基于本体的化学药物知识表示模型构建
2021-08-25秦璐徐倩胡超王安莉罗爱静
秦璐,徐倩,胡超,王安莉,罗爱静★
(1.中南大学湘雅三医院,湖南 长沙 410013;2.中南大学湘雅二医院,湖南 长沙 410013;3.中南大学生命科学学院,湖南 长沙 410013;4.中南大学大数据研究院,湖南 长沙 410083;5.医学信息研究湖南省普通高等学校重点实验室(中南大学),湖南 长沙 410013;6.移动医疗教育部-中国移动联合实验室,湖南 长沙 410013)
0 引言
在诊断和治疗环节中,药物信息是一个重要要素。药物研究不断创新,新药的种类不断增多,药物相互作用复杂。规模急速增长和内容纷繁复杂的药物信息需要信息领域的专业人员对其进行收集、存储、处理、分析等,进而从不同层次反映药物与不同实体间的相互关系。因此,对药物信息进行知识表示显得尤为重要。
本体(ontology)作为一种语义网技术,常用三元组表示两实体间的关系[1],可用于对特定领域中的概念及其相互关系进行形式化、规范化的描述[2-3],其明确性、共享性、形式化、重用性等特点,有利于知识推理[4]、提高异构系统互操作性[5]等,因而被广泛用于医疗领域的知识表示。
因此,本文拟基于本体的思想和方法构建符合中国应用场景的化学药物信息的知识表示模型,通过引入药物不良反应发生的频率,药物间的相互作用和配伍禁忌的详细关系,对患者群体进行划分等,较为细致地揭示了语义关系,用以支持药物数据的管理和整合。
1 研究现状
目前,国外已有许多药物知识表示研究成果。美国国家医学图书馆 (National Library of Medicine,NLM) 构建的统一医学语言系统(Unified Medical Language System,UMLS) 是一组文件和软件,汇集了许多卫生和生物医学词汇及标准[6];临床药物本体RxNorm,通过品牌名称、成分、剂型、剂量对通用药品和品牌药品进行规范化表示,支持药物术语和药学知识库系统之间的语义互操作,使得医院、药店等通过计算机系统能够高效、明确地传递与药物有关的信息[7]。《药物注册用医学术语词典》(MedDRA)是ICH 提供的一个单一的标准化国际医学术语,用于在医药产品开发周期(从临床试验到上市后)的所有阶段中,对与人类使用的药品有关的数据(如:注册、文档和安全等)的监管交流和评估[8]。DrugBank 从各个生物医学和制药数据库汇总了药物的化学、药理学、制药药物数据、药物靶点数据等信息,其广泛的药物和药物靶标数据使许多现有药物的发现和重新利用成为可能,以治疗罕见和新发现的疾病[9]。SIDER(Side Effect Resource)是从药物包装说明书中挖掘与上市药物不良反应相关的数据,包括药物适应证、不良反应发生频率、不良反应分类和药物-靶标关系的链接方面的数据[10]。国内常以字典形式的药物知识表示如:《中国药典》[11]《中国药典临床用药须知》[12]《中国药学大辞典》[13]《当代药品商品名与别名辞典》[14]等。
随着对本体研究的不断深入,国内外学者从不同针对点和侧重点丰富了对药物知识表示模型的研究。Liang C 等[15]、沈柳等[16]、康宏宇等[17]从基因组学或药理学的角度对药物知识进行表示,揭示了药物作用的内在机制;Grando A 等[18]、李梅等[3]、林鑫等[5]通过本体的方法对药物不良反应信息进行整合分析,从而减少药物不良事件的发生;Chen RC等[19]、Chen SM 等[20]、Wang M 等[21]通过对疾病、药物、患者及其相关概念和关系的拓展对药物知识模型进行构建,实现了安全用药推荐。
2 药物本体构建过程
本体已经得到广泛应用,常见的构建方法有七步法、骨架法、METHONTOLOGY 法、企业建模法等方法[22]。综合分析已有的药物领域本体构建思路,本文主要借鉴了斯坦福大学医学院开发的七步法,并利用protégé 工具构建化学药物本体。
2.1 本体数据来源
本文数据主要来源于《中国药典》和《中国药典临床用药须知》。《中国药典》通常是以药物化学成分为基本单元描述其相关信息,包括药物的中文名字、英文名、拼音、别名、性状、规格、贮藏、化学成分及组成等;《中国药典临床用药须知》记录了合理用药以及药物相互作用、使用禁忌等方面的内容。除此还利用药品说明书、抗菌药物临床应用相关指南、不同人群的用药指南、相关文献、百科知识等进行补充,并通过咨询专家对药物本体进行完善。构建流程如图1 所示。
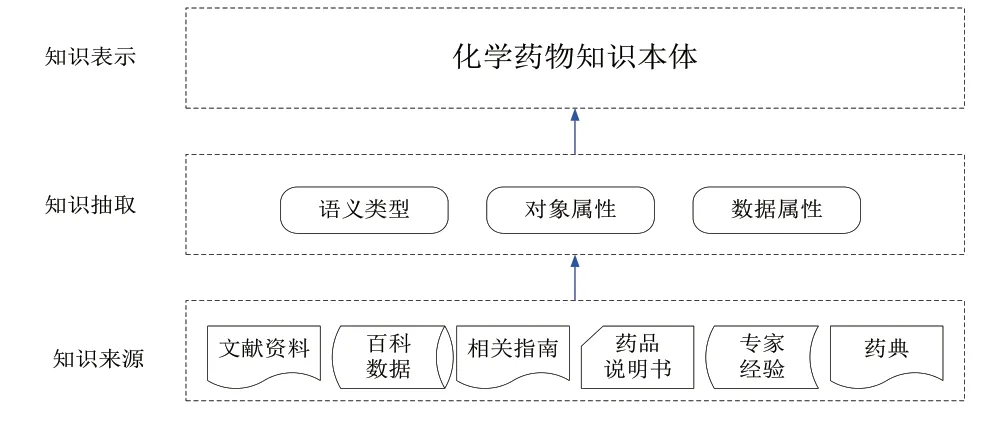
图1 化学药物知识本体构建过程
2.2 确定本体语义类型
2015 年版《中国药典临床用药须知》化学药和生物制品卷(以下简称《临床用药须知》)通常包括化学药物的适应证/禁忌证、不良反应的相关信息、药物的用法用量、药物与群体的适用关系。从以往的研究中也可以看出,对药物知识表示的语义类型通常涉及药物、疾病、用法用量、特殊群体,因此在这个基础上抽取5 个相关概念作为一级语义类型,分别为药物、化学成分、用法用量、疾病与临床表现、群体,见图2。

图2 化学药物本体一级语义类型
通过对《临床用药须知》以及药品说明书的内容进行分析,[用法用量]通常包含剂型、剂量、给药途径、用药频次、度量范围、饮食等信息。[适应证]、[禁忌]、[注意事项]中有对包含对疾病、症状、过敏患者用药等信息的描述。[孕妇及哺乳期妇女用药]、[老年用药]、[儿童用药]等反映了特殊群体的用药,除此之外,还有对肝功能或肾功能不全的患者的用药调整。结合相关文献,分析我国药物常用指南,确定了28 个二级语义类型。将最后确定的一级语义类型和二级语义类型在protégé 软件中构建,最后结果如图3 所示。

图3 protégé 构建化学药物本体语义类型
2.3 确定本体属性
在明确药物本体语义类型后需定义类的属性关系,即本体类的对象属性(object property)和数值属性(datatype property)。对象属性常用于描述类之间的关系,而数值属性是对概念的固有属性的一种描述[5]。
通过对《中国药典》(2015年版)及相关资料分析,确定“药物”的数据属性包括通用名、别名、英文名、拼音、性状、制剂、贮藏、国家药管平台YPID、ATC编码、医保通用名库编码,“化学成分”的数据属性包括化学名、分子式、化学结构。通过相关文献以及专家咨询,确定“群体”的数据类型包括体质、生活习性、职业、年龄范围、性别、情绪、生理状态、指标、单位、取值范围。对象属性的确定参考RxNorm、ULMS、TCMLs 等药物知识表达体系,确定了“用药操作”“成分”“不良反应”“相互作用”“配伍禁忌”“禁忌证”“适应证”“禁忌人群”“适应人群”9 个主要属性。其中,在《临床用药须知》中对[不良反应]的相关描述通常还记录了不良反应的发生频率;对于药物间的“相互作用”“配伍禁忌”“禁忌证”“适应证”等关系进行详细扩充,最终构建的20 个对象属性和23 个数据属性相关信息如表1 所示。

表1 化学药物本体的属性
3 添加实例
在protégé 中完成化学药物本体的构建后,可通过“individual”选项卡,添加实例。受篇幅限制,本研究拟通过添加抗菌药“阿莫西林胶囊(Amoxicillin Capsules)”的部分知识对该知识表示模型的重要部分进行演示。
“Data property assertions”是实例的数据属性。通过查询《中国药典》(2015 年版)等获取“阿莫西林胶囊”的数据属性,具体设置结果如图4 所示。

图4 “Amoxicillin_Capsules”的“Data property assertions”设置
“Types”指这个个体属于的类。通过对抗菌药“阿莫西林胶囊”相关信息的检索,获取其“FDA 孕妇危险等级”为“B 类”,即妊娠期患者有明确指征时需要慎用(未见到药物对胎儿的不良影响);“医保分类”为“甲类”,即全保类药物;“哺乳期用药危险等级”为“L1”,即该药哺乳期患者最安全,不会显著增加婴儿的副作用,对婴儿的危害甚微;“处方类别”为“处方药”,即必须由执业医师或执业助理医师处方后,才能够调配购买的药物;“抗菌药物临床应用分级”为“非限制使用级”,说明该药物在长期临床应用中证明安全、有效,对病原菌耐药性影响较小,价格相对较低的抗菌药物;“药物代谢类别”为“肝、肾代谢”。在“Types”中进行设置,具体情况如图5 所示。

图5 “Amoxicillin_Capsules”的“Types”设置
“Object property assertion”是对象属性声明,通过对象属性连接另一个个体,刻画两者之间的关系。图6 展示了部分“阿莫西林胶囊”及其相关实体间的关系设置,包括“适应证”“禁忌证”“不良反应”“相互作用”“配伍禁忌”“适应人群”以及“成分”等对象属性声明。

图6 “Amoxicillin_Capsules”的“Object property assertion”设置
由于不同“群体”的“用法用量”可能不一样,本文通过设置“患者1”和“患者2”两个个体对其进行揭示。图7 为“患者1”的属性设置。治疗年龄大于3 个月且体重<40kg 的儿童,用法用量为45mg/kg/日,每12h1 次,在患者无症状或已经获得细菌根除证据的时间之后,应继续治疗至少48~72h。

图7 “患者1”属性设置
图8 说明“患者2”是“肾功能不全”患者,若肾小球过滤率为10~30mL/min,其用法用量为0.5或0.25g/次,每12h1 次能达到治疗目的,在患者无症状或已经获得细菌根除证据的时间之后,应继续治疗至少48~72h。

图8 “患者2”属性设置
通过protégé 中的“OntoGraf”选项卡显示“阿莫西林胶囊”对不同群体“用法用量”的知识表示如图9 所示。

图9 不同群体“用法用量”的知识表示
4 结论
本研究针对我国药物数据信息特点,采用本体的思想和方法构建了化学药物知识表示模型,通过protégé 软件实现本体,并以“阿莫西林胶囊”为例,填充了部分相关信息,展示了构建的知识表示模型。本研究构建的化学药物知识表示模型引入了药物不良反应发生的频率,药物间的相互作用和配伍禁忌的详细关系,对患者群体进行划分等,较为细致地揭示了药物相关概念的语义关系。基于本体的方法可以用于共享和推理,帮助医生辅助用药和安全用药,为医生、患者等提供药物知识;还可以用于分析药物及药物相关实体间的信息,如分析药物的常用人群、常用用法用量的构成比、发生最多的不良反应以及不同人群、用法用量等因素与不良反应发生频率之间的关系。
在研究过程中还存在着一些不足,对一些权威的、应用广泛的药物及相关概念本体的映射不够,兼容性和协同性有待增强;语义类型及属性的提取受主观影响可能存在一些不准确的问题,模型的一致性、完整性和可操作性有待验证;对知识模型的展示不够完全,对“阿莫西林胶囊”的知识表示有部分预设的语义类型或属性不适用或不存在。今后的研究将针对以上的问题进行更多改进,要加强对药物及相关概念本体的映射,方便数据共享和系统的互操作性;通过专家咨询等方法,对模型进行多维度的检验,不断完善和改进,增加知识本体的覆盖面。
