基于中间表示规则替换的二进制翻译中间代码优化方法
2021-08-24庞建民
李 男,庞建民
(1. 战略支援部队信息工程大学, 河南 郑州 450001;2. 数学工程与先进计算国家重点实验室, 河南 郑州 450002)
二进制翻译技术[1-2]是作为程序等价变换工具产生并发展起来的,被定义为一种机器上的指令序列到另一种机器上指令序列的等价转换过程。它在丰富国产平台软件生态的过程中,发挥了重要作用。
二进制翻译按照实现方式主要包含静态翻译和动态翻译[3]。静态翻译采用的是一种先翻译后执行的“离线翻译”方式,实现了“一次翻译,多次执行”,其翻译过程与执行过程彼此独立,翻译时间不计入系统时间。动态翻译采用的是一种边翻译、边执行的“捆绑式”工作方式,可以实现多源到多目标的程序翻译,由于可以获得运行时信息,因此动态翻译能够解决静态翻译难以解决的动态地址发现和自修改代码的问题。但是,动态翻译本身需要占用部分系统时间。翻译优化问题一直是动态翻译的研究热点[4-6]。本文在不引起歧义的情况下,将待翻译二进制文件的生成平台称为源平台,将动态二进制翻译器运行的平台称本地平台或目标平台。
1 问题的提出
动态二进制翻译在实现多源到多目标的程序翻译过程中,为了屏蔽不同源平台间的硬件差异,引入了中间代码,可以将任何源平台的指令先转化成中间代码,再转化成目标平台指令。在中间代码生成过程中,动态二进制翻译采用了内存虚拟机制,借助临时变量和环境变量,将对源平台特定寄存器的访问操作转化为与寄存器无关的内存访问操作。临时变量用来暂存变量,一般使用tempX的形式来表示,例如temp0,temp1等;环境变量是一种全局变量,用来模拟源平台的CPU环境,负责将临时变量存储到本地内存,一般使用env的形式来表示。env有多种实现形式,例如X86平台对应的env数据结构如图1中的CPUX86State所示,其成员变量regs[CPU_NB_REGS]用来模拟X86平台的寄存器,此时常量CPU_NB_REGS=9。
图1 X86平台下的env结构
Fig.1 env structure on X86 platform
利用内存虚拟机制,二进制翻译器在处理与源平台寄存器有关的指令时,借助env将其转化成对本地内存空间的操作。图 2展示了X86平台的立即数加法被翻译到中间代码的过程。源平台第1条movl汇编指令是立即数传送指令,使用了通用寄存器eax,经过内存虚拟机制,被翻译为2条中间代码:第1条中间代码是movi_i32 temp0,S|0x1,表示将立即数0x1暂存于临时变量temp0中;第2条中间代码是st_i32 temp0 env,S|0x0,表示将temp0存储于由环境变量env和偏移量0指定的本地内存位置。由环境变量env与偏移量构成的虚拟内存位置等价表示了源平台的位置,实现了去源平台化,这就是内存虚拟的含义。

图2 立即数加法的翻译过程Fig.2 Translation process of immediate addition instruction
内存虚拟策略在屏蔽源平台硬件差异的同时,会带来中间代码的膨胀问题。在图 2的示例中,源平台的前2条指令被分别翻译为2条中间代码,第3条指令被翻译为6条中间代码。总的代码膨胀达到3.3倍。造成中间代码膨胀的原因在于中间代码生成机制依赖于频繁的内存模拟操作。
在针对中间代码优化的相关研究中,主要采用的方法有两类:第一类与后端冗余指令相关,文献[7]提出了线性扫描冗余ldM和stM指令的匹配删除算法来删除冗余指令;文献[8]引用活性分析技术对快速模拟器(Quick EMUlator, QEMU)[9]后端无内部互锁流水级的微处理器(Microprocessor without Interlocked Piped Stages, MIPS)冗余MOVE指令提出了删除算法。另一类方法与寄存器分配策略相关,文献[10]详细分析了QEMU下的寄存器管理机制,但并未提出自己的优化方案;文献[11]实现了X86平台到龙芯平台的寄存器映射,映射的寄存器范围限于源平台的eax、esp、ebp三个寄存器和龙芯平台的S4、S5、S6三个寄存器;文献[12]提出了一种在寄存器映射过程中进行裁剪的方法,借助裁剪函数实现了PowerPC平台到ALPHA平台的寄存器映射;文献[13]实现了X86平台下的8个通用寄存器向MIPS平台的映射;文献[14]提出一种基于优先级的动静结合寄存器映射优化算法,首先根据源平台寄存器的统计特征进行静态全局寄存器映射,然后通过获取基本块中间指令需求确定寄存器分配的优先级,进行动态寄存器分配。
基于上述研究,本文将特殊指令匹配与寄存器直接映射思想应用在二进制翻译中间代码的优化过程中,对造成中间代码膨胀的典型场景进行分析归纳,找出特定指令动作的组合,通过建立相应的映射规则,将内存虚拟表示转化为对本地寄存器的直接操作,从而提高翻译效率。
2 优化方法
2.1 中间表示函数
动态二进制翻译使用内存虚拟策略时,中间代码的生成是通过调用中间表示函数(序列)实现的,一次内存模拟操作需要调用一个中间表示函数序列,由多个中间表示函数的组合进行实现。例如,对于x86平台下的数据传送指令MOVIm,reg,内存虚拟机制会调用两条中间表示函数gen_op_movl_T0_im()和gen_op_movl_reg_T0()生成中间代码。表1给出了这两条中间表示函数的功能描述和定义。

表1 中间表示函数示例
中间表示函数gen_op_movl_T0_im()用来实现将立即数暂存于临时变量CPU_T[0]中,中间表示函数gen_op_movl_reg_T0()用来实现将立即数存入对应于源寄存器的本地内存区域。类似于这样的中间表示函数还有很多,它们的函数名称都以gen_op_作为前缀,以特定的指令动作名称作为后缀。基于中间表示函数,可以进一步对相关机器指令操作,特别是造成中间代码膨胀的寄存器操作进行描述。
2.2 基于中间表示函数的特定指令动作描述
在图2的示例中,源平台的代码翻译到中间代码后,反复出现了立即数提取指令movi_i32,加载指令ld_i32,以及存储指令st_i32等。通过大量的代码分析得出,中间代码膨胀主要与四种寄存器操作相关,包括立即数提取操作、加载操作、存储操作和临时变量操作,本文将上述四种造成中间代码膨胀的特殊指令操作称为特定指令动作。
使用中间表示函数可以对这四种特定指令动作进行描述,并进一步抽象,方便后续的优化工作。例如,立即数提取操作可以使用中间表示函数类gen_op_movl_A_im表示,并可进一步简化表示为op_mov_im(A,Im)。
四种特定指令动作的描述如下:
1)立即数提取操作:op_mov_im(A,Im)∈{gen_op_movl_A_im}。
2)加载操作:op_ld(A,α)∈{gen_op_movl_A_reg(α)}。
3)存储操作:op_st(α,A)∈{gen_op_movl_reg(α)_A}。
4)临时变量操作:op(A),op(A,B)。第一个参数A用于存储运算后的结果。
其中,A,B∈{T0,T1,A0}。
以此为基础,分析造成中间代码膨胀的典型场景,找到与其相关的特定指令动作组合,然后运用寄存器直接映射思想,使用少量的本地寄存器操作进行等价替换,从而降低中间代码膨胀。
3 优化方法的实现
在实现将内存虚拟操作映射到本地寄存器的过程中,需要解决好两个问题:一是要保证寄存器在映射过程中的一致性。二是要建立等价的中间表示替换规则。
针对第一个问题,首先需要构建合适的映射公式,同时,还要保证源平台每一个待映射的寄存器都能够映射到本地平台的某个寄存器上。当本地平台的寄存器数量远大于或等于源平台的寄存器数量时,可以选择本地平台的部分寄存器进行映射。当本地平台的寄存器数量小于源平台的寄存器数量时,可以采用活性分析技术加以解决。3.1节给出了实现过程。
针对第二个问题,需要找到与中间代码膨胀相关的特定指令动作的组合,通过构建相应的映射规则,实现将原有的内存虚拟操作转化为对本地平台的寄存器操作。3.2节给出了实现过程。
3.1 映射公式的构建
本文研究的源平台为X86平台,目标平台是国产申威平台,源平台包含9个通用寄存器,目标平台包含32个通用寄存器。目标平台寄存器的数量远多于源平台寄存器的数量,满足映射的前提条件,因此,适用于本文的优化方法。
原有的内存虚拟策略是借助环境变量env通过调用使用env→regs[α]实现的,本文在实现内存虚拟操作到本地寄存器映射时,引入临时变量数组reg[i],建立了式(1)和表2所示的映射关系。

env→regs[α]→reg[i] (1)
在式(1)中,临时变量数组reg[i]的自变量取值范围由源平台寄存器的数量决定,例如,源平台X86平台包含9个通用寄存器,则reg[i]中i的取值为0≤i≤8。而目标申威平台包含32个通用寄存器,仅需要选用其中的部分寄存器进行本地映射即可。本文选用申威平台下的r7到r15作为本地寄存器进行映射,表2显示了具体的映射关系。
3.2 中间表示替换规则的建立
2.2节中已经提到中间代码的膨胀往往和一些特定指令动作的组合相关,针对中间代码膨胀呈现出的几种典型场景,应用式(1),可以建立以下4条基本替换规则:
替换规则C1:如果存在相邻的特定指令动作op_mov_im(A,Im)和op_st(reg(α),A)其中A∈{T0,T1,A0},则可以使用op_mov_im(reg[α],Im))替代op_mov_im(A,Im)和op_st(reg(α),A)。
C1的典型应用场景:将立即数移动到虚拟内存。
分析:将立即数Im提取到中间变量A,然后将中间变量A存储到虚拟内存reg(α)的操作序列,这与将立即数Im存储到寄存器reg(α)的操作功能等价。
替换规则C2:如果存在相邻的特定指令动作op(A)、op_ld(B,reg(α))、op(B,A)和op_st(reg(α),B),其中A、B∈{T0,T1,A0},则可以使用op(reg[α],A)替代op_ld(B,reg(α))、op(B,A)和op_st(reg(α),B)。
C2的典型应用场景:虚拟内存与立即数的计算结果存入同一虚拟内存。
分析:将虚拟内存reg(α)提取到中间变量B,然后将中间变量B和A的计算结果临时存储到B中,再将B存储到虚拟内存reg(α)的操作序列,这与将虚拟内存reg(α)和中间变量A的计算结果存储到虚拟内存reg(α)的操作功能等价。
替换规则C3:如果存在相邻的特定指令动作op_ld(A,reg(α))、op(A)和op_st(reg(α),A),其中A∈{T0,T1,A0},则可以使用op(reg[α])替代op_ld(A,reg(α))、op(A)和op_st(reg(α),A)。
C3的典型应用场景:仅操作同一虚拟内存数据。
分析:将虚拟内存reg(α)提取到中间变量A,然后对A进行相关计算并保存计算结果到A,再将A写回虚拟内存reg(α)的操作序列,这与将虚拟内存reg(α)计算后存储到自身的操作功能等价。
替换规则C4:如果存在相邻的特定指令动作op(A)、op_ld(A,reg(α))和op_st(reg(β),A),其中A∈{T0,T1,A0},则可以使用mov_reg_reg(reg[β],reg[α])替代op(A)、op_ld(A,reg(α))和op_st(reg(β),A)。
C4的典型应用场景:仅涉及不同虚拟内存间的数据移动。
分析:将虚拟内存reg(α)提取到中间变量A,然后将A的值存储到虚拟内存reg(β)的操作,这与将虚拟内存reg(α)存储到虚拟内存reg(β)的操作功能等价。
在上述4条基本替换规则基础上,还可以衍生出以下2条扩展的替换规则:
替换规则C5:如果存在相邻的特定指令动作op_ld(A,reg(α))、op(B,A)和op_st(reg(β),B),则可以使用op(reg[β],reg[α])替代op_ld(A,reg(α))、op(B,A)和op_st(reg(β),B)。
替换规则C6:如果存在相邻的特定指令动作op_ld(A,reg(α)),op_ld(B,reg(β)),op(B,A)和op_st(reg(β),B),其中A,B∈{T0,T1,A0},则可以使用op(reg[β],reg[α])替代op_ld(A,reg(α))、op_ld(B,reg(β))、op(B,A)和op_st(reg(β),B)。
上述规则提到的相邻特定指令动作并不要求位置连续,但必须存在于同一基本块,这是由语义环境一致性要求决定的。通过以上6条替换规则,可以实现功能等价条件下的寄存器直接映射策略,将原有内存模拟操作替换为本地寄存器操作。
4 优化方法的应用
下面分别以翻译源平台X86下的立即数加法指令和栈操作指令为例,阐述中间表示替换规则的运用。
图3展示了应用替换规则后,X86平台的立即数加法指令被翻译到中间代码的优化过程。源平台中第一条movl指令应用替换规则C1后,将立即数0x1直接存入eax寄存器对应的本地寄存器reg[0]中;类似地,源平台第二条movl指令应用替换规则C1后,将立即数0x3存入ebx寄存器对应的本地寄存器reg[3]中;源平台第三条addl指令应用替换规则C6后,使用本地寄存器reg[0]和reg[3]完成相应操作。最终,中间代码由优化前的10条指令简化为优化后的5条,中间代码规模缩减为原来的50%。
同样,图4展示了应用替换规则后,X86平台的栈操作被翻译到中间代码的优化过程。应用替换规则后,中间代码数量由优化前的29条指令简化为优化后的16条,规模减少了44.8%。

图3 立即数加法指令的中间代码优化示例Fig.3 Example of intermediate code optimization for immediate addition instruction

图4 栈操作指令的中间代码优化示例Fig.4 Example of intermediate code optimization for stack operation instruction
5 实验部分
将提出的中间代码优化方法在开源二进制翻译器QEMU1.7.2[15]进行了实现。使用如表3所示的实验环境,源平台采用的是X86-64架构处理器,本地平台采用的是国产申威411[16]处理器。

表3 实验环境
采用了正确性测试和性能测试两种方法来验证优化方法的正确性和有效性。正确性测试通过对比优化前和优化后的执行结果是否一致来进行验证,性能测试通过计算优化后的中间代码指令数量相对于优化前的中间代码指令数量的压缩率来进行验证,压缩率越高优化效果越好。测试用例选取了SPEC CPU2006[17]中的CINT2006的测试用例,如表4所示。
5.1 正确性测试
实验使用SPEC CPU2006进行了正确性测试,采用的测试方法是比较优化前后测试用例的执行结果是否一致。表 5显示了选取的测试用例和测试结果,测试结果表明优化方法的正确性达到100%。
5.2 性能测试
实验借助QEMU翻译SPEC CPU2006测试用例过程中产生的中间代码日志文件,通过对比优化前后日志文件中的中间指令数量,测试中间代码优化的效果。为了更清楚地说明测试效果,引入了代码缩减率R,如式(2)中所示:
R=1-Nopt/Nori×100%
(2)
式(2)中,Nori代表优化前的中间指令数量,Nopt代表优化后的中间指令数量,R值越高表明中间代码优化效果越好。
实验记录了每个测试用例的R值,测试结果见图5。结果表明,中间表示规则的建立对于中间代码的优化效果作用明显,各用例的代码缩减率R平均达到32.59%。可以看出,不同用例的加速效果差别较大,优化效果最好的用例是xalancbmk,其R值达到了37.31%;优化效果最差的用例是gcc,其R值为30.68%。通过分析用例源代码发现,xalancbmk用例中包含了大量的寄存器操作,使得中间表示替换规则可以被充分使用,所以优化效果明显;gcc用例只包含少量的寄存器移位操作,替换规则应用较少,所以优化作用有限。

表4 测试用例说明
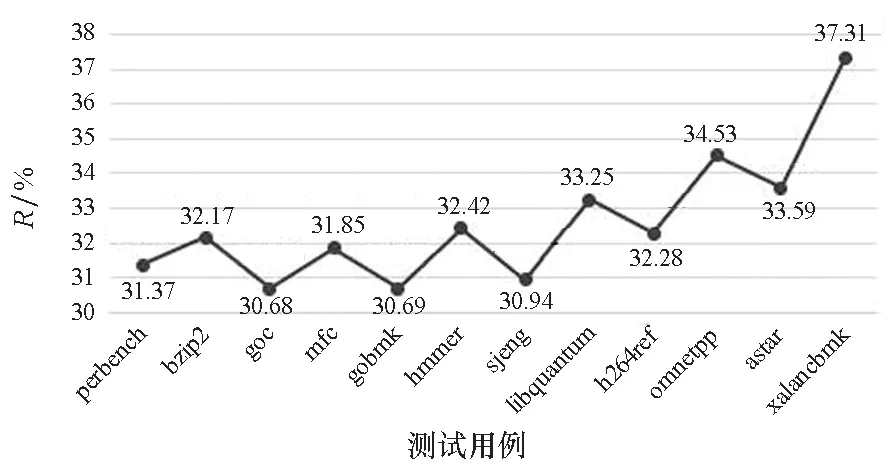
图5 中间代码优化性能测试Fig.5 Performance test of intermediate code optimization
6 结论
针对动态二进制翻译过程中的中间代码膨胀问题,本文对内存虚拟策略的实现机制进行了深入分析,提出了一种基于中间表示规则替换的二进制翻译中间代码优化方法,在对中间表示函数进行分类归纳的基础上,建立了针对特定指令函数匹配的中间表示替换规则,对于能够匹配规则的特定指令动作,应用建立的映射公式,使用少量的本地寄存器操作替代原有的内存虚拟操作,进而达到优化中间代码的目的。
另外,本文研究的基础平台是QEMU,具备多源到多目标的二进制翻译功能,因此,本文提出的方法具有一定的泛化能力。同时,需要进一步完善等价替换规则,从而取得更好的翻译效果。
