省级地理信息公共服务平台数据融合方案研究
2021-08-25朱琳,占媛
朱 琳,占 媛
(1.安徽省基础测绘信息中心,安徽 合肥 230031)
安徽省地理信息公共服务平台的建设目的是促进地理信息资源的共享和高效利用,提高地理信息公共服务水平和能力。为进一步提升地理信息公共服务平台数据资源的丰富性,根据国家地理信息公共服务平台建设要求以及国家基础地理信息中心制定的《天地图数据融合技术要求(2020)》,并针对本地的数据特点,统筹利用各类测绘地理信息数据资源,进行国家、省、市级节点的数据融合,通过数据融合,提高地理信息公共服务平台数据的现势性,丰富数据内容,实现各级节点之间数据的优势互补,充分发挥公共服务平台分布式资源的节点作用,加强分布式资源节点的协同能力[1]。
数据融合是按照国家统一的数据模型和标准,利用最新的国家主节点数据、省级节点数据作为数据源,进行数据融合生产,形成优势互补、现势性高的地理信息公共服务平台数据集[2]。数据融合的对象主要有矢量数据、地名地址与兴趣点和影像数据三大类,其中矢量数据和地名地址与兴趣点数据融合处理是整个工作的主要内容和重点,需要根据融合数据源的特点,制定数据融合方案,对融合过程中的关键技术问题进行研究,并据此提出相应的对策,提高融合工作的效率。
1 数据源分析
融合数据源主要包括国家主节点和省级节点两类数据,其中国家主节点数据为国家基础地理信息中心下发的最新的主节点母库数据和导航数据,省级节点数据包括本年度更新的省级母库数据、基础测绘数据、地理国情数据、本地POI数据和影像数据,具体数据情况如表1所示。

表1 融合数据源情况
1.1 主节点数据分析
主节点数据为主节点母库数据和导航数据,主节点母库数据为2019年度融合成果数据,现势性为2019年,内容包括道路、铁路、水系、居民地、绿地、地理单元、基础设施和POI等要素。导航数据现势性为2020年,数据内容主要包括水系、交通、居民地及设施、植被、地名和POI等要素。其中,主节点母库数据中的地铁要素现势性好,且包含完整的省外接边数据。导航数据中道路数据信息较为丰富,道路模型完整。
1.2 省级节点数据分析
省级节点数据包括省级节点母库数据、基础测绘数据、地理国情监测数据、本地维护POI数据、在线更新POI数据和影像数据。省级节点母库数据主要包括矢量和POI两大类数据,矢量数据是在2019年度融合成果数据的基础上,利用影像数据对城市主城区范围进行了更新,现势性为2020年,数据内容全面,精度较高。POI数据范围为全省全覆盖,现势性为2020年。 基础测绘数据现势性为2019年,数据内容主要包括水系、交通、居民地及设施、境界与政区、植被等要素,要素内容详细,精度高。地理国情监测数据现势性为2019年,本次融合主要用到的是地理国情监测数据中的地理单元要素;本地维护POI数据为我省根据自身数据情况选择维护的政务类兴趣点,数据现势性为2020年。 在线更新POI为利用公众在互联网上提供的联动更新数据,经过官方审核通过后作为更新的数据源。
2 技术路线
2.1 基本原则
数据融合时,通过对参与融合的不同精度、不同模型地理数据进行分析比对,从中选取表达准确、现势性好、精度高、内容全的要素进行合并,并对合并后的结果进行几何拓扑、空间关系与逻辑一致性处理,使融合后的地理信息数据在现势性、准确性、丰富性等方面达到最优[3]。
2.2 技术路线
根据数据源的分析情况,设计了合理的数据融合总体技术路线,如图1所示。

图1 数据融合总体技术路线图
3 数据融合方法
3.1 矢量数据融合
3.1.1 数据源选择
矢量数据融合的数据源包括主节点母库数据、导航数据、省级节点母库数据、基础测绘数据和地理国情监测数据,按照数据融合选取原则及数据源分析成果,对参与融合的数据进行分类,确定好本底数据、新增数据和补充数据源[4]。具体数据源用途如表2所示。

表2 数据源用途
3.1.2 处理方法
按照融合的基本原则,对道路、铁路、水系、居民地、地理单元、基础设施进行融合处理,数据处理过程中实时叠加高清影像作为参考,如图2所示。
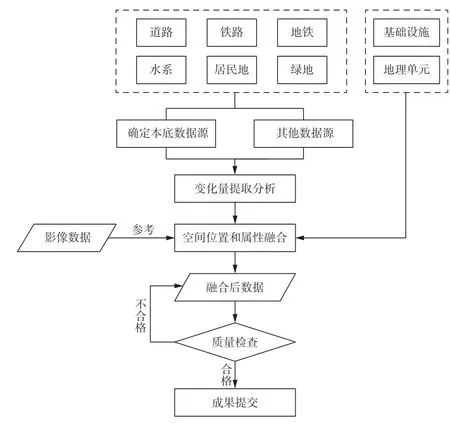
图2 矢量数据融合流程图
1)道路数据处理时,以省级节点母库数据中路网数据为本底,利用基础测绘数据、导航数据与省级节点数据变化对比结果,依据现势性、数据精确度、空间关系合理性等进行融合处理[5]。
2)铁路数据处理时,以省级节点母库数据为本底,导航数据、基础测绘数据作为补充数据源进行融合处理。
3)地铁数据处理时,以国家主节点母库数据为本底,充分结合各类数据源,保持地铁数据的信息完整。地铁站点捕捉在地铁线上,地铁站点及出入口应在地铁面状数据内。
4)水系数据处理时,对“新增”与“变化”数据进行处理,并进行属性融合,融合时以省级母库数据为本底,充分结合各类数据源,保持水系数据的信息完整,不应出现河流在桥梁处断开、线状河与面状河不相接等情况[6]。
5)居民地数据处理时,对“新增”与“变化”数据进行处理,并进行属性融合,融合时以省级母库数据为本底,充分结合各类数据源,尽可能详细地表示出单幢房屋或独立构建筑物等信息。
6)绿地数据处理时,以省级节点母库数据为本底,对“新增”与“变化”的数据进行处理,并进行属性融合,融合时以省级节点数据为本底,充分结合各类数据源,对城市绿地进行融合处理。
7)地理单元数据处理时,以国情监测数据为本底,按照融合技术要求提取数据。
8)基础设施数据的处理,以基础测绘数据库为本底,按照融合技术要求提取数据。
3.2 地名地址与POI融合
3.2.1 数据源选择
地名地址与POI的数据源包括安徽省导航POI、安徽省导航DM、安徽省母库、在线更新POI、省级本地维护POI和本底POI。按照数据融合选取原则及数据源分析成果,对参与融合的数据进行分类,确定好本底数据、替换数据和补充数据源。具体数据源用途如表3所示。
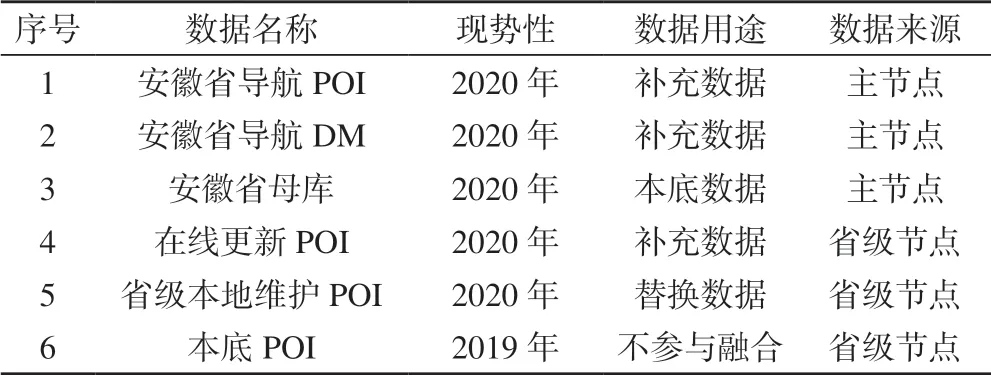
表3 数据源用途
3.2.2 处理方法
1)数据一致性处理。根据《天地图数据融合技术要求(2020)》要求,依据国家统一的数据模型和标准,对融合数据源进行一致性处理,使所有数据源的数据结构满足要求。
2)本地维护类别POI处理。首先选取省级本地维护、在线更新数据中的政务大类兴趣点数据作为融合数据源,并对其进行质量检查;然后以省级本地维护主数据源,在线更新数据为补充数据,对本地维护选取类别的兴趣点数据进行融合;对数据进行判重、去重处理;按照相关要求,对分类、简称、品牌词、重要度、标签等属性进行制作,最后进行质量检查。
3)数据融合。首先选取国家下发安徽省母库数据作为融合的本底数据,将省级本地维护数据及在线更新POI数据整体替换至安徽省母库数据中,然后将国家下发导航数据作为补充数据融合至更新后的安徽省母库数据中;对数据进行判重、去重处理,判重时优先保留顺序为:在线更新POI>省级本地维护数据>安徽省母库>安徽省导航数据。按照相关要求,对数据的分类、简称、品牌词、重要度、标签等属性进行制作,最后进行质量检查[7-10]。
4 主要技术问题研究
4.1 地理信息要素变化量提取
数据融合是将选取的各类数据源进行提取合并,在确定本底数据源后,需要将其他数据源与本底数据进行针对性的变化量提取,关于数据比对问题,由于全省的矢量数据条目数较多,如果只用人工方法进行比对分析的话,工作效率低而且难度大。因此在作业过程中开发了数据比对工具,利用工具加人工相结合的方法进行变化量提取。
数据的变化量提取,主要是对比数据和待比较数据的位置和属性,确定数据的变化情况,形成比对结果。比对过程中主要是通过同名字段确定同一对象的关联关系,在10m的分析半径内确定同一对象是否发生位置变化,用待比较字段确定同一对象是否发生属性变化,在比对结果中通过新增字段记录变化信息。新增“属性值变化”字段记录变化后的属性值,新增“属性变化”字段记录发生属性变化的字段,新增“变化类型”字段记录对象的变化类型。变化类型主要分为“新增”、“删除”、“图形变化”、“属性变化”、“图属变化”和“未变化”6种。数据比对工具主要设置参数有原始数据、参考数据、结果存放、分析半径、相似度阈值、同名字段和待比较字段等。
在进行道路数据变化量的分析比对中,以省级节点母库数据为本底,将最新的导航数据和基础测绘数据分别与省级节点母库数据进行分析比对,最后利用工具提取的变化量结果进行数据融合。该工具能有效提高数据分析比对效率,在多源数据的融合处理工作中具有重要意义。
4.2 水系要素显示级别定级
全省水系量众多,水系的类型级别和面积又各不相同,水系显示级别定级是为配图表达专门定义的,主要作用是确定该水系在地图上的哪一级别进行显示较为合理。天地图数据融合技术要求里没有具体说明水系面显示级别字段应如何赋值,可能是因为全国各地的水系情况不尽相同,没有做统一的赋值要求。
在水系显示级别属性赋值时按照天地图配图表达要求,同时参考省内水系的实际情况和配图表达效果,经过多次实验,确定了以面积为指标因素的面积指标赋值表,如表4所示。首先根据水系面积来填写水系显示级别值,然后再综合考虑收集到的水系的重要度信息和连通性因素来确定水系的最终显示级别。

表4 水系显示级别面积指标
4.3 地名地址与兴趣点判重
利用多源数据进行融合后地名地址与兴趣点数据可能会出现重复点的问题,即在一定距离内出现多个重复兴趣点,在兴趣点判重问题上,由于全省兴趣点条目数达一百余万条,人工逐个检查耗费时间过长,工作效率低而且很容易出现遗漏错误。因此为了提高兴趣点判重的工作效率,针对数据的特点开发了数据判重处理工具,主要方法是通过兴趣点的名称属性和点与点之间的距离来判断兴趣点的相似度。判重时将距离设置在半径100m内,然后通过工具计算出的相似度值来人工辅助进行判重,相似度在96%以上的认为是同名点,直接去重。相似度在78%~96%之间的需要人工辅助进行判重,若判断为同名点则直接去重,否则将其作为新增点融合到本底数据中。
5 结 语
本文针对安徽省地理信息公共服务平台融合数据源的特点,制定了数据融合技术路线,重点阐述了矢量数据和地名地址与兴趣点的融合方法,同时对数据融合过程中的关键技术进行分析和研究,并据此提出了相应的对策,提高了数据融合处理的工作效率,为我省今后开展数据融合更新工作奠定了良好的技术基础。通过数据融合,在提高数据现势性的同时,也丰富了数据的内容,从而进一步提高了安徽省地理信息公共服务平台对外提供地理信息服务的能力。
