机器学习在读者需求驱动采购中的应用探析
2021-08-23曹莎莎徐岚刘涓
曹莎莎 徐岚 刘涓


摘 要 随着读者需求驱动采购在高校图书馆的应用日益广泛,随之而来的经费超支、馆藏结构失衡等问题引起业界关注,为有效解决上述问题,文章通过探索机器学习方法在读者需求驱动采购中的应用,构建具体应用框架,并从读者、图书、模型三个角度对应用框架进行拓展和延伸,分别描述不同角度下机器学习方法应用于读者需求驱动采购的技术路线。研究表明将机器学习方法应用于读者需求驱动采购,可以有效预测读者需求、图书触发采购概率和馆藏结构,从而实现节省图书馆经费、改善馆藏结构失衡的目标,事实证明其对图书馆采购决策和馆藏建设有着积极的影响。关键词 机器学习 读者需求驱动采购 读者决策采购 馆藏建设
分类号 G253.1
DOI 10.16810/j.cnki.1672-514X.2021.07.012
Analysis on the Application of Machine Learning in Demand Driven Acquisition
Cao Shasha, Xu Lan, Liu Juan
Abstract With the wide application of demand driven acquisition in university libraries, the following problems such as over expenditure and unbalanced collection structure have attracted the attention of libraries. In order to solve the above problems effectively, the paper first puts forward a specific application framework by exploring the application of machine learning in demand driven acquisition, then expands and extends the application framework from the perspectives of readers, books and models, and respectively describes the technical route of the application of machine learning methods in demand driven acquisition from different angles. The research shows that the application of machine learning method in demand driven acquisition can effectively predict readers demand, the likelihood of books being triggered for purchase and collection structure, so as to achieve the goal of saving library funds and improving the imbalance of collection structure. Facts have proved that it has a positive impact on library procurement decision-making and collection construction.
KeywordsMachine learning. Demand driven acquisition. Patron driven acquisition. Collection development.
0 引言
图书馆一直有读者参与图书采购决策的传统,从读者意见箱到线上荐购再到馆际互借,但馆藏建设的最终决策权仍在图书馆员身上。随着读者对文献资源需求越来越高,电子出版物大量涌现,与此同时,图书馆经费收缩,现有馆藏利用率较低,催生了读者需求驱动的图书采购新模式[1](Demand Driven Acquisition,以下简称DDA)。ProQuest2018年发布题为“Why DDA is Here to Stay”的白皮书[2],对全世界449名图书馆员(其中99%的受访者为高校图书馆员)开展调查,有93%的受访者称其图书馆采用多种电子书采购模式,92%的受访者称需求驱动采购是其图书馆电子书的主要采购模式,可见读者决策采购在国外图书馆,特别是高校图书馆扮演着越来越重要的角色,学界一致认为该采购方法是对当前馆藏建设方法的有益補充[3]。现有DDA研究主要集中于各机构的实施案例和经验,研究发现,依据读者需求而非图书馆员对馆藏的评估采购图书,虽优势明显,但其过程中的不可预见成本及馆藏结构失衡问题,对图书馆来说也是一种挑战,如俄亥俄州立大学图书馆的DDA试点项目投入25000美元,测试预计持续18周,结果在第五周经费已花完[4];犹他大学的DDA项目被3名用户主导,3人花了近1/3的年度经费[3]。由于不确定性广泛存在,图书馆员一直在努力探索推动DDA实践的积极方法,大数据时代的到来为读者需求驱动采购提供了新的思路。
随着互联网的发展,数据快速增长,由此催生的数据科学研究方法和产品正在改变各行各业,也包括图书馆业[5]。现今不断涌现的各种人工智能技术正在成为大数据获取、预处理、存储、分析或可视化的有效手段。机器学习作为人工智能的重要分支,是大数据时代必不可少的核心技术,其在分析读者数据、发现读者需求、挖掘数据隐藏的结构和关系上有着极大优势。当前,机器学习在图情领域的应用主要有个性化信息推荐服务、智能信息检索以及自动文本分类等方面[6]。作为一种数据驱动的采购模式,DDA涉及大量数据,这些数据不仅能够触发购买行为,还可以通过机器学习方法对其分析和处理,判断DDA模式是否符合图书馆预期,从而为读者提供个性化服务、协助馆藏建设决策制定,并对高校教学科研产生积极的影响。
1 读者需求驱动采购的数据来源
读者需求驱动采购源于馆际互借,典型的DDA项目始于预设文档的构建,预设文档类似于纲目购书(Approval Plan)的纲目,图书馆可以根据图书的主题、价格、出版社及DDA服务商提供的其他限制设置预设文档;服务商将符合预设文档的MARC记录导入到OPAC中,项目过程中可以增添或删减书目记录来调整DDA资源库;随后读者能够在终端看到图书并根据自己需求触发购买。DDA主要有两种触发购买模式:单触发模型和短期借阅模型。前者基于读者请求直接购买,即10-10-1-1-1范式,读者在某本书上停留10分钟、查看10页、1次下载、1次打印或1次复印则触发购买;后者在单次或数次短期借阅之后产生购买行为,每次短期借阅行为通常也符合10-10-1-1-1參数,除最后一次以图书标价直接触发购买外,每次短期借阅的价格一般为图书标价的20%~25%[7]。可以看出,DDA在实施过程中涉及大量数据,从赖以提供服务的馆藏书目数据和学科建设数据,到读者相关数据,再到读者在利用图书馆的过程中产生的书目数据和流通数据等,对上述数据进行收集和分析,有助于提高DDA决策的科学性和精准性。
1.1 书目数据
读者需求驱动采购中的书目数据包括馆藏书目数据和预购书目数据。馆藏书目数据指的是馆藏MARC数据和数字资源数据,具体包括书名、作者、出版社、出版日期、编目日期、主题等内容,该数据有助于了解馆藏文献类型分布、时间分布、学科分布及馆藏特色资源。预购书目数据指的是DDA项目过程中预计采购图书的书目数据,即DDA资源库中的书目数据。馆藏书目数据和预购书目数据是制定DDA预设文档的基础。
1.2 读者数据
读者数据包含读者身份数据、读者行为数据和读者偏好数据。读者身份数据指的是读者身份信息,如性别、年级、读者类型、读者所属院系及专业等相关信息。读者行为数据指的是读者在利用图书馆资源中产生的行为数据,如图书浏览、借阅、数据库访问、请求、检索、下载、评价等数据。读者偏好数据指的是不同类型的读者(本科生、研究生或教职人员)对不同类型、不同载体、不同学科图书的偏好数据。读者数据可以用于读者画像描述,构建DDA读者偏好模型。
1.3 流通数据
流通数据指的是馆藏图书的借还和续借数据,是典型的静态数据。流通数据可以用来识别高利用率馆藏和低利用率馆藏,判断一本书的生命周期及馆藏文献半衰期[8],从而评估馆藏,还可以了解不同读者群体的阅读倾向及其对图书的偏好,掌握其潜在信息需求。流通数据可以和书目数据一起构建图书采购模型,还可以指导DDA预设文档的建立,评估DDA效能以确定DDA是否按照预期执行。
1.4 学科建设数据
学科建设数据指的是高校的学科专业设置和学科发展规划、重点学科建设和教科研文献需求等数据。学科建设数据可以同书目数据一起科学制定馆藏建设策略,明确馆藏建设的方向和重点,指导DDA参数的设置,如按照学科、出版社、作者、出版时间等因素决定优先采购何种文献资源,使DDA决策和馆藏建设方向一致,进而完善馆藏特色资源建设[9]。
1.5 门禁数据
门禁数据指的是读者进出图书馆的人次数据,此类数据可以通过图书馆的门禁系统获得,对该数据进行收集、整理和分析可以得出到馆读者构成,从而区分不同类型、不同年级、不同系部、不同专业读者的入馆比例等,提供准确时段数据。借助于门禁数据,图书馆可以根据读者类型和到馆人流变化趋势制定服务策略。门禁数据可以同书目数据、学科建设数据、读者数据和流通数据一起,辅助馆藏决策制定。
2 机器学习在读者需求驱动采购中的应用框架
2.1 机器学习在读者需求驱动采购中应用的优势
作为一种以数据为导向的方法,机器学习利用不同的理论模型和训练方法,从特定的行业数据中寻找隐含的规律,是一种依赖数据并能够极大提升数据利用水平的重要智能信息技术。按照学习方式,机器学习可以分为监督学习、无监督学习和强化学习。其中监督学习是根据已知类别的数据来推断未知数据的学习任务,大致可分为回归和分类两大类,如逻辑回归、K-近邻、决策树、贝叶斯分类、神经网络等算法;无监督学习没有对训练数据进行事先标记,由机器自动对输入的数据进行分类和分群,依靠训练集的统计规律实现数据的分析,常见的方法是聚类和降维,如K均值算法、主成分分析等;强化学习是完全随机的操作,通过不断尝试,从错误中学习最后找到规律[10]。在大数据和人工智能应用的背景下,将机器学习技术有机地融入图书馆读者需求驱动采购工作,有利于提升信息时代馆藏资源建设的智能化水平,为馆藏建设带来有益启示。
读者需求驱动采购中涉及的数据既有宏观层面的图书和读者群体的特征和行为数据,也有微观层面的读者个性数据,这些数据蕴含了大量的特征、模式和关系,为读者需求驱动采购提供了重要依据,也为机器学习提供了用武之地。通过机器学习方法对这些大数据进行收集、分析和处理,可以提前预测读者需求,在读者没有意识到需要何种图书的时候购买该书,理解读者不断变化的偏好[11],能够为DDA预设文档和馆藏建设制定方向;可以节省DDA经费,提高图书馆投资回报率;还能对DDA项目进行评估,提高其应用效能。
2.2 机器学习在读者需求驱动采购中的应用框架
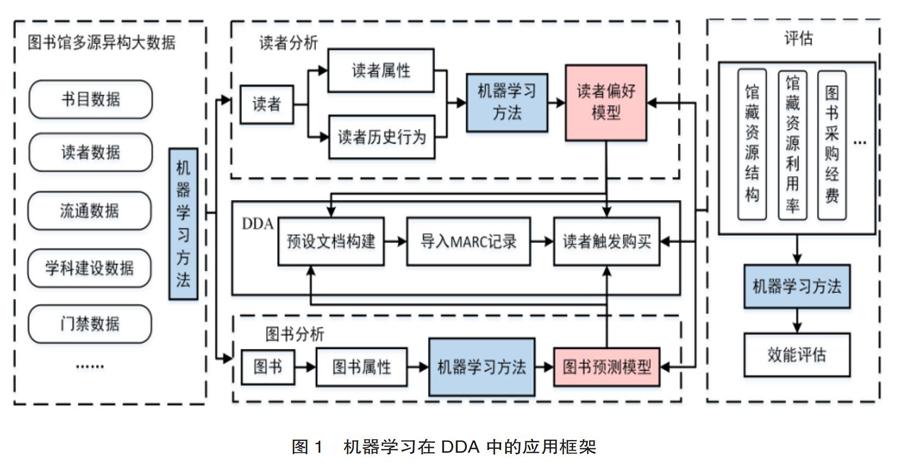
机器学习在读者需求驱动采购中的具体应用框架如图1所示,其中图书馆大数据是基础,机器学习是手段,满足读者需求和完善馆藏结构是目标。该应用框架分为三个阶段,第一个阶段是图书馆多源异构数据的预处理和融合;第二阶段针对读者需求驱动采购的具体环节,利用不同的机器学习方法对数据进行分析和处理,建立对应的科学模型,通过模型在分类、聚类和预测等方面的深入应用实现读者需求驱动采购的智能化和精准化;第三阶段是读者需求驱动采购的评估过程,重点是利用机器学习方法来评估图书馆大数据驱动下读者需求采购的效能。
2.2.1 数据预处理和融合
图书馆大数据是典型的多源异构数据,数据来源和类型多样,同时具有时间、空间和语义的多维度特征,往往无法直接被应用于数据分析和建模[12]。DDA中的多源异构数据包括书目数据、读者数据、流通数据、学科建设数据和门禁数据,这些数据既有静态数据,也有动态数据;既有结构化数据,也有半结构化、非结构化数据,需要对其预处理和融合才能形成结构完整、形式统一的数据格式。数据的预处理流程指的是对数据进行清洗、集成、变换和规约,数据清洗通常对数据缺失值和异常值进行处理,数据集成通常用于识别数据中的不一致和冗余属性,数据变换是对原始数据进行规范化处理,而数据规约是对原始数据进行数据和属性的约减。通过分类、回归、聚类、关联分析等机器学习方法对数据预处理和融合,可以提高数据的质量,为后续的数据分析提供基础和支撑。
2.2.2 模型建立
完整的读者需求驱动采购流程分为三个部分,依次是预设文档构建、导入符合预设文档的MARC记录、读者触发购买。其中预设文档的构建跟图书密切相关,具体购买行为则与读者密切相关,对图书和读者分别进行分析可以建立相应的图书预测模型和读者偏好模型。
读者分析模块中,读者在利用图书馆资源的过程中产生系列数据,这些数据既包含读者显性兴趣,也包含其隐性需求倾向,这类读者偏好信息无法被主动获取。借助于机器学习方法中的监督学习方法,从读者属性、历史行为等方面抽取出关键的特征,利用这些数据和特征训练得到读者偏好模型,该模型能计算出读者对图书的喜好概率,从而更加准确、有效地预测读者需求。对于预购新书,可将其加入到读者偏好模型中预测其被触发购买的概率,根据项目经费确定是否需要将该书加入DDA资源库,以防经费超支;还可以通过该模型对馆藏资源进行效用评价,确定馆藏资源是否符合读者需求及馆藏建设目标,改善馆藏结构失衡。
图书分析模块中,通过对图书的题名、责任者、出版社、主题、出版時间等属性信息进行深入挖掘和分析,掌握不同属性的图书利用情况。将图书的属性信息抽取出来构成关键的特征,不同特征的组合可以用来表示不同的图书,由于缺乏足够的先验知识,开始可以利用无监督学习的算法如聚类分析,区分出不同的图书群体,并且概括出同一类图书的特点,把注意力放在某一特定的类上以作进一步的分析;或者可以利用关联分析,分析图书不同特征和实际利用效率的关联关系,得到每一个特征和不同特征组合对图书利用的影响,其后利用监督学习的算法构建图书预测模型。对于预购图书,可将其加入到模型中,预测是否会被购买以及多长时间会被购买,根据预测的触发因素推断详细的经费支出,评估DDA经费分配或者调整预设文档参数。
2.2.3 模型评估
读者需求驱动采购的评估过程,重点是利用机器学习方法来评估图书馆大数据驱动下读者需求采购不同环节在长期运行后的实际效果。评估是对读者需求驱动采购的必要信息反馈,只有进行评估才能知道读者需求驱动采购是否满足预期效果,以及读者偏好模型、图书预测模型等机器学习背景下建立的模型是否能有效提高工作效率,从而构成一个闭环,促进读者需求驱动采购的优化。评估的核心是在各种静态和动态的图书馆大数据基础上,引入机器学习在数据挖掘和数据建模方面的方法,验证读者需求驱动采购过程中所构建读者偏好模型和图书预测模型的准确性,运用不同分类和聚类算法来衡量馆藏资源结构、图书采购经费运用是否合理,利用机器学习方法建立的模型预测馆藏图书以及读者需求驱动采购的图书在当前和未来的利用率。
3 机器学习在读者需求驱动采购中的应用模式
为将机器学习思想和算法引入读者需求驱动采购中,学界进行了有益探索。Kohn[13]通过建立包含主题、出版社和供应商的逻辑回归模型确定何种因素最利于预测电子书的利用率;Walker[14]等人利用自适应增强(AdaBoost)模型预测DDA项目中新书被触发购买的可能性,其准确率超过82%;Zhehan Jiang等人[15]利用基于随机森林算法的生存分析预测图书馆新书是否会触发购买及何时会被触发购买,其中涉及出版社、出版时间、分类和价格等参数的复杂模型产生的AUC(一种测量预测模型预测能力的方法,AUC越接近1表明模型越完美)高于0.8,预测效果良好。然而,这些应用模型存在手段单一、效果不显著、应用场景受限制等问题。本文对如何在数据驱动下将读者需求驱动采购和机器学习进行有机的结合开展了深入思考,总结了机器学习技术在读者需求采购中的三个应用方向,其一,基于读者分析的应用模式,重点研究如何深入分析和挖掘读者数据中隐含的信息,利用机器学习的不同算法建立准确的读者偏好模型,提升读者需求驱动采购的智能化水平;其二,基于图书分析的应用模式,重点研究如何深入挖掘图书采购和利用的规律,利用书目数据和流通数据建立图书预测模型,提升读者需求驱动采购和利用的效率;其三,基于模型分析的应用模式,重点研究如何针对读者需求驱动采购的不同环节需求,选择合适的机器学习方法,准备训练数据构建最佳模型,实现对应环节服务能力的全面提升。
3.1 基于读者分析的应用模式
基于读者分析的应用模式是从深入分析读者的角度,利用图书馆大数据中读者身份数据、读者行为数据和读者偏好数据,经预处理后依据不同的维度抽取出可以用来揭示读者区别的特征,如读者性别、年级、类型、专业等内在特征,检索行为、浏览行为、借阅行为和评价行为等动态特征[16],以及阅读兴趣、阅读习惯、教育目标等深层次的特征,再利用不同的机器学习方法挖掘读者的需求倾向,具体搭建下图2所示的读者偏好模型,该模型能实现预测图书触发采购概率、预测读者阅读行为和趋势、评估现有馆藏三大目标。
3.1.1 预测图书触发采购概率
读者偏好模型的重点是反映读者对不同类型图书的偏好程度,具体过程是分析读者年级、专业等内在特征数据,如法律系的读者可能更偏好法律类的图书;或者分析读者对图书的检索、浏览、借阅、评价等行为特征数据,如借阅武侠小说多的读者们比较偏好武侠小说;或者分析读者阅读目标等深层次特征数据,如低年级本科生偏好参考类图书、高年级本科生偏好考研类图书。读者偏好模型一般可以训练决策树、贝叶斯网络、神经网络等数学模型来表达,其表现形式是不同读者对不同图书属性(题名、作者、出版社、价格、出版时间等)或者属性组合喜好的概率,如周志华著的《机器学习》一书,清华大学出版社2016年出版,通过该模型可以分别计算出喜欢该书以及不喜欢该书的读者比例。日后对于预购图书,都可以利用该模型分别计算出读者对某本书每个属性喜欢和不喜欢的概率,综合得出该书的需求概率,从而做出购买与否决策。
3.1.2 预测读者阅读行为和趋势
分析读者行为历史数据,诸如检索过哪些关键词,借阅过哪些书,对哪些书进行过点评,对检索关键词、图书属性和读者评价进行分析,统计读者不同行为的分布特征,可以从侧面反映出读者的阅读需求。读者本质上由性别、年龄、专业、年级、类型等特征进行区分,将读者上述本质属性与对应的行为联系起来,即挖掘读者属性和行为特征的关联,利用决策树、贝叶斯分类等方法训练具体的读者偏好模型。随着读者组成结构的变化,读者需求也随之变化,而需求变化的规律将遵循读者偏好模型所表达的规律,通过模型抽取出新的读者属性特征,经过计算可以得到新的读者需求变化趋势,对读者需求采购进行指导,提升采购智能化水平。此外,结合馆藏流通数据和门禁数据,可以得知不同时间段读者对馆藏文献的需求,从而调整DDA项目的实施时间及经费,如在读者对馆藏需求较高的时段开展DDA项目并适当加大这一时期的经费投入。
3.1.3 评估现有馆藏
分析读者不同属性特征的分布,建立读者属性和行为特征的关联,一般采用贝叶斯网络、关联规则等知识表示的手段来总结规律,构建读者偏好模型,利用上述模型实现对馆藏图书的深入分析。具体分析流程如下:馆藏图书经过特征提取以后可由读者偏好模型计算得到对应的读者需求概率,概率越高表示图书被读者借阅的概率越大,相应的利用率也越高;概率越低表示图书被借阅的概率越小,越有可能成为闲置资源。读者偏好模型的建立,能够对馆藏资源的整体效用进行计算和评价,明确现有馆藏资源是否符合读者的需求及馆藏建设目标。同时随着读者结构的变化,该模型还能评估馆藏图书的结构是否沿着满足读者需求的方向发展。
3.2 基于图书分析的应用模式
基于圖书分析的应用模式从分析图书的角度,以图书馆大数据中预购书目数据、馆藏流通数据和馆藏书目数据为基础,经过预处理以后根据不同的维度抽取出可以用来区分图书的特征,如题名、作者、出版社、价格、出版时间、借阅时间、借阅频率等特征。在不直接依赖读者偏好数据的前提下,深入挖掘图书特征与图书采购和利用之间潜在的规律,利用机器学习方法构建图书预测模型,实现图书触发采购、图书流通趋势和馆藏资源结构预测的目标,模型如图3所示。
图3 基于图书分析的应用模式
3.2.1 预测图书触发采购
分析图书的题名、作者、出版社、价格、出版时间等特征,结合图书被检索、被借阅、被评价等历史流通行为数据,建立图书属性和流通数据之间的关联,一般采用贝叶斯网络、决策树、随机森林等方法,建立图书预测模型。模型表达的是满足什么样属性值的图书容易被读者借阅,以及被读者借阅的概率,如知名作者、权威出版社、近期出版的图书被借阅的概率更大。对于预购图书,首先提取其特征值,在图书预测模型中检索对应的特征值或者特征值组合,计算得到对应的被借阅概率,从而得出该书被采购的概率,这个值即该书被读者需要的程度,从而实现图书触发采购概率预测。
3.2.2 预测图书流通趋势
通过对图书属性特征进行区分,分析图书不同的属性在流通过程中的分布规律,如分析具备哪些特征或特征组合的图书被借阅的概率更高,建立图书属性和图书流通数据的关联,利用逻辑回归、贝叶斯网络、决策树、随机森林、关联分析等机器学习方法,建立图书预测模型。模型表达的是不同属性和属性组合的图书在当前环境下被借阅的概率,结合历史流通数据预测未来一段时间内馆藏图书将被借阅的概况,实时、精准了解馆藏需求的变化,实现预测图书流通趋势的目标。
3.2.3 预测馆藏资源结构
与预测图书触发采购概率功能方法一致,采用贝叶斯网络、决策树、随机森林等方法,建立图书属性和图书被触发采购的关联,构建图书采购预测模型。模型表达的是不同属性值的图书被触发购买的概率,结合历史触发数据预测各类图书被触发购买的数量和比例,及时反应馆藏结构的变化。随着读者需求的变化,该模型对馆藏资源结构的预测结果也将保持动态更新,有利于图书馆及时调整馆藏建设决策。
3.3 基于模型分析的应用模式
基于模型分析的应用模式是从不同机器学习算法的特点入手,面对读者需求驱动采购的不同业务环节要求,抽象出需要机器学习算法解决的问题,确定最佳机器学习建模方法。然后依据方法对准确性、效率和稳定性的不同要求选择具体的机器学习算法,其中监督学习有逻辑回归、贝叶斯分类、决策树、集成学习、深度神经网络等方法,无监督学习有K均值算法、分层聚类算法、主成分分析、奇异值分解等方法。确定好机器学习建模算法以后,根据算法对输入数据的特征和格式需要采集数据、提取特征,对采集来的数据预处理生产训练集。最后在训练集的基础上利用对应的机器学习算法训练模型,直到满足模型预期的参数指标,完成训练的模型可以在实际应用中完成预测、分类和聚类的任务,代替人工的工作。
4 结语
图书馆多年实践表明,图书采选的质量并不能保证其实用性或流通率,随着图书馆经费收缩,读者需求驱动采购将发挥重要作用。在大数据和人工智能技术广泛应用的背景下,本文通过构建机器学习在读者需求驱动采购中的具体应用框架,从读者、图书和模型三个角度阐述了构建和应用相应模型的方法,能够实现读者需求驱动采购的智能化和精准化,有效改善DDA项目成果,帮助图书馆更好地管理采购决策,提高经费的投资回报率。机器学习在读者需求驱动采购中的应用有助于图书馆积极应对信息技术的挑战,促进馆员向新的工作流程转变,不断提升信息服务能力。然而,由于图书馆数字化程度的不同,传统机器学习技术在图书馆馆藏建设中的应用往往受限于数据样本少,无法发挥出应有的价值,当前人工智能领域涌现的新技术,如迁移学习、自监督学习等可以弥补数据准备的不足。未来,开展此类研究将大大提升机器学习在读者需求驱动采购领域,甚至是整个图书馆领域的应用效果。
参考文献:
曹莎莎, 徐岚.“互联网+馆藏建设”:读者决策采购[J].新世纪图书馆,2016(12):21-24,29.
ProQuest. Why DDA is ries[EB/OL].[2020-06-20]. https://go.proquest.com/ddawhitepaperemail.
BLUME R. Balance in demand driven acquisitions: the importance of mindfulness and moderation when utilizing just in time collection development [J]. Collection Management, 2019, 44(2-4),105-116.
HODGES D, PRESTON C, HAMILTON M J. Patron-initiated collection development: progress of a paradigm shift[J]. Collection Management, 2019(35):3-4, 208-221.
OLIVER J C, KOLLEN C, HICKSON B, et al. Data science support at the academic library[J]. Journal of Library Administration, 2019,(59):241-257.
张坤,王文韬,谢阳群.机器学习在图书情报领域的应用研究[J].图书馆学研究,2018(1):47-50.
WALKER K W, ARTHUR M A. Judging the need for and value of DDA in an academic research library setting[J]. The Journal of Academic Librarianship, 2018, 44(5):650-662.
RENAUD J, BRITTON S, WANG D D, et al. Mining library and university data to understand library use patterns[J]. The Electronic Library, 2015, 33(3):355-372.
王芙蓉.大数据环境下基于读者决策的图书馆文献资源采购模型研究[J].图书馆学研究,2017(12): 54-59.
周志华.机器学习[M].北京:清华大学出版社,2016.
LITSEY R, MAULDIN W. Knowing what the patron wants: using predictive analytics to transform library decision making[J]. The Journal of Academic Librarianship, 2018, 44(1):140-144.
马晓亭.图书馆多源大数据融合研究:问题与挑战[J].新世纪图书馆,2017(1):28-31,35.
KOHN K. Using logistic regression to examine multiple factors related to e-book use[J]. Library Resources & Technical Services. 2018, 62(2):54-65.
WALKER K W, JIANG ZHEHAN. Application of adaptive boosting (AdaBoost) in demand-driven acquisition(DDA) prediction: a machine-learning approach[J].The Journal of Academic Librarianship. 2019,45: 203-212.
JIANG ZHEHAN, FITZGERALD S R, WALKER K W. Modeling time-to-trigger in library demand-driven acquisitions via survival analysis[J]. Library and Information Science Research. 2019, 41(3):1-8.
沈敏,杨新涯,王楷.基于机器学习的高校图书馆用户偏好检索系统研究[J].图书情报工作,2015,59(11):143-148.
曹莎莎 安徽警官职业学院图书馆馆员。 安徽合肥,230031。
徐 嵐 安徽警官职业学院图书馆研究馆员。 安徽合肥,230031。
刘 涓 安徽警官职业学院图书馆馆员。 安徽合肥,230031。
(收稿日期:2020-10-06 编校:陈安琪,左静远)
