基于特征显著性的点云自适应精简
2021-08-23张亦芳刘光帅
张亦芳,李 立,刘光帅
(西南交通大学 机械工程学院,四川 成都 610031)
0 引 言
点云精简是将密集的点云数据在保留模型特征的前提下进行简化,以提高计算机处理的速度和后续重建曲面的光顺性。目前,常用的点云精简算法为基于传统特征的点云精简算法,例如曲率精简法[1]、法向矢量精简法[2]。该类算法以曲率或法向矢量作为来衡量局部细节特征和复杂度的标准,能够很好保持点云的细节特征。但这类方法通常需要以人工设定阈值参数的方式进行特征识别,所设定的阈值对不同的点云模型难以达到同样的理想精简效果,导致这类算法适用性不广。
与依赖于曲率、法向等底层特征方法不同,模拟人类视觉注意机制的显著性检测能够自动捕捉不同场景中的重要信息。显著性概念被广泛应用于计算机视觉和图形学任务中[3]。受二维显著性检测的启发,三维显著性检测通常基于全局显著性计算,即对全体点云或网格顶点特征聚类成簇,由簇的显著性来计算得到全局显著性。例如,Wu等[4]利用K-means聚类和近似最近邻搜索将顶点分组成簇求解簇的显著性,然后根据簇的显著性插值得到单个顶点的全局显著性。Tasse等[5]利用模糊聚类将点集分解成小簇,将每个簇的唯一性和空间分布定义一个点簇概率矩阵来计算每个点的全局显著性。Ding等[6]利用体素连通性分割算法将点云分解为小簇计算簇的显著性值后,利用随机游走排序法计算簇中的每个点全局显著性。这些全局显著性的计算方法在保持简单高效的同时,能够得到稳定的显著性映射,有效捕捉模型中大部分重要的视觉区域。已经被应用在三维数据处理视点选择[6]、分割[7]和点云缩放[8]等各个方面。但全局显著性不足之处在于丢失了簇内信息,降低了显著性区分不同性质点云的能力,若直接应用在点云精简上容易造成细节特征的丢失。
因此,针对现有点云数据精简算法适应性不强,通过对全局显著性算法的改进,提出一种基于特征显著性的点云自适应精简算法,算法在计算特征单词全局显著性基础上融合了单词类内显著性生成显著性词典,并根据点云的显著性值,通过配置不同的采样率,实现对不同尺寸、形状点云的自适应精简。
1 FPFH特征提取
传统的点云特征描述仅利用中心点的法向量、曲率等几何属性,未考虑与邻域点的相对关系,难以准确反映物体几何形状和特性。而快速点特征直方图(fast point feature histograms,FPFH)三维特征描述子,通过计算关键点及邻域点的多个几何属性关系构建直方图,能够较好反映物体几何形状和特性[9]。因此,本文选用FPFH 作为点云特征描述子。提取方法如下:
首先,为每一个点对构建Darboux框架。如图1所示,给定关键点pi及其法向量ni,领域点pj及其法向量nj。则Darboux框架的3个坐标轴(u,v,w)可通过这两个点及它们的法向量构建得到,即

图1 Darboux框架
u=ni
(1)
(2)
w=u×v
(3)
然后,基于上述所建立的Darboux框架,计算以下3个参数表达两点之间几何关系
α=v·nj
(4)
(5)
(6)
其中,α是点pj的法向量nj和坐标轴v的夹角,φ是向量ni和pij的夹角,θ是向量nj在wpju平面上的投影和坐标轴u的夹角。计算pi的k近邻中所有点对之间的(α,φ,θ),以统计的方式放进直方图中,就得到了点的直方图特征(simple point feature histograms,SPFH)。
最后,对点pi邻域内的各点分别计算其邻域内点的SPFH,得到最终的直方图(FPFH)
(7)
式中:wj是pi到点邻域内任意点pj的距离,作为计算权重。
本文采用FPFH 作为点云特征描述子时,将每个参数划分为11个子区间,最终形成33维的统计直方图作为点云特征描述,生成特征集合F={fi|i=1~N}。
2 特征显著性计算
获取点云FPFH特征集合后,特征显著性计算的主要步骤为:首先对特征进行k均值聚类,每类作为一种单词。然后由单词全局显著性和类内显著性计算单词显著性,形成显著性词典。最后根据显著性词典软编码单点特征,获得点云特征显著性。
2.1 单词全局显著性计算
提取点云FPFH特征集合F={fi|i=1~N}后,首先对特征集合进行K-means聚类,将每个聚类中心作为一个单词,得到特征词典W={wi|i=1~k},词典中不同单词的显著性不同。文献[4]通过计算每个类别与其它类别的差异定义全局显著性,这种显著性的计算方法在保持简单高效的同时,能够有效捕捉点云模型中大部分重要的视觉区域。故参考此方法计算单词全局显著性,公式如下
(8)
式中:wi和wj分别表示特征词典W={wi|i=1~k}中两个不同的单词,nj表示被编码到wj下的点云的数量,d表示卡方距离。文献[4]公式中的d采用的欧式距离,容易受点云模型中噪声和采样密度不均的影响。而文献[6]中采用的卡方距离受噪声影响较小,更适用于点云模型,故本文采用卡方距离度量单词之间的距离d。定义如下
(9)
由此所得的全局显著性的意义在于:一方面,通过对比度刻画单词间的差异,如果单词wi与其它单词wj区别较大,则代表此单词具有较强的显著性。另一方面,通过稀有性来刻画单词间的差异,如果其它单词内部点云数量较多,则此单词内的点云数量较少,内部点云数量较少的单词具有较强的显著性。
2.2 单词类内显著性计算
全局显著性仅考虑了不同单词间的区别,并未考虑单词内部点云特征的分布情况。单词内部分布如果分散,则表示包含的信息丰富,显著性强。反之,分布如果集中,则表示包含的信息少,显著性弱。而VLAD[10](vector of locally aggregated descriptors)可以描述单词内部分布情况。在Bow(bag-of-words)基础上改进而来的VLAD计算了每个局部特征与它对应的聚类中心的残差,能够有效解决类内的信息缺失问题。因此,利用VLAD特征来定义单词内部的显著性。
根据单词词典及点云的单词编码第k个单词的VLAD特征作为类内显著性
(10)
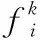
将VLAD(k)记为Sck,融合全局显著性特征Sgk,构成最终特征显著性
Sk=Sgk+λSck
(11)
由此构成显著性词典S={sk|k=1~K}。
式中,λ为组合权重,考虑到在显著性计算中,全局显著相比于类内显著性仍是主要影响因素,故用λ来调节单词内部显著性对最终显著度的贡献比时应取小值,本文λ取0.2。
从式(11)可看出,最终的特征显著性既考虑了单词间的差异,也综合了单词内部点云特征分布情况。相比于只考虑全局显著性的特征显著度计算方式,这种融合了类内差异的方法,能够提高显著性区分不同性质点云的能力,增强显著性描述相似区域点云的区分性。
2.3 特征显著性
获得单词显著性词典S后,根据点云特征fi与单词wk的距离,编码特征显著性。编码方法中传统的硬性表决编码方法只选择完全激活与其最相似的一个视觉单词来表达特征,忽略了与其它单词的相似性,容易丢失部分点云的特征信息。而局部软编码法[10]选择激活与邻近内k个相似的视觉单词来表达特征,能够更充分地保留点云特征信息。故本文采用局部软编码方式,选择激活与点云特征相似的Ni个单词编码特征显著性,表示如下
(12)
(13)
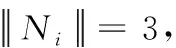
综上,点云特征显著性算法步骤具体如下:
算法1:点云特征显著性计算
输入:点云模型每个点的FPFH特征向量fi
输出:点云模型每个点的特征显著性Sfi
(1)输入点云的FPFH特征向量集,K-means聚类生成码本词典:W={wk|i=1~k};
(2)根据单词间的差异,由式(8)计算单词全局显著性Sgk;
(3)考虑单词内点云的分布,由式(10)计算单词类内显著性Sck;
(4)融合全局显著性和类内显著性由式(11)得到显著度词典S={sk|k=1~K};
(5)采用局部软编码方式,由式(12)计算所有点云的特征显著性Sfi。
3 点云自适应精简
在点云模型中存在平缓和变化复杂的不同区域,如果采用同一个策略对整个点云数据进行精简,则很有可能造成特征信息的缺失。因此,为了保证精简后特征的完整性,在不同区域应采用不同的精简策略。传统的点云精简算法采用的精简策略一般是根据曲率、法矢等几何属性,通过设定某个固定的阈值对点云进行精简,这样人为选取一个阈值会导致算法鲁棒性较差,选取的阈值可能对于某一种点云模型处理得比较理想,换了另一种点云后可能难以达到理想的精简效果。针对此类问题,本文提出基于特征显著性的自适应精简算法。精简原则是对点云均匀网格化后,根据每个网格内的特征显著性的不同进行不同程度的精简,特征显著性高代表此网格内的点位于特征明显区域的可能性越大,采样率应高,反之,显著性越低,采样率应小。算法的优势是能自适应计算每个网格内的采样率,无需设定相关的参数。具体过程如下:
(14)
然后,计算每种单词下点云数量的占比hk
(15)
式中:nk表示被分配到k类单词的点的数量,N表示点云总数。
(16)
此外,在对点云进行精简的过程中为确保特征信息的完整性,考虑到仅单独根据显著性精简可能会丢失部分特征细节区域。而利用点云的曲率能够快速检测到这些细节区域,故将点云曲率作为采样率设置的补充条件。在计算网格采样率后,若检测到网格内存在曲率较大的点,说明网格内点云位于特征区域的可能性大,则将网格采样率置为百分百,以保留此区域的特征信息。由于在计算点云特征FPFH阶段,利用(principal component analysis,PCA)算法计算点的法向量时可同时得到曲率,故此过程并不增加时间。
综上,点云自适应精简算法具体步骤如下:
算法2:点云自适应精简
输入:点云模型每个点的特征显著性Sfi
输出:精简点云
(1)将点云均匀网格化;
(3)由式(15)计算单词内点云占比hk;
(4)由式(16)计算网格采样率p_sample;
(5)检测点云的曲率,若存在大于0.1的点,将此网格采样率p_sample置为百分之百;若无则采用p_sample对网格点云数据进行精简;
(6)循环(3)到(5),直至精简完所有网格,输出精简点云。
经过以上计算,算法以特征显著性指导点云精简,在特征显著性高的特征区域保留更多的点,在特征显著性低的平坦区域精简更多的点,无需设定相关阈值,实现了点云的自适应精简。该算法完整流程如图2所示。
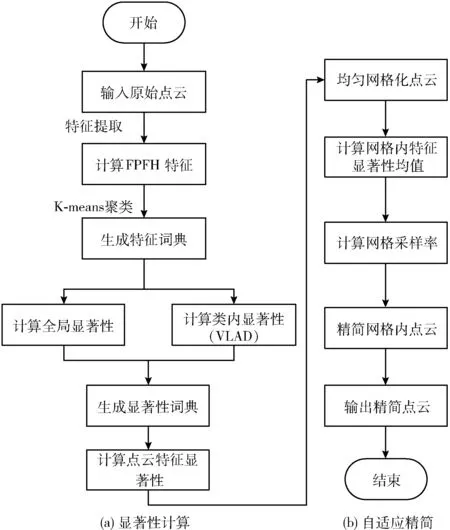
图2 本文算法流程
4 实验结果与分析
使用Matlab对算法进行编程,计算机配置为Win 10小系统,Intel Corei5、8 G内存和NVDIA GeForece GTX960M显卡。实验用到的点云数据来自斯坦福大学建立的3D点云数据库,均为PLY格式。
实验分为两部分。首先,为验证类内显著性算法的有效性,在不同类型模型下应用本文方法和文献[4]的方法,对比显著性检测的效果。然后,为验证自适应精简的有效性,在不同类型模型下应用包围盒法、文献[11]法、文献[12]法以及本文算法,对比精简效果并分析精简误差及效率。
4.1 特征显著性实验
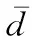
图3和图4中的图(a)是原始点云数据,图(b)是仅利用全局显著性算法计算每个点的特征显著性的效果,图(c)是融合全局和类内显著性算法每个点的特征显著性效果。图中灰度值从低到高代表特征显著性依次升高。从图3Skull模型可看出,图3(b)中仅利用全局显著性计算点的特征显著性时,眼眶、鼻骨和牙齿等区域显著性相似,且与颧骨及下颚骨区分度不高,而图3(c)中融合了类内显著性时,额骨的裂痕、牙齿、颧骨及下颚骨等不同区域的显著性区分明显,基本无混合。图4(a)中可看出Cow模型显著性高的特征区域主要集中在面部,而图4(c)中面部中的眼睛和嘴巴的区分度和显著性明显高于图4(b)。由此可验证本文融合全局显著性和类内显著性的算法能够提高显著性区分不同性质点云的能力,增强显著性描述相似区域点云的区分性。

图3 Skull模型显著性效果
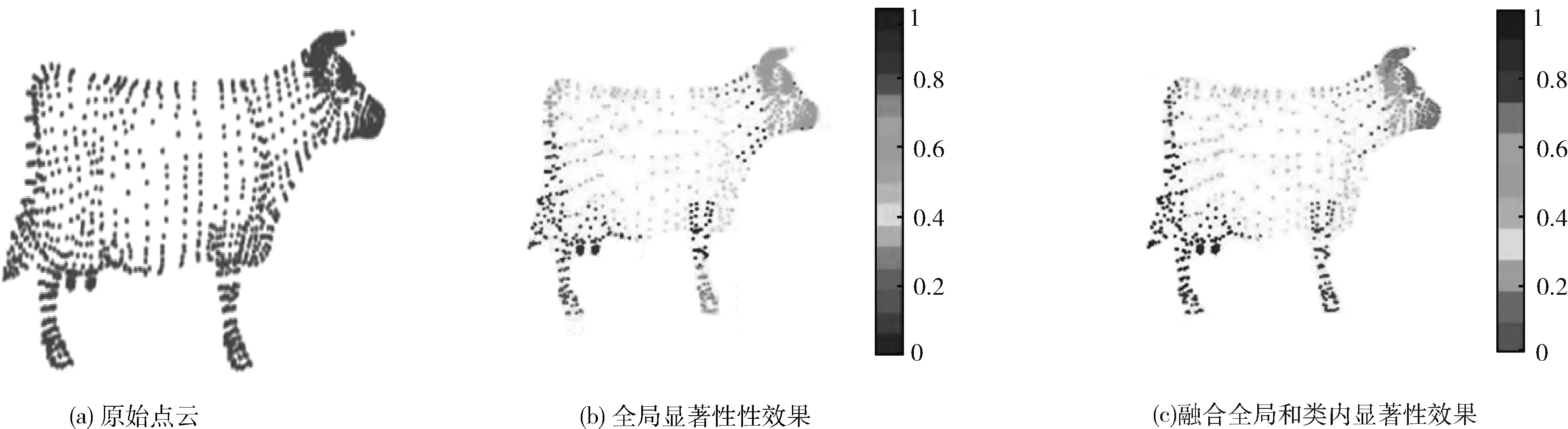
图4 Cow模型显著性效果
4.2 自适应精简效果对比实验
为验证本文算法的自适应精简效果,在不同类型模型下应用包围盒法、文献[1]法、文献[11]法、文献[12]法和本文精简算法对比精简结果,并分析精简误差及效率。文献[1]属于曲率阈值法,该算法将点云聚类后,将数据点之间的最大曲率差大于设定阈值不断的迭代细分以保留特征点。文献[11]和文献[12]都是基于显著性的点云精简,其中文献[11]的显著性检测是基于无向加权图,文献[12]的显著性检测是基于法向量。将这5种算法应用于3种不同类型的模型进行精简:一种为Chair模型,原始点云数据为49 960,该模型数据量较小,实际尺寸大,特征细节较少;一种为Hand模型,原始点云数据为327 323,数据量密集,实际尺寸较小,特征细节较多;一种为Dragon模型,原始点云数据为437 645,数据量大,实际尺寸小,细节特征丰富。为了增强显著性的区分性,聚类参数k取20,其它参数与4.1相同。将文献[1]方法阈值设置为1。定义精简比为精简掉的点数与原始点数的比值,将其保持在90%左右。图5、图6和图7为实验结果。

图5 Chair模型点云不同精简算法精简结果

图6 Hand模型不同精简算法精简结果
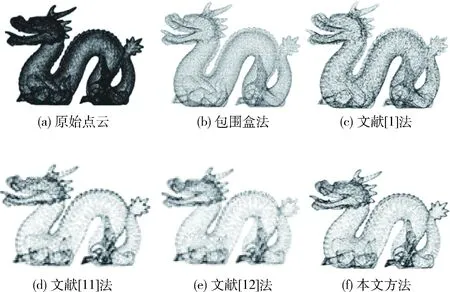
图7 Dragon模型不同精简算法精简结果
从图5Chair模型点云的精简结果来看,由于椅子模型本身数据量不大,特征信息不丰富,除了包围盒法在比较平坦的区域还是存在很多的冗余信息,文献[1]法、文献[5]法、文献[11]法还是本文方法都可以较大程度地去除冗余并有效保留点云特征。但文献[11]、文献[12]和本文基于显著性的点云精简算法取得的视觉效果更好。
从图6Hand模型点云的精简结果来看,包围盒法精简效果整体较为均匀,但特征信息丢失严重大,精简效果差。文献[1]法能够在一定程度上较好保留手骨模型的特征,但在指尖等细微特征区域信息丢失严重,精简效果一般。文献[11]法、文献[12]法和本文算法精简后的点云在关节等特征区域保留了大量的数据点,在骨头等非特征区域保留数据点相对较少,特征区分明显,精简效果优于包围盒法和文献[1]法。但本文算法在手骨关节处保留了更多的特征点,视觉效果优于文献[11]和文献[12]。
从图7Dragon模型点云的精简结果可看出,当面对数据量大、特征丰富的点云模型时,包围盒法在精简时由于没有考虑点云的特征分布,导致龙爪龙头等特征信息丢失严重,精简效果差。文献[1]法虽然考虑了点云的曲率特征,但需设定合适的阈值,从精简效果看该阈值显然不适用于此模型,以致冗杂位于曲率高的区域但不是特征的点云,例如龙身;以致丢失对位于特征区域但曲率不高的细节特征,例如龙的面部特征。文献[11]法、文献[12]法和本文算法精简效果明显优于前两种算法,但文献[11]法和文献[12]法已经开始丢失某些细节和边缘特征,例如龙眼、龙牙、尾巴的边缘等细节部位,而本文算法在这细节特征区域均保留完整。故,本文精简效果优于包围盒法、文献[1]法、文献[11]法和文献[12]法。
从以上实验结果可看出,在面对不同类型的模型时,包围盒法能获得均匀点云的效果,但容易丢失特征;文献[1]法需人工调试合适的阈值,才有可能获取合适的精简效果;文献[11]法和文献[12]在面对细节特征丰富的点云模型时可能会造成细节特征的丢失。而本文算法对不同的模型均获得良好的精简结果,验证了本文基于特征显著性的点云自适应精简在能够保留视觉显著性高的特征区域的同时,对不同模型均具有适用性。
为了更客观地评估点云精简后的物体描述能力,记录多个不同类型的模型误差。误差计算方法为求取精简点云与原始点云的最大误差和平均误差[5],表达式分别为
(17)
式中:d(g,S*)表示原始曲面S上采样点g到精简点云曲面S*上投影点g*的欧式距离。
多个模型精简误差见表1,当模型简单时,包围盒法、文献[1]法、文献[11]法、文献[12]法和本文方法的精简误差相差不大,但当模型复杂时,本文方法的最大误差和平均误差远小于其它4种方法,更好地保留了模型特征,但由于本文算法需进行单词类内特征显著性计算等算法流程,计算量较大,所以运行时间要多于其它方法,具体结果详见表1。
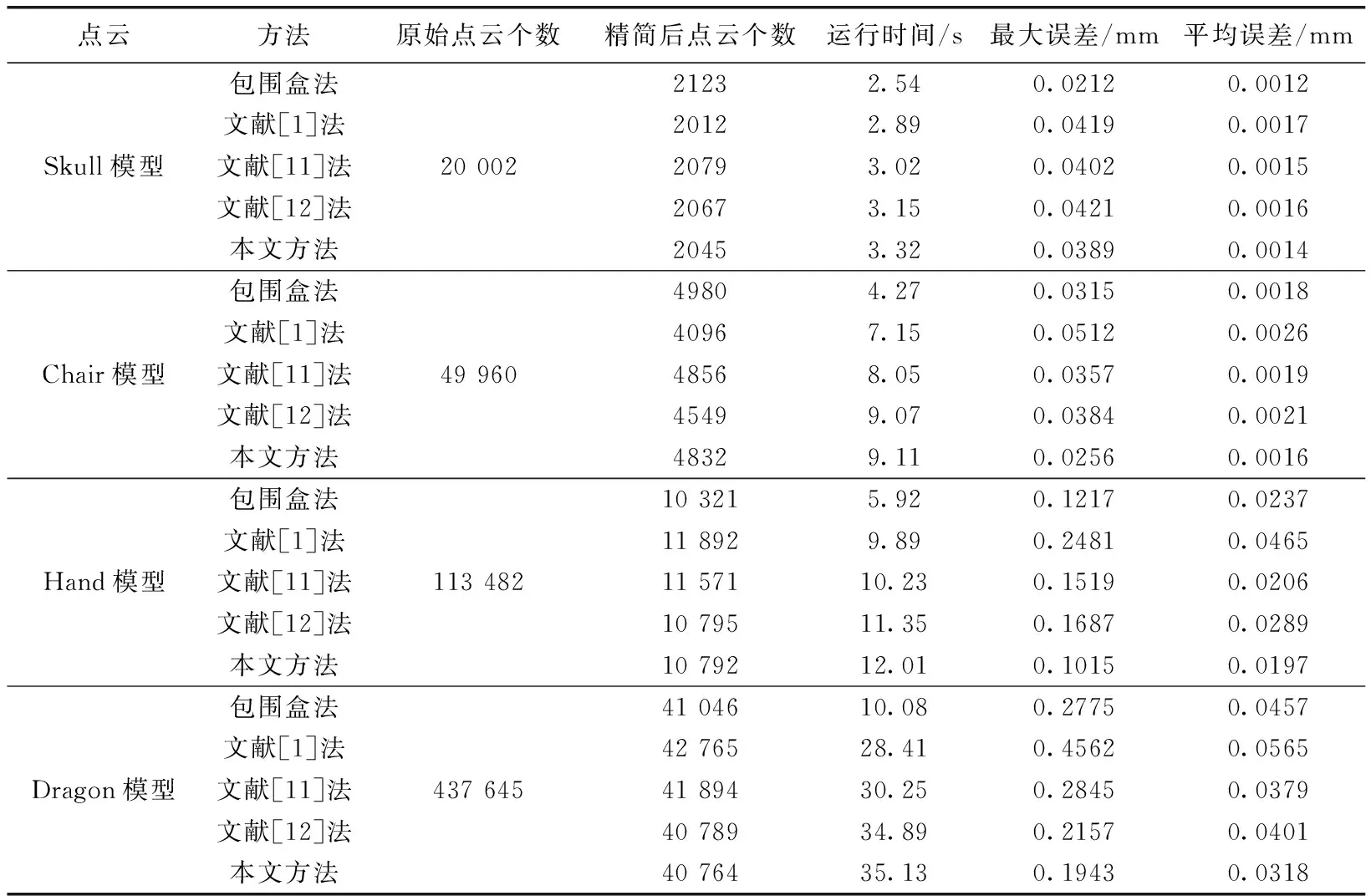
表1 精简算法结果对比
5 结束语
提出了一种基于特征显著性的点云自适应精简算法,算法在计算点云FPTP特征聚类生成单词后,在生成显著性词典的过程中,为避免单词内部特征信息的缺失,在计算单词全局显著性基础上融合单词类内显著性生成最终的显著性词典后,采用软编码的方式对点云进行特征显著性计算,并利用点云的特征显著性实现了特征显著性越强的区域,采样率越高的自适应精简。实验结果显示,本文的融合全局和类内显著性的显著性检测算法相比只计算全局显著性的显著性检测算法,提高了显著性区分不同性质点云的能力,增强了显著性描述相似区域点云的区分性。利用特征显著性对点云进行精简时,与其它4种精简算法相比,能够更好保留模型视觉特征明显区域的同时,对不同类型的点云具有适应性。
