基于随机森林的矿压预测方法
2021-08-26冀汶莉刘艺欣
冀汶莉,刘艺欣,柴 敬,王 斌
1. 西安科技大学 通信与信息工程学院,陕西 西安 710054;2. 西安科技大学 西部矿井开采及灾害防治教育部重点实验室,陕西 西安 710054;3. 西安科技大学 能源学院,陕西 西安 710054 )
煤炭一直以来都是我国的主体能源。随着煤矿开采深度和强度的加大,煤壁片帮、支架“压死”、地表坍塌等矿压显现愈加剧烈,制约着矿井的安全高效生产[1-2]。工作面来压直接影响了安全生产,其中来压步距和强度是其重要特征,因此工作面来压的准确预测对于指导煤矿安全高效生产有着重要意义[3-6]。
国内外学者从不同的角度研究了矿压显现的预测方法,第一类是基于统计学与数值模拟等数学方法的矿压显现预测研究。霍丙杰[7]等依据不同开采因素对矿压显现的定量影响关系,利用模糊数学理论建立了坚硬顶板煤层矿压显现分级预测模型,可在工作面开采前较准确地评估开采过程中矿压显现强度的等级;张通[8]等采用回归分析和概率统计的方法,结合浅埋工作面现场实测矿压数据分析工作面覆岩硬度指数、工作面长度、开采高度及埋深与工作面矿压显现之间的非线性关系,并估算出工作面矿压最大值、初次及周期来压步距等信息;金宝圣[9]等利用现场实测及数值模拟的方法对麻家梁矿的顶板破断特征进行研究,得出的来压步距与现场实测数据基本一致。这类方法计算得出的矿压显现强度及来压步距等参数,只是在工作面开采前宏观评估矿压显现的强度及来压步距的范围,在实际开采过程中来压位置或来压步距则随工作面的推进而动态变化。因此,上述方法并非真正意义上的工作面矿压预测。
第二类是基于矿压监测系统产生的监测数据,利用机器学习或深度学习等智能算法进行矿压预测研究[10]。赵毅鑫[11]等运用长短时记忆网络( LSTM )深度学习方法建立了矿压预测模型,较为准确地预测了红庆河大采高工作面矿山压力,由于只选取位于工作面中间位置的支架压力数据,未全面反映不同支架的压力数据和矿压显现之间的非线性关系。随着新技术的发展,分布式感测技术被引入矿山围岩变形监测及矿压显现的研究中,柴敬[12-13]等将分布式光纤传感系统应用于煤层采动过程中覆岩变形监测及来压判别,定义了光纤频移平均变化度的概念,通过光纤频移平均变化度的经验阈值判别工作面矿压的发生情况;并在此基础上,引入混沌理论,采用XGBoost算法建立矿压显现预测模型,取得了一定的效果,但此方法只能预测未来的光纤频移平均变化度,仍需以经验阈值进行来压判别。综上可知,目前光纤传感技术在矿山围岩监测中的应用仍处于现场应用研究阶段,将分布式光纤用于工作面矿压监测及预测还处于实验室和理论研究阶段,未见实际的工程应用[14]。
笔者以相似材料物理模拟试验中分布式光纤监测数据为数据源,引入多步逆向云变换( MBCTSR ),并利用机器学习算法中的随机森林( Random Forest,RF ),建立MBCT-SR-RF工作面来压位置预测模型,对相似物理模型试验工作面开采过程中的来压位置进行预测。
1 试验背景与矿压分析
1.1 试验背景与光纤频移值
以千秋煤矿工作面上覆岩层的实际组成为原型,利用相似材料模拟搭建了工作面及上覆岩层的三维立体物理模型,模型的相似比为1∶400,尺寸为360 cm×200 cm×200 cm,模拟单个工作面长度为60 cm,煤层厚度为6 cm,上覆岩层厚度为174 cm。三维立体模型如图1( a )所示。在相似材料物理模型搭建的过程中,沿工作面开采方向在模 型的120,180,240 cm处的上覆岩层内布设了3根垂直光纤FV1,FV2和FV3,垂直光纤的分布如图1( b )所示。每根垂直光纤上可以获得174个监测位置的数据。

图1 相似材料物理模型组成 Fig. 1 Physical model composition diagram of similar materials
模拟煤层厚度为6 cm,模拟工作面开挖步距为4 cm,共计开挖60次,推进距离为240 cm。在开挖过程中,光纤监测系统采集3根垂直光纤上所有测点的监测值。为了表征岩体的变形情况,定义了光纤频移值的概念[15],表达式为

通过物理模拟试验,研究光纤频移值与工作面周期来压之间的表征关系。
1.2 工作面矿压观测及分析
在模拟试验过程中工作面共出现了1次初次来压和15次周期来压,记录每次来压的位置和来压步距等试验数据,见表1。

表1 三维立体模型试验矿压观测数据 Table 1 Three-dimensional model test rock pressure observation data
假设在物理模型试验中单根垂直光纤上有n个光纤传感器测点,在工作面第i次开采时可得到当前垂直光纤上每个监测点的光纤频移值集合表示当前垂直光纤上的监测点总数。每根垂直光纤在整个开采周期内产生60组Xi,频移值集合记为U,则。三维立体模型内铺设有3根垂直光纤,将垂直光纤获得的频移数据集记为D,则
研究表明光纤频移值可以表征上覆岩层的变形、破断及垮落的状态[15-16],而工作面周期来压的发生与上覆岩层的变形状态有直接关系,光纤频移值可以用来表征工作面初次来压和周期来压的发生。定义分布式光纤频移平均变化度的概念来反映工作面来压的发生情况[17],表达式为

式中,Dx为工作面推进x距离时光纤频移平均变化度;n为某根光纤传感器上所有传感器测点个数。
因此,可以通过光纤平均频移变化度的经验阈值判定周期来压的发生情况。
上覆岩层中垂直光纤不同测点的光纤频移值蕴含了与工作面矿压显现的相关信息,即光纤频移值与工作面周期来压之间具有复杂的非线性关系。机器学习算法可以很好地表达这种复杂非线性关系。因此,本文提出基于随机森林的工作面来压位置预测模型。
2 基于随机森林的工作面来压位置预测模型
2.1 随机森林算法
随机森林算法是BREIMAN L[18]在2001年提出的以决策树为基分类器的集成学习算法,其能够处理分类和回归问题。RF在训练阶段,使用自助法重采样( Bootstrap )技术从输入训练数据集中采集多个不同的子训练数据集来依次训练多个不同决策树,将这些决策树拟合到数据集的各个子样本上。在预测阶段,通过计算随机森林内部决策树的预测结果的平均值得到最终预测值,以提高预测的准确性。在训练过程中等价于式( 3 )的优化问题[19]。

式中,G为决策树的平方误差和;lc为决策树终端叶子节点的预测值;yi为数据集中第i个样本的输出值。
随机森林回归算法流程如图2所示,算法的实现流程如下:

图2 随机森林算法训练流程 Fig. 2 Training flowchart of random forest algorithm
( 1 ) 通过Bootstrap重采样方法从原始样本集X中有放回地抽取ntree个样本,作为训练数据集;
( 2 ) 对抽取到的ntree个样本分别生成对应的ntree个回归决策树模型;
( 3 ) 设样本集X包含M个特征属性,从M个属性中随机选取m个属性作为子集(m<M),根据最小Ginni系数原则从这个子集中选取最优属性作为分裂变量;
( 4 ) 重复步骤( 1 )~( 3 ),建立多个决策回归树组成随机森林,分别利用ntree个回归决策树进行回归预测。将新样本数据输入随机森林,并取每个决策树预测结果的平均值作为最终的预测结果。
2.2 工作面来压预测的特征提取
2.2.1 垂直光纤的加权频移平均变化度
光纤频移平均变化度忽略了工作面上覆岩层具有不同的岩性,随着工作面的推进,不同岩层变形状态不一致,对工作面周期来压的影响程度也各不相同。为了更准确地表达不同岩层变形对工作面周期来压的影响,定义光纤加权频移平均变化度xV,表达式为
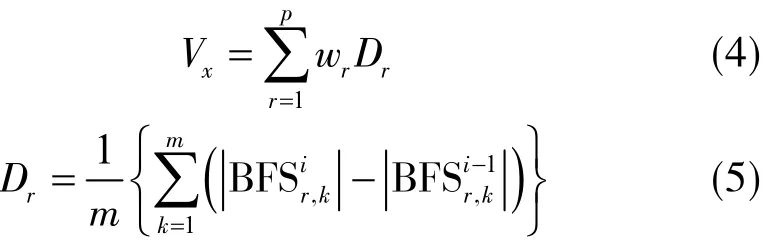
式中,Vx为工作面推进至x距离时光纤加权频移平均变化度;p为上覆岩层的层数;wr为权重系数,表示第r层覆岩变形对矿压显现的影响程度;Dr为光纤测点所在第r层的光纤频移平均变化度;为第r层内第k个光纤测点在第i次开挖时的频移值;m为第r层覆岩内光纤的监测点个数。
根据相似物理模型的配比,将工作面上覆岩层分为5类,对应物理模型的1~16,35~96,160~174 cm为软弱岩层,17~34 cm为亚关键层,97~159 cm为关键层。按照各层所在模型高度从上至下将岩层依次标记为1~5。采用极端随机树( Etra-Trees )[20]模型计算5类岩层中埋设光纤的频移变化度的权重系数rw。该模型的输入为工作面开采过程中获得第r层内光纤频移值的算术平均值,即,输出为当前时刻工作面的矿压发生情况,用“1”表示有周期来压发生,“0”表示无周期来压发生,权重系数wr在随机数迭代优化过程中计算得出。采用Etra-Trees模型对三维立体模型试验中的训练部分历史数据进行计算,得到权重系数训练集的数据,见表2。

表2 训练部分数据得到各岩层内频移平均 变化度的权重系数 Table 2 Weight distribution of the average change degree of the frequency shift within calculated from the training data
由表2可知,3根垂直光纤对应的不同权重系数反映了开采过程中不同岩层变形对工作面周期来压发生的影响程度。其中FV1垂直光纤离开切眼最近,也是最先监测到第1层岩石的垮落,即第1层覆岩变形对工作面周期来压的影响最大,权重也最大;而第4层关键层和第2层亚关键层的权重次之,说明该层内岩石变形对周期来压的影响也较大;岩层最上方的软弱岩层即第5层的权重最小,岩石变形对周期来压的影响最小。FV2垂直光纤位于整个开采工作面的中部,其经历了岩石多种形态的变形过程,因此整体上对工作面来压的影响高于第1和第3根光纤,且各层权重的均值比其他2根大。而FV3垂直光纤的位置接近工作面开采的结束部位,对工作面来压影响最大的是关键层。由此可知,利用Etra-Trees模型得到的计算结果符合物理模拟试验的相关结论。
考虑到模型预测的有效性和准确性,笔者同时采用三维立体模型试验的全部历史数据进行了光纤频移平均变化度的权重系数的计算,计算结果见表3。 训练部分数据与全部历史数据得到的各岩层内频移平均变化度的权重系数偏差,见表4。

表3 全部历史数据得到各岩层内频移平均 变化度的权重系数 Table 3 Weight distribution of the average change degree of frequency shift within each rock layer calculated from all historical data
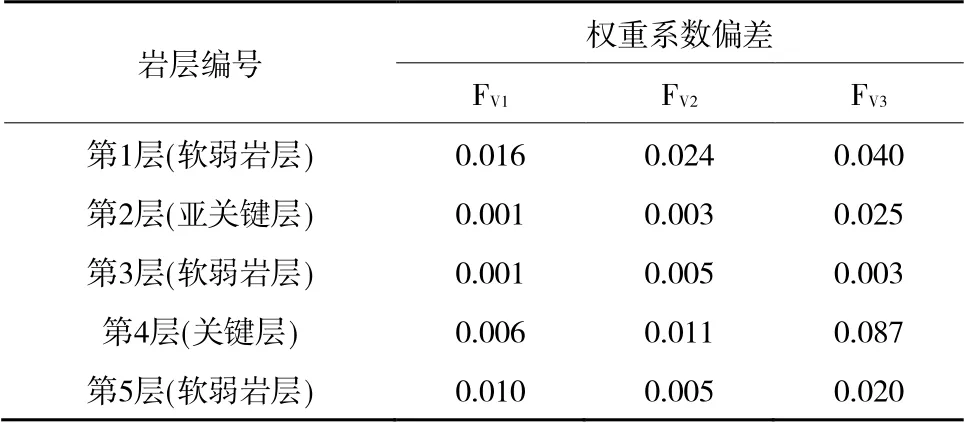
表4 不同数据集光纤频移平均变化度的权重系数偏差 Table 4 Error of fiber weighted frequency shift average change degree on different data-sets
由表4可知,训练集部分光纤监测数据与全部光纤监测数据得到的频移平均变化度的权重系数偏差均在0.087以内,说明训练集和测试集对应岩层权重系数的分布是一致的。因此,可以使用训练数据获得的权重系数处理光纤频移值,得到加权频移平均变化度,进而构建预测模型的输入样本是可行的。
2.2.2 垂直光纤频移值的统计特征
数据集的统计特征在宏观上反映了数据的真实变化情况,通过1.2节分析可知,3根垂直光纤所有测点在某一次工作面推进时会产生3个独立的数据集U,U中每一个数据子集i X都具有独立的统计特性。在机器学习中数据集的统计特性可以作为样本重要的特征属性,为了更准确地描述每根光纤在工作面开挖时产生的频移数据的统计特征,引入多步逆向云变换算法( Multi-step backward cloud transformation algorithm based on sampling with replacement,MBCT-SR )[21],该算法为基于云模型理论计算Ex,En,He的改进方法[22-23]。
MBCT-SR算法的计算步骤如下:

Step2:对光纤频移数据集Xi进行随机可重复的抽样,每次抽取r个数据为一组,共抽取m组( 其中m,r∈N+,m和r的乘积不一定等于n),形成新的子集,并计算每组数据集的期望,计算公式为


2.3 工作面矿压位置预测模型的构建
预测模型整体流程框架如图3所示,模型构建的主要步骤如下:

图3 工作面矿压预测模型整体流程 Fig. 3 Overall flow chart of mine pressure of working face prediction mode
( 1 ) 数据预处理
数据预处理是模型训练的基础,为保证预测结果的准确性,需要对原始频移数据进行预处理,包括去除噪声和数据清洗。采用小波去噪的方法去除频移数据的噪声。数据清洗包含缺失值填补和异常数据去除,采用邻近均值法,根据相关性分析确定离缺失值或异常数据最近样本,对其计算加权平均值来代替异常值或缺失值。同时为减小不同值域数据样本特征对模型训练的影响,通过差分归一化方法将数据转换成均值为0,标准差为1的形式。
( 2 ) SMOTE数据增强
由于相似物理模拟试验采集到的光纤频移样本数据有限,为提高模型的预测精度,采用SMOTE( Synthetic Minority Over-sampling Technique )算法对光纤频移时间序列数据进行数据增强。通过SMOTE提高样本容量,从而提高模型的预测精度。
( 3 ) 样本数据特征值提取
采用光纤加权频移平均变化度作为工作面来压位置预测方法的输入样本特征。采用3根垂直光纤在第i次开采时全测点频移值集合的期望Ex、熵En和超熵He,作为工作面来压位置预测方法的输入特征。
( 4 ) 工作面来压位置预测模型的构建
将上述垂直光纤加权频移平均变化度,以及光纤频移数据的统计特征作为模型训练的输入样本,建立基于随机森林算法的矿压预测模型,模型输出为未来时刻工作面矿压发生位置,并评估模型的性能。
2.4 预测模型的评价指标
选用均方根误差RMSE( Root Mean Squares Error )、平均绝对误差MAE( Mean Absolute Error )和平均绝对百分比误差MAPE( Mean Absolute Percentage Error )作为预测模型性能的评价指标,计算公式为

式中,yi为实际值;为预测值;n为样本个数。
RMSE是回归预测中常用的评价指标,但易受异常值的影响。MAPE用来评估相对误差,降低了个别离群点带来的绝对误差影响。3个评价指标的值越小表示预测值与真实值之间的偏差越小,模型的预测性能越好。
3 仿真试验与结果分析
3.1 预测样本集构成
相似材料物理模型试验中,3根光纤各产生了60组不同测点的频移数据。在试验过程中发生了1次初次来压和15次周期来压,对应的周期来压位置见表1。构造的样本集见表5,其中1ˆEx,1ˆEn,1ˆHe为垂直光纤FV1全测点在工作面推进一次所获得的光纤频移数据的期望、熵和超熵的估计值;1xV为垂直光纤FV1频移值的加权频移平均变化度,垂直光纤FV2和FV3同理;Y表示模型输出,即未来时刻工作面来压发生的位置。

表5 样本集部分数据 Table 5 Partial data display of sample set
将样本数据集划分为训练集和测试集。3根垂直光纤上的测点产生的频移数据具有时间序列的特征,取前40次模拟开采获得的样本数据作为训练集进行预测模型的训练,并采用十折交叉法验证模型的有效性。利用训练好的模型,根据当前时刻测点频移值计算出输入样本就可以预测未来时刻周期矿压发生的位置。为了验证预测模型的有效性和准确性,将剩余20次模拟开采产生的数据作为测试集,与模拟试验中实际周期来压位置进行比较,评估预测模型的性能。
3.2 模型的参数设置
本文基于Python语言,使用scikit-learn库中Ensemble框架内的RandomForestRegressor. predict( )函数建立RF模型。RF算法在建模过程中首先需要设定2个参数,即决策树的数量n_estimators和每棵树的最大特征变量max_features。若n_eatimators太小容易导致模型欠拟合,太大则不能显著提升模型的性能。最大特征变量值max_features越小则随机森林中决策树的差异越大,导致模型产生过拟合而降低算法精度,最大特征变量值max_features越大则会降低模型的运算速度,一般情况下max_ features=2log( n_features ),n_features为样本集中特征向量的维度。
在RF训练过程中需要优化的2个参数为决策树最大深度max_depth和节点可分的最小样本数min_samples_split。
在训练过程中,对n_estimators,max_depth,min_samples_split等3个参数采用网格搜索方法进行寻优,即给定n_estimators的参数范围为[10,200],步长为10;max_depth和min_samples_split的参数范围为[1,10],步长为1。通过网格搜索遍历给定参数 后 得 到n_estimators=100,max_depth=4,min_ samples_split=2。
为验证预测模型的有效性,在相同试验环境和数据集条件下,分别采用BP神经网络、SVM支持向量机方法建立预测模型,与随机森林方法进行对比分析。SVM算法的核函数选取高斯径向基函数( RBF ),σ和惩罚因子C是影响SVM回归性能的2个重要参数,其中σ决定数据映射到在新特征空间的分布状态,不同取值会影响模型在测试集中的准确率;惩罚因子C能够平衡模型的逼近误差和复杂度,C越大越容易过拟合,越小则容易欠拟合,2种情况都会使模型的精度变差。在模型训练过程中对参数进行寻优后得到最优参数组合为σ=0.01,C=10。BP神经网络模型的激活函数选用relu,并通过模型的不断迭代确定最优的输入权重、输出权重和隐藏层连接的权重。
3.3 试验结果分析
根据RF,SVM,BP等3种学习算法的最优参数组合建立对应的预测模型,各模型训练集的预测结果如图4所示。

图4 工作面矿压位置训练集预测训练结果 Fig. 4 Prediction training results of mine pressure position training set in working face
由图4( a )可知,在模型训练阶段,没有打乱训练样本数据集时,BP,SVM和RF模型的拟合能力都较差。3个预测学习曲线在第15次和第22次开采时都出现了向下的尖峰,而对应位置的真实曲线是水平的,特别是SVM模型在整个模型训练阶段的预测结果与真实值之间的偏差较大,总体来看出现预测值在真实曲线上下波动的情况,说明模型对数据样本的学习不够彻底。为了在模型训练过程中消除数据之间的相关性,减少模型的过拟合,在训练过程中打乱了训练集顺序。由图4( b )可知,在打乱训练样本数据集后,模型较全面地学习了训练样本输入和输出之间复杂的非线性关系,BP,SVM和RF模型的预测精度均得到了提升,且均能较好地拟合真实值。但相对来说SVM的学习表现最差,在第3,12,29和36次都有较大的误差,而这些点均与前一次样本数据间存在较大的数据落差。表6为3种预测模型在训练阶段的各项性能评估指标。

表6 不同预测模型训练集性能评价指标对比 Table 6 Comparison of performance evaluation indexes of different prediction model on training sets
由表6可知,无论是否打乱训练样本顺序,在训练集中3个模型的RMSE,MAE和MAPE均较小,但打乱训练样本顺序的训练模型性能更好。相较于BP和RF预测模型,SVM预测模型的总体误差相对较大,RF在训练阶段表现更优。
各模型测试集的预测结果如图5所示。

图5 工作面矿压位置测试集预测训练结果 Fig. 5 Prediction training results of mine pressure position test set in working face
由图5可知,在测试集中BP神经网络模型、SVM支持向量机模型的预测值与真实值有较大的偏差。对于BP神经网络模型在第40,41,42,45,46,47,49次开采时的预测曲线与真实值的误差较大,原因为BP易陷入局部最优,在训练过程中出现了过拟合现象,导致预测模型在测试集中表现较差。对于SVM支持向量机模型在第40,41,42,48,49,52,53,57次预测值都与真实值有较大偏差。总体来看,在测试集中RF预测模型整体上与真实值之间的拟合效果最优,仅在第45,46,56,57次开采时预测值与真实值有一定偏差,原因为当开采工作临近结束时光纤频移值变化较为缓慢,导致预测效果不佳,但与BP神经网络模型、SVM模型在对应位置相比偏差更小,预测效果表现更优。
当利用历史监测数据生成的训练样本集完成预测模型的训练后,就可以用模型进行未来时刻工作面来压位置的预测。如,将第42次模拟开采时3根垂直光纤所获得的频移值,利用2.2节特征值提取方法计算得到输入样本;然后输入预测模型进行计算,输出结果是未来时刻发生周期来压的位置180.3 cm,与试验记录的真实值184 cm偏差为3.7 cm,可以认为预测有效。表7为预测过程中预测值与真实值的偏差。

表7 预测值与真实值的偏差 Table 7 Error between the predicted value and the true value
表8为测试集中各预测模型的性能评价指标。将3个预测模型的评价指标与表6中乱序训练集对应的指标相比,每个预测模型的性能评价指标变大,说明3种模型在测试集上的预测性能低于训练集。BP模型的各项指标显著大于乱序训练集,说明BP模型在训练阶段出现了过拟合现象,导致测试集的误差明显增大。SVM预测模型在测试集的RMSE显著低于BP模型,但MAE和MAPE值的大小与BP模型评估指标的值非常接近。RF预测模型在测试集中的评价指标均最小,表明RF预测模型的准确性和鲁棒性在3个预测模型中最优。

表8 不同预测模型测试集性能评价指标对比 Table 8 Comparison of performance evaluation indexes of different prediction models on test sets
3.4 工作面来压位置预测模型泛化能力分析
3.4.1 样本数据扩充后预测模型性能分析
笔者使用的数据样本属于小样本,为了提升预测效果及预测模型的普适性,使用SMOTE数据增强技术对原始数据进行了扩充,扩充后训练集为79个样本数据,测试集保持不变。
预测结果如图6所示,性能评价指标见表9。由图6和表9可知,当样本数据扩充后预测效果都有了进一步的提升,更加接近真实值。

图6 数据扩展后工作面来压位置预测测试结果 Fig. 6 Predictive results of pressing position on test data sets after data augmentation

表9 数据扩展后不同预测模型性能评价指标对比 Table 9 Comparison of performance evaluation used different prediction models after data augmentation
从表9中可以看出,3种预测方法的各项评价指标均低于未进行数据扩充的指标值,同时相比于其他2种预测模型,RF模型的性能指标也低于其他2个预测模型。说明在进行数据扩充后该预测模型有更优的表现和更准确的预测效果。
3.4.2 预测模型泛化能力分析
为研究MBCT-SR-RF工作面矿压位置预测模型的泛化能力,以内蒙古某矿工作面地质结构为原型搭建的相似材料模拟试验产生的光纤监测数据及工作面来压数据作为预测模型的数据源。物理模型内沿工作面开采方向布置3根垂直光纤,煤层厚4 cm,开挖步距为3 cm,共计开挖51步。
采用与前述相同的样本特征提取和样本集构造方法,共产生51个样本数据,其中前35个样本用于模型训练,后16个样本用于预测模型性能测试。3种预测模型的预测结果如图7所示,预测性能的评估指标见表10。

图7 内蒙古某矿模拟试验中工作面来压位置预测结果 Fig. 7 Predictive results of pressing position on test data sets by physical model based on Inner Mongolia mine
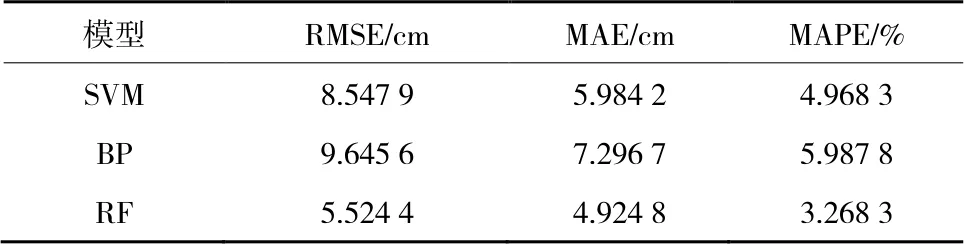
表10 预测模型性能评价指标对比 Table 10 Comparison of prediction performance indicators on test data sets
由图7可知,新测试集中BP神经网络模型和SVM支持向量机的预测值与真实曲线之间存在较大的偏差,RF随机森林预测模型的拟合效果最优,预测值与实际来压位置基本一致,表示模型预测性能稳定。由表10可知,RF随机森林预测模型的RMSE,MAE和MAPE值最小,说明RF随机森林的预测模型具有稳定的非线性拟合能力和较强的泛化能力,对于处理光纤频移数据与工作面来压之间的非线性关系,是一种简单、准确、稳定、可靠的方法。结合垂直光纤全测点频移值的期望、熵和超熵统计特征和光纤加权频移平均变化度作为输入样本,基于RF随机森林工作面矿压位置预测是一种有效的矿压预测方法。
4 结 论
( 1 ) 针对光纤加权频移平均变化度,采用随机森林算法,考虑了不同岩性和厚度的岩层对工作面矿压的影响程度,可以对工作面矿压进行预测。
( 2 ) 引入多步逆向云变换算法,提取了以期望、熵和超熵为重要属性的样本特征,融合光纤加权频移平均变化度形成了输入样本数据,提高了模型的预测性能。 ( 3 ) 将基于RF随机森林的预测模型与BP神经网络、SVM支持向量机预测方法在相同样本集下进行预测效果对比,MBCT-SR-RF预测模型具有较强的准确性、稳定性和泛化能力,适用于分布式光纤监测的矿压显现位置预测。
