深度聚类算法综述*
2021-08-30邓祥,俞璐
邓 祥,俞 璐
(陆军工程大学,江苏 南京 210007)
0 引言
聚类目标是把相似的数据点划分到同一个簇中,根据不同的聚类方式导出不同的聚类算法。根据聚类方式的不同,经典聚类方法[1-9]将典型聚类算法分为原型聚类、密度聚类、图聚类以及层次聚类等。原型聚类用一组原型刻画聚类簇结构,通过度量样本与原型之间的距离确定样本归属。密度聚类的主要目标是寻找被低密度区域分割的高密度区域。图聚类算法通过构建一个基于相似度的无向加权图把聚类问题转化为图的最优划分问题。层次聚类通过度量数据节点之间的相似性或者距离构建一个树形结构,在不同层面上对数据集进行划分。研究这些经典的传统聚类算法[10]可以发现,进行特征提取的聚类算法效果要明显优于没有进行特征提取的聚类算法。因此,研究人员开发了大量特征处理算法,包括线性的主成分分析(Principal Component Analysis,PCA)[11]和非线性的核方法[12]等。最近的研究表明,联合优化特征处理与聚类目标可以获得更好的结果。这方面深度学习强大的非线性拟合能力和特征表示能力可以很好地连接特征处理与聚类目标。本文将深度学习引入无监督聚类领域形成的模型统称为深度聚类模型。
近些年,随着深度嵌入聚类(Deep Embedding Clustering,DEC)[13]模型的提出,深度聚类研究领域变得越来越引人关注,于是大量深度聚类模型被提出,对现有的深度聚类模型进行了一个全面综合的整理。文献[14-15]提出从神经网络的角度出发建立一个分类系统,对现有的深度聚类模型进行分类。然而,这两篇文章是对早期的深度聚类模型进行整理,缺少最前沿的深度聚类算法。本文综合整理了现有的深度聚类模型,补全了文献[14-15]中缺少的图神经网络。
深度聚类的本质是用神经网络学习一个聚类导向的特征表示,并用神经网络拟合数据内蕴的聚类规律。深度聚类模型的两个关键因素是神经网络和聚类规律。神经网络相比于聚类规律能更清晰地划分深度聚类模型。因此,本文沿用以前的分类标准,使用神经网络作为深度聚类的区分标准。回顾现有的深度聚类模型,将深度聚类模型分为基于前馈神经网络的深度聚类模型、基于自编码器[16]的深度聚类模型、基于生成模型的深度聚类模型和基于图卷积神经网络的深度聚类模型。
1 深度聚类的神经网络
深度聚类模型选用不同的神经网络可以借用不同神经网络的能力提升聚类效果,如自编码器能产生表征数据本质的特征,生成模型能够捕获数据分布等。深度聚类模型借助神经网络提高了聚类效果,但深度聚类模型也存在神经网络的一些缺点,如生成模型的模式崩塌、难以收敛等。
1.1 前馈神经网络
前馈神经网络是一种最简单的神经网络,一般采用单向多层的结构。整个网络中无反馈,信号从输入层向输出层单向传播。其中,网络层选用基础的神经元,最出名的模型是多层感知机(Multilayer Perceptron,MLP)。如果网络层使用卷积操作,则是卷积神经网络模型。
1.2 自编码器
自编码器[17]是无监督特征学习领域中最出名的算法,由编码器和解码器两部分组成。编码器h=fθ(x)将输入样本x映射为一个隐特征h。解码器r=gθ(h)从隐特征h中重构出原始样本,要求重构样本r逼近原始样本x。
当使用均方误差时,自编码器的优化目标为:

自编码器的中间特征维度小于输入样本维度时,可以学得一个能表示样本本质的低维隐特征,此时把这种自编码器称为欠完备自编码器。
1.3 生成模型
生成模型能够捕获数据分布并产生未见样本,基于生成模型的深度聚类模型,期望借助生成模型的能力捕获数据样本属于各簇的后验概率分布。生成对抗网络(Generative Adversarial Network,GAN)[18]和变分自编码器(Variational Auto-Encoder,VAE)[19]是最成功的生成模型,在这两个模型上都有成功的深度聚类模型。下面将分别介绍这两个神经网络。
1.3.1 GAN
生成对抗模型通过让识别器D和生成器G进行最大化、最小化的对抗性训练来捕获数据分布。生成器G把来自先验分布p(z)的特征Z生成为一个样本。识别器D通过训练能够识别出输入样本是真实样本还是来自生成器的假样本。
GAN 的对抗性训练可以描述为:
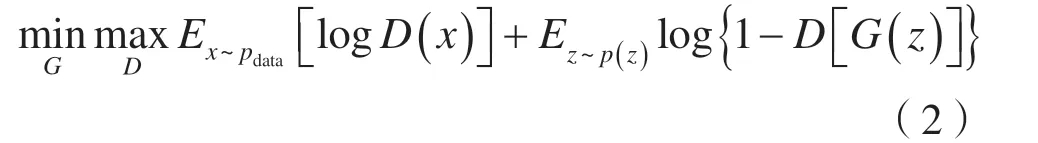
生成对抗模型可以使数据的特征表示所服从的分布逼近任意给定的先验分布,并可以从这个先验分布中生成真实未见的样本。GAN 模型虽然能捕获数据分布,但存在难以收敛、模式坍塌等问题,会延续到基于生成对抗模型的深度聚类模型上。
1.3.2 VAE
变分自编码器是自编码器在生成模型上的变体。VAE 要求自编码器的中间特征服从给定的高斯分布。通过变分推断法推断出样本概率p(x)的最大下界。最大化证据下界的过程会使样本的中间特征逼近给定的先验分布。
VAE 的优化目标如下:
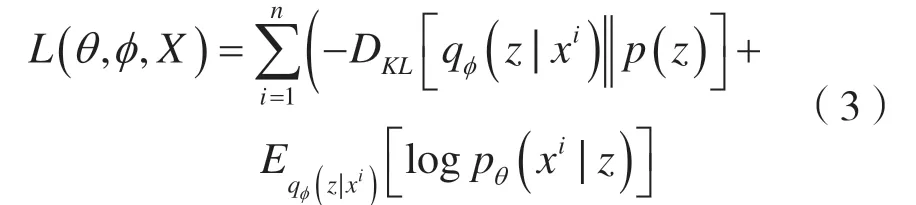
式中:qφ(z|xi)表示经验后验概率,近似表示未知的真实后验概率;qφ(z|xi)代表编码器;pθ(xi|z)代表解码器。
1.4 图卷积神经网络
图卷积神经网络是卷积操作的一种扩展。图卷积操作能够处理图结构数据,提取带有结构信息的特征,而卷积操作做不到。
图卷积操作可以描述如下:
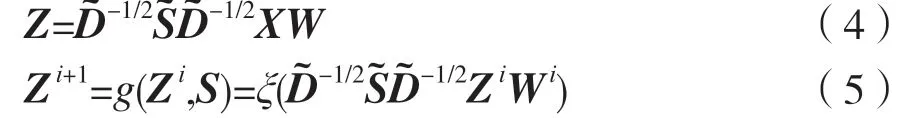
式中:S表示图结构(邻接矩阵);X表示N个节点的特征矩阵;W表示图卷积核;D表示图的度矩阵(对角矩阵);Z表示图卷积结果;g(·)表示图卷积操作;ξ(·)表示非线性激活函数。其中,邻接矩阵S和特征矩阵X是图卷积神经网络的输入。
2 深度聚类的评估指标
深度聚类模型有3 种常用的评估指标,分别为无监督聚类准确度(Unsupervised Clustering Accuracy,ACC)、标准化互信息(Normalized Mutual Information,NMI)和同质性(Homegeneity)。
2.1 ACC
ACC[20]用来评估聚类准确性,一般要求簇的个数等于真实类别数,是在所有映射关系中找出准确率最大的一种映射。
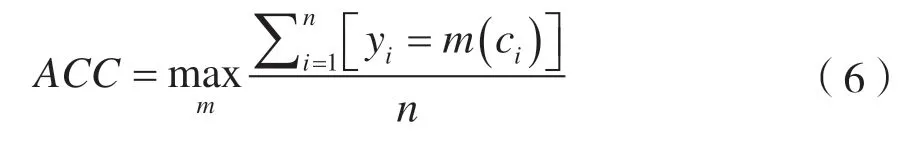
式中:yi表示样本的真实标签;ci表示算法的预测标签;m(·)表示预测标签与真实标签的一种映射关系。
2.2 NMI
NMI[21]用来评估预测标签分布与真实标签分布之间的差异。
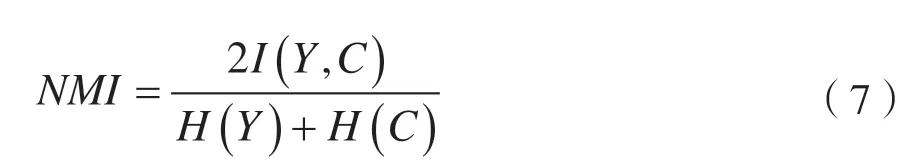
式中:Y表示真实标签;C表示预测标签;H(·)表示信息熵。
2.3 Homegeneity
Homegeneity[22]用来评估聚类簇的同质性,即划分到一个聚类簇中的样本属于同一个类别的可能性。
Homegeneity 计算公式如下:
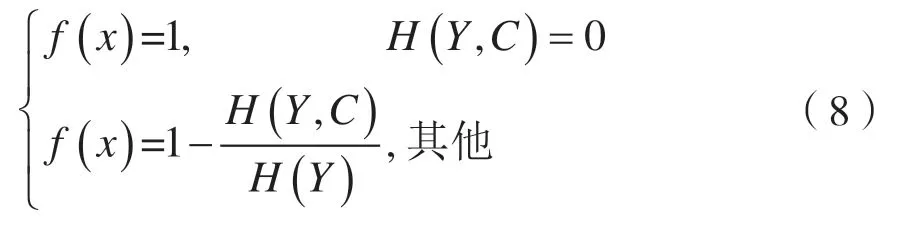
3 深度聚类的分类
深度聚类的本质是用神经网络学习一个聚类导向的特征表示,并用神经网络拟合数据内蕴的聚类规律。深度聚类模型的两个关键因素是神经网络和聚类规律。以这两个关键因素考察现有深度聚类模型的损失函数,可以将损失函数统一为如下形式:

整个损失函数由网络损失Ln和聚类损失Lc两部分组成。网络损失Ln用来学习一个利于聚类的特征表示,聚类损失Lc用来拟合设定的聚类规律。从神经网络的角度出发,将深度聚类模型划分为基于前馈神经网络的深度聚类模型、基于自编码器的深度聚类模型、基于生成模型的深度聚类模型以及基于图卷积神经网络的深度聚类模型。
3.1 基于前馈神经网络的深度聚类模型
前馈神经网络中最出名的模型是卷积神经网络。前馈神经网络一般都需要样本的标签信息作为网络的监督信号,限制了前馈神经网络在无监督聚类领域中的应用,是基于前馈神经网络的深度聚类模型需要克服的难点之一。
循环框架的凝聚深度聚类(Recurrent Framework Agglomerative Deep Clustering,RFADC)模型[23]是在卷积神经网络上建立的深度聚类模型。前馈神经网络一般需要样本的标签信息作为监督信号。RFADC 模型在Agglomerative 聚类的基础上构建了一个循环框架。在t次循环时,根据聚类簇的相似性合并t-1 次循环的聚类簇,同时使用t-1 次循环的聚类簇标签更新用于提取特征的前馈卷积神经网络。RFADC 循环框架背后的思想是好的聚类结果能够提取利于聚类的特征表示,而聚类导向的特征表示能够提升聚类效果,以此形成一个相互促进的循环结构。
3.2 基于自编码器的深度聚类模型
自编码器在重构原始样本时能产生表征样本本质的特征,而深度聚类的一个关键因素是学习一个利于聚类的特征表示,因此自编码器可以作为深度聚类的优先选择。自编码器的重构损失一般可以视为深度聚类模型的网络损失Ln,从不同角度出发设计的聚类规律可以视为深度聚类模型的聚类损失Lc。下面介绍一些典型的基于自编码器的深度聚类模型。
3.2.1 深度聚类网络
深度聚类网路(Deep Clustering Network,DCN)模型[24]是自编码器聚类算法中最经典的模型,结合了自编码器与k-means 算法。
目标函数如下:
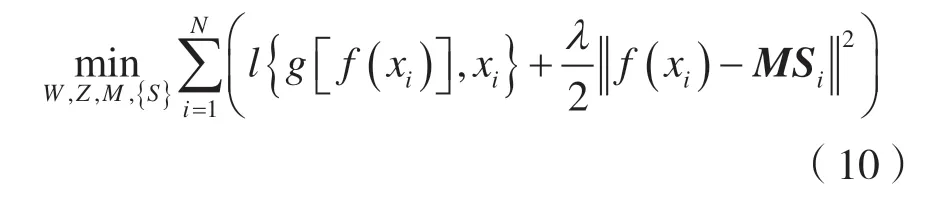
式中:f(·)代表编码器;g(·)代表解码器;l(·)代表重构误差函数;M是由各簇的中心向量组成的中心矩阵;Si为样本i所属簇的one-hot 向量。该模型的目标函数包含中心矩阵和分配向量,整个目标函数的优化需要使用自定义的交替优化算法。
3.2.2 深度嵌入网络
深度嵌入网络(Deep Embedding Network,DEN)[25]是另一个自编码器聚类模型,在自编码器的基础上,通过添加两个约束项来学得一个利于聚类的特征表示,最后在这个利于聚类的特征上进行k-means 算法,以提供聚类效果。
整个目标函数如下:

式中:Eg代表局部保持约束项。它通过把相似的样本聚在一起降维,从而在低维子空间中保持原始数据的局部结构,公式描述如下:
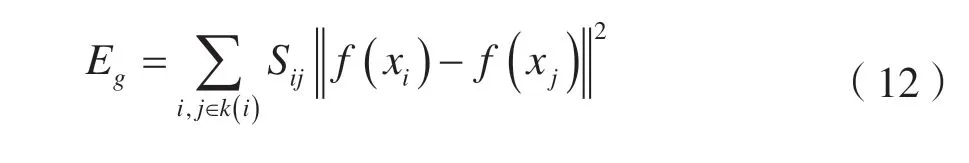

3.2.3 DEC
DEC 是深度聚类领域最具代表性的方法之一。它的提出引起了人们对深度领域的广泛关注。DEC模型事先预训练一个自编码器,选取编码器部分用于特征提取,在提取的特征上用一个软分布对样本簇标签进行预测,用硬分布选择样本的高置信度簇标签。最小化软分布与硬分布之间的KL 散度将引导聚类结果逐渐向高置信度分布靠近。
软分布公式如下:

软分布把样本与聚类中心的相似度转换为概率分布。硬分布是对软分布进行加强,即聚类分配置信度高的得到加强,置信度低的得到减弱。这种加强操作通过对软分布进行平方后的标准化来实现,公式如下:

DEC 模型的最终目标为最小化软分布与硬分布之间的KL 散度:

3.2.4 深度子空间聚类网络
深度子空间聚类网络(Deep Subspace Clustering Networks,DSC-Nets)模型[26]在自编码器的框架上引入子空间聚类的自表示性质。自表示性质的描述如下:给定来自多个线性子空间{Si}i=1,…,K的数据样本{Xi}i=1,…,N,则样本Xi可以由同一个子空间中其他样本线性组合而成:
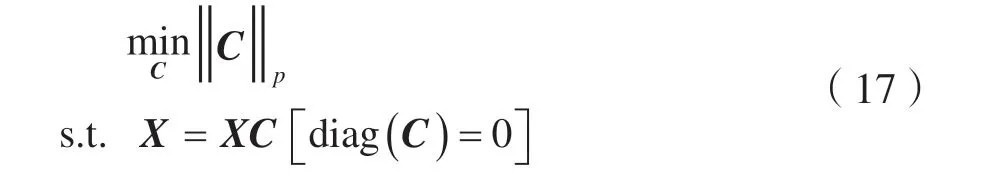
式中:矩阵C为自表示系数矩阵。
DSC-Nets 模型在编码器和解码器的中间引入一个自表示层网络用来模拟上述的自表示性质。这个自表示层采用全连接网络,没有阈值,没有非线性激活函数,输入来自编码器,输出为解码器输入。
DSC-Nets 完整损失函数如下:

DSC-Nets 模型空间消耗和时间消耗过大,不适用于大规模数据集。
3.3 基于生成模型的深度聚类模型
将生成模型引入聚类领域的目的是希望借助生成模型捕获数据分布的能力去捕获数据样本属于各簇的后验概率分布。生成模型中最广为人知的模型是变分自编码器(Variational Autoencoder,VAE)和生成对抗模型(Generative Adversarial Networks,GAN)。将这两种生成模型分别引入聚类领域,形成了基于VAE的深度聚类模型和基于GAN 的深度聚类模型。
3.3.1 基于VAE 的深度聚类模型
变分自编码器要求自编码器的中间特征服从给定的高斯分布。在将变分自编码器引入聚类领域时,将原有假设服从一个标准高斯分布变为服从由K个多元高斯分布组成的高斯混合分布。现有的两个深度聚类模型都是基于这个新的假设,不仅可以输出样本属于各簇的概率,还可以生成指定类别的样本,但是计算复杂度过高。
(1)变分自编码器(Variational Deep Embedding,VaDE)[27]是在变分自编码器上开发的一个优秀深度聚类模型,强制编码器的中间特征服从高斯混合分布。VaDE 是一个生成模型的同时,也是一个聚类模型,所以其生成的样本需要指定所属的簇。生成模型由簇类c、簇的中间特征z、样本x这3 个部分共同决定。所以,假设生成模型为:

观测样本x的生成过程如下:
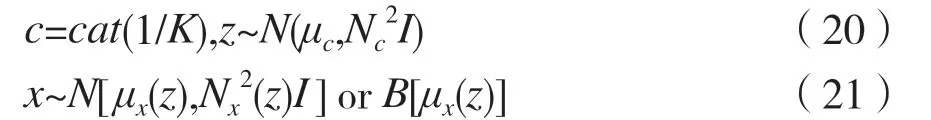
式中:cat(·)表示类别的离散分布;K为预先定义的聚类簇个数;μc、σc为簇c对应的均值和方差;μx、σx是样本x对应的均值和方差。
VaDE 的总体目标与VAE 相似,都是最大化生成模型的对数似然函数,即:
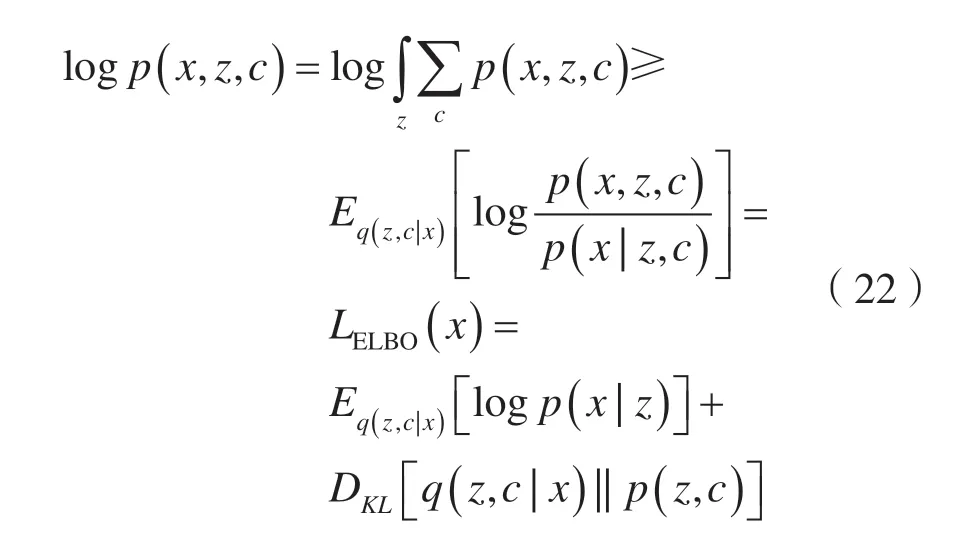
这里最大化生成模型的对数似然函数就是最大化证据下界LELBO(x)。下界中的第一项重构损失可以视为网络损失Ln;第二项最小化后验概率分布与先验分布的KL 散度可以视为聚类损失Lc,将用来完成聚类分配。
(2)GMVAE(Gaussian Mixture VAE)[28]与VaDE 相似,对生成过程的假设更复杂。
GMVAE 对生成模型做如下假设:
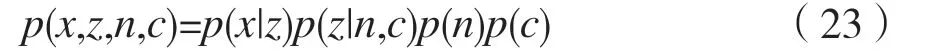
即生成过程由类别c和标准正态分布n共同生成中间特征z,再由中间特征z生成观测样本x。整个生成过程的数学描述如下:
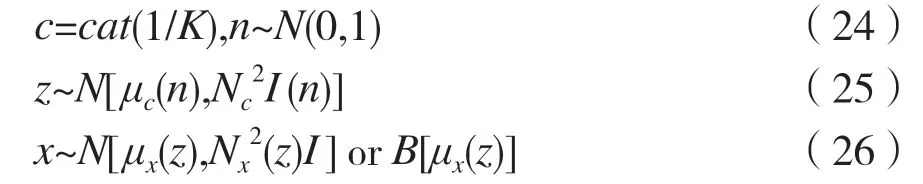
GMVAE 同样是把最大化生成模型的对数似然函数转化为最大化证据下界LELBO(x),得到一个能进行聚类分配的后验概率分布。需要注意,GMVAE 要比VaDE 更复杂。但是,从聚类效果上来看,GMVAE 要比VaDE 更差。
3.3.2 基于GAN 的深度聚类模型
基于GAN 的深度聚类模型希望借助GAN 捕获数据分布的能力,捕获数据样本属于各簇的后验概率分布。基于GAN 的深度聚类模型中,有的模型是专门针对聚类任务开发的,有的模型只是把聚类任务当作模型的一个应用场景。
(1)对抗自编码器(Adversarial Auto-Eencoder,AAE)[29]和变分自编器相似。VAE 使用KL 散度强制中间特征服从标准正态分布,而AAE 使用对抗性训练强制中间特征服从标准正态分布。AAE 的聚类使用方式是把自编码器中间特征拆分为两部分——softmax 输出代表簇标签的one-hot 向量z和代表样本样式的隐特征y。隐特征y与标准正态分布进行对抗性训练的同时,保证z与y组成的中间特征能够重构原始样本x,从而保证类别向量z与样式y在语义上相互分离。
(2)深度对抗聚类(Deep Adversarial Clustering,DAC)模型[30]是在AAE 模型的基础上设计的一个深度聚类模型。它把AAE 对抗训练使用的聚合后验概率分布从标准正态分布变为高斯混合分布(其系数、均值、协方差矩阵参数化)。参数化混合分布的方式类似于VaDE 的编码器过程。DAC 的损失函数由:自编码器重构损失、高斯混合模型的似然函数、最大化最小化的对抗目标3 部分组成。
它的数学描述如下:
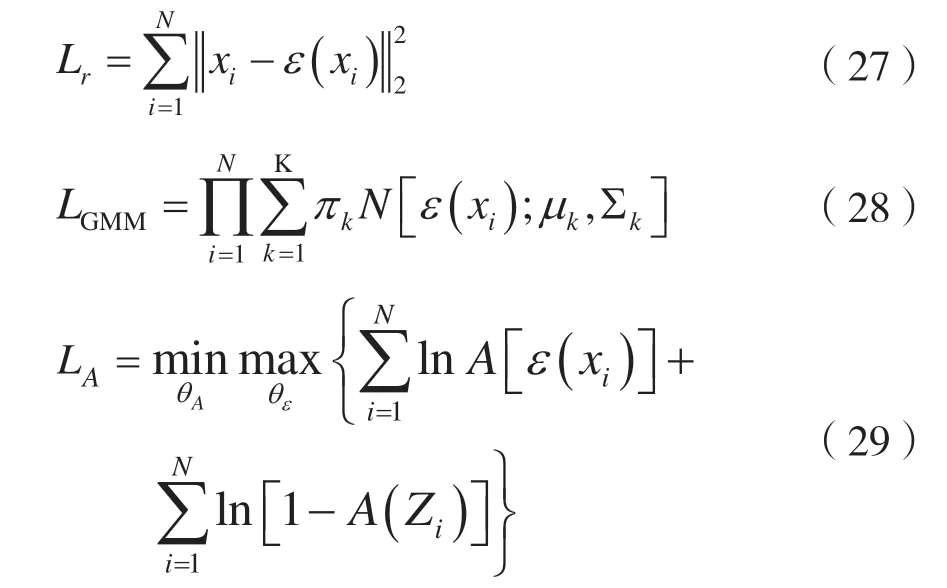
式中:第1 项可以视为网络损失;后2 项可以视为聚类损失。
(3)分类生成对抗网络(Categorial Generative Adversarial Network,CatGAN)模型[31]是在GAN 模型基础上进行的一种扩展。它在数据集上进行无监督学习,将GAN 模型的二分类识别器扩展为多分类识别器。在无监督条件下,CatGAN 模型从信息论的角度出发完成簇标签与样本之间的对应关系。
它的具体设计过程如下:保持生成器G不变,从给定的先验分布p(z)中抽样噪声z,生成器G把噪声z生成一个假样本:

识别器D将GAN 模型的二值识别器D改成输出为样本属于各簇概率的K值识别器D,p(y=k|X,D)。由于对抗性训练的需要,CatGAN 模型对识别器D做如下要求:①确定真实样本的分配类别;②不确定生成样本的类别;③平等的使用所有类别的样本。对于要求①,由于没有真实标签信息,因此从信息论的角度出发,最大化真实样本分配类别的确定性,数学公式即为最小化预测分布的信息熵Hx[p(y|X,D)]。对于要求②,数学公式则为最大化生成样本预测分布的信息熵Hz[p(y|G(z),D)]。对于要求③,选择均匀分布来达到平等的使用所有类别样本。从信息论上来说,即最大化所有样本边缘分布的信息熵HX,G[p(y|D)]。
整个对抗性训练过程的损失函数如下:
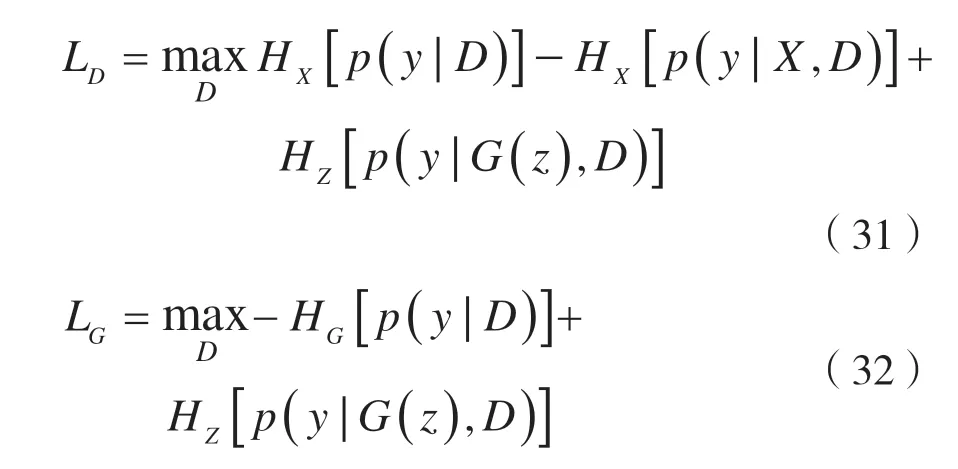
(4)信息最大化生成对抗网络(Information maximizing Generative Adversarial Network,InfoGAN)模型[32]与CatGAN 模型类似,都是从信息论的角度出发,把GAN 模型扩展到无监督领域。InfoGAN 的主要目的是分离生成器输入变量的语义信息,即使得输入的每个变量都代表不同含义的语义信息。InfoGAN 的具体操作过程如下:识别器D拥有两个输出层,一个输出层D输出样本是否是真样本,另一个输出层Q输出样本的各个语义变量。生成器G的输入噪声为(C,Z),其中C代表不同语义变量的离散值,Z代表不可压缩的连续特征值。InfoGAN 模型的对抗性游戏做如下改动:识别器D最大化识别真样本的概率,生成器G最小化识别生成样本的概率,同时最小化输出变量c~与生成样本G(z,c)之间的互信息。
它的数学描述如下:
式中:L1(G,Q)为输入变量与生成样本之间互信息I[,G(z,c)]的证据下界。
3.4 基于图神经网络的深度聚类模型
图卷积操作能够处理非对齐型数据,如图结构数据,提取的特征信息含有数据节点的结构信息。因此,将图卷积神经网络引入无监督聚类领域的优势是可以提取利于聚类的特征表示。
图卷积操作需要数据集具有图结构信息,而需要聚类的数据集一般没有图结构。针对这个问题,AGAE(Adversarial Graph Auto-Encoders)模 型[33]通过集成聚类构建一个一致性图来将图卷积操作引入聚类领域。
具体构建方法如下:使用M个传统聚类方法对数据集进行聚类,获得数据集的M种聚类分配方案,并在M种聚类分配方案中使用如下函数获得联合矩阵作为数据集的图结构。

在一种聚类分配中,如果样本a与样本b的预测标签相等,则δ(a,b)=1;否则,δ(a,b)=0。获得图卷积特征后,AGAE 模型在这个特征上设计了一个特征先验分布:
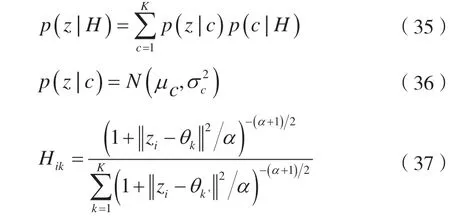
从这个特征先验分布抽样一个特征,把它与图神经网络得到的特征进行对抗性训练,得到一个能进行聚类的特征先验分布。
其目标函数为:
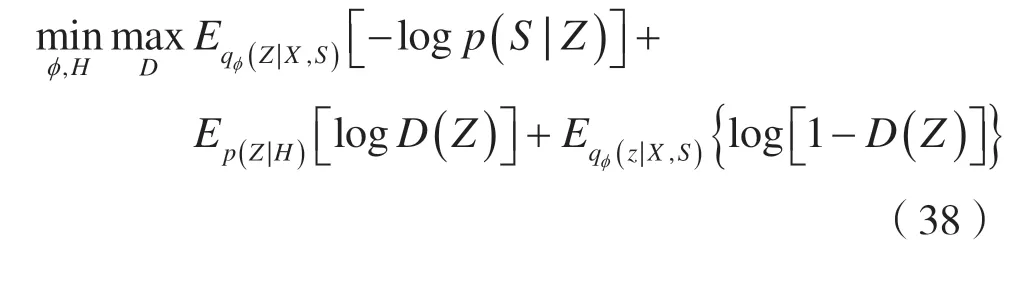
4 深度聚类的未来方向
基于上述深度聚类模型的分析与深度聚类结构的研究,认为深度聚类未来的关注点如下。
4.1 聚类理论研究
虽然联合优化神经网络与聚类目标可以提高聚类性能,但可解释性不强,因此需要探索深度聚类的理论依据,为深度聚类的进一步研究作出理论指导。
4.2 聚类场景与神经网络
深度聚类模型借用不同神经网络的能力,帮助提升聚类效果。而不同的神经网络适用的场景不同,如卷积神经网络适用于图像数据集,循环神经网络适用于序列数据集[34-36]。现有的深度聚类模型大多都是针对图像数据集开发的,所以针对文本序列数据集,尝试将循环神经网络引入无监督聚类领域是后续的任务之一。
4.3 平衡聚类约束项
深度聚类模型的聚类效果是由多个约束项共同作用得到的结果,而每个约束项起到的重要性程度不同。因此,如何平衡各约束项是一个重要工作。
5 结语
在大数据时代,随着数据的获取越来越便利,数据分析、计算机视觉等应用需要处理的数据量越来越大、数据结构的复杂度越来越高。面对这些新挑战,传统聚类算法越来越无法满足需求。而深度学习可以处理复杂数据结构、冗余信息以及大数据等难点,因此将深度学习引入无监督聚类领域是应对大数据时代的一种必然。本文从深度神经网络的角度出发,对深度聚类算法做了一个全面综合的回顾。基于前馈神经网络的深度聚类模型是深度模型中最基础的模型。基于自编码器的深度聚类模型,借助自编码器无监督特征学习能力,联合聚类目标完成子空间聚类。基于生成模型的深度聚类模型则借助生成模型捕获数据分布的能力,捕获数据样本属于各簇的后验概率分布。基于图卷积神经网络的深度聚类模型则是希望使用图卷积操作,提取带有节点结构信息的特征辅助聚类。
