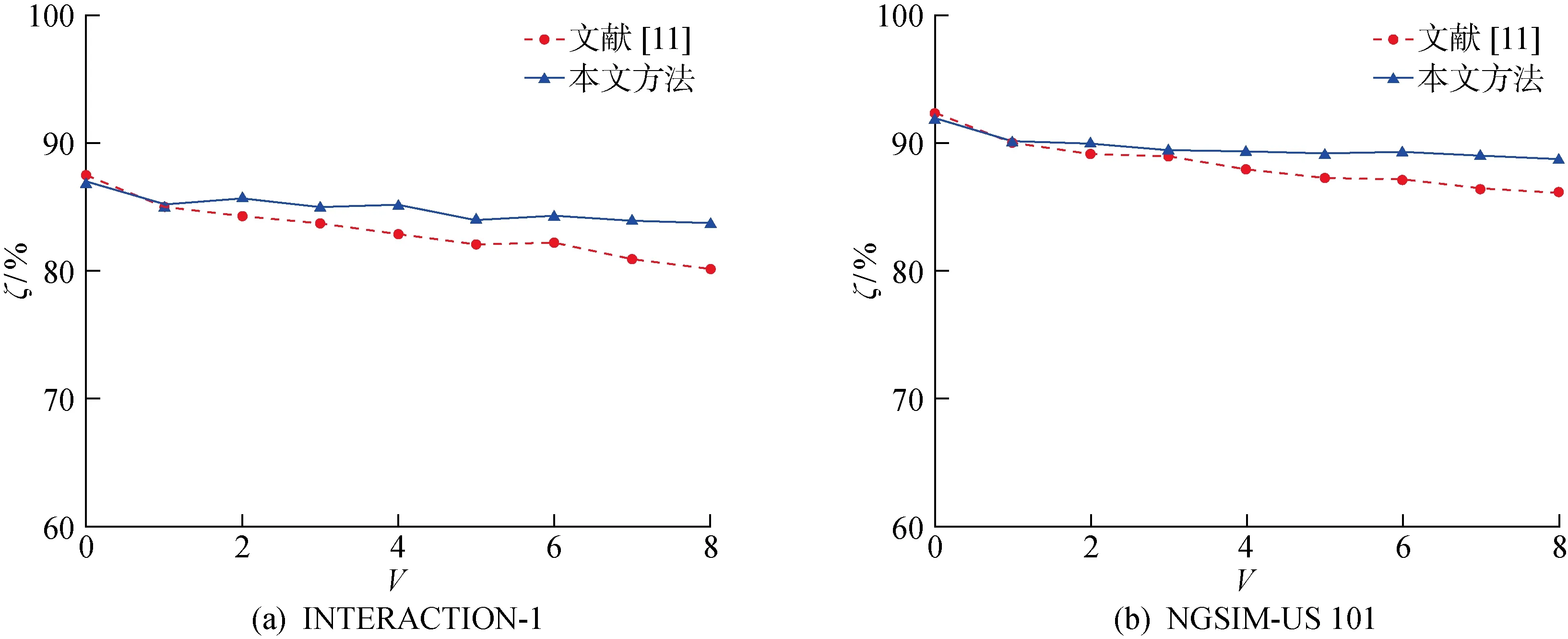
图6 行为预测准确率与车流量关系Fig.6 Behavior prediction accuracy versus traffic flow
5 结语
本文提出了一种基于主从博弈的汇流场景智能车决策方法,该方法通过引入路权的定义,分别构建了双车博弈模型以及多车博弈模型,用以解决汇流场景中的决策问题.此外,本文还设计了汇流场景的参数化模型,增加了决策方法的可迁移性.本文通过设计安全收益、时间收益、控制收益以及合作收益,显式地构成了车辆博弈中的目标收益函数,增加了所提决策方法的合理性与可解释性.最后,分别基于INTERACTION与NGSIM数据集进行测试与分析,验证了所提方法的有效性与稳健性.结果表明,基于主从博弈的决策方法可以和汇流场景中的路权信息有效结合,提升决策的合理性.同时,合作收益的引入可以使无人驾驶车辆解算出更加类人且安全的决策.下一步工作将致力于在更加普适的场景中研究基于博弈方法的智能车决策问题.
