DcNet: Dilated Convolutional Neural Networks for Side-Scan Sonar Image Semantic Segmentation
2021-08-30ZHAOXiaohongQINRixiaZHANGQileiYUFeiWANGQiandHEBo
ZHAO Xiaohong, QIN Rixia, ZHANG Qilei, YU Fei, WANG Qi, and HE Bo
DcNet: Dilated Convolutional Neural Networks for Side-Scan Sonar Image Semantic Segmentation
ZHAO Xiaohong, QIN Rixia, ZHANG Qilei, YU Fei, WANG Qi, and HE Bo*
,,266100,
In ocean explorations, side-scan sonar (SSS) plays a very important role and can quickly depict seabed topography. Assembling the SSS to an autonomous underwater vehicle (AUV) and performing semantic segmentation of an SSS image in real time can realize online submarine geomorphology or target recognition, which is conducive to submarine detection. However, because of the complexity of the marine environment, various noises in the ocean pollute the sonar image, which also encounters the intensity inhomogeneity problem. In this paper, we propose a novel neural network architecture named dilated convolutional neural network (DcNet) that can run in real time while addressing the above-mentioned issues and providing accurate semantic segmentation. The proposed architecture presents an encoder-decoder network to gradually reduce the spatial dimension of the input image and recover the details of the target, respectively. The core of our network is a novel block connection named DCblock, which mainly uses dilated convolution and depthwise separable convolution between the encoder and decoder to attain more context while still retaining high accuracy. Furthermore, our proposed method performs a super-resolution reconstruction to enlarge the dataset with high-quality images. We compared our network to other common semantic segmentation networks performed on an NVIDIA Jetson TX2 using our sonar image datasets. Experimental results show that while the inference speed of the proposed network significantly outperforms state-of-the-art architectures, the accuracy of our method is still comparable, which indicates its potential applications not only in AUVs equipped with SSS but also in marine exploration.
side-scan sonar (SSS); semantic segmentation; dilated convolutions; super-resolution
1 Introduction
Autonomous underwater vehicles (AUVs) are used in a number of marine missions. As a significant sensor equip- ped on AUVs, the role of side-scan sonar (SSS) is becoming increasingly important for many applications, including three-dimensional (3D) reconstruction (Coiras, 2007), seabed identification and classification (Lucieer, 2007), submarine survey (Li, 2006), and object localization (Johnson and Helferty, 2007). Therefore, the SSS image analysis can realize and improve the intelligence level of AUV environment perception and autonomous na- vigation behavior decision-making to promote theperfor- mance of AUVs in underwater operation tasks (Johnson and Deaett, 1994). Effective methods should be introduced for sonar image recognition and classification.
However, due to the particularity of the operating environment of underwater equipment and the imaging principle of the SSS itself, sonar images have the following problems: a) the resolution of the images is low; b) sonar images include various noises, such as ambient noise,reflection, and speckle noise; c) intensity inhomogeneity. Because of the above problems, feature extraction, sonar image recognition, and classification are difficult. Thus far, many methods have been proposed for SSS image seg- mentation, including active contour models, Markov random field (MRF) methods, and clustering segmentation method. Active contour models, including snake models and level-set models, have been used for sonar image seg- mentation (Linanatonakis and Petillot, 2005, 2007). However, the topology of the models is poor as they easily fall into local extremes and are sensitive to the initial contour. The methods based on the MRF (Mignotte., 2000) have some ideal research results about sonar image segmentation, but they have complicated calculations and low efficiency. Among the clustering segmentation algorithms, the fuzzy C-means (FCM) (Chuang,2006) algori- thm has been widely studied and applied. Due to the large amount of calculation in the FCM algorithm, the requi- rements of real-time image segmentation, such as SSS image analysis tasks, can hardly be met.
With the development of artificial neural network tech- nology, image segmentation algorithms based on convo- lutional neural networks, especially pixel-wise semanticsegmentation, have attracted considerable attention (Wang, 2018). Long(2015) proposed the fully convolutional network (FCN), replacing the fully connected layer with a convolutional layer, which was the earliest method to apply deep learning technology to image semantic segmentation. Since then, more semantic segmentation methods (Noh, 2015; Lin, 2016a; Paszke, 2016; Badrinarayanan, 2017; Lin, 2017) based on FCNs have been proposed. However, most segmentation network architectures are complicated and con- tain several parameters (Zhang, 2015; Lin, 2016b;Chaurasia and Culurciello, 2017; Pohlen, 2017; Chen, 2018), which are disadvantageous for real-time operations. For real-time semantic segmentation, ENet is a lightweight network that greatly improves efficiency withnotable sacrificed accuracy. Based on this lightweight net- work, ShuffleSeg (Gamal, 2018), LEDNet (Wang, 2019), and Light-Weight RefineNet (Nekrasov,2019) were proposed. However, the real-time perfor- mance of these methods cannot meet our hardware requi- rements. In this paper, we propose a novel segmentation method without several parameters for real SSS image seg- mentation.
In this paper, we propose an architecture that can segment sonar images in real time with high accuracy. Our network is based on an encoder-decoder structure, which is proposed by SegNet (Badrinarayanan, 2017). On the one hand, the encoder increases the receptive fields and reduces the resolution of the feature map through the pooling layer to extract the features of sonar images. On the other hand, the decoder uses deconvolution to reproduce the features after image classification and uses the upsampling layer to restore the original size of the image. One of the novelties of our network is the usage of dilated convolutional connections between the encoder and decoder. Moreover, compared with other network layers, our structure has fewer layers and parameters owing to the use of the dilated convolutional connections to get more context. Thus, the network can achieve real-time process- ing without affecting the accuracy. In particular, we use su- per-resolution reconstruction to enlarge datasets with high- quality images.
2 Network Architecture
In this section, we will introduce our novel neural network architecture named dilated convolutional neural net- work (DcNet) with the block connection named DCblock in detail. The architecture of DcNet is divided into three parts (Fig.1): the encoding module is for feature extraction, the decoding module is for upsampling features, and the DCblock makes a connection with the encoder and decoder to increase the spatial information of the decoder.
2.1 DCblock
We focus on making connections between the corresponding encoder and decoder. The structure of the DC- block is illustrated in Fig.1. To capture a sufficient receptive field, a few methods have been proposed (Chen, 2017a, b; Zhao, 2017), such as dilated convolution and pyramid pooling modules. These methods significantly im- prove the spatial information and receptive field. During the downsampling process of the encoder, some spatial information of the image will be lost. However, if the output of the encoder is directly used as the input of the de- coder, then the amount of calculation will be significantly increased. Therefore, we use a dilated convolution with a dilation rate of two. Through this method, we aim at recovering the information lost by the encoder. Compared with the standard convolution operation, dilated convolution can expand receptive fields and capture multi-scale context information without loss of resolution or coverage. Letbe the initial kernel size andbe the dilated convolution rate, and consider the actual dilated convolution kernel size:

Thus, the standard convolution is a special form of dilated convolution when1. In our DCblock, we expand- ed the receptive fields to obtain more context through this method. Then, we added an average pooling after the dilated convolution, which can provide a more receptive field.
2.2 Encoder Module
The details of the encoder module are presented in Fig.2.Here Conv/DWConv means convolution or depthwise (DW)separable convolution. DW convolution and pointwise con- volution are collectively called DW separable convolution (Chollet, 2017). This structure is similar to conventional convolution operations and can be used to extract features, but compared to conventional convolution operations, its parameter quantity and operation cost are lower, so our network adopts this method. We used a 3×3 receptive field, which is the smallest batch, to obtain the notion of right/ left, down/up, and center (Simonyan and Zisserman, 2014). Batch normalization (Ioffe and Szegedy, 2015) that is followed by a rectified linear unit (Nair and Hinton, 2010) is used between convolutional layers. Max pooling denotes that the max-pooling operation with a 2×2 window and stride 2 is used to implement translation invariance in the input image for downsampling, and the indices are passed to the corresponding decoder. By using the max-pooling operation, there is no need for a deconvolution operation, whichreduces the number of parameters and speeds up the training. Inspired by SegNet, the first two encoders have two layers of convolution, and the last two encoders have convolution layers, as shown in the dotted box in Fig.2.
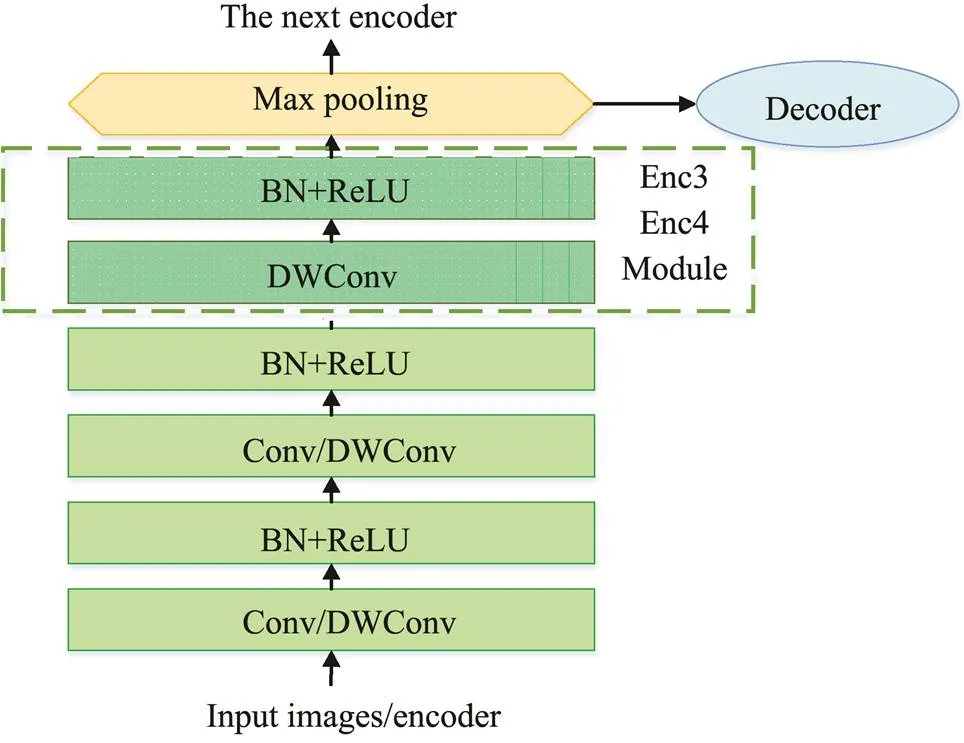
Fig.2 Encoder module.
2.3 Decoder Module
Similar to Fig.2, Conv/DWConv means convolution or DW separable convolution. The decoder in the segmentation network is to upsample the input image resolution. Most recent semantic segmentation networks have identical encoder networks,, VGG16, but have different de- coder networks that play a key role in the performance of the model. For instance, the SegNet decoding network stores the indices of the max locations computed during max pooling and passes them to the corresponding decoder. Compared with SegNet, U-Net (Ronneberger, 2015) transmits the entire feature map (cost of more me- mory) to the corresponding decoder and connects them for upsampling. In LinkNet, the outputs of the encoder are directly added to the decoder. In this way, the accuracy significantly improves in the processing time, and information lost in the encoding network decreases.
In our network, the decoding network uses max-pooling indices inspired by SegNet while directly using the DC- block instead of the connection between the encoder and decoder. The details of the encoder and decoder are summarized in Table 1.

Fig.3 Decoder module.

Table 1 Convolutional methods in each stage
Note: 3 × 3 is the kernel size of the convolution layer.
3 Experiment
We experimentally compared popular semantic segmentation networks to verify the effectiveness of our method. The segmentation experiment operation of the SSS image is shown in Fig.4. Section 3.1 describes the operations to obtain the SSS image, which can be directly used to make the dataset. Section 3.2 provides details on the super- resolution reconstruction and the training and testing of the dataset. The details of the implementation and expe- rimental parameters are presented in Section 3.3.
3.1 Preprocessing of SSS Images
We evaluated the network on two different datasets, name- ly, the seabed reef dataset obtained from Nanjiang Pier and the sand wave dataset from Tudandao Pier in Qingdao. SSS data were acquired by an AUV equipped with SSS. The experimentalAUV and experimental scene are shown in Figs.5 and 6, respectively.
The SSS we used is a dual-frequency SSS. The sonar images used in our dataset were parsed from the XTF file of the SSS. Each time the SSS transmits and receives a sound wave. It is a ping data in the XTF file, and the magnitude of the value is the echo intensity. Each ping was parsed and stitched to obtain the pixel values of the grayscale image. The initial parsed picture is shown in Fig.7. To obtain the needed data, we interpolated the original so- nar data and removed the water column without data information. The processed image is provided in Fig.8.

Fig.4 Experimental operation of the SSS image semantic segmentation.

Fig.5 Sailfish AUV equipped with SSS.

Fig.6 Sailfish AUV in the sea trial.

Fig.7 Raw sonar image.
Fig.8 Processed sonar image.
3.2 Super-Resolution Reconstruction and Datasets
The tool we use for labeling the ground truth and target of the SSS image is LabelMe, which is an open access annotation tool developed by the Massachusetts Institute of Technology. The number of pixels of the image input to the network must be appropriate to ensure the computing efficiency of the network, so we cropped the sonar image (shown in Fig.9) and the corresponding label (shown in Fig.10) into an image of 500×500 size with a stride of 100 pixels. To verify that our network is effective for sonar images obtained in different environments, the data were obtained from two locations. The two datasets consist of 12486 images, out of which 11424 were used for train- ing and the remaining 1062 were used for testing.
In Fig.9, the sonar image has strong noise, and the ob- ject feature is not clear. Because low-pixel pictures have a great impact on image segmentation, we use the super- resolution reconstruction method based on the super-re- construction convolutional neural network (SRCNN) (Dong, 2015) to enhance image quality. Compared with other state-of-the-art methods, SRCNN has an uncomplicated structure, but it provides superior accuracy. The no- velty of the SRCNN is the usage of the FCN and learning an end-to-end mapping between low- and high-resolution images. Moreover, it needs little preprocessing beyond the optimization. The sonar image after super-resolution reconstruction is shown in Fig.11. In this way, our network can precisely extract features of images, thus improving the accuracy of the segmentation.

Fig.9 Sonar image.

Fig.10 Corresponding label.
3.3 Experimental Setup
We used PyTorch, which is an open-source Python ma- chine learning framework, for training. Our models were trained on NVIDIA Quadra M5000. Moreover, to verify that our model can be used for real-time processing of AUV underwater tasks, we tested the trained model on an NVIDIA Jetson TX2, which is an embedded platform. To get optimum performance, we used a mini-batch Adam optimization algorithm with a batch size of 15, learning rate of 1e-3, and weight decay of 1e-4 in the training. Then, we retained the model with the highest accuracy in the test set during the training process.

Fig.11 Comparison of the original picture and sonar image after the super-resolution reconstruction. (a) and (c) are the initial images; (b) and (d) are the corresponding results after the super-resolution reconstruction.
4 Results and Analysis
4.1 Accuracy Analysis
The metrics we used to evaluate the network performance are the pixel accuracy (PA), mean pixel accuracy (MPA), mean intersection over union (mIoU), and frequency-weighted intersection over union (FWIoU). We also compared our network with other models, such as SegNet and ENet. Tables 2 and 3 display the results of our architecture and the other model on the sonar image datasets, where the segmentation accuracy was improved from 67.98% to 69.03% and from 66.93% to 67.50%, which proves the effectiveness of the DCblock module. We note that, for the sand wave sonar images, our network yielded an mIoU of 69.03%, which can closely ma- tch the performance of the state-of-the-art methods. For the seabed reef sonar images, our DcNet achieved higher accuracy against the other methods.

Table 2 Comparison on the sand wave test set
Note: The best results are in bold.
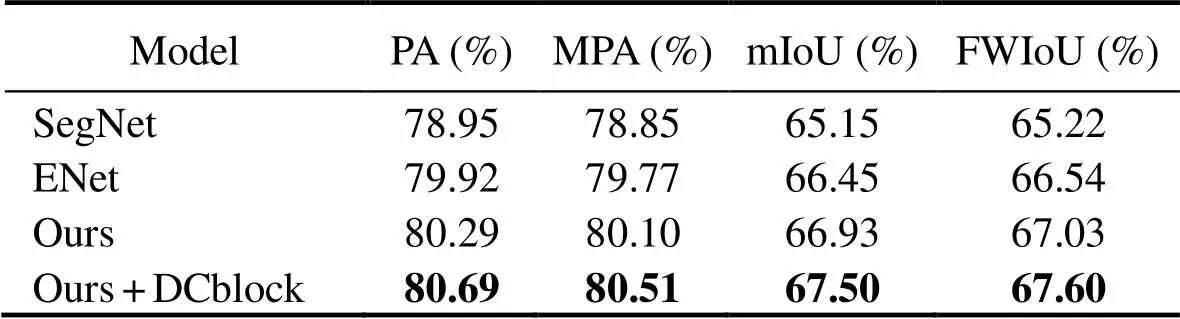
Table 3 Comparison on the seabed reef test set
Note: The best results are in bold.
Meanwhile, by adding the DCblock, the accuracy of our network was significantly improved. The prediction accuracy of the sand wave dataset is generally high because the sand wave features are more evident than the seabed reef features, so the manual labeling was more accurate. Fig.12 shows the semantic segmentation results of the DcNet. Generally, even if the noise of the SSS image is strong, the segmentation results of the sand waves and seabed reefs are ideal.

Fig.12 Examples of segmentation produced by our network. The first row is the initial input image (the first two images are from the sand wave test set, and the latter two are from the seabed reef test set); the second row corresponds to the ground truth of the first column; the third row contains the segmentations predicted by our network without the DCblock; and the last is the segmentation tasks with the DCblock.
4.2 Speed Analysis
Speed is an essential factor when we apply the network in an embedded platform. Table 4 reports a comparison of the number of parameters and giga floating-point operations per second (GFLOPs) used by different networks. Table 5 presents the inference time of the high-resolution sonar images on NVIDIA Jetson TX2. The symbol ‘−’ indicates that the network is not able to test on the embed on 500×500-resolution sonar images using NVIDIA Jetson TX2. Compared with other methods, our architecture has fewer parameters without a clear decrease in the model performance and thus can be applied in embedded platform operations.

Table 4 Accuracy and parameter analysis of our method and other state-of-the-art methods. FLOPs are estimated for input of 3×500×500

Table 5 Speed comparison of our model and other methods on NVIDIA Jetson TX2
4.3 Speed and Accuracy Comparisons
In the field of deep learning image segmentation, the mIoU value is an important indicator to measure the accuracy of image segmentation. mIoU can be interpreted as the average cross-union ratio, and the IoU value is calculated on each category (true sample number/(real sample number+false negative sample number+false positive sam-ple number)), so we used mIoU as the main segmentation accuracy standard.The speed and accuracy comparison is presented in Fig.13. While SegNet obtains high accuracy in the sand wave test set, the inference time speed in SegNet is too low, and thus it cannot be performed in an embedded platform. Compared with ENet, the inference speed in our network is good in the sand wave and seabed reef test sets, and the accuracy is comparable to that of ENet.

Fig.13 Inference speed and accuracy performance on the (a) sand wave and (b) seabed reef test sets.
In the actual experiment, after the AUV main control unit used the command to open the SSS, the embedded GPU received five pings of data per second, corresponding to the five lines of pixels in the picture, and the GPU processed the data every 3s and sent the results back to the master control unit to perform the path planning. The time to preprocess the image is approximately 0.5s, so the time to split the image is approximately 4s. When the SSS range is set to 120m, each ping has 9600 pixels. After cropping the 500×500 image for processing, almost 20 images needed to be processed, and the time for each image is 0.2s. Hence, after the network processes the images, there will be sufficient time for other operations, thus im- proving the efficiency.
5 Conclusions
In this study, we introduce a semantic segmentation net-work of SSS images through DcNet, based on the encoder- decoder module. By using the DCblock between the encoder and decoder, the network increases the receptive field and gains more context. Thus, it achieves better per- formance in SSS image segmentation, and its inference can be performed in real time. In addition, super-resolu- tion reconstruction can improve the accuracy of the segmentation tasks. The experimental results show that, in contrast to the state-of-the-art approaches, our network per- forms better in the trade-off between effectiveness and efficiency. The findings also show that AUVs can use this network in real-time online sonar image recognition to achieve intelligent path planning. Moreover, the accuracy can be further improved if a better super-resolution recon- struction method is adopted.
Acknowledgement
This work is partially supported by the Natural Key Re- search and Development Program of China (No. 2016YF C0301400).
Badrinarayanan, V., Kendall, A., and Cipolla, R., 2017. Segnet: A deep convolutional encoder-decoder architecture for image segmentation., 39 (12): 2481-2495, DOI: 10.1109/tpami. 2016.2644615.
Chaurasia, A., and Culurciello, E., 2017. Linknet: Exploiting en- coder representations for efficient semantic segmentation..St. Petersburg, 1-4, DOI: 10.1109/vcip.2017.8305148.
Chen, L. C., Papandreou, G., Kokkinos, I., Murphy, K., and Yuille, A. L., 2017a. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs., 40 (4): 834-848, DOI: 10.1109/tpami. 2017.2699184.
Chen, L. C., Papandreou, G., Schroff, F., and Adam, H., 2017b. Rethinking atrous convolution for semantic image segmentation., arXiv: 1706. 05587.
Chollet, F., 2017. Xception: Deep learning with depthwise separable convolutions.Honolulu, 1251- 1258.
Chuang, K. S., Tzeng, H. L., Chen, S., Wu, J., and Chen, T. J, 2006. Fuzzy c-means clustering with spatial information for image segmentation., 30 (1): 9-15.
Coiras, E., Petillot, Y., and Lane, D. M., 2007. Multiresolution 3-D reconstruction from side-scan sonar images., 16 (2): 382-390, DOI: 10.1109/ tip.2006.888337.
Dong, C., Loy, C. C., He, K., and Tang, X., 2015. Image super- resolution using deep convolutional networks., 38 (2): 295-307.
Gamal, M., Siam, M., and Abdel-Razek, M., 2018. Shuffleseg: Real-time semantic segmentation network.,arXiv: 1803.03816
Ioffe, S., and Szegedy, C., 2015. Batch normalization: Accelerating deep network training by reducing internal covariate shift.,arXiv: 1502.03167.
Johnson, H. P., and Helferty, M., 1990. The geological interpretation of side-scan sonar., 28 (4): 357- 380, DOI: 10.1029/rg028i004p00357.16.
Johnson, S. G., and Deaett, M. A., 1994. The application of au- tomated recognition techniques to side-scan sonar imagery., 19 (1): 138-144, DOI: 10.11 09/48.289460.
Li, A. L., Cao, L. H., Li, G. X., and Yang, R. M., 2006. Application of side-scan sonar to submarine survey and vessel dynamic positioning technique.,36 (2): 331-335 (in Chinese with English abstract).
Lianantonakis, M., and Petillot, Y. R., 2005. Sidescan sonar seg- mentation using active contours and level set methods. In:. Brest, 719-724, DOI: 10.1109/oceanse. 2005.1511803.
Lianantonakis, M., and Petillot, Y. R., 2007. Sidescan sonar seg- mentation using texture descriptors and active contours., 32 (3): 744-752, DOI: 10. 1109/joe.2007.893683.
Lin, D., Dai, J., Jia, J., He, K., and Sun, J., 2016a. Scribblesup: Scribble-supervised convolutional networks for semantic seg- mentation.. Las Vegas, 3159-3167, DOI: 10.1109/cvpr.2016.344.
Lin, G., Milan, A., Shen, C., and Reid, I., 2017. Refinenet: Mul- ti-path refinement networks for high-resolution semantic seg- mentation.. Honolulu, 1925-1934, DOI: 10.1109/cvpr.2017.549.
Lin, G., Shen, C., Van Den Hengel, A., and Reid, I., 2016b. Efficient piecewise training of deep structured models for semantic segmentation..Las Vegas, 3194-3203, DOI: 10.1109/cvpr.2016.348.
Long, J., Shelhamer, E., and Darrell, T., 2015. Fully convolutional networks for semantic segmentation.. Boston, 3431-3440.
Lucieer, V. L., 2007. Object-oriented classification of sidescan sonar data for mapping benthic marine habitats., 29 (3): 905-921, DOI: 10.1080/01 431160701311309.
Mignotte, M., Collet, C., Perez, P., and Bouthemy, P., 2000. Sonar image segmentation using an unsupervised hierarchical MRF model., 9 (7): 1216- 1231, DOI: 10.1109/83.847834.
Nair, V., and Hinton, G. E., 2010. Rectified linear units improve restricted boltzmann machines.Haifa, 1-8.
Nekrasov, V., Shen, C., and Reid, I., 2018. Light-weight refinenet for real-time semantic segmentation.,arXiv: 1810.03272
Noh, H., Hong, S., and Han, B., 2015. Learning deconvolution network for semantic segmentation.. Santiago, 1520- 1528, DOI: 10.1109/iccv.2015.178.
Paszke, A., Chaurasia, A., Kim, S., and Culurciello, E., 2016. Enet:A deep neural network architecture for real-time semantic seg- mentation.,arXiv: 1 606.02147.
Pohlen, T., Hermans, A., Mathias, M., and Leibe, B., 2017. Full- resolution residual networks for semantic segmentation in street scenes.Honolulu, 4151-4160.
Ronneberger, O., Fischer, P., and Brox, T., 2015. U-net: Convolutional networks for biomedical image segmentation. In:. Navab, N.,., eds., Springer, Munich, 234- 241, DOI: 10.1007/978-3-319-24574-4_28.
Simonyan, K., and Zisserman, A., 2014. Very deep convolutional networks for large-scale image recognition., arXiv: 1409.1556.
Wang, P., Chen, P., Yuan, Y., Liu, D., Huang, Z., Hou, X.,., 2018. Understanding convolution for semantic segmentation.. Lake Tahoe, 1451-1460, DOI: 10.1109/wacv.20 18.00163.
Wang, Y., Zhou, Q., Liu, J., Xiong, J., Gao, G., Wu, X.,., 2019. Lednet: A lightweight encoder-decoder network for real- time semantic segmentation.). Taipei, 1860-1864.
Zhang, W., Li, R., Deng, H., Wang, L., Lin, W., Ji, S.,., 2015.Deep convolutional neural networks for multi-modality isointense infant brain image segmentation.,108: 214- 224, DOI: 10.1016/j.neuroimage.2014.12.061.
Zhao, H., Shi, J., Qi, X., Wang, X., and Jia, J., 2017. Pyramid scene parsing network..Honolulu, 2881- 2890, DOI: 10.1109/cvpr.2017.660.
. Tel: 0086-532-66782339 E-mail: bhe@ouc.edu.cn
July 14, 2020;
September 16, 2020;
September 23, 2020
© Ocean University of China, Science Press and Springer-Verlag GmbH Germany 2021
(Edited by Chen Wenwen)
杂志排行

Journal of Ocean University of China的其它文章
- Numerical Modelling for Dynamic Instability Process of Submarine Soft Clay Slopes Under Seismic Loading
- Bleaching with the Mixed Adsorbents of Activated Earth and Activated Alumina to Reduce Color and Oxidation Products of Anchovy Oil
- The Brown Algae Saccharina japonica and Sargassum horneri Exhibit Species-Specific Responses to Synergistic Stress of Ocean Acidification and Eutrophication
- Effects of Dietary Protein and Lipid Levels on Growth Performance, Muscle Composition, Immunity Index and Biochemical Index of the Greenfin Horse-Faced Filefish (Thamnaconus septentrionalis) Juvenile
- Transcriptome Analysis Provides New Insights into Host Response to Hepatopancreatic Necrosis Disease in the Black Tiger Shrimp Penaeus monodon
- Genome-Wide Patterns of Codon Usage in the Pacific Oyster Genome