面向新闻评论的汉语反问句语料库构建
2021-08-31李翔朱晓旭刘承伟
李翔,朱晓旭,刘承伟
(苏州大学 计算机科学与技术学院,江苏 苏州 215006)
0 引言
反问句是汉语中一种常用的、有特色的疑问句,由于其自身的特殊性以及重要的应用价值,一直受到诸多研究者的关注。刘彬[1]、李宇明[2]、刘钦荣[3]、于天昱[4]等研究者分别从修辞、语法、语义、语用、反诘度多个角度对反问句进行了研究。在不同的语境,针对不同的对象,反问句往往具有不同的语用价值,表达不同的情感[5]。越来越多的自然语言处理任务都要求对文本进行更细粒度的情感分析,而反问句作为一种带有强烈感情色彩的特殊表达方式,如果能对其进行正确地识别,将会改善情感分析等任务的结果。例如,在例句1、2 中,虽然都有疑问代词“什么”,但例句1 表达的是疑问,说话者想知道这是一家什么样的医院,而例句2 则是反问句,说话人在否定这家医院的治疗水平,表达的是负面情绪。
例句1:这是什么医院?能把我的病治好吗?
例句2:这是什么医院?小感冒都治不好!
目前,利用计算机对汉语反问句进行识别的研究尚处于起步阶段,现有的数据集也非常少。语言学家对反问句进行研究所使用的语料多以文学作品为主,难以为反问句识别提供有效帮助。在语料收集方面,仅文治等人[6]采用人工标注的方式获取了1 700 余句微博反问句语料。因此,整理并构建一个较大规模的汉语反问句语料库尤为重要。本文主要贡献如下:
(1)提出一种基于半监督学习和主动学习的半自动反问句语料收集方法。
(2)构建了一个6 000 余句的新闻评论汉语反问句语料库,并将其应用于反问句识别,取得良好效果。
本文组织结构如下:第1 节介绍关于反问句研究、语料库建设的相关工作。第2 节详细阐述反问句语料收集方法,并对构建的语料库进行分析。第3 节介绍反问句识别实验。第4 节给出本文结论。
1 相关工作
1.1 反问句研究
在语言学领域,语言学家们着眼于反问句的特殊性,从不同的角度进行了研究。刘彬等人[1]提出了反问句的识解机制,即听话人可通过语言交际中的“合作原则”及其下的相关准则来对反问句的意义进行理解。李宇明[2]考察了反问句和疑问句在语表形式之间的交叉关系,即存在特殊句式既可以构成疑问句,又可以构成反问句。刘钦荣[3]认为在句法结构上,反问句的特指疑问句和是非问在语义不发生改变的情况下可以互相转变。刘芳[7]从反问句标记角度进行研究,将反问句标记分为五类,即副词标记、疑问代词标记、能愿动词标记、指示代词标记和句末语气词标记。
在应用计算机识别反问句方面,文治等人[6]将反问句的句式结构作为识别反问句的重要特征,提出一种融合句式结构的卷积神经网络反问句识别方法,该方法的精确率为89.5%。李旸等人[8]则在文治等研究的基础上,利用特征抽取模型获取与反问句相关的语言特征,设计了一种基于语言特征自动获取的反问句识别方法,达到90.7%的精确率。
1.2 语料库建设
汉语语料库的建设开始于20 世纪80 年代,研究者们根据所在领域提出了不同的构建语料库的方法。JIANG 等人[9]在修辞结构理论的基础上,对宏观篇章信息和附加篇章信息进行标注,构建了宏观汉语篇章树库。奚雪峰等人[10]提出自顶向下、后向搜索的标注策略,采用人机结合的标注方式,完成了篇章话题结构语料库构建。任璐等人[11]利用命名实体识别等技术对中文笑话的标题、主人公等进行机器自动识别,并人工对机器识别的结果进行修正,标注了33 025 条中文笑话。ZOU 等人[12]参考BioScope 生物医学文献语料库[13]的标注规则,制定针对中文否定信息与不确定信息标注规则,构建了一个由三个子语料库组成的中文语料库。朱晓旭等人[14]设计了一个机器自动判别与少量人工标注相结合的脏话语料采集方法,构造了6 000 规模的脏话语料库。曹媛等人[15]开发出中文事件事实性信息标注平台,在ACE 2005 中文语料库的基础上完成了Movement 事件的事实性标注。在以上方法的基础上,本文构建了汉语反问句语料库。
2 汉语反问句语料库
2.1 反问句语料标注规则
因为现阶段尚没有公开的汉语反问句语料库,本文的主要工作是构建一个高质量的反问句语料库。本文在构建语料库的起始,为保证质量,采用人工标注的方式标注了少量数据,标注规则如下:
(1)疑问句中说话人在已经知道或倾向于知道某个信息时,仍发出疑问,则该句子为反问句。例如“国足连叙利亚都输,能进得了世界杯?”,从语境可以判断出,该句的语用前提是说话人已经倾向于认为想进世界杯,起码要赢叙利亚,可以推断出说话人的“能进得了世界杯?”并不是真性疑问句,而是反问句。
(2)对于较为简短的、没有给出语境的疑问句,可将其判定为非反问句。如例1、2 中的“这叫什么医院?”,在给出特定语境的情况下,例2 的说话人表达出反问意义,如没有给出语境,则将其视为疑问句。(3)含有反问句标记的句子可能不是反问句。(4)在某一长句的分句中出现反问句,可将该长句判定为反问句。
(5)遵循“宁缺毋滥”原则,对模棱两可的句子不予标注。
本文采用kappa 值[16]作为衡量语料标注一致性的指标,由两名标注者根据上述规则对100 条数据独立进行标注。统计的结果如表1 所示,kappa 值为0.78,语料标注的一致性在可接受范围内。

表1 语料标注一致性的统计结果Table 1 Statistical results on the consistency of corpus tagging
2.2 语料库构建
2.2.1 语料库构建流程
为了在保证语料库质量同时减少人工标注的工作量,本文根据半监督学习和主动学习提出了一个需要少量人工干预的半自动反问句语料收集方法。本文在新浪体育网中国足球版块获取了大量评论数据,并对数据进行了去重、分句等处理。本文构建了一个基于特征词典的反问句识别器以筛选出数据中反问特征明显的反问句,并将数据分为反问句集合、不确定集合以及非反问句集合。在分析评论数据过程中可以发现,不确定集合中包含大量需要依据语境判断的反问句,对于这一类反问句,本文采用人工标注的方式。为了最小化人工标注的工作量,本文提出未标注样本选择策略,构建了基于CNN、LSTM 的反问句主动学习器。语料库构建流程如图1 所示。

图1 语料库构建流程图Fig. 1 Construction flowchart of the corpus
2.2.2 基于特征词典的反问句识别器
本文按照2.1 节制定的标注规则对新闻评论数据进行人工标注,获得反问句和非反问句各300 条。利用已标注的语料以及语言学家们对反问句标记的研究,本文总结了81 种反问句特征词,并根据不同特征词对句子反诘度的影响程度,为每一个反问句特征词设置权值value,0<value<10,value值越大,反问特征越明显,对反诘度的影响也越大。因此,可以将每一个特征词及对应的权值看作一个二元组(feature,value),建立反问句特征词典,如表2所示。

表2 反问句特征词及权值(部分)Table 2 Feature words and weights of rhetorical questions(part)
为避免构造语料库过程中重复标注反问特征明显的反问句,本文设计了一个基于特征词典的反问句识别器。在识别器中,句子反诘度score的公式为

设句子S=(w1,w2,w3,…,wn)由n个词语组成,含有m个反问特征词,通过查询反问句特征词典 可 得 句 子 的score。当score>Threshold1 时,S扩充至反问句集合;score<Threshold2 时,S扩充进非反问句集合,其余情况S扩充进不确定集合。通过实 验,Threshlod1 取10,Threshlod2 取4 时,识 别 器对反问句的识别精确率为91.6%,对非反问句识别精确率为93.0%。反问句识别器对评论数据进行迭代识别,并在迭代过程中动态更新特征词的权值,共计进行了三次迭代,获得3 378 条反问句,57 698 条非反问句,不确定集合中含有5 802 条评论数据。
2.2.3 基于CNN、LSTM 的反问句主动学习器
在不确定集合中,由于反问句与其他句型之间的交叉关系[2],集合中的数据虽含有反问句特征词,但其反问特征并不明显。本文数据使用的是新闻评论数据,同一则新闻中可能会出现相似的评论,例如“垃圾!踢叙利亚都踢不过,国足的希望在哪里啊?”,该评论与“叙利亚这样的国家都踢不过,国足的未来在哪里?”在句式上基本相同,且都表达的是反问,如果能避免对这一类数据的重复标注,将会提高标注的效率。
因此,对于不确定集合的数据,本文采取人工标注结合主动学习器的方式来扩充反问句语料库。本文根据LEWIS 等[17]、FREUND 等[18]的主动学习算法,提出了未标注样本选择策略,并构建了基于卷积神经网络(CNN)[19]的反问句主动学习器和基于长短时记忆神经网络(LSTM)[20]的反问句主动学习器。
反问句主动学习器分别以CNN、LSTM 为基础,将句子的矩阵表示作为神经网络的输入,输出每个句子为反问句和非反问句的概率值Pc0、Pc1。学习器根据以下未标注样本选择策略筛选信息量最大的样本。
(1)任一学习器的Pc0、Pc1的值越接近,学习器对样本属于哪一类标签的不确定度Uncertainty越高(见公式(2)),即样本被错误分类的可能性就越大,这一类的样本应由人工标注。因此,Uncertainty大于0.8 时,样本被学习器选择。

(2)两个学习器对同一样本数据预测结果是否一致,用该样本的分歧度Divergence表示。Diver⁃gence<0,预测结果一致;Divergence>0,预测结果不一致。学习器将主动选择预测结果不一致的样本。公式3 中Pnc0表示CNN 主动学习器对样本数据为反问句的预测概率,Plc0表示LSTM 主动学习器对样本数据为反问句的预测概率。
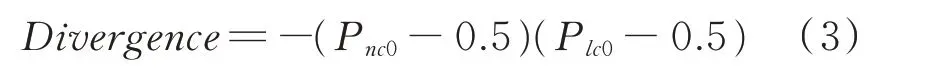
训练好的CNN、LSTM 反问句主动学习器按照上述样本选择策略仅筛选不确定度高、分歧度大的样本交由人工标注。在筛选过程中,若两个学习器都判定某样本为反问句,则将其扩充至反问句集合,否则扩充至非反问句集合。利用扩充的反问句语料以及人工标注的反问句语料再次训练两个学习器,让学习器学习具有代表性的样本信息,以不断优化其性能。本文从不确定集合中人工标注500条反问句训练主动学习器,学习器每次对500 条数据进行学习,共计进行10 次,获得反问句2 670 条,其中人工标注数据量为21%。实验过程如表3所示。

表3 主动学习器实验过程Table 3 Active learner experiment process
2.3 语料库分析
经过上述实验,汉语反问句语料库规模达到6 000余句。为选取具有代表性的反问句特征词,本文对反问句特征词典中的特征词进行置信度计算,选取置信度大于75%的特征词,并根据句子中是否含有特征词将反问句分为显式反问句和隐式反问句。特征词如表4 所示。

表4 反问句高置信度特征词(部分)Table 4 Rhetorical questions with high confidencefeatures(part)
置信度是统计中较为常用的方法之一,计算方法如公式4:

其中,yt表包含反问句特征词且是反问句,yf表示包含反问句特征词但不是反问句。
表5 显示的是语料库相关统计数据,文本长度以字为单位。语料库中,反问句数为6 548,其中显式反问句占比40.5%,隐式占比59.5%。本文在非反问句集合中抽取6 191 条非反问句,平均长度为43.80,而反问句作为一种高度依赖语境的句型,其所需的上下文信息更多,平均长度为48.8,高于非反问句的平均长度。显式反问句句子平均长度为49.39,隐式反问句句子平均长度为48.40。图2 显示的是在显式反问句中特征词的使用频率。“难道”一词的使用频率最高,由于其较强的反问特征,语言学家通常将其作为识别反问句的重要标记,在本文的构建的语料库中,“难道”在显式反问句中的占比达到20%,置信度为97.7%。“干嘛”类反问句也是比较典型的反问句,通过句末语气词“嘛”增强反诘句调,语料库中占比13%。
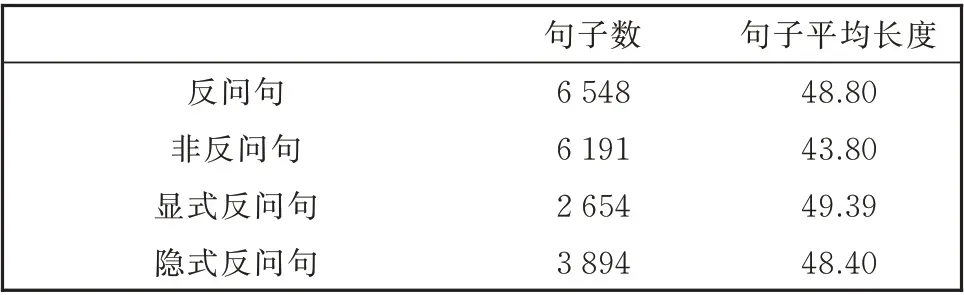
表5 语料库相关数据统计Table 5 Data statistics related to corpus
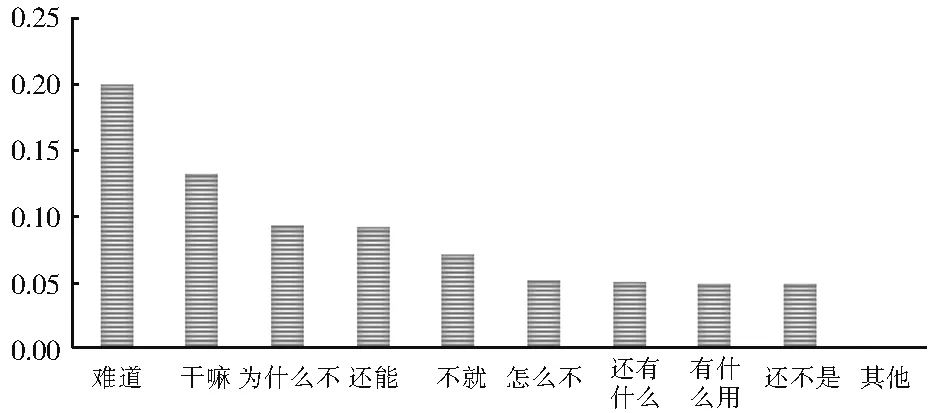
图2 显式反问句中特征词使用频率Fig. 2 Frequency of usage of characteristic words in explicit rhetorical questions
3 反问句识别
在反问句识别方面,语言学家给出了反问句的识解机制。文治等人[6]、李旸等人[8]利用人工标注的1 700 余条反问句,着眼于反问句标记、特定句式结构等方面设计了反问句识别模型。本文在构建的语料库的基础上,从句法关系角度对反问句进行分析,并利用多个神经网络模型进行反问句识别实验。
3.1 反问句特征研究
反问句特征词的作用在于能够影响周围词语甚至整个句子的反诘度。结合构建的语料库,本文发现特征词在句子的句首、句中、句末都可能出现。当句子较长时,特征词对相距较远的词语的影响并不能简单地通过距离的大小来判断。利用依存句法可以解决词与词之间长距离依赖关系[21]的特点,本文从句法关系角度考察句中词语与特征词的位置关系。
由于反问句是一种高度依赖语境的表达方式,本文还考虑了反问句特征词语的上下文环境。相对位置(relative position)在诸多的自然语言处理任务中都是一个很有用的特征[22],因此本文选取距离特征词最近的k个词语,并在依存句法树中抽取它们到特征词的句法路径作为句子的左、右句法路径特征。
结合第2 节表4 总结的反问句特征词,本文对句子考虑的特征表示包括句子语义特征、位置特征以及句法路径特征。图3 显示的是显式反问句、隐式反问句的句法路径、位置特征(k=1)。
(1)语义特征。假设句子S由n个词语组成,则S=(w1,w2,w3,…,wn),句 子 根 据 一 个 词 向 量 表M∈Rd0×V转化为句子的矩阵表示Xs∈Rd0×n,其中,d0表示词向量的维度,V表示词向量表的大小。矩阵表示Xs进入神经网络学习语义特征。
(2)位置特征。本文从依存句法树抽取句中每个词语到特征词的句法路径,将句法路径的长度作为句子的位置特征。在图3 的显式反问句中,词语“你”到特征词“难道”的句法路径为“你SBV 指望ADV 难道”,其句法路径长度为5,则反问句的位置特征可表示为D=[7,5,9,7,7,5,0,5,3,9,7,7,5,5]。句子的位置特征映射为矩阵Xpo∈Rdp×n,其中dp表示位置特征的维度。
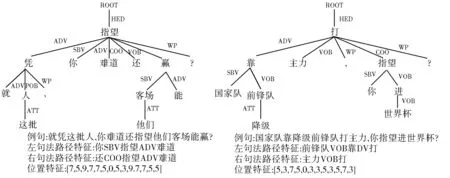
图3 句法路径特征与位置特征Fig. 3 Syntactic path characteristics and location characteristics
(3)句法路径特征。若当前句子为隐式反问句,将该句子依存关系中的核心动词作为特征词。本文将句法路径分为左、右句法路径:在依存句法树中,与特征词相对位置为[k,k-1,…,1]的词语到特征词的依存句法路径为左句法路径,与特征词相对位置为[-1,-2,…,-k]的词语到特征词的依存句法路径为右句法路径。在得到左、右两条句法路径之后,映射为矩阵表示Xlp∈Rdo×nl、Xrp∈Rdo×nr,并输入神经网络中学习句法路径特征。其中nl、nr为左、右句法路径的长度。
3.2 实验设置
本文的反问句实验数据来源于第3 节构建的反问句语料库,非反问句实验数据来源于构建语料库过程中的非反问句集合。所有数据均经过去噪、去重和分词等预处理操作,并使用LTP[23]进行词性标注和依存句法分析。实验过程中,本文将数据集的80%作为训练集,10%作为验证集,10%作为测试集,采用精确率(Precision)、召回率(Recall)和F1 值(F1-measure)作为实验结果的评价指标。为对比本文选取的反问句特征在不同模型上的性能,本文选取以下模型作为基准系统。
(1)卷积神经网络模型(CNN):模型利用卷积神经网络能够捕捉局部特征的特点,获取句子中具有代表性的局部特征。模型超参数设置:卷积核大小为3、4、5,数量为128,学习率为0.001。
(2)双向长短时记忆神经网络模型(BiL⁃STM):BiLSTM 网络捕获序列的历史信息和未来信息,更有助于学习序列的特征表示。模型超参数设置:隐藏单元维度为256,batch size 为50,学习率为0.001。
(3)Transformer 模 型[24]:将Transformer 在 反问句语料库上预训练后得到的序列特征直接通过全连接层输入到softmax 分类器中。模型超参数设置:隐藏状态维度为1 024,迭代次数为30,attention heads 为5,学习率为5×10-4。
(4)Bert 模 型[25]:Bert 使 用 多 层Transformer 结构,可以学习每个词语的前后信息,获得更好的词向量表示。模型超参数设置:batch size 为100,隐藏单元维度为768,学习率为5×10-5。
本文在依存句法树中抽取离特征词最近的k个词语到特征词的句法路径作为句子的句法路径特征,k值的大小决定了模型能够获取多少句子的上下文信息。本文利用BiLSTM 分析了不同k值对反问句识别实验的影响,如表6 所示,随着k值的增加,BiLSTM 对识别反问句的精确率不断降低。本文认为,结构化的句法路径特征可以为模型提供联系更为紧密的上下文信息,k值等于1 时,模型已经从依存句法路径中学习到足够的特征信息,k值大于1时,过多的特征信息反而会造成过拟合,因此,本文将超参数k设置为1。

表6 不同k 值对实验的影响Table 6 The influence of different k values on the experiment
3.3 实验结果与分析
本文获得实验结果如表7 所示,其中,Fs 表示语义特征,作为每个模型的基本特征;Fpo 表示位置特征;Fpa 表示句法路径特征;CNN[W+F]表示文治等人[6]设计的模型;Auto-AOA 表示李旸等人[8]设计的模型。

表7 各个模型的实验性能比较Table 7 Comparison of experimental performance of each model
实验结果表明:
(1)与文治等人[6]的模型相比,CNN 使用本文选取的反问句特征时的召回率、F1 值要略高于他们的模型。本文考虑到反问句是一种高度依赖语境的表达方式,从句法分析角度提取句子的位置特征,同时考察了的上下文环境,使得召回率提高4.2%,F1 值提高1.17%。与李旸等人[8]的模型相比,Bert 模型在使用本文构建的语料库时,性能略高于李旸等人[8]的模型。
(2)从神经网络模型上来看,Bert 无论是否使用了位置特征和句法路径特征,性能都要优于其他神经网络模型,展现出更强大的语义表示能力。在考虑位置特征与句法路径特征情况下,Bert 的F1 值可达到92.15%。
(3)从特征角度分析,模型考虑句法路径特征、位置特征时,模型在精确率、召回率和F1 值上均有提升。从召回率来看,CNN 提升4.39%,BiLSTM提 升0.63%,Tranformer 提 升4.54%,Bert 提 升1.41%。句法路径和位置特征提供了词语上下文信息,从而提高模型的性能。
(4)实验结果中Bert 模型的F1 值达到90%以上,这种结果可能是因为显式反问句作为带有明显反问句特征的反问句,本身即具有较高的辨识度,而本文通过反问句特征词来获取位置特征和句法路径特征,进一步提升了模型对显式反问句的识别性能。
4 结论
利用半监督学习和主动学习,本文提出了一个半自动的反问句语料收集方法。首先,本文构建了基于特征词典的反问句识别器来筛选数据中较有代表性的反问句,接着为进一步减少人工标注的工作量,提出未标注样本选择策略,训练了基于CNN、LSTM 的反问句主动学习器,并利用学习器对样本进行分类,最终语料库规模达到6 000 余句。结合反问句特点,本文利用反问句语料库,以句子的语义特征为基本特征,将位置特征、句法路径特征与其相融合共同作为句子表示,并输入至各个神经网络模型进行反问句识别。实验结果表明,本文建设的语料库在反问句识别方面的具有一定的应用价值。
在实验过程中,本文发现隐式反问句因其无明显特征,且高度依赖语境的特点而识别效果较差。在以后的工作中,本文将尝试设计针对隐式反问句的神经网络模型来提高对隐式反问句的识别能力,以进一步提升反问句识别系统的性能。
