OODA-L模式下的智能无人集群作战仿真建模框架
2021-08-24邹立岩张明智柏俊汝
邹立岩,张明智,柏俊汝
(国防大学 联合作战学院, 北京 100091)
随着人工智能(Artificial Intelligence, AI)技术的不断发展,智能无人装备将成为未来智能化战争中的新兴作战力量。与此同时,随着分布式作战概念的提出和发展[1],以一定数量的智能无人装备组成无人集群来遂行特定的作战任务,被认为是未来智能化战争的典型作战样式,也是当前军事理论研究的前沿和热点问题。由于目前智能无人集群作战尚处于概念研究阶段,因此采用建模仿真方法率先对这一新型作战样式进行前瞻性和探索性研究,可以为未来智能无人集群作战力量的发展和运用提供理论支撑,具有重要的现实意义。本文首先分析了智能无人仿真实体的智能特性需求,在此基础上提出一种将学习过程显性化的OODA-L模式及其扩展形式;然后给出了智能无人仿真实体的总体描述;最后提出智能无人集群协同作战建模的体系结构。上述内容,旨在从高层上探讨如何对具有较高自主能力的智能无人集群进行作战建模与仿真的理论和方法。
1 智能无人集群作战的相关概念
1.1 无人系统及无人集群
无人系统(unmanned systems)[2-3]是指在陆、海、空、天各作战域内执行任务的战场机器人系统,如无人车、无人艇、无人潜航器、无人机等无人装备。智能无人系统(intelligent unmanned systems)是指具备一定感知、判断、决策以及自主行为能力的无人系统。无人集群(unmanned swarms)是指由一定数量的无人系统组成的集群,具有网络化沟通、自适应协同和集群智能三大基本特征[4],在接到指令后能够自主完成任务,因此也称为智能无人集群。无人集群在内涵上与机器人集群(robotic swarms)[5]、集群机器人(swarm robotics)[6-7]、智能集群(intelligent swarms)[5,8]以及群化武器[9]等概念相似,可以认为是同一概念在不同研究视角和不同发展时期的不同表述方式。
1.2 集群作战及智能无人集群作战
一般而言,集群作战(swarming)具有下列特点[10]:一是以破坏对手的战斗力聚合为主要作战目的;二是作战单元主要以小型化、分散化、能互联、具有自主或半自主能力的机动单元为主,且作战单元之间能够互相协作;三是要求集成指挥、控制、通信、情报、监视、侦察等能力,并具备待命、包围并发动持续的脉冲式攻击的能力;四是强调采取分布式的队形,以灵活的协同方式和精心设计的组织架构,采取中心化的战略和去中心化的战术,从多个方向对作战目标发起全面攻击。
根据上述集群作战的特点,将其延伸到以智能无人系统为主要作战单元的集群当中,便可演绎出智能无人集群作战的概念,其主要优势体现在:经济优势、数量优势、协同与情报优势[11]、速度优势等方面。
2 OODA-L模式的提出
在智能无人集群作战仿真建模中,对智能无人仿真实体建模的重点和难点是其较高的智能水平,而传统的无人集群作战模型中经常采用的自上而下的集中控制思想通常难以表达智能无人仿真实体高度智能化的战场适应能力和协同能力。为此,提出一种具有学习、进化特征的智能无人仿真实体的智能特性表达模式——观察-判断-决策-行动-学习(Observe, Orient, Decide, Act and Learning, OODA-L)模式。
2.1 智能无人仿真实体的智能特性需求
智能无人仿真实体的显著特征是拥有较高的自主能力和适应能力,低级别智能区别于高级别智能的标志在于智能体是否具有感知、理解、决策和学习等能力[10]。自主能力表现在:智能无人仿真实体能够感知不断变化的自身性能、任务目标、限制条件以及所处的战场环境,及时地做出新的行为规划或对原来的规划进行重规划。同时,在涉及集群作战时,行为规划和执行是一个协同处理的过程,智能作战仿真实体不仅要具有自主规划能力,而且要能够推断自身决策对其他仿真实体产生的影响[8],从而衡量自身决策的正确与否。适应能力表现在:智能无人仿真实体具备能够与环境以及其他仿真实体进行交互作用的一种能力。在这种持续的交互作用过程中,主体不断学习或积累经验,并根据学到的经验改变自身的结构和行为方式[12],其核心是学习能力。
自主能力与适应能力之间是相辅相成、循环演进的关系,这是复杂适应系统(Complex Adaptive System, CAS)的重要特征。在作战仿真建模中,智能问题通常以规则为基础,以各种适合规则的方法表达,很多情况下是用“If-then-else”的形式表示[13]。因此,基于规则的智能特性主要表现为:智能无人仿真实体通过对当前环境的感知,从现有规则集中选择某一自主行为去执行,而后通过与环境的交互作用,学习产生新的规则并对原有规则集进行更新,进而调整自身行为,这一过程循环往复进行,如图1所示。

图1 自主能力与适应能力的相互作用Fig.1 Interactions between autonomous capability and adaptive capability
2.2 智能无人仿真实体的智能特性表达
由2.1节可知,智能特性表达应当着重反映自主能力和适应能力,两种能力都是在与作战环境的互动过程中不断进化的。但传统的作战仿真实体建模,大多是基于预先、固定的规则来表达智能问题,难以体现“智能”的学习及进化特征。为解决这一问题,提出一种将OODA循环与学习过程相融合的智能特性表达模式,简称OODA-L模式。OODA循环之所以可以用于表达上述智能特性,是由于OODA循环描述的作战过程本身与CAS产生适应性的过程具有相似性。实际上,OODA循环的提出者博伊德也是CAS理论的坚定支持者,OODA循环的概念不仅被用于说明战争的胜利往往取决于更快地完成OODA循环的能力,同样也与CAS模式的作用、进化及适应过程有紧密联系[14]。OODA循环中的“观察”等同于智能无人仿真实体对环境的感知;“判断”等同于将感知到的信息进行处理并与规则集进行匹配的过程;“决策”等同于根据所匹配的规则选择自主行为的过程;“行动”等同于决策之后对自主行为的执行过程。OODA循环还隐含了一个十分重要的步骤,即“学习”的过程。学到的经验将会对“判断”和“决策”产生指导作用,这也是战争系统能够产生适应性以及智能无人仿真实体产生“智能”的根本原因。其中,“学习”的方式包括无人干预的学习即完全自主产生新的规则,有人干预的学习即由人类总结新规则并纳入规则集,以及两者相结合的方式。在OODA-L模式下,通过将“学习”过程显性化,可以表示智能无人仿真实体的智能特性演进的完整过程,如图2所示。

图2 OODA-L循环与智能特性的演进过程Fig.2 Evolution of OODA-L cycles and intelligent features
值得注意的是,OODA-L模式下的智能特性,不再是一种静态属性,而是一个不断发展变化的动态过程。“智能”应当视为在周期过程中逐渐演进的一种特性,而非固定不变的特性。OODA-L模式下的智能特性如图3所示,智能无人仿真实体在初始阶段仅具备一定的初始自主能力,但是随着OODA-L循环的大量迭代运行,其自主能力不断提升,适应能力不断增强。最终,无人仿真实体的智能特性体现为一个非线性的上升过程,其智能水平在逐渐加强过程中趋于收敛。

图3 OODA-L模式下的智能特性Fig.3 Intelligent features under OODA-L pattern
2.3 智能无人仿真实体的集群协同模式
集群行为在本质上是一种自组织活动,它是由一定数量的相对简单的个体通过相互关联、互相协作而形成的有机整体,能够在宏观层面涌现出群体智能(swarm intelligence)[18],从而具备更高级、多样化的功能,进而完成更加综合、复杂的任务。这里的“简单”是相对整体而言,并不排除个体本身具有一定的复杂性,需要视具体的集群类型而定。传统上的集群行为建模主要受到生物集群的启发,并从中抽象出相应的自组织行为规则。典型代表如Reynolds[19]等提出的“类鸟群”模型,每个“类鸟”通过感知邻居行为以作出反应,在遵循凝聚性(cohesion)、分离性(seperation)和对齐性(alignment)三条基本规则的前提下,整个类鸟群将展现出如同真实鸟群一般的一致行为。将上述思想用于集群作战仿真建模,一般需要预先对集群个体的行为能力和行为规则作出适当的简化、抽象和假设。例如在作战仿真平台ISSAC[20]和EINSTein[21]中,驱动Agent运行的局部感知和交互机制,就是受到类鸟群行为的启发扩展而来的[22]。这一建模方法在后来出现的许多更加复杂的基于Agent的作战仿真平台如MANA[23]、WISDOMⅡ[24]、SEAS[25]中均被广泛地应用于集群作战行为涌现机理的研究。
然而,这种依据“简单”规则的集群行为建模方法,本身较难适用于复杂多变的战场环境,且随着AI技术的进步,更难以体现智能无人集群作战的高度自主协同特点。因此,在2.2节的基础上,进一步将OODA-L模式扩展为Co-OODA-L(Cooperative OODA-L)模式,用于描述智能无人仿真实体的集群协同模式,如图4所示。
在图4中,智能无人Agent代表一个智能无人仿真实体,集群之间存在协同观察、协同判断、协同决策、协同行动、协同学习的交互性关系。将智能无人集群视为一个整体,相当于形成一个具有全局视角的虚拟全局智能体,它存在于每个智能无人Agent的本地,与集群内其他Agent之间通过数据链共享信息。全局智能体在观察、判断、决策和行动过程中,以全局为中心,在集群整体的角度进行综合权衡和协调,如图5所示[26]。其最终在集群个体的作战行为产生的效果不一定最优,但集群整体作战行为产生的效果却为最佳,相当于具有了群体智能。

图4 智能无人集群的Co-OODA-L循环Fig.4 Co-OODA-L cycle of intelligent unmanned swarm
值得注意的是,虚拟全局智能体区别于自上而下的全局控制,其职能是辅助集群内的个体获取和处理全局信息,并在集群内进行沟通和协调,并非如自上而下的全局控制一般要取代个体作出决策,其具体的行为决策还是由智能无人Agent自行作出,只不过这种决策在虚拟全局智能体的辅助下更具宏观视角。
3 智能无人仿真实体的总体描述
3.1 智能无人仿真实体的数学抽象
将智能无人仿真实体统一抽象为智能体Agent,则Agent的作战活动可以表示为马尔可夫决策过程(Markov Decision Process, MDP)[15-16],每个Agent用四元组〈S,A,T,R〉[10]表示,其中:
S表示Agent的状态空间,包括智能无人仿真实体所能感知到的自身状态信息和环境状态信息,对应于OODA-L模式中的“观察”和“判断”环节。
A表示Agent的动作空间,包括智能无人仿真实体可以采取的各种动作(作战行为),对应于OODA-L模式中的“行动”环节。
T为S×A×S→[0,1],表示Agent的状态转移函数,是智能无人仿真实体从一个状态转移到另一个状态的概率。
R为S×A→,表示Agent的奖励函数,是智能无人仿真实体在每个状态上采取某个作战行为之后,作战仿真环境给予的反馈值。
在MDP中,Agent的目标是找到一个最优的作战行为策略π*,使它在任意状态s和任意时间步t下的长期累积折扣奖励和最大。
(1)
式中:π为S×A→[0,1],表示Agent的作战行为策略,对应于OODA-L模式中的“决策”环节,是Agent用于决策的“大脑”;Eπ表示策略π下的期望值;γ∈[0,1]为折扣率;k为未来某一时刻的时间步序号;rt+k为Agent在时间步t+k上获得的即时奖励。式(1)代表智能无人仿真实体在作战仿真环境中进行学习的目标,可等价地表示为:
(2)
式中,Q*(s,a)表示“状态-动作”对(s,a)在最优策略下所获得的长期累积折扣奖励。式(1)中的V*(s)和式(2)中的Q*(s,a)分别称为MDP的最优状态值函数和最优动作值函数,而最优策略π*则可以通过计算V*(s)或Q*(s,a)得到。
智能无人仿真实体的动作寻优原理如图6所示。从某一初始值函数V和初始策略π出发,智能无人仿真实体通过策略评估学习到π的状态值函数Vπ并赋值给V,而后根据V的值取贪心策略后,又可以通过策略改进得到新的π,每次迭代的过程对应于OODA-L模式中的“学习”环节。经过多次迭代,V和π将最终收敛到最优值V*和π*,从而得到智能无人仿真实体的最优作战行为策略。
3.2 智能无人仿真实体的组成结构
传统上,作战仿真建模中的Agent具有如图7所示结构。
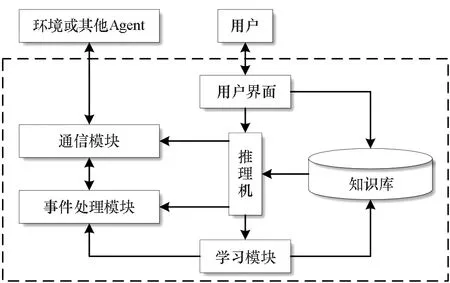
图7 Agent的一般结构Fig.7 General structure of Agent
在图7中,Agent的智能特性表达是通过知识库、推理机和学习模块组成的专家系统构成,属于人工智能中符号主义学派[17]的观点即知识表示,但该结构中的知识库构建一般较为困难。而OODA-L模式,属于人工智能中行为主义学派[17]的观点,无须构建过于复杂的知识库和推理机。同时,借鉴CAS理论中的“开放”理念,强调将Agent视为一个开放的子系统,其智能特性是在与外界复杂环境建立起“观察-判断-决策-行动”的高级行为机制基础上,通过Agent不断地与仿真环境交互迭代,以此进化出“智能”的作战行为。
为实现OODA-L模式,提出智能无人Agent建模的四个基本思路:①智能无人Agent所具有的基本行为能力,应当依据现实中无人作战装备的基本组成结构和功能配置,进一步抽象而来。②智能无人Agent应当由相互分离的底层技能模型、中层行为模型和高层智能模型组成。③智能无人Agent的某一具体行为可由单个或多个技能模型组成,智能模型可视为Agent在时序范围内,依据策略对作战行为的选择和运用。④智能无人Agent应当是一种开放、可扩展的模型,可以根据需要对技能模型、行为模型进行扩充。基于上述四点,构建智能无人Agent的三域分层结构,如图8所示。

图8 智能无人Agent的三域分层结构Fig.8 Three-domain hierarchical structure of intelligent unmanned Agent
在图8中:①智能模型对应于认知域,该模型主要是根据上级指控信息、预定的作战任务以及对作战态势的认知,对下一步应当采取的作战行为作出决策。同时,智能无人Agent的状态在执行某一行为时,也随之改变。②行为模型对应于信息域,该模型主要描述智能无人Agent的行为能力,这里将行为模型视为信息行为,主要是因为信息域充当了认知域与物理域之间的媒介,起着“黏合剂”的作用,如图8左侧的图例所示。从建模角度,行为模型承担的功能是将物理域模型的输出值进行综合并以信息交互的方式反馈给智能模型,从作用的本质上看,它是将OODA循环的各个环节连接起来的中介,仍然是一种信息行为。另外,由于通信行为和感知行为属于智能无人Agent的常态行为,比较特殊,故单独列出,以区别于其他行为。③技能模型对应于物理域,该模型更加贴近于装备的硬件层面,强调对物理实体功能的描述,是能够直接与外界环境或其他Agent发生交互的物理仿真模型,如雷达的探测模型、导弹的毁伤模型、飞机的空气动力模型、武器的控制模型等。技能模型比行为模型粒度更细,一个行为模型包含一定量的先验知识,可以看作某个行为对基础技能的一种调用,它由多个技能的序列、算法或规则集组成。
综上所述,可以将智能无人Agent的组成结构特点总结为:智能模型是学习出来的,行为模型是抽象或规划出来的,技能模型是相对固定的。智能模型决定智能无人Agent该“做”什么,行为模型决定“做”的具体内容和方式,技能模型负责将“做”贯彻落实。
4 智能无人集群协同作战建模的体系结构
协同行为是智能无人集群作战仿真建模的关键所在,结合2.3节提出的Co-OODA-L模式,提出智能无人集群协同作战建模的体系结构,如图9所示。
在图9中,设定智能无人集群采用分布式集群架构,各Agent之间相互独立,集群内部可通过数据链实现信息共享。该体系结构的运行过程为:①智能无人Agent通过协同感知外部环境,使全局战场状态信息在集群内部共享。②各智能无人Agent结合自身视角,利用人工神经网络(Artificial Neural Network, ANN)构成的态势认知网络,对全局战场状态进行协同“思考”。③各智能无人Agent将“思考”后的信息,通过通信层/集群作战协调层(兼虚拟全局智能体),进行充分的沟通和协调,该层也由ANN构成,在具体实现上可采用循环神经网络(Recurrent Neural Network, RNN)及其变体或替代形式。④将沟通和协调后的信息反馈给同样由ANN构成的策略网络,各Agent按照策略网络的输出选择相应的作战行为,并在作战仿真环境中具体执行。⑤智能模型对协同作战行为的执行效果进行综合评估,并改进和优化智能无人Agent的作战行为选择。上述过程,将通过人不在回路的作战仿真环境进行大量迭代运行,直至智能无人Agent学习到满足要求的智能模型。相比传统的集群行为建模方法,该体系结构具有下列特点:
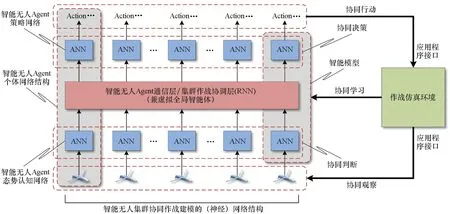
图9 智能无人集群协同作战建模的体系结构Fig.9 Architecture of cooperative operation modeling of intelligent unmanned swarm
1)各智能无人Agent共用相同的神经网络结构(包括态势认知网络、策略网络和通信网络)及参数,可适用于可变Agent数量的集群;另外,由于采用了分布式结构,可同时适用于同构或异构集群的建模,在经过充分的训练和学习后,智能无人Agent将会产生高度自主的集群协同作战能力。
2)各智能无人Agent的行为决策,并非简单的“If-then-else”式结构,不单纯追求集群行为的一致性,而是通过对外部环境的感知和思考,同时兼顾其他Agent可能采取的行为,进而推理出自身的行为决策,从而使智能无人Agent个体具有了一种全局思维能力。
3)智能无人Agent的策略网络经过作战仿真环境的训练而不断优化,因而每个Agent都具有自学习和自成长特性,相比基于固定规则的Agent而言,具有更好的适应能力和泛化性能,能够应对未知环境的不确定性,后续还能够通过不断地自我学习来进一步提升自身的智能水平。
5 结论
建模框架是从高层对仿真建模活动提供的方法指导。本文针对智能无人仿真实体的智能特性需求,提出一种能够反映智能无人仿真实体自主能力和适应能力的OODA-L模式,并将其扩展为适用于集群做的Co-OODA-L模式。在OODA-L模式下,采用MDP对智能无人Agent进行数学描述,并给出智能无人Agent的三域分层结构描述。在Co-OODA-L模式下,探讨了分布式体系结构下智能无人集群协同作战建模的(神经)网络结构及其特点。下一步,将根据所提建模框架,重点结合具体的智能无人集群作战任务背景,搭建仿真实验环境和智能无人Agent模型,构建相关算法,开展细化研究。
