一种基于多任务学习的语音关键词检测与定位方法研究*
2021-08-30王金明张宏瑜
孙 渊,王金明,汪 鹏,张宏瑜
(陆军工程大学,江苏 南京 210001)
0 引言
语音流中关键词实时检测也被称为关键词检测或唤醒词检测技术,是语音识别任务中的一个分支。该技术需要从一串语音流里检测出有限个预先被定义的激活词或关键词,而不需要对整个语音流进行识别。传统的按键或鼠标输入在一定程度上限制了使用者的体验,随着人工智能的快速发展,语音交互技术成为解放使用者双手的重要技术。语音流中的关键词检测作为语音交互的基础,使用者通过预先定义的关键词来唤醒目标设备,进而发出指令实现交互。设备从唤醒到交互的过程中,使用者可以获得完全免提的体验。该技术广泛应用于智能手机、个人电脑、智能音响、智能家居和车载设备等虚拟助手中。
大词汇量语音识别系统(Large Vocabulary Continuous Speech Recognition,LVCSR)是唤醒设备的一种方法。该系统对接收到的语音信号进行解码,并在产生的解码词格中搜索预先定义的关键词从而实现设备的唤醒[1]。但LVCSR 解码需要占用较高的计算资源,并且该系统的模型庞大,用户使用过程中无可避免地会遇到时延的问题,致使LVCSR 无法部署在计算资源受限的设备端。
近年来,小规模的语音关键词检测越来越受到关注[2-5]。这是因为在低计算资源、低功耗、低延迟、长待机的嵌入式设备要求框架下,语音关键词检测系统需要在设备上持续运行,监听一定范围内所有语音流,并忽略与关键词无关的音频,在检测到关键词时立即使设备进入工作状态[6]。这样的关键词检测系统被设计成高召回率、低虚警率,以使用户获得良好体验的同时一定程度上解决用户隐私问题。
传统语音关键词检测通常使用隐马尔可夫(Hidden Markov Model,HMM)模型分别对关键词和非关键词进行建模[7]。在解码时,使用维特比算法在解码图中搜索最佳路径,当关键词模型和非关键词模型的似然比大于某个阈值时,设备将被触发。传统上一般使用高斯混合模型(Guassian Mixed Model,GMM)对语音特征观测状态进行建模,随着深度学习的长足发展,深度神经网络已经替代了高斯混合模型。Chen[8]等人使用深度神经网络(Deep Neural Network,DNN)网络对关键字及其子词直接进行置信度判断,不仅提升了系统性能,还避免了复杂的解码环节,大大减少了系统延迟。Ming[9]等人使用时延神经网络在初始层对语音特征进行精确建模,在较高层对上下文信息进行广泛建模,再使用降维技术减少模型参数,该方法在性能和系统延迟上都获得了较大提升。
实践中发现,在工程应用中语音关键词触发的具体定位能给下游模块提供有价值的信息,由此本文提出采用一种多任务学习机制,检测关键词的同时对语音关键词进行帧级别的定位。此外,本文还在关键词数量上进行了拓展,实现了多个关键词的并行检测。
1 语音关键词检测与定位模型结构
1.1 数据结构
本文定义了两个语音关键词,分别为“Hi XiaoWen”“Nihao Wenwen”,对应的两个标签分别是1、2;负样本记为“Freetext”,对应标签为0。由于本文在检测语音关键词的基础上拓展了对语音关键词在帧级别上的精确定位,因此对于训练数据i除正负样本标签之外,还需对每个样本进行帧级别的音素对齐,得到定位标签。其中:;s为语音关键词的起始帧;e为语音关键词的结束帧;对于不含语音关键词的负样本。令s=-1,e=-1。
1.2 模型结构
如图1 所示,整个模型结构包含4 个部分D0、M0、D3、D4,分别对应特征提取器模块、区域提案网络(Region Proposal Network,RPN)、语音关键词检测或分类模块、语音关键词定位模块。
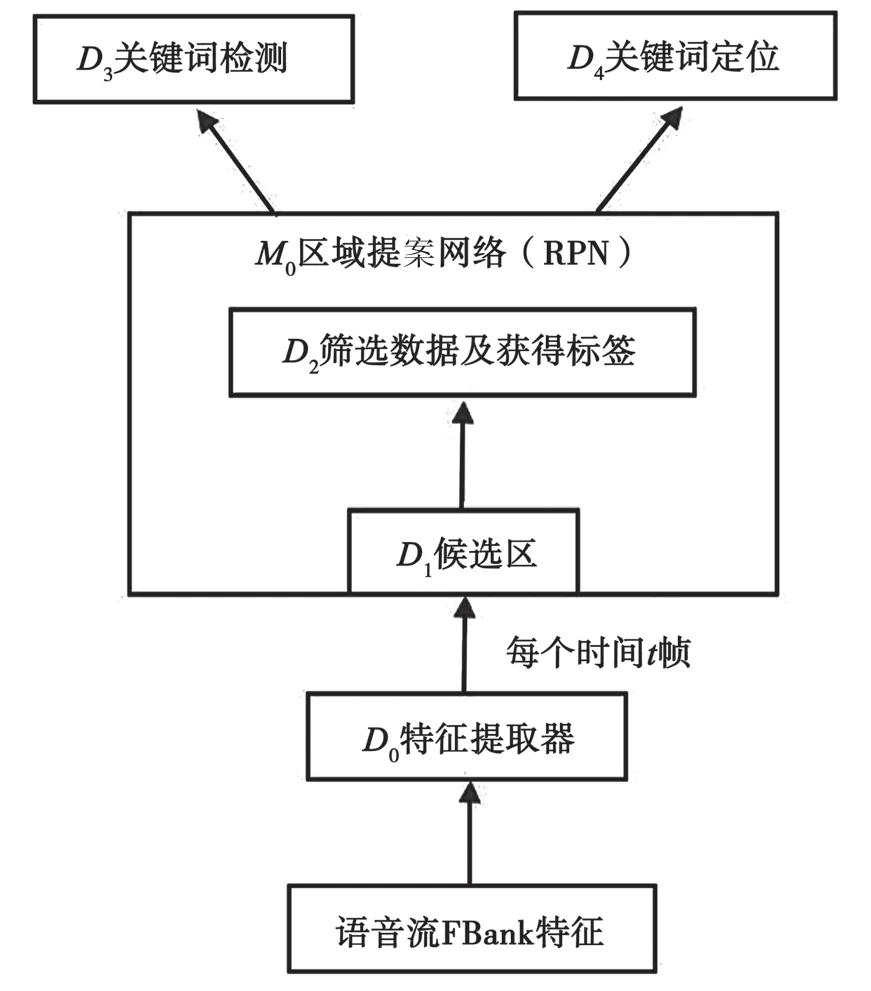
图1 语音关键词检测与定位模型结构
(1)D0特征提取器。此模块用于将语音FBank特征输入流X(X1,X2,X3,…,XT)编码成一个更高层次的特征表示h(h1,h2,h3,…,hT),编码方式为:

式中:θ1为模型参数。本实验D0模块使用两层门控循环单元(Gate Recurrent Unit,GRU)网络[10]对特征X进行高维提取,每层GRU 网络结点数为128,线性投影层结点数也为128,并使用ReLU 作为激活函数。
(2)M0区域提案网络。此模块采用区域提案网络来对语音关键词进行识别与定位[11-12]。它主要包含两个部分,分别为生成候选区域(Region of Interest,RoI)的D1模块和对候选区进行标签与筛选的D2模块。
①D1生成候选区RoI。对每个时间t帧,令t为候选区的右边界即结束点,向前随机生成K个区域,K个区域的平均帧长度应不小于关键词的统计帧长。
②D2对RoI 进行筛选与定位。在每个时间t帧,由D1生成K个区域。不妨假设:正样本A的起始点为s,终止点为e,即A(s,e);区域R(p,q)为生成的K个区域中的1 个;A∩R表示区域A与R重叠的部分;|A|=e-s表示区域A的帧数。当,认为该区域为候选区域且为非关键词样本,记标签为0,(p,q);当时,也为候选区域且为关键词样本,记标签为1 或2,(p,q);当时,记为非候选区域,并舍弃此类区域。在t帧经过筛选后生成的候选区个数记为Nt。
(3)D3关键词检测模块。在每个时间t帧,输出Nt个区域对应于关键词的帧级后验概率序列,由于本实验定义了两个关键词1、2,对应的∈R3:

式中:θ2为模型参数。
(4)D4关键词定位模块。该模块主要用于将经过筛选的候选区域RoI 变换成正样本A的实际区域:

式中:θ3为模型参数;表示RoI 区域的变换向量;=(φ,μ);φ表示缩放因子;μ表示中心点位移。
2 实 验
2.1 语 料
实验数据使用一个从商业智能扬声器收集到的唤醒词语料库,称为Mobvoihotwords,关键词语音段包含“Hi XiaoWen”和“Nihao Wenwen”。每个关键词大约有30 000 条数据,所有的关键词语音数据来源于年龄3~65 岁的共788 个研究对象。分别是从距离扬声器不同的距离处(1 m,3 m,5 m),以及从不同方向说出的预先定义的关键词的语音数据。有大约220 h 的非关键词语音段作为负样本加入唤醒词数据库。本实验采取6:1:3 的随机划分方式将整个数据集分为训练集、开发集、测试集。划分后的各数据集成分见表1。
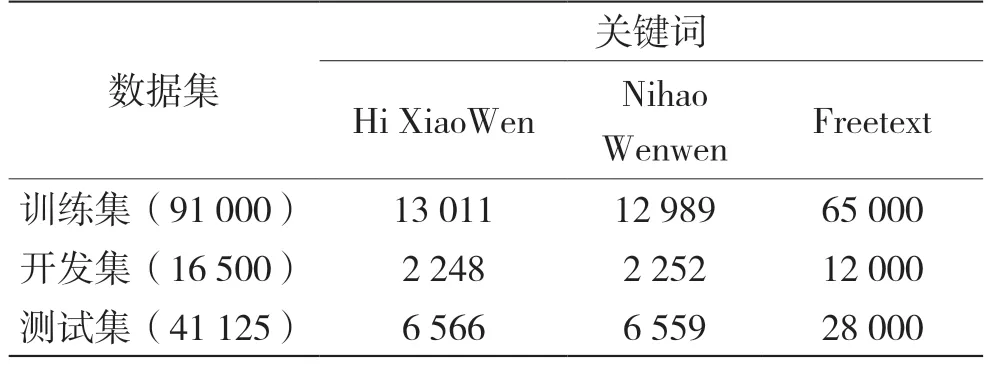
表1 数据成分表
2.2 实验设置
2.2.1 数据预处理
本节主要获取每个训练数据的定位标签(s,e)。首先,选取数据量合适的任意语料,本实验采用Mobvoihotwords 语料;其次,由于本实验预先定义的语音关键词中协同发音的现象基本不存在,基于高效化的考虑,训练了一个单音素的高斯混合-隐马尔可夫模型(GMM-HMM),其中GMM 用于对语音观测状态序列建模,HMM 用于建模音素间的转移概率;最后,将得到的模型采用维特比算法对正样本训练数据进行解码对齐,得到关键词语音帧的起始点s,终止点e。
2.2.2 语音特征
本实验将40 维的滤波器组特征(FliterBank)进行倒谱均值方差归一化(Cepstrum Mean Variance Normalization,CMVN)压缩特征参数值域的动态范围,然后将归一化后的特征作为输入X(X1,X2,X3,…,XT)送进神经网络特征提取器D0,帧长设置为25 ms,帧移设置为10 ms。
2.2.3 损失计算
模型的损失Loss由分类损失Lc和定位损失Lp两部分组成。

式中:Lc采用交叉熵计算分类损失;Lp采用均方误差计算定位误差;λ表示多任务学习在该系统中的比重。
通过改变λ的值来权衡多任务学习对系统性能的影响,其中:
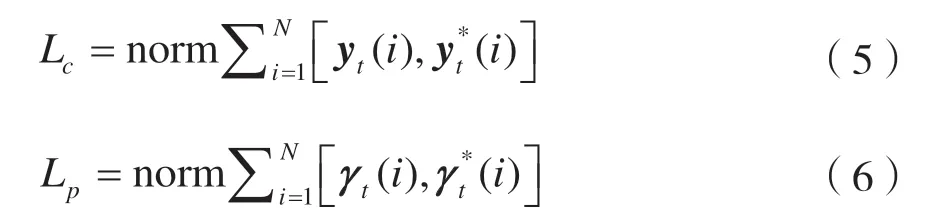
式中:M、N对应模块相应训练数据量。
2.3 基线系统
本文将不带定位子网络D3的模型作为基线系统(λ=0),以评估多任务学习对语音关键词识别的影响,并与文献[9]中的深度语音关键词检测(Deep-Keywords Spotting,Deep-KWS)系统对比。
3 实验结果分析
随机挑选一段正样本语音并进行定位,结果如图2 所示。其中虚线方框区域是用单因素GMM 模型强制对齐得到的帧级别真实标注,实线方框区域是本实验的预测结果。可以看出本实验得到的关键词语音段与真实语音段大部分重合,在语音初始段和结束段存在少量误差。
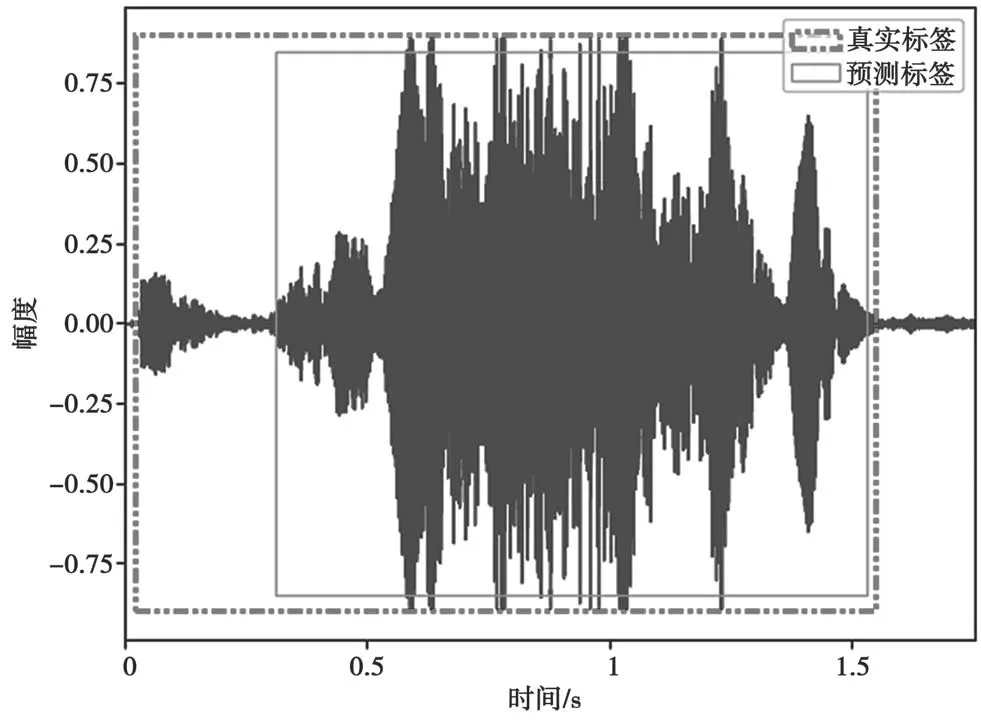
图2 “Nihao Wenwen”语音关键词定位
图3和图4分别展示了以“Hi XiaoWen”和“Nihao Wenwen”为语音关键词的检测错误权衡图(Detection Error Tradeoff,DET)曲线。由于曲线下面积越小表示性能越好,则λ=0.3 的结果明显优于λ=0,说明多任务学习确实对该系统起积极作用。此外,当限制虚警率为1 次/h 时,性能有6%~10%的相对提升。从图中还可以看出“Nihao Wenwen”的DET曲线性能略好于“Hi XiaoWen”,说明4 音节词语的识别率要比3 音节词语的识别率高,也就是说语音关键词的识别率在一定程度上正比于关键词的音节数量。相比于选择LVCSR 作为辅助任务联合优化模型[9]在应用时抛弃辅助模块以换取高性能,本文使用的辅助任务在训练阶段没有引入较大的复杂流程,且在训练完成后,可作为辅助模块投入应用。
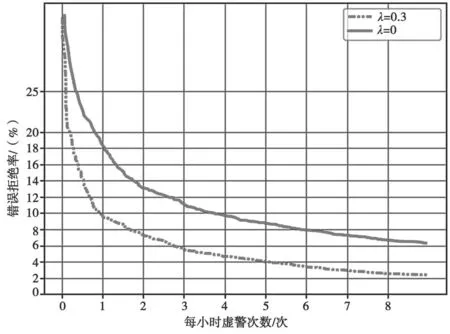
图3 “Hi Xiaowen”的DET 曲线
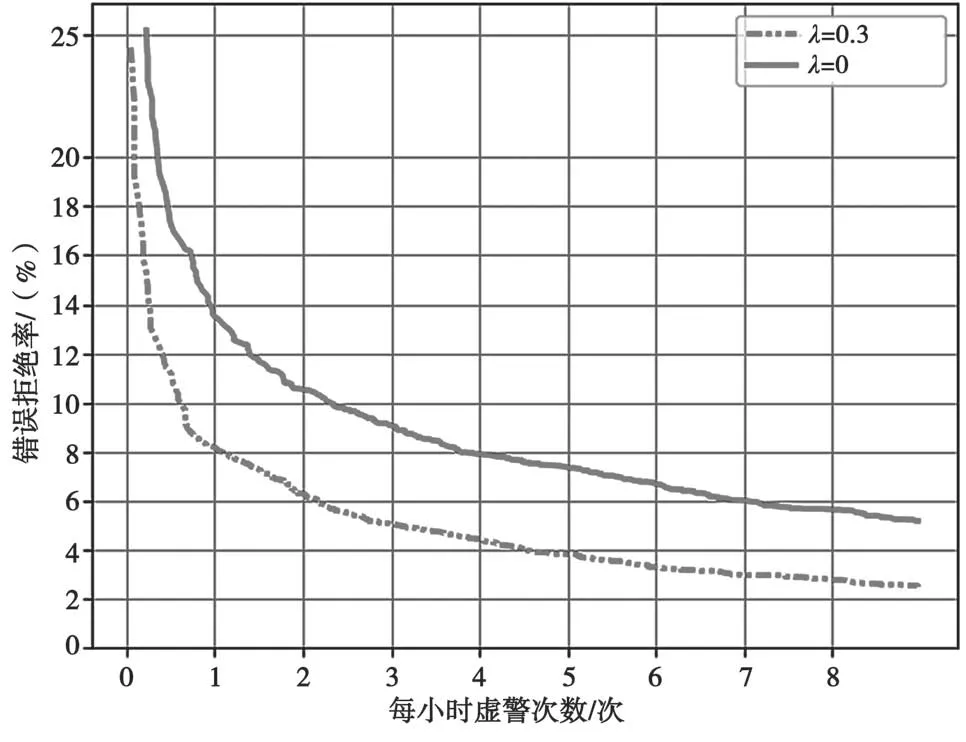
图4 “Nihao Wenwen”的DET 曲线
图5 对比了Deep-KWS 基线系统和本实验系统的DET 曲线性能,基于RPN 的多任务学习系统性能明显优于基线系统,当每小时虚警次数较低时,系统性能相对提升了至少15%。
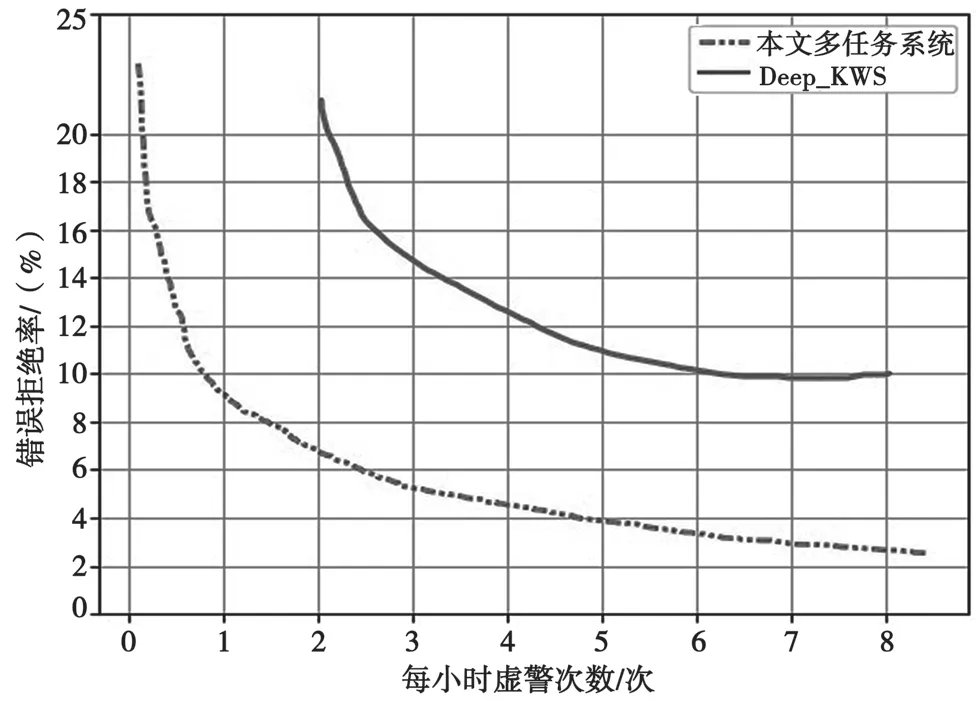
图5 Deep-KWS 和本文多任务系统的DET 曲线
4 结语
本文提出采用一种多任务学习机制,将语音关键词的定位作为辅助任务,联合优化语音关键词检测系统。利用RPN 网络生成语音关键词候选区域,进而对这些区域进行分类,同时拟合语音关键词的起始帧与结束帧,完成定位功能。本实验提出的模型对比Deep-KWS 系统,在每小时低误唤醒的条件下,性能相对提升15%。本实验还验证了添加适当的辅助任务对系统进行多任务联合优化可以提高模型的泛化能力。
