一种自动构建数据集的实体关系抽取方法*
2021-08-30房冬丽陈正雄黄元稳衡宇峰
房冬丽,陈正雄,黄元稳,衡宇峰
(中国电子科技集团公司第三十研究所,四川 成都 610000)
0 引言
实体和关系概括了文本主要内容,能够直观地展现数据之间的联系,为智能问答、检索系统等下游任务提供基础数据。目前,除了论文等形式规范的文献提供了几个关键词外,大部分文献资料都没有提供能够反映其内容的、直观的数据结构。依靠人工阅读文本来抽取文档实体关系的传统方法在拥有多源、海量文档数据的今天越来越不能满足实际应用的需求。因此,如何高效、准确地抽取实体和关系是当前急需解决的一个问题。目前,抽取实体、关系的方法层出不穷,总结起来主要分为基于规则的方法和机器学习的方法两大类。
(1)基于规则[1]的方法。该方法需要构建一定数量的规则模板集合,由领域的相关语言学家建模、指定匹配模式。它在字符、单词特征分析、词法分析以及句法依存分析等语言学知识的基础上,获取高质量的语法模式匹配模板,挖掘文本中现存的关系模式。这种手工编制规则的方法在早期能有效地应用到专业领域,但由于语言规则的复杂多样性,需要消耗大量的人力来编写规则。
(2)机器学习[2-9]的方法。该方法中的实体关系抽取方法大多是从语言特征来考虑。需要考虑如何提取词性标注、语法解析树等特征,并且需要预先构建一定的样本数据,再将样本输入到模型训练。然而,构建特征依赖于自然语言处理工具的技术水平,工具产生的误差会在实体关系抽取过程中传播和积累,对后续操作影响较大。此外,样本数据的产生需要消耗大量的人力。
数据对各领域来说都是十分重要的资源,数据的匮乏限制了各领域研究工作的进展,且传统人工标注的方式需消耗大量的人力资源。针对这些问题,本文基于哈工大语言技术平台(Language Technology Plantform,LTP)和双向编码器(Bidirectional Encoder Representations from Transformer,BERT)模型,提出一种抽取文本中实体关系的技术解决方案。一方面,可对文本内容实现自动化解析,有效解决训练与测试数据集生成难的问题;另一方面,通过对BERT模型的优化调整,解决以往实体关系的抽取需依赖大量资源计算的问题,仅通过对BERT 模型的微调,就能高效抽取文本中的实体关系,从而直观地呈现多源异构数据之间的本质联系。
1 相关工作
实体关系抽取是知识图谱基础的一部分,目前已经提出了大量方法。在英文的实体关系抽取上,基于神经网络的方法是主流的方法,其中卷积神经网 络(Convolutional Neural Networks,CNN)与 条件随机场(Conditional Random Field,CRF)结合的模型和双向长短期记忆神经网络(BI-directional Long Short-Term Memory,BIL-STM)与条件随机场(Conditional Random Field,CRF)结合的模型最为典型。但该方式并不适用于中文,因为对于中文实体关系抽取主要分为基于字和词的方式。基于词的方式利用分词工具进行分词,再进行抽取,但存在错误传播的问题。基于字的方式是将语料笼统地进行切分,但将中文字上下文语义切割会导致无法充分利用词信息的问题。
随着深度学习的快速发展,在自然语言处理(Natural Language Processing,NLP)领域,词向量备受关注,其中word2vec24[10]和GloVe25[11]是两个典型模型。鉴于中文的特殊性,Zhang[7]等人采用同义词词典来缓解字词的多义问题。Chen[8]等人提出增强词向量(Character-enhanced Word Embedding,CWE)模型,采用字词的联合学习,最大限度利用文本的特征信息,以提高向量的质量。目前,一些基于大规模无标注数据的预训练方法被提出,如典型的向量表示语言模型(Embeddings from Language Models,ELMo)[12]、BERT[13]和预训练(Generative Pre-Training,GPT)[14]等。ELMo 使用海量无标注文本对语言模型进行预训练,进而进行加权求和,每层神经网络的中间表示作为上下文相关的词向量,实现一词多义的表示。2019 年Google 发布BERT 的最新版本,在此基础上,基于BERT 的研究层出不穷,如李建[15]等人提出的基于改进BERT算法的专利实体抽取。
2 自动构建数据集的实体关系抽取方法
2.1 基于LTP 和BERT 优化
本文针对LTP 和BERT 模型进行了优化。针对文本数据集匮乏的情况,采用LTP 分词工具自动完成数据集的构建,有效解决以往只能靠人工大量标注的问题。
BERT 模型的自监督任务中,有个掩码语言模型(Masked Language Model,MLM)任务,即在网络训练时随机在输入序列中掩盖掉一部分单词,然后通过上下文输入到BERT模型中来预测被掩盖的单词。但MLM 是针对英文的NLP 训练方法,因此MLM 任务会将中文词语进行分割,割裂上下文语义信息。2019 年Google 发布BERT 的最新版本,将文本中的掩盖粒度从单词升为词语,尽可能保证句子语义不被分割。遗憾的是BERT 仍没有针对中文的版本。《Pre-Training with Whole Word Masking for Chinese BERT》[16]中指出,可采用LTP 分词工具先对句子进行分词,然后再以词为粒度进行掩盖,进行自监督训练。因此为了更好地提高中文语义理解,本文首先使用LTP 工具进行分词,再结合2019 年BERT最新版本提供的词粒度的掩盖能力以及开放的源代码,重新执行BERT 的预训练过程,从而构建支持中文的词粒度级别的BERT 模型。此外,本文采用的实体和关系网络模型皆是基于该BERT 模型。
2.2 实体关系抽取算法流程
该算法包含6 个步骤,如图1 所示。
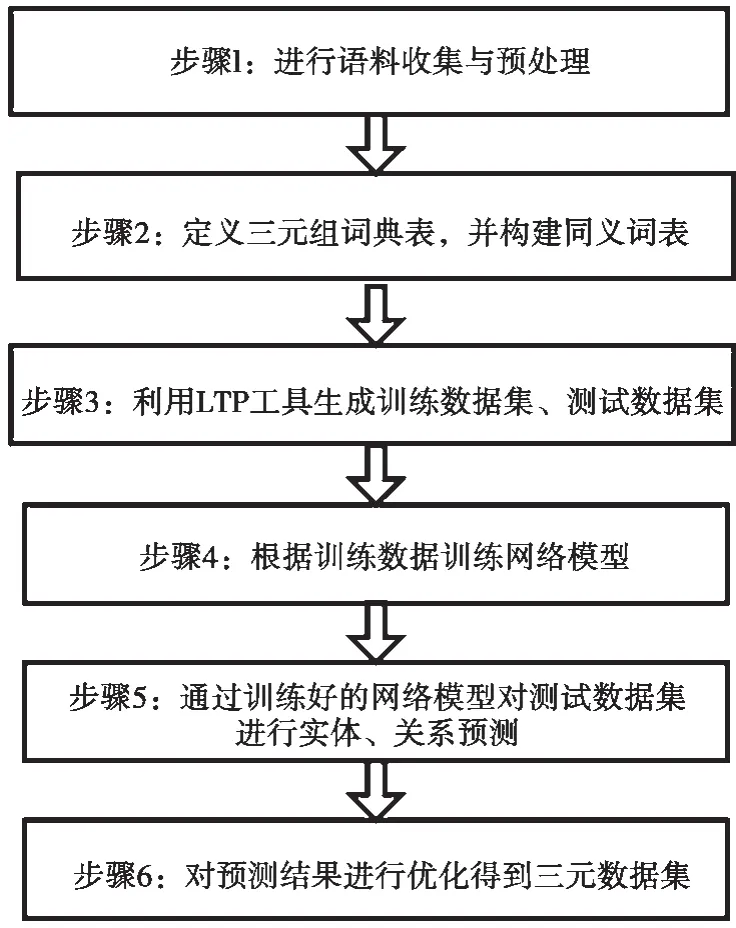
图1 实体关系抽取算法流程
2.2.1 语料处理
步骤1 主要收集爬虫数据和不可公开的文档数据,对收集的多源异构数据进行清理,最后对文本内容进行准确地语句划分。针对不同类型的文本可采用不同的切分方式实现,比如利用正则表达式切分、利用标点符号切分等。
2.2.2 字典定义
步骤2 中,根据预处理后的语料,定义实体类别与类别关系,形成三元组字典表。主要包括定义实体、关系类别、数据类型等信息。
2.2.3 数据集自动生成
步骤3 中,LTP 融合了基于词典匹配和基于统计机器学习的分词算法,可以方便地对语料进行词性标注、词性类别标注、边界等信息标注。因此,采用LTP 工具根据标注信息,确定词语的词性为名词或动词。名词作为实体,动词作为关系或属性,初步形成训练数据集和测试数据集。
由于通过LTP 工具构建出的数据集存在不规范、不合理的数据,需对其进行清理。对于实体关系、属性类型不明确的数据进行纠正,对于不合理的数据进行清理,同时不断优化实体类别和关系类别字典表,最终形成高质量的数据集。
2.2.4 模型训练
步骤4 中,一个句子可能会包含多个关系或者实体,所以对于实体、关系的抽取过程是多标签分类任务。为更有效地提取文本中的实体关系信息,本文采用实体、关系网络模型分离的方式,先构建关系网络模型,再构建实体网络模型。主要目标是让关系网络模型尽可能多地抽取出所有关系分类,以便于实体网络模型能够更好地抽取出相关实体。近年来BERT 模型以其自身的优势,在NLP 领域得到广泛应用,因此本文要构建的关系和实体网络模型皆基于BERT 模型。基于BERT 模型构建关系和实体网络模型十分方便,只需定义transformer、self-attention、隐单元、循环次数等。其中,本文采 用12 层transformer,12 层self-attention,768 个隐单元,循环次数为3。关系分类模型与实体抽取模型的输入是(1,n,768)维度的向量,BERT 模型的输出采用句子级别,BERT 模型输出的特征信息经过一个全连接层与Sigmoid 激活函数。具体模型如图2 所示。
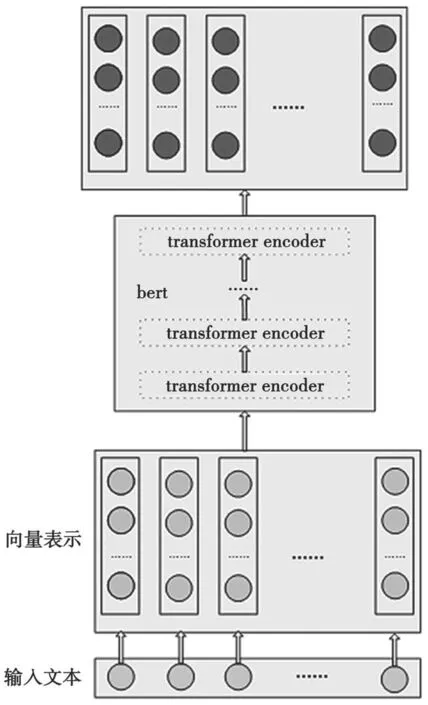
图2 网络模型
在训练阶段,主要是对训练数据集进行处理,从而形成网络模型的权重和偏置等参数,并进行保存,供后续在测试数据集上进行验证。两种网络模型的训练过程为:
(1)在句子开头和结尾分别插入CLS 和SEP;
(2)将每个字转换成768 维的向量;
(3)产生segment ids;
(4)产生positional 向量。
3 种向量均为(1,n,768),可进行元素相加,得到一个(1,n,768)的合成表示,即BERT 的编码输入。将编码后的信息输入到定义好的网络模型中,并行执行实体、关系的网络模型训练,网络模型和各种权重参数、偏置信息的保存等。
其中,激活函数为:

仅有该模型还不能有效地抽取出有用的特征信息。尽管BERT 模型是基于开源语料预训练过的,但各领域文本组成具有复杂性、多样性,使整个BERT模型预训练阶段较难涉及到完整的领域数据。本文通过对提出的模型训练微调,不断优化模型。由于是多标签分类任务,因此采用与之匹配的损失函数:
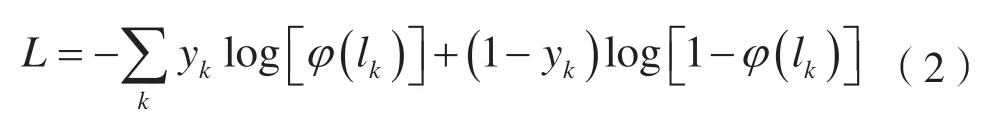
式中:yk表示one-hot 编码的标签;输出层包含k个神经元对应k个类别;φ(lk)表示使用Sigmoid 函数激活输出层对应的神经元。
2.2.5 实体关系预测
步骤5 基于步骤4 中训练好的网络模型,在测试数据集上进行实体预测、关系预测。基于BERT的实体和关系网络模型将输入文本自动拆分成两个参数text-a 和text-b。text-a 是句子内容,text-b 可以是具体的关系,从而进行多种关系的预测以及实体位置的标注。
2.2.6 转换三元组
步骤6 中的预测结果优化方法对预测处的实体关系是否存在同义词、近义词或者指代相同的实体或关系判别。采用余弦相似度进行判别,若余弦相似度高于阈值,则认为是同一类型的词,反之则不是。通过计算余弦相似度,清理语义相同的实体关系,形成最终的三元组数据集。所述余弦相似度计算方式为:
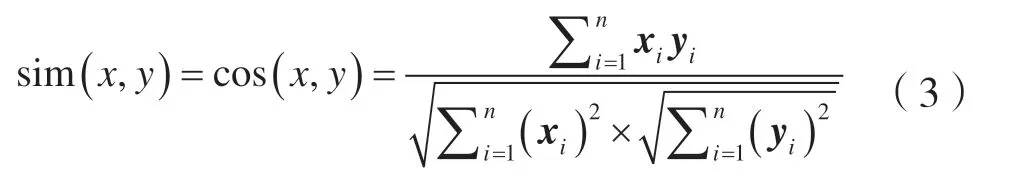
式中:x、y分别表示两个词的向量集合;xi代表x中第i个词语的向量表示;yi代表词语y中第i个词语的向量表示。
2.3 政策法规领域实验
2.3.1 实验流程
本文给出原始文本数据以政策法规领域文本为主的实施实例。收集网络爬虫数据和不可公开的文本数据共计15 982 份。具体实验流程如下文所述。
(1)自动构建训练和测试数据集,如图3 所示。
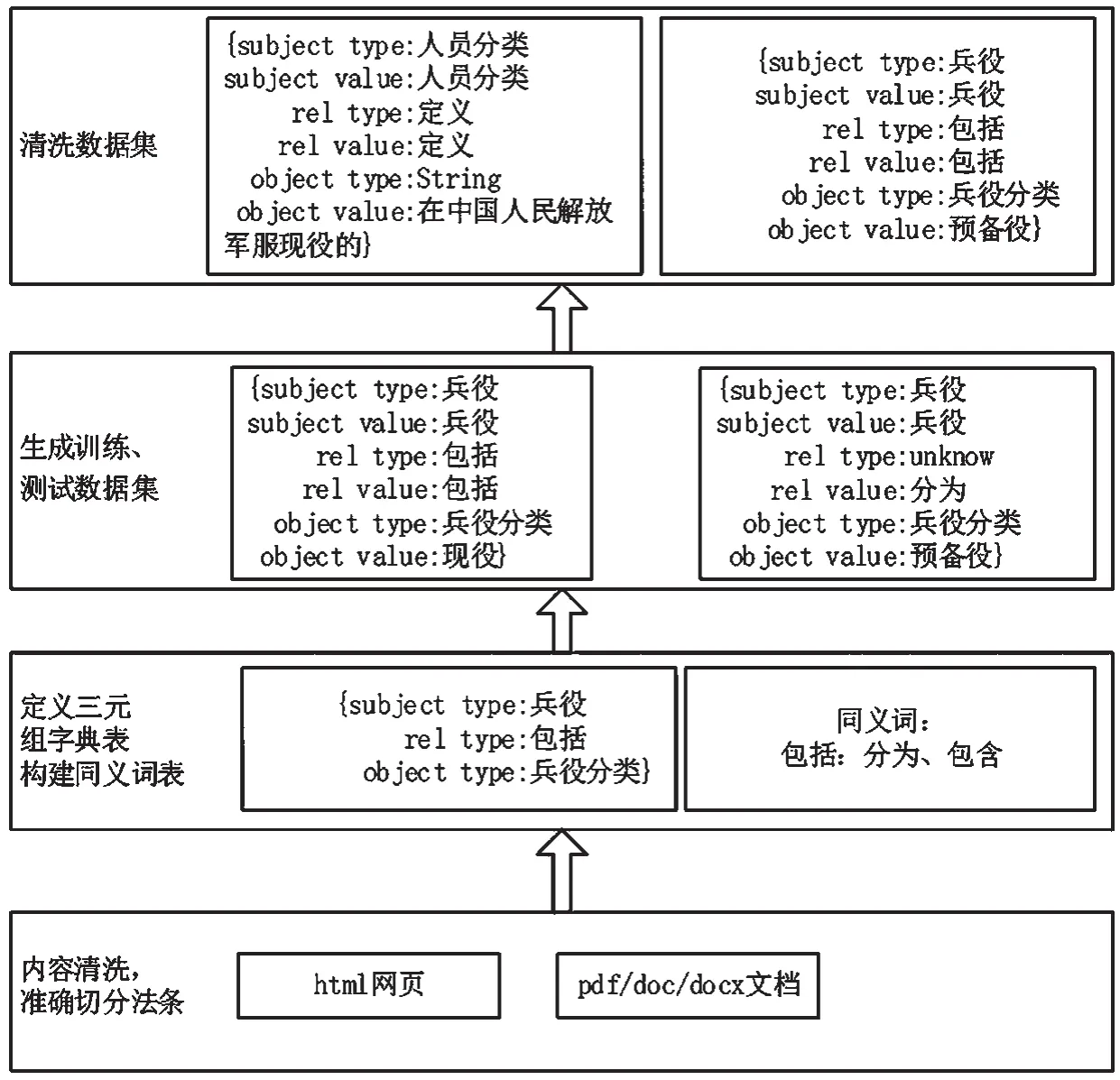
图3 构建训练和测试数据集流程
①首先,利用正则表达式对所有文档进行准确地切分,形成法条。
正则表达式:
第([一二三四五六七八九十百千万零1234567890\s])*[编章节条])([\s\S]*?)(?=(第([一二三四五六七八九十百千万零1234567890\])*[章节条]))。
②其次,定义实体类别和类别关系。实体类别见表1,类别关系见表2。

表1 实体类别

表2 关系类别
③最后,根据LTP 工具标注语料信息,并对数据进行清理形成数据集。
例:现役军人/n 和/c 预备役人员/n,/wp 必须/d遵守/v 宪法/n 和/c 法律/n,履行/v 公民/n 的/u 义务/n,/wp 同时/d 享有/v 公民/n 的/u 权利/n;/wp由于/c 服兵役/v 而/c 产生/v 的/u 权利/n 和/c 义务/n,/wp 由/c 本法/n 和/c 其他/r 相关/r 法律法规/n 规定/v。
产生的数据集如:{现役军人,遵守,宪法},{现役军人,遵守,法律}……
(2)根据训练集训练网络模型,将法条和单个关系分别作为BERT 模型text-a 和text-b,将法条中所有存在的关系尽可能多地预测出来,具体如下例所述。
例如“兵役分为现役和预备役,{兵役,分为,现役},{兵役,分为,预备役}”,先将其转化为“兵役分为现役和预备役,{兵役,分为,现役}”和“兵役分为现役和预备役,{兵役,分为,预备役}”两个句子。再根据每个法条和对应的三元组,在法条中进行序列标注。例如,“兵役分为现役和预备役,{兵役,分为,现役}”被标记为“CLS B-SUB I-SUB 0 0 B-OBJ I-OBJ 0 0 0 0 SEP 现役”。
对训练数据集中每个法条进行tokenization 处理,分为BasicTokenizer 和WordpieceTokenizer 处理,并进行向量化处理,包括掩码向量mark、片段序列segment ids、位置编码positional emcoding。具体如图4 所示,主要包含以下具体步骤:

图4 网络模型输入向量
①在句子开头和结尾分别插入CLS 和SEP;
②将每个字转换成768 维的向量;
③产生segment ids;
④产生positional 向量。
3 种向量均为(1,n,768),可进行元素相加,得到一个(1,n,768)的合成表示,即BERT 的编码输入。编码后的信息输入到定义好的网络模型中,并行执行实体、关系的网络模型训练,网络模型和各种权重参数、偏置信息的保存等。
2.3.2 实验结果
计算余弦相似度,形成实体、关系的三元组数据集,直观地呈现数据间的联系,结果如表3 和图5 所示。
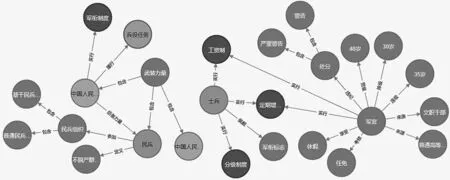
图5 实体和关系
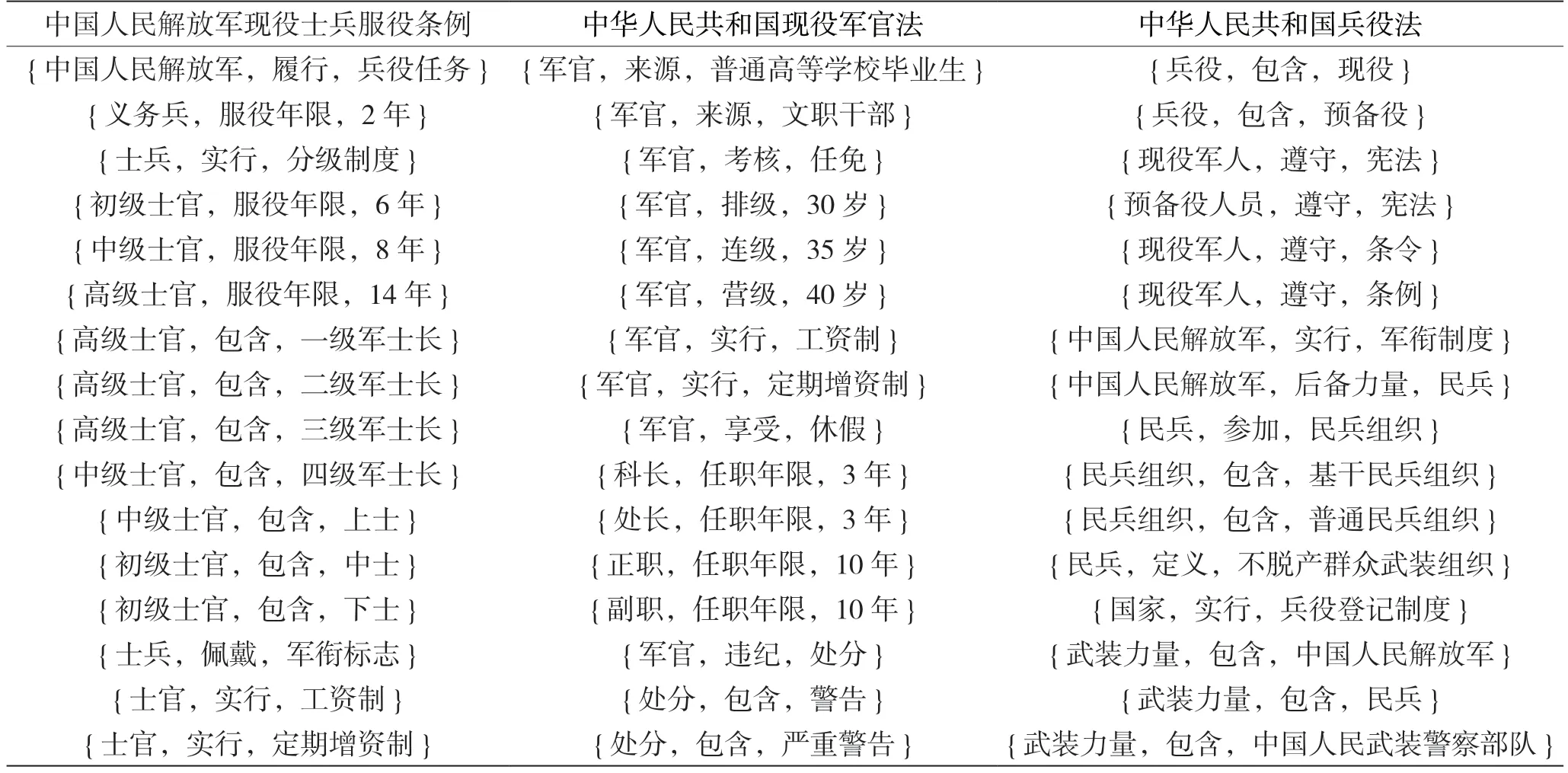
表3 实体、关系案例
3 性能分析
一般采用精确率与召回率对模型的性能进行测评,将测试集中样本分为以下几种:预测正确的阳样本TP,预测错误的阳样本FP,预测正确的阴样本TN,预测错误的阴样本FN,精确率P和召回率R如下:

在实体关系抽取领域,一般采用比较F1的大小,其计算方式如下:

不同网络模型的精确率P、召回率R和F1的值的对比如表4 所示。从表4 可以看出,改进的BERT 模型取得了较好的效果。
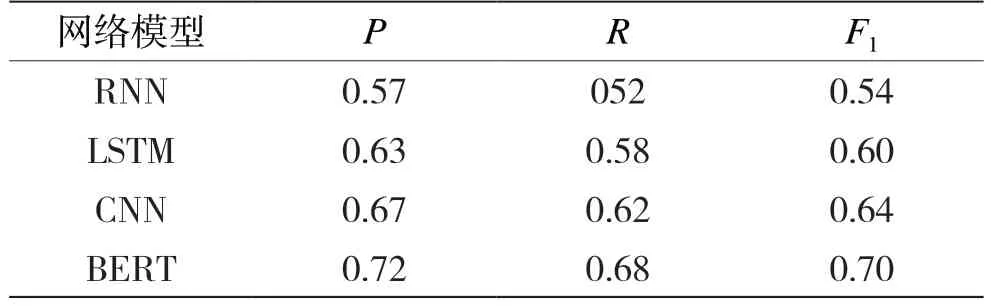
表4 不同模型对比
4 结语
针对训练与测试数据集生成难的问题,提出一种对文本内容实现自动化解析的方法。该方法采用LTP 工具根据标注信息标注名词和动词的词性,名词作为实体,动词作为关系或属性,并对实体关系、属性类型不明确的数据进行纠正,对于不合理的数据进行清理,形成训练数据集和测试数据集。此外,本文通过对BERT 模型的优化调整,解决以往实体关系的抽取需依赖大量资源计算的问题。在政策法规领域的实验结果证明了该算法的可行性和有效性。
