模糊先验引导的高效强化学习移动机器人导航
2021-08-31刘浚嘉谢荣理
刘浚嘉,付 庄,谢荣理,张 俊,费 健
(1.上海交通大学机械系统与振动国家重点实验室,上海200240;2.上海交通大学医学院附属瑞金医院,上海 200025)
0 引言
经过机械、电子、控制、计算机等领域长达数十年的发展,机器人在服务行业的应用逐渐兴起。与工业界中的情况类似,日渐高昂的人工成本以及老龄化等社会问题,极大地增加了人们研究与开发服务机器人的热情。服务机器人相较于较成熟的工业机器人,具有多任务、非结构环境和安全可靠等复杂要求[1]。尽管基于现有技术设计的服务机器人还远不能满足人们对美好生活的向往,但已经引领了社会与人类生活的新潮流。
要想使服务机器人走进家庭,就要使其具备主动完成人类指定任务的能力。在现有技术支撑的前提下,一个可行的任务就是在复杂房屋中高效地到达人类指定的目标位置。高效准确的主动目标导航是一切服务的基础,因此,人们对移动服务机器人的自主导航能力有更高的要求。移动服务机器人需要能够根据周围环境的变化采取相应的措施来提高移动机器人的避障、导航能力。此外,考虑到成本因素,应仅使用RGB-D传感器完成上述要求[2]。因此,研究者们逐渐对将强化学习算法与机器人导航方法相结合产生兴趣,旨在以学习的方式使机器人能够通过与真实环境交互,自主探索并学习得到完成任务的最佳策略。
1 数据高效强化学习算法
深度强化学习(deep reinforcement learning,DRL)在游戏与棋类任务中的成功,是建立在使用大量数据对大型神经网络进行训练之上的,也就是使Model-based RL(MBRL)算法也具有这一特性。目前,先进的智能体通常都具有很高的样本复杂度,以近期在游戏中性能最强的几种算法为例,MuZero[3]和Agent57[4]在每场Atari游戏中,均需要借助10~50年的经验,OpenAI Five[5]更是利用了相当于人类45 000年的经验来实现其卓越的性能。这些都是在模拟环境中通过大规模显卡(GPU)与CPU集群的并行训练才实现的。在现实中,这显然是不切实际的,与虚拟环境中的游戏不同,许多显示任务收集交互数据的成本很高,高频、高强度的交互甚至会导致系统的损坏,这在机器人领域是格外值得关注的。此外,从仿生学角度来讲,这种利用大规模数据进行并行学习的方式也不符合人类学习的直觉,相比之下,人类近乎单线程的学习是十分高效的,通常可以仅通过很少的例子就掌握相关知识。要想DRL算法能够大规模应用到机器人的智能控制中,提高数据效率成为不可避免的技术路线[6]。
导致DRL算法数据利用效率低的原因有很多,Yu[7]列举了影响数据效率的5个方面:探索策略、优化方法、环境模型学习、经验迁移与抽象化。本文结合这篇文章的观点,将影响因素总结为以下几点:
a.探索策略。常用的ε-greedy和Gibbs采样等基础探索策略是比较盲目且低效的。
b.环境模型学习。MBRL相较于Model-free RL(MFRL)在策略学习的同时,利用同一组数据学习一个环境模型,会在数据的利用效率上有所提升。
c.状态与动作空间维度。DRL算法是将深度学习技术应用于传统强化学习的函数拟合与优化中,而神经网络的参数量和拟合能力与输入输出维度成指数级相关性,维度越高,神经网络所需的参数量越多,拟合难度越大。
目前对高效强化学习的研究主要从2个方面入手:引入概率神经网络或专家先验的软约束。MBPO[8]是一种以贝叶斯神经网络为拟合工具的MBRL算法,将模型的误差以概率的形式考虑到策略的学习中,使其不完全依赖模型对未来状态预测,从而实现策略在可信区间内的鲁棒预测学习;此外,也可以通过引入专家示范作为软约束,从不完美的示范数据中得到大致的探索方向[9],从而对强化学习的策略学习起到引导作用。二者均能够提高训练数据的利用效率,从而加速学习进程。
2 模糊先验引导的数据高效强化学习算法
2.1 融合控制框架
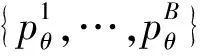
(1)
MBPO采用Soft Actor Critic (SAC)[10]作为其策略优化算法,SAC在每一次策略估计时,估算值函数为
(2)
作为动作的评价指标,并在策略提升环节通过最小化期望KL散度Jπ(φ,D)=Est~D[DKL(π|exp{Qπ-Vπ})]来训练策略。本文在其基础上,结合先验知识,提出了能够有效避免无意义探索的融合控制器,如图1所示。
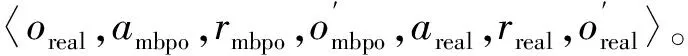

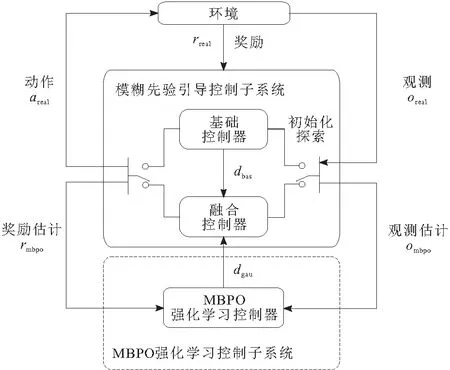
图1 模糊先验引导融合控制框架
(3)
(4)
IPK的动作可以确保机器人以很大概率避开障碍物,并且避免在训练的初期在与目标方位完全相反的方向进行无意义的探索,而MBPO子系统仍可以在IPK的先验安全约束下,以一定程度的精度改进整体的融合策略。因此,上述融合控制器就实现了学习过程中的安全探索。此外,它实现仅通过1次交互,而获得2种不同的经验,这显然会比单纯的MBPO更加高效。
2.2 先验与强化学习的融合方式
在初始化探索过程之后,MBPO将以高斯策略作为主要学习策略,该策略输出符合高斯分布的动作分布均值和方差。相应地,IPK子系统也进入了新的阶段:融合控制器。尽管MBPO通过仅查询短期推出的模型来解耦任务范围和模型范围,但是它仍然受到达到目标的可能性的限制,尤其是在稀疏奖励问题中。由于IPK的基础控制器是基于规则的,因此,可以很方便地为其评估性能,从而形成了解决稀疏奖励问题所提倡的内在激励。从初始Replay Buffer及其任务长度的记录中,可以将数据还原为完整格式。在每个时间步上,都可以得到动作前后的目标向量,然后可以容易地估计出每个动作与预期方向的偏差。这些偏差可以描述为高斯分布。此外,SAC的原始行为也是高斯分布。因此,需要提出一种可行的方法,能够将这2种有用的信息同时应用起来。
一个非常朴素的想法就是将基本控制器输出的高斯分布与SAC动作分布融合在一起。卡尔曼滤波器是一种融合多个传感器的测量信息,且比任何一个传感器都更准确的常用方法。如图2所示,本文使用卡尔曼滤波器对2个控制器的输出进行融合,并获得新的融合分布。此过程在SAC的重参数化技巧之前进行。
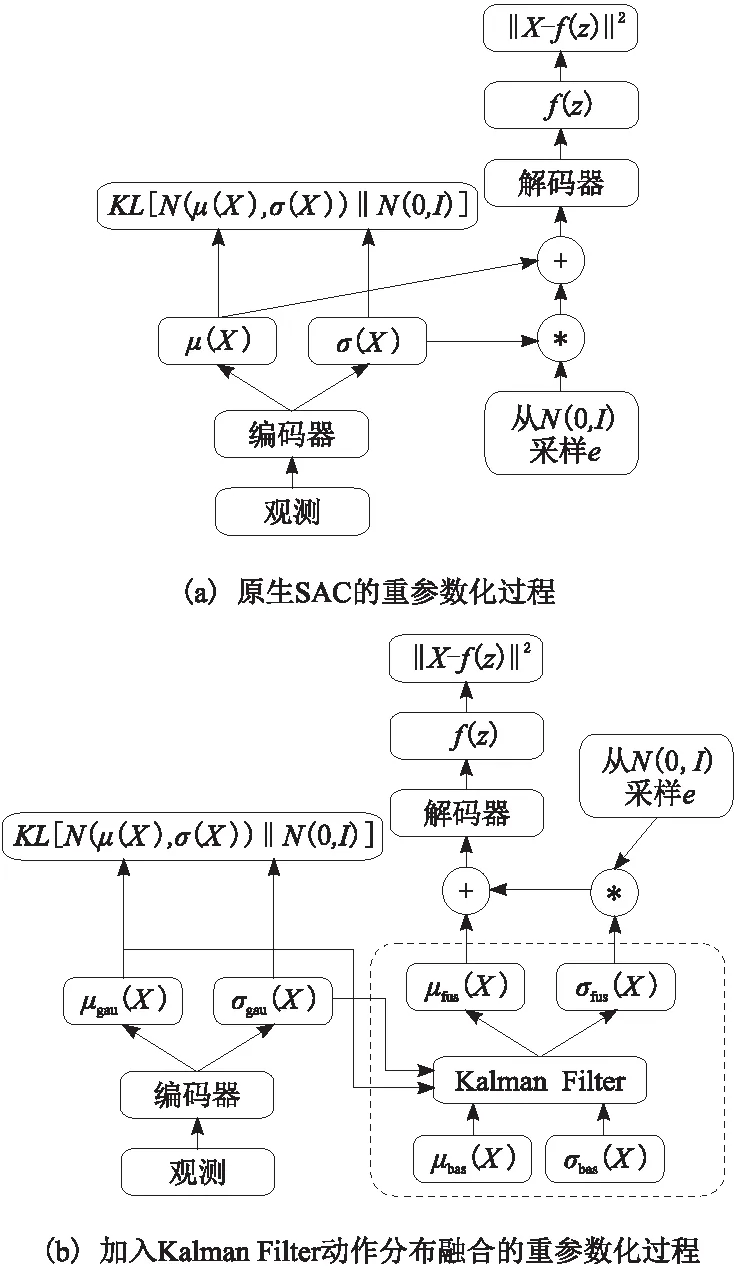
图2 模糊先验引导融合控制器的动作分布融合原理与原生SAC的比较
(5)
(6)
3 实验验证
3.1 分布式DD-PPO强化学习点导航基准
针对强化学习以及所提出的数据高效强化学习控制器的仿真性能验证,本节采用Matterport3D[11]以及AI Habitat2020挑战赛中的PointNav[12]任务作为控制器算法的评价标准,并在Habitat[13]模拟器中继续实验。PointNav任务使用了成功率、sPL和DTS(distance to goal)的评价指标。sr表示在多次实验中找到目标的概率,定义为
(7)
N为总实验次数;Sui为一个二进制值,表示第次实验的成功或失败。sPL同时包含了对成功率和路径长度的考量,定义为
(8)
在第i次实验中,本文使用模拟器提供的最短路径长度作为Li,而机器人的路径长度为Pi。DTS是每次实验结束时,智能体到目标物体边界的距离,也是机器人离任务成功的距离。
本节复现了Habitat挑战赛官方给出的基线算法——DD-PPO[14]。该算法以PPO(proximal policy optimization)[15]为核心,对其训练方式进行了更改,以实现去中心化的分布式PPO(decentralized distributed,PPO)。DD-PPO利用分布式数据并行地将PPO无缝扩展到数百个GPU组成的服务器集群。这些GPU集群是完全去中心化的,不含有中央服务器,这种做法可以使分布式算法不受集群规模限制。去中心化分布式的具体实现方式是将每一个Worker的参数使用PPO计算策略梯度,并将这些梯度分享给其他Workers,即
(9)
由于该算法的官网没有给出专门针对Matterport3D数据集的预训练模型参数,本文只能依靠现有设备进行复现。通过使用2块Nvidia GTX 2080Ti显卡,分布式运行6天、共计超过70 M(百万)步。经过长时间的训练,即使仅使用2块显卡也可以得到不错的效果。其中,DTS最后达到1.2 m左右,即机器人在任务终止时到目标点的平均距离是1.2 m;sr和sPL分别达到了约83.7%和0.68。很明显,该结果还并未完全达到收敛,但考虑到时间成本与算力限制,本文只能将这个结果作为数据高效强化学习的对比。由于对比更加关注训练效率、速度,因此并不影响本文得到正确且合理的结论。
3.2 模糊先验引导的高效强化学习
本节使用与DD-PPO相同测试环境与作图方式,旨在展示本文所提出的数据高效强化学习算法的高效性。图3展示了引入模糊先验引导的Model-based算法、原生的MBPO算法以及分布式DD-PPO算法对比。表1整理了3种算法对应的收敛位置时的累积回报与训练时长。本文所使用的模糊先验,或称作基础控制器,正是上一节训练得到的DD-PPO模型。然而,与现有的迁移学习方法不同,本文以融合的方式使新的强化学习控制器能够在具备一定性能的基础控制器引导下,加速学习进程。值得强调的是,该基础控制器还可以使用调参后的TEB等传统无图点导航方法,甚至可以仅给出一些显而易见的避障规则。

图3 模糊先验引导的数据高效强化学习的性能对比

表1 3种算法收敛位置时的累积回报与训练轮数
由图3的对比结果可知,Model-based的强化学习方法相较于普通的Model-free方法确实有数据高效的优势,符合理论预期。而本文提出的模糊先验引导的IPK算法,能够较另2种方法大幅提升训练速度,相当于在一名知识水平尚可的教师指导下学习。IPK是DD-PPO先验与Model-based的MBPO算法的融合,其出色的训练速度是建立在二者基础上的,因此能得到这样的效果并不意外。当然,这其中也有本文所提出的融合方式的贡献。在具体的实验中,作为模糊先验基础控制器的DD-PPO首先进行初始化探索,通过模拟器的反馈,对自身性能以及动作误差有大致的了解。将这种误差考虑到后续的动作输出中,使其以高斯分布的形式输出动作的概率分布。再将MBPO的高斯概率输出,与该基础控制器输出分布进行动态Kalman融合,即得到融合动作分布。对该分布进行采样,其结果即为融合动作。显然,该融合动作收到模糊先验基础控制器的软约束,同时也保证了MBPO学习控制器能够在这个安全限制下进行充分的探索。
4 结束语
本文所提出的数据高效强化学习控制器具有以下特点:
a.能够以概率的形式融合先验,使强化学习的策略学习建立在一定先验知识的及基础上,实现高效训练。
b.强化学习的自主探索受到先验控制器的软约束,确保了机器人在自主探索时的安全性。
c.实际的动作是由融合控制器输出的,提升了控制系统的鲁棒性。
