基于顺风车数据和聚类方法的都市圈区域划分与层级结构研究
2021-08-28闫学东郭浩楠李永昌王云官云林
闫学东,郭浩楠,李永昌,王云*,官云林
(1.北京交通大学,综合交通运输大数据行业重点实验室,北京100044;2.山东省交通规划设计院集团有限公司,济南250031)
0 引言
随着我国城镇化进程的快速推进,大城市的辐射带动能力不断增强,都市圈作为一种新型空间形态应运而生。都市圈以一个或多个中心城市为核心,能够吸引辐射周边地区,促进相互联系与合作,带动区域经济社会发展,对于我国新型城镇化建设具有重要意义,也因此得到了学术界与社会各界的广泛关注。国外自上世纪50年代便开始了对都市圈的相关研究,并将其作为一种地域统计与管理单位,服务于社会经济建设。国内学者自上世纪80年代末起对都市圈界定问题展开了初步探究。但由于对研究问题认知的差异性,不同研究领域学者对都市圈的界定标准不尽相同,产生了包括“都市区”“大都市区”“城市群”“都市连绵区”等一系列概念。
不同的定义与界定标准导致都市圈在空间尺度、影响范围等方面无法形成统一认知,这不仅不利于相关理论研究的深入开展,同时也会严重影响政府部门规划工作的有序实施。因此,如何合理划分都市圈区域范围及其结构特征对学术界和规划领域都具有十分重要的意义,更是开展和推动有关都市圈研究的基础和前提。
早期国外学者主要采用土地及人口规模作为评判指标,随后引入通勤率、城市化水平等进一步反映区域间的经济社会联系强度,强调了核心区与外围区域之间的人口空间活动情况。日本将外围区域到中心区域的通勤比例超过15%作为都市圈界定的阈值,美国将通勤率作为大都市区范围界定的唯一指标[1]。
在我国,都市圈这一大尺度的城市空间组织问题最早受到地理及规划领域人文学者的关注。但受限于早期交通调查制度不完善,通勤率相关数据难以获取,学者们多选取人口与经济规模、非农化水平等作为都市圈界定的主要指标。周一星[2]等采用外围县区非农化水平来界定都市圈范围。宁越敏[3]等发现,相比于非农化水平,外围地区的城镇化水平更合适用来界定都市区范围。
研究表明,都市圈这一概念着重强调区域间的经济社会联系。早期研究中采用的非农化或城镇化等宏观经济指标则注重于区域本身的属性划分,无法完全体现区域间的关系。居民通勤作为城市居民活动的必要组成部分,能反映大城市郊区化发展及人口外迁所导致的出行空间变化,是区域间经济社会联系的直观体现。张沛[1]等在研究中指出,通勤率仍是都市圈范围界定中最为合理的指标。与此同时,我国自上世纪八十年代起逐步开始进行大城市居民出行调查,这一举措为利用通勤数据进行都市圈范围界定的研究提供了有利条件。但调查周期长,人工成本高等固有问题使调查数据的时效性与准确性难以保证。
近年来,随着大数据技术的广泛应用,通过手机信令数据、交通刷卡数据等对居民通勤问题展开研究已成为现实。Jiangping Zhou[4]等利用刷卡数据对北京市小汽车和公交的通勤效率进行对比分析。有保障的数据来源与不断突破的挖掘技术为都市圈区域划分及层级结构研究提供了新方向。王德[5]等利用手机信令数据识别用户居住地与工作地,根据区域间的通勤联系对上海都市区的边界及区域划分展开研究。随着共享经济和网约出行的发展,顺风车服务凭借其便捷、经济、舒适等优点,在高峰期间主要用于居民通勤出行[6]。与传统出租车与专快车相比,顺风车可以提供跨区乃至跨城市的出行服务,且随着服务范围增加,有利于获得更加全面的区域间联系的数据,为开展都市圈相关研究提供了必要的数据支撑。与手机信令数据相比,顺风车出行数据可以提供更加直观、全过程、全信息的通勤数据,更有利于区域间通勤联系的直接获取。
本文利用京津冀地区网约顺风车订单数据与POI 数据,使用基于网格的K-means++聚类方法对北京都市圈区域划分进行研究,确定北京都市圈功能区域范围。进一步使用层次聚类法,结合不同功能区域内通勤特征对北京都市圈层级结构展开研究。研究成果可为有关部门制定都市圈规划与管理政策提供依据。
1 数据及网格模型介绍
1.1 数据及来源
(1)顺风车订单数据
该数据字段包括订单编号、出发时间、到达时间、出发城市、到达城市、行程、费用等15个属性字段。提取京津冀市域范围内2017年5月-7月的网约顺风车订单数据,通过对数据的预处理及清洗得到共计1200余万条有效数据。
对订单行程距离进行统计分析后发现,居民出行距离分布如图1所示,出行距离的99%分位数为100 km,在后续研究中将京津冀范围内顺风车服务距离定义为100 km。对工作日与非工作日不同时间的订单数量统计如图2所示,发现顺风车在工作日6:00-10:00 与16:00-19:00 期间相较于非工作日同时段订单量剧增。
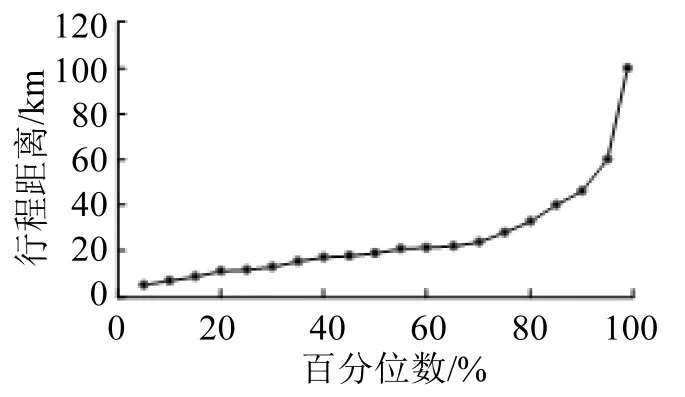
图1 行程距离百分位数分布图Fig.1 Travel distance percentile distribution
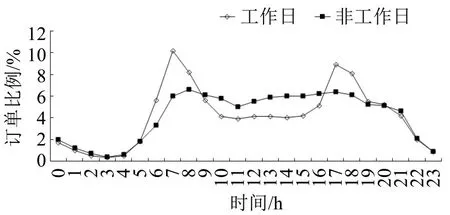
图2 工作日与非工作日订单量分布对比Fig.2 Comparison order volume distribution on workdays and weekend
(2)顺风车早高峰通勤特性
考虑到晚高峰期间居民出行目的多样化,如通勤、休闲、购物、娱乐等,故选用工作日早高峰期间顺风车订单数据,分析订单起点与终点的空间分布情况,得到订单起终点核密度图,如图3所示。
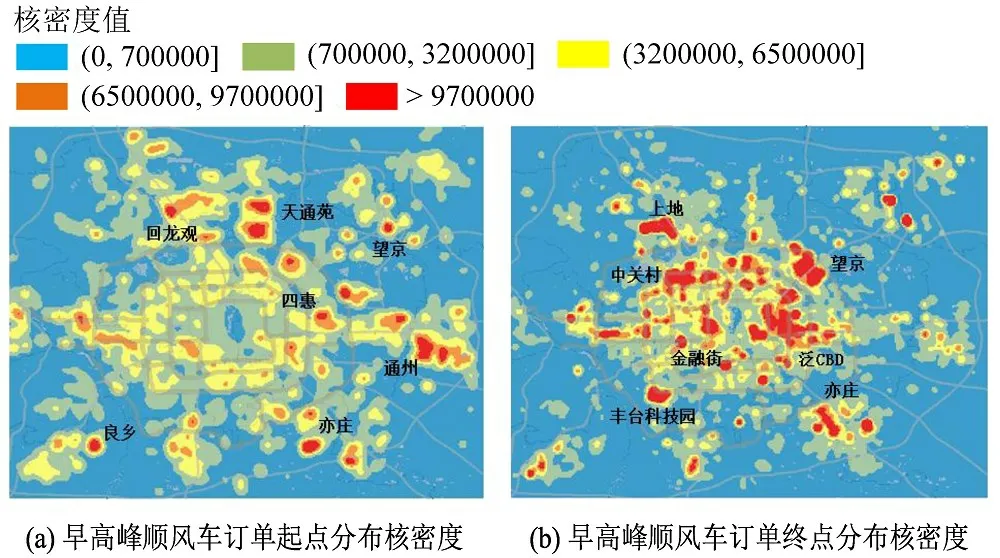
图3 顺风车订单数据起终点分布Fig.3 Distribution of density of departure and destination of carpooling data
从图3可以看出,早高峰期间顺风车订单数据起点主要集中在回龙观、天通苑、望京、四惠、通州、亦庄、良乡等区域,订单终点则主要集中在上地、望京、中关村、金融街、丰台科技园等区域,这些热点区域与北京市交通发展年报[7]中六环内主要居住地与就业地分布热点区域一致。因此,由早高峰订单起终点分布情况可以间接说明顺风车在早高峰期间主要用于通勤出行。
基于上述结果,假设顺风车通勤订单为起止时间均在工作日6:00-10:00 的订单,可以根据订单字段中的出发时间与到达时间,筛选两个时间戳均在工作日6:00-10:00 的顺风车订单,并作为通勤订单数据,用于后续研究。
(3)兴趣点数据
兴趣点(Point of Interes,POI)数据,指与居民日常生活相关的各类设施的信息点,包括住宅小区、公司企业、购物中心、娱乐场所等。企业与公司作为开展经济活动的主要场所,POI数据作为能够反映不同企业位置及数量分布的数据可以映射不同空间的经济活动强度。本文利用高德地图获取覆盖京津冀范围的12大类共计87万余条POI数据。
1.2 网格模型构建
为避免以往研究中以交通小区或行政区域为基本研究单元所导致的尺度不一、空间不连续等问题[8]。本文将研究区域划分为网格,采用空间网格作为标准研究单元,将数据映射到网格中,实现数据统一均衡分布,再结合土地利用属性确定都市圈内不同功能区域。
利用顺风车订单行程分布情况,设定本文研究区域,该区域要能够包含北京都市圈的可能范围。由前文可知,99%的顺风车订单行程小于100 km,故先以北京市区五环为边界,并向四周延伸100 km设定为研究区域,并将该区域划分为100×100个方形栅格,如图4所示。该范围将包含几乎全部顺风车订单,便于开展进一步研究。
图4 网格模型研究范围Fig.4 Research scope of grid model
将清洗后的顺风车订单数据匹配至网格中,由于初始研究区域范围选取较大,部分网格中的出行量极少。计算初始研究区域范围内每个网格中的早高峰均出行量,将日均出行量少于1次的网格定义为无效网格,并将其剔除,可以消除缺少数据的网格对后续聚类分析产生的影响,减少计算量。最终得到有效网格分布情况及其早高峰期间出行OD量分布如图5所示。图5中OD分布是顺风车数据在网格模型中的直观展示,可将获取的POI数据匹配至网格中,结合网格中多重数据属性,利用聚类算法确定北京都市圈具体范围。

图5 有效网格起讫点订单量分布Fig.5 Origin-destination order quantity distribution of valid grid
2 基于改进K-means++聚类算法的都市圈区域划分
2.1 聚类算法
以K-means 为代表的基于划分的聚类方法和以DBSCAN为代表的基于密度的聚类方法是当前利用交通大数据进行区域划分研究中最常用的两种方法。由于本文以每个网格作为数据点,同时包含位置、起讫点(OD)数量、POI信息等多重属性,而DBSCAN 算法在聚类过程中无法考虑多重数据属性,故本文结合复杂属性的K-means类算法进行网格聚类。K-means 聚类算法在实际应用中的主要问题在于需事先给定聚类数值k,且随机选取的聚类中心可能导致完全不同的聚类结果[9]。
(1)k值选取
在选取聚类数k值时用到的方法主要有手肘法和轮廓系数法:手肘法的判断依据是误差平方和(Sum of Squared Errors,SSE)。随着聚类数增加,每个簇的聚合程度会大幅增加,随之SSE的下降幅度较大。当聚类数增大到真实类别数目后,k值增加将不会显著提高聚合程度,SSE 下降幅度也会变小,随后趋于平缓。所以会在SSE-k图中形成下降趋势变缓,形似肘部的区域,该手肘部对应的k值即为恰当的聚类数。具体计算方法为
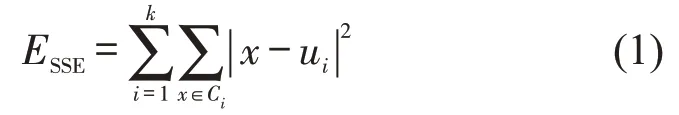
式中:Ci为第i个簇;x为Ci簇中的样本点;ui为簇Ci的质心。
轮廓系数法是通过对聚类合理程度进行有效度量来选择恰当的聚类数k值[10],计算公式为
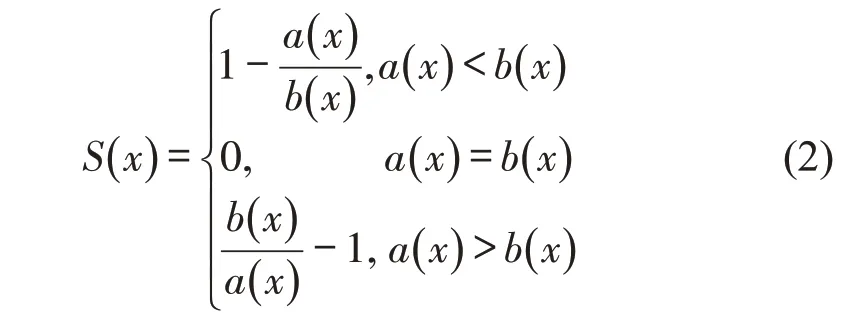
当k值分布较广时,单独使用手肘法会面临手肘部不明显,且会在多个位置出现肘部,无法准确判断聚类数k的情况;而单独使用轮廓系数法,会出现当与的值都比较大且,此时的轮廓系数S值可能会较大,但其实样本x与簇中其他样本距离较远,紧凑程度较低的情况,影响聚类效果。因此,结合使用手肘法与轮廓系数法,有利于选择恰当的聚类数k值。
(2)初始点选择
在初始点选择方面,K-means++聚类算法改进了传统K-means 中随机选取初始点的方式。它强调聚类中心间的距离尽可能的远,即假设已经选取了n个初始聚类中心,在选取第n+1 个聚类中心时,距离当前n个聚类中心越远的点会有更高的概率被选择。这种初始聚类中心选择方式能够显著改善聚类效果。
2.2 都市圈区域聚类划分
将获取的POI 数据匹配至筛选获得的有效网格中,每个网格中将包含网格所处位置、顺风车订单量所表征的通勤出行OD 量,以及POI 数据所反映的土地使用情况等三大类属性,部分样本数据如表1所示。
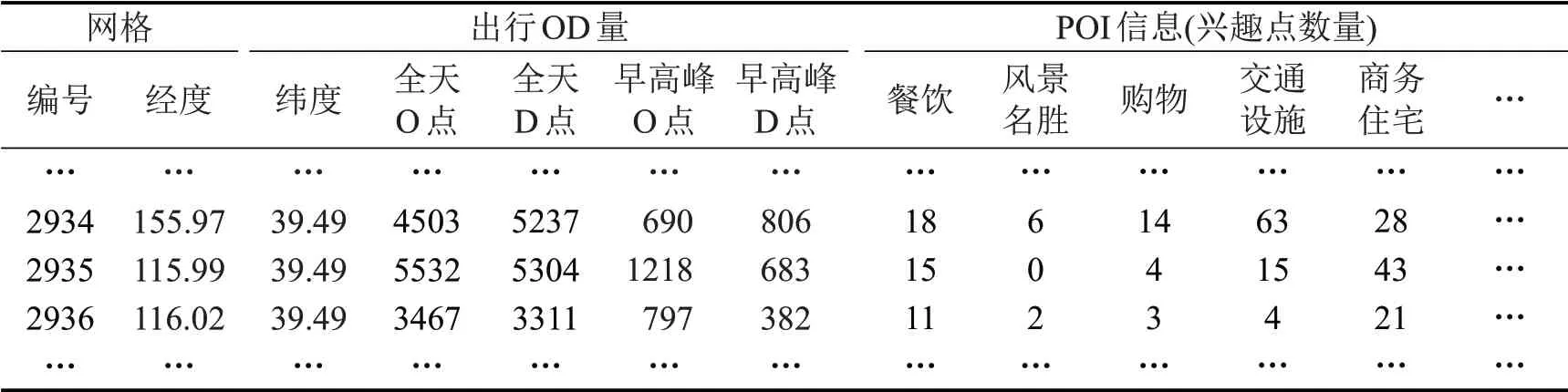
表1 聚类数据格式示例Table 1 Example of clustering data format
首先计算不同聚类数k值手肘法与轮廓系数法中关键指标参数。因网格数量较多且分布散乱,本文展示k取30~50时聚类效果明显的SSE与轮廓系数进行比选。结合前文分析,应当选取同时使得SSE 值处于手肘部且轮廓系数较大的k值,如图6中所示,最佳聚类数应为42。
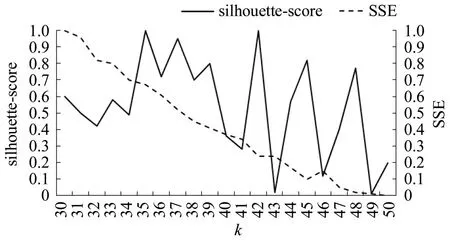
图6 不同k 值时两种系数的分布Fig.6 Distribution of two coefficients at different k values
使用基于网格的K-means++聚类算法得到对北京市都市圈范围内42类功能区。将早高峰期间目的地为北京中心区的出行量与该区域总出行量之比定义为通勤率,参考张沛[1]对都市圈范围界定研究中的结论,以出行量超过2000 同时通勤率大于5%为阈值进一步筛选,最终得到图7所示的19个北京都市圈主要功能区。值得注意的是,虽然天津市早高峰期间出行总量较多,有44万余条,但其通勤率不足5%,故未能被划分于北京都市圈功能区中。从宏观角度来看,天津市作为省级行政区域与直辖市,自身城市功能较为完善,可在区域范围更广的京津冀城市群有关研究中作为主要中心城市之一展开单独研究。
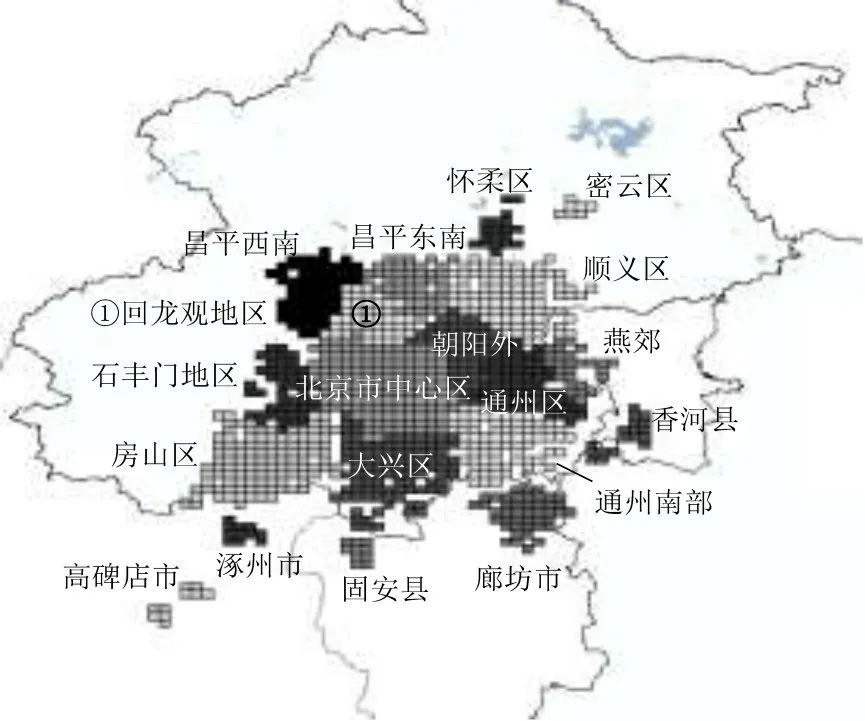
图7 北京都市圈功能区划分结果Fig.7 Result of functional area division of Beijing metropolitan area
功能区根据其与所在行政区域相对位置进行命名,但并不代表整个行政区域。图8为聚类功能区与现有行政区域对比,两者具有显著差异性,涿州市、廊坊市、香河县等一些行政划分不属于北京市的区域在联系度层面反而强于延庆区、平谷区等一些北京市郊区。因此在北京市城市及交通整体建设中,如果仅从自身行政区域角度进行规划设计是不够的,必须考虑北京都市圈影响范围进行统一规划,还需针对不同功能区域特性提出对应的发展方向。

图8 北京都市圈功能区与行政区划分对比Fig.8 Comparison of functional areas and administrative are as in Beijing metropolitan area
3 都市圈功能区通勤特征分析与层级结构研究
得到北京都市圈主要功能区域划分结果后,利用订单起止时间筛选到顺风车通勤订单数据,针对不同功能区的通勤强度、通勤时空分布特征、通勤可达性等特征进行分析,并利用其通勤特征属性围绕北京都市圈的层级结构划分开展相关研究。
3.1 基于功能区的通勤特征研究
(1)通勤强度
在研究功能区通勤强度时,定义功能区内早高峰期间的OD 数量为该功能区的通勤强度(Commuting Intensity,CI)指标,通勤强度的计算公式为

式中:ICI(A)为功能区A的通勤强度;OA为早高峰期间从功能区A出发的订单量;DA为早高峰期间到达A的订单数量。计算得到各个功能区的通勤强度ICI(单位:万辆)如图9所示。
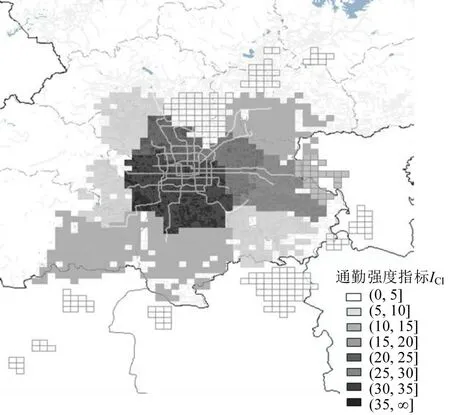
图9 功能区通勤强度指标分布Fig.9 Distribution of functional area commuting intensity
(2)区域独立性
除通勤强度指标外,还可以引入功能区独立性(Regional Independence,RI)表示功能区的通勤联系度。通过外来通勤率(External Commuting Rate,ECR)与外出通勤率(Outgoing Commuting Rate,OCR)分析某个功能区在早高峰期间与其他功能区之间的通勤联系,其计算公式为
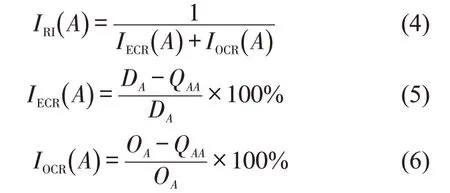
若某功能区的独立性高,则说明在早高峰期间其外出通勤与外来通勤都较少,该功能区具备较为完善且均衡的职住分布;若某功能区的独立性低,则说明其早高峰期间的外出通勤或外来通勤较高,该功能区可能是居住地主导的通勤发生地或商业发达的通勤吸引地,或是该区域职住分布不合理导致的无法就近就业。经计算得到各个功能区的独立性指标IRI如图10所示。
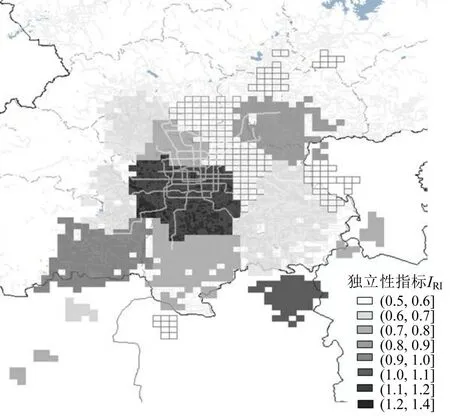
图10 功能区独立性指标分布Fig.10 Distribution of functional area regional independence
从图10 可以发现,北京中心区的通勤强度与独立性都较高,说明该区域内的综合功能较为齐全,既有大量的工作岗位,又能提供足够的居住环境,且该功能区内的居民倾向于在本区域内工作。其他功能区域随着与中心区之间距离增加,通勤强度在逐渐下降,结合功能区独立性指标可以将其原因归结为两方面:一方面是随着距离增加,部分距离北京市中心区较远的功能区域如廊坊、涿州、高碑店等,形成了独立发展的组团,其区域独立性较高,外出通勤与外来通勤需求都有所下降,且在本区域内使用顺风车通勤的意愿不强。另一方面是部分独立性较差的功能区域如朝阳外、回龙观、通州等,即使存在与其他区域尤其是北京中心区之间较多的通勤需求,但由于通勤时间和金钱成本的急剧增大,使得其与其他区域的通勤联系强度减弱。由于都市圈范围较大,城市轨道交通往往无法服务远郊层的居民,应当通过发展市郊铁路提高远郊层对都市圈中心层的可达性,为远郊层通勤客流提供快速、便捷、大运量的服务,将有利于推动都市圈的进一步快速发展。
(3)通勤时间
在研究功能区的通勤时空分布时,平均通勤时间能够直观反映功能区内居民通勤出行特征,统计各功能区早高峰期间出发订单的出行时间,得到功能区平均外出通勤时间为

式中:TA为早高峰期间从功能区A出发订单的平均通勤时间;NA为早高峰期间从功能区A出发的所有通勤订单量;tn为第n条订单的通勤时间。图11 为计算得到的各功能区早高峰期间的平均外出通勤时间。
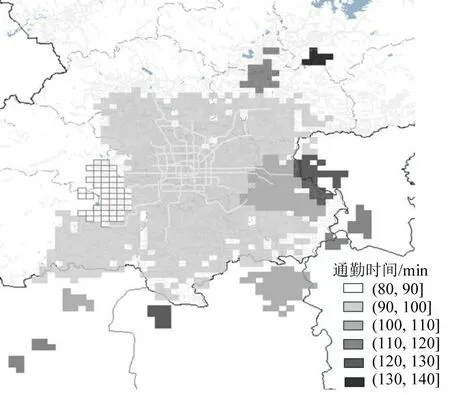
图11 功能区通勤时间分布Fig.11 Distribution of commuting time based on functional area
从图11可以发现,早高峰期间北京都市圈内顺风车平均通勤时长超过80 min,绝大多数功能区的外出通勤时间在120 min以内,密云、平谷、燕郊、怀柔、固安等部分功能区的通勤时间较长,超过2 h。
(4)可达性
可达性指从某个区域到达另一区域的容易程度,根据不同标准和计算方法,可达性分为多种类型。累积机会法也称等时间线法和等值线法,使用一定阈值内能够到达活动点的数量表示可达性,该值越大表示可达性越高。
在研究功能区的可达性时,利用划分好的功能区之间的通勤量OD矩阵及其通勤时间信息,采用累积机会法计算不同功能区的通勤可达性,即
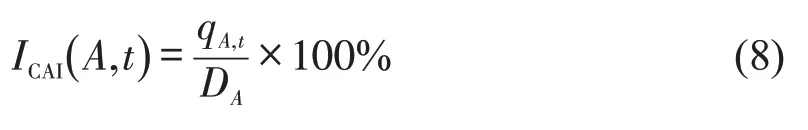
计算每个功能区内的通勤指标,并进行min-max标准化处理,得到结果如表2所示。
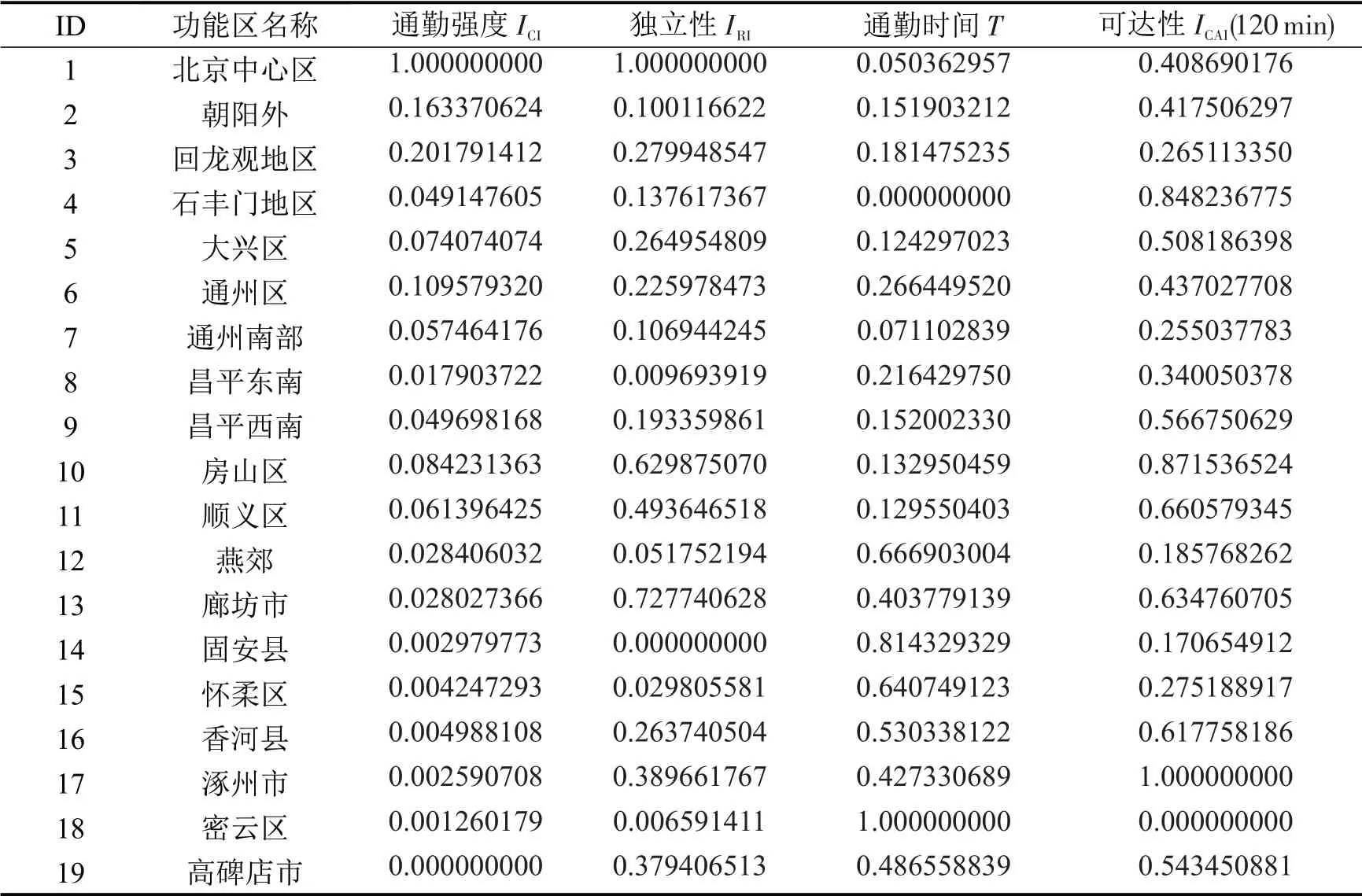
表2 用于层次聚类的通勤特征指标Table 2 Commuting characteristic index for hierarchical clustering
3.2 基于凝聚式层次聚类的都市圈层级结构划分
都市圈功能区内的通勤特征指标不仅可以反映都市圈的通勤特征现状,还可以用于都市圈层级结构划分。根据功能区的通勤特征差异性可以将其划分为不同类别,不同类别的功能区构成了都市圈的层级结构。本文针对已有的19 个功能区,选取凝聚式层次聚类方法结合其通勤特征进行层次聚类,分析不同功能区在都市圈中的层级位置。
凝聚式层次聚类算法将每个对象作为一个类,然后将这些类合并为越来越大的类,直至所有对象都在同一个类中或满足某种终止条件,其算法流程如下。
Step 1 将每个对象看作一类,计算两两之间的最小距离;
Step 2 将距离最小的两个类合并成一个新类;
Step 3 重新计算新类与所有类之间的距离;
Step 4 重复Step 2 和Step 3,直到所有类合并成一类或达到某个结束条件。
当每一类中只包含一个单独功能区时,类之间的距离为

式中:D(x),y指x与y两个类之间的距离;xn和yn分别为类x与y之间的第n个特征变量。
当一类中包含多个功能区时,以属于不同类中的两两功能区之间欧氏距离的均值作为两类的距离,计算公式为

式中:A,B,C,E为4个不同的功能区。
结合不同功能区中的通勤特征变量,对北京市都市圈19 个功能区进行凝聚式层次聚类,得到的聚类结果如图12所示。

图12 层次聚类结果树状图Fig.12 Dendrogram of hierarchical clustering results
图12 清晰地显示了层次聚类过程:当设置最终聚类数量为2 类时,如图中最右侧虚线所示,北京中心区被单独划分为一类,剩余所有功能区归为一类;当最终聚类数为3时,如图中间虚线所示,北京中心区为一类,燕郊、怀柔区、固安县、密云区为一类,剩下所有功能区为一类;当最终聚类数为4类时,如图中最左侧虚线所示,所有功能区被划分为4 个组团,北京中心区为一类,燕郊、怀柔区、固安县、密云区(组团1)为一类,房山区、顺义区、廊坊市、香河县、高碑店市、涿州市(组团2)为一类,通州南部、昌平东南、大兴区、昌平西南、通州区、朝阳外、回龙观地区、石丰门地区(组团3)为一类。
根据功能区的特征变量及聚类结果可以发现,北京中心区由于其通勤强度高、可达性优异,在聚类过程中始终单独属于一类,故在进行都市圈层级划分时,应当将其定义为都市圈核心层;在划分为4类时,得到了3类特征明显的组团,组团1和组团2都与北京中心区距离较远,组团3距离北京中心区较近,可将组团1 与组团2 合并作为北京都市圈的外层,组团3定义为北京都市圈的中层。
结合聚类分析结果与不同功能区地理区位特征,可以将北京都市圈划分为如图13所示的3个层级:北京中心区为核心层;由组团2 内的功能区构成的第二层级——近郊层;由组团1 和组团2 内功能区共同构成的第三层级——远郊层。结合不同圈层的通勤指标特征,可对相关功能区的后续发展规划提供参考,例如通过建设市域或市郊轨道交通解决远郊层面临的通勤困境,增强与其他区域间的通勤联系,有助于都市圈的良性发展。
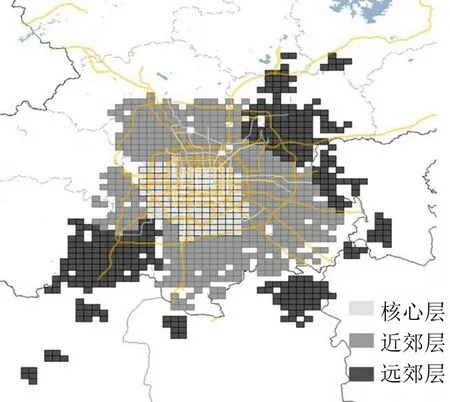
图13 北京都市圈三级层级结构Fig.13 Three level hierarchical structure of Beijing metropolitan area
4 结论
本文以京津冀区域为研究对象,基于顺风车订单数据与城市POI数据,使用聚类算法实现北京都市圈主要功能区域界定、层级结构划分。本文方法有效划分了北京都市圈的19 个主要功能区域及3级圈层结构。结果表明,功能区与现有行政区域划分具有差异性,在未来规划建设中,应当围绕都市圈功能区域划分与圈层结构进行综合规划,破除行政边界对都市圈基础设施建设与通勤交通发展的束缚;提高都市圈核心层与外围圈层之间的通勤可达性是促进都市圈发展的关键任务。由于都市圈范围内的通勤方式多样且数据难以全部获取,本文只采用和分析了顺风车订单数据,对功能区筛选条件也比较简单,后续可融合多源数据对都市圈的区域划分进行更加深入的研究。
