机器学习视域下融合情感元素的社交网络信息交互度量化分析
2021-08-23郝志远
马 捷,郝志远
(1.吉林大学管理学院,长春 130022;2.吉林大学信息资源研究中心,长春 130022)
1 引 言
随着互联网技术的发展、数字时代的到来,社交网络愈发成为用户进行信息交互的主要载体。基于社交网络开放性的特点,用户能够不受限于时间和地点的约束,快速便捷地进行信息交流以及热点话题的讨论[1]。社交网络的便捷性与开放性促进了信息的传播,与此同时,也成为了影响话题舆论走向的主要因素。信息行为是情报学的核心研究领域之一,“交互”也已成为移动互联网时代用户共享多元信息资源的普遍性行为。对于社交网络上传播的热点话题信息,不同用户对待话题信息的情感倾向性不同,即同一个话题可能存在多个不同的情感倾向解读视角。根据研究表明,用户针对话题信息所产生的不同解读倾向与用户自身的性别、性格、喜好以及教育背景等有关。话题所附属的解读倾向种类越多,话题热议程度则越高,因此,舆论走向就更应得到正确的引导。
本文从交互与信息行为的角度出发,以网络用户产生的情感倾向性作为基本切入点,采用机器学习中的密度峰值聚类算法对热点话题的用户评论数据进行倾向性分类。同时,参考已有的情感极性值计算方法,融入方差加权信息熵的策略,并将所得解读倾向映射到计算结果中,提出衡量话题热议程度,量化话题信息价值的信息交互度计量方法。信息交互度概念的提出为网络监管提供了合理的度量参考,交互度数值变化具象地反映了舆论的演化趋势,通过信息交互度把控谣言形成时机,对促进互联网的健康文明发展具有重要的理论意义。
2 相关研究
2.1 信息交互相关研究
移动互联网时代,信息是不同个体间进行交流与联系的必要连接媒介。而随着互联网技术的发展以及用户信息需求所呈现的多元化趋势,使得“交互”越发成为网络用户群体间一种具有社会普遍性的信息行为方式。信息交互行为作为一种基于信息技术的更迭发展而衍生的具有丰富内涵的跨领域概念,国内外学者以不同的研究视角对信息交互行为进行了归纳与阐述。国外学者Costello等[2]从信息交互的应用层面出发,研究了血液透析患者在面对健康信息时所发生的信息交互行为,分析了不同场景对信息交互行为的影响。Buijs等[3]基于信息检索与人机交互的研究视角,将异步社会搜索作为一种新的、直观的信息搜索方法在论文中进行呈现,并通过这种方法实现用户在信息检索中的交互过程。Bronstein等[4]研究了用户的自身判断能力以及自我效能对信息交互行为产生的影响,进而提出了一种新的信息交互行为模型。此外,国内学者邓小咏等[5]针对网络用户信息交互行为的特征类型以及影响因素等方面进行研究,多角度地探究了信息交互行为的相关理论与思想。马捷等[6]认为,信息存在包括新闻、语录等在内的多种表现形式,而信息交互则旨在实现多元信息的传播过程与信息主体的情感宣泄。杨璐伊等[7]将信息交互行为解释为不同信息体间信息流相向传播的一种信息反馈过程,每一次信息的接收与反馈都能对信息体双方产生相应的映射效应,并影响双方接收与反馈的信息价值,进而满足信息流传播过程的延续性。孙璐等[8]基于网络技术层面论述了信息交互过程中实现信息价值提升的相关理论,并以此实现信息一致和信息增值。王晰巍等[9]从计算机与信息技术的角度出发,以用户的信息需求为基本导向,探析了信息技术以及相关工具对信息交互行为的影响。有相关学者基于信息交互的类型[10]、基于信息交互的内部规律[11-12]、基于交互的方法[13-14]以及基于交互的对象[15]等不同方面对信息交互行为进行了分析与研究。上述学者对信息交互内容的研究,主要是针对交互与信息行为这一具体过程展开的论述,忽略了随着信息交互行为的产生而引发的对社交网络舆情走向的影响,本文将信息交互行为作为基本落脚点,深入剖析了信息交互对舆情演化趋势的影响作用。
2.2 情感分析与舆情分析相关研究
情感分析是基于自然语言处理以及文本挖掘等相关技术,针对具有个体主观感情倾向的文本内容或图片内容进行分类、抽取以及挖掘等操作以满足个体信息需求的分析过程。同时,也是一种综合多领域研究方法的交叉内容,相关研究始于学者Pang等[16]融合SVM(support vector machines)等有监督机器学习算法对电影评论数据进行的情感分类。随着信息技术的更迭发展,越来越多的学者致力于情感分析的研究中,按照研究文本对象的粒度划分,情感分析包括篇章级、句子级和词语级,如国外学者Berka[17]针对篇章级文本对象情感分类问题的准确性,在情感分析过程中引入人工智能基于规则推理和基于案例推理的策略,以实现篇章文本情感的准确分类。Sharma等[18]以Twitter用户评论数据为研究对象,分析相关评论的情感极性。与国外学者对于情感分析多以英文为研究对象相比,由于中文句式,语义等对比英文更为复杂,国内学者则更多对中文相关文本内容进行研究。例如,杨鹏等[19]针对细粒度情感分类问题,提出了基于注意力机制的交互式神经网络模型,通过该模型对上下文语义和方面词语义进行建模,提高分类的准确性。林敏鸿等[20]为解决多模态情感分类任务中的信息冗余问题,在张量融合方案的基础上提出了基于注意力神经网络的多模态情感分析方法。徐健等[21]从情感分歧角度出发,通过提出情感分歧度量化算法,为网络用户评论情感分析提供了新的研究方法和视角。
舆情是指在信息的传播过程中,随着用户与信息之间交互行为的进行,用户群体基于自身的情感、心理等因素的影响,对该话题信息所产生的不同评论倾向以及解读视角的集合。对社交网络舆情走向进行正确的引导,能够为政府相关部门提供有效的策略支持。目前,针对社交网络下的舆情研究,Fang等[22]通过对不同用户群体在不同热点话题中的评论倾向性进行研究,提出一种新的舆情理论。Stewart等[23]为了对舆情进行相关测算,采用社会调查的方法对舆情进行了度量分析。Rasmussen等[24]通过对社交媒体的相关数据进行分析,综合度量了公众舆情走向与政府部门政治决策间的关系,建立了相应的度量模型。高俊峰等[25]通过多种不同角度对网络舆情的发展趋势进行了分析与探讨,并提出一种新的舆情理论模型,为网络舆情的监管与把控提供了合理的理论支持。陈福集等[26]结合案例分析的方法,通过对具体实例进行剖析,将网络舆情的走向趋势以及信息的传播模式进行了针对性的分析与研究。王晰巍等[27]通过对新浪用户的舆情情感演化进行研究分析,利用分类算法进行情感分类,进而提出一种用户舆情情感预测模型,对加强相关部门的信息监管能力具有重要的促进意义。与此同时,还有其他学者基于信息的生命周期[28]、基于舆情传播本质[29]以及基于网络舆情意见领袖[30]等方面对舆情进行了研究分析。
2.3 信息交互度相关研究
综上对信息交互行为的理解,本文所提出的社交网络“信息交互度”是指在社交网络环境中任意两个或多个主体对象针对某一话题或信息体(信息源),以主体对象主观感情倾向表现作为交互过程的信息反馈,通过量化信息反馈结果来反映话题或信息体(信息源)热议程度的概念。探究话题或信息体的“信息交互度”,能够为舆情演化分析以及广告影评分析等相关内容提供全新的研究评测视角。
上文所述国内外学者的相关研究为本文的研究内容奠定了理论基础,然而当前直接基于“信息交互度”这一概念的研究仍处于探索阶段。刘雅婷[31]为研究空间规划问题基于复杂网络节点分析以及粒子群算法等提出了“城区信息交互度”的概念。苗壮等[32]针对目前校园网络存在的问题,以某高校的校园网建设为研究对象,通过整合校园网络资源,提出一种基于私有云计算的信息交互模型。赵洪钢等[33]融合社会感知计算,提出了一种应用于无线传感器网络的信息交互模型。然而,一方面,上述“信息交互度”的有关研究内容主要针对计算机相关领域,着重于网络技术与算法的探讨分析,对于信息自身层面的研究与讨论仍具有一定的局限性;另一方面,现阶段国内外学者针对舆情分析以及情感分析的既有研究主要集中于单一的方法技术手段层面、纯粹的情感极性值计算和倾向分类层面以及舆情演化机理和引导策略层面等几个研究视角进行论证分析,所述内容更多以信息作为实验研究载体,过于强调用户主体性和用户情感的功能性。现有研究大多或利用相关算法进行情感分类,通过情感倾向类别与情感极性值分布研判舆情走势;或只将信息作为实验样本数据(输入变量)突出技术方法的可行性与先进性;或根据舆情特征分析舆情演化机理进而提出相应的政策方针,然而,这极大程度上忽视了信息本身在网络用户意见(情感)反馈过程中应具备的主体属性。社交网络信息交互过程实际上是网络用户信息的接收与再发出过程,在接收-发出过程中,信息作为中介主体承载用户的情感反馈,这就导致整个交互过程中信息量是浮动变化的。与此同时,舆情监管的本质是对社交网络言论、话题等信息进行的监测和管理过程,监管的直接对象是信息本身,而非用户情感分布,文章所提信息交互度以信息本身内涵为主导,通过浮动变化的信息量大小量化话题的信息价值来衡量话题的热议程度,不但充分体现了信息的主体效应,而且能更贴切、更直接地服务于网络监管人员对舆论导向和谣言时机的精准把控。因此,本文充分考虑社交网络用户与网络话题信息在信息传播过程中存在的交互关系,并将情感分析与信息交互行为相关联,从定量的角度出发,对基于用户信息行为的交互过程进行量化计量,进而为互联网监管部门以及网络的健康文明发展提供行之有效的度量参考。
3 研究框架
本文从定量的角度分析社交网络话题信息与用户的交互关系,通过融入用户主体的情感倾向构建信息交互度这一计量概念,以明确的信息交互度数值变化,厘清社交网络话题的舆情演化趋势,具体研究框架如图1所示。
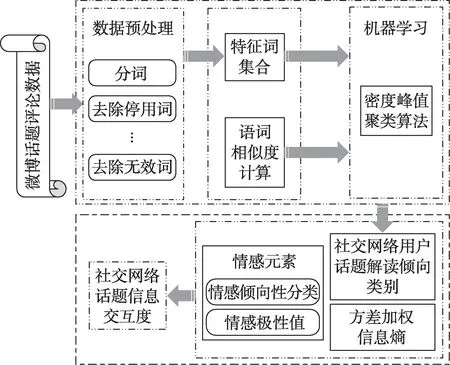
图1 社交网络信息交互度计量模型研究框架
3.1 关键词提取与语词相似度计算
3.1.1 文本关键词提取
本文所分析的实验数据,是长短不一的文本内容,所以文章首先通过“结巴”中文分词组件对获取的微博话题评论内容进行分词处理,同时进行去除停用词处理,再结合TF-IDF(term frequency-in‐verse document frequency)算法计算分词之后的特征词的权重,以获取样本数据的标签集合。
TF-IDF算法作为一种测算特征词权重的算法,常被应用于度量某个具体词条在一个既定文本中的作用程度[34]。TF-IDF算法中TF(term frequency)叫作词频,IDF(inverse document frequency)叫逆文档频率,计算结果为
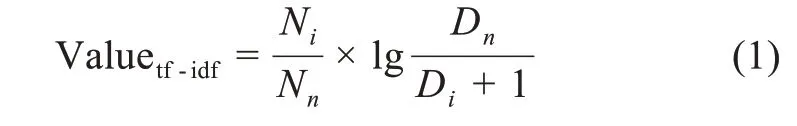
其中,Ni表示一条评论中某一个词出现的次数;Nn表示当前评论中所有词的个数;Dn表示所有有效评论的总数;Di表示具有该词的评论数目。
3.1.2 改进的文本语词相似度计算
上文通过TF-IDF算法抽取每一条用户评论数据的若干关键词,形成了相应的关键词集合。若针对所得集合直接进行评论倾向分析,由于未厘清数据样本间的潜在关系,则难以获取准确的评论视角类别。为深入探析数据样本的内在联系,本文在原始Ochiai系数的基础上,提出了改进的文本语词相似度计算方法,进而确定数据样本的相似度矩阵,为下文的聚类分析奠定基础。原始Ochiai系数计算公式为
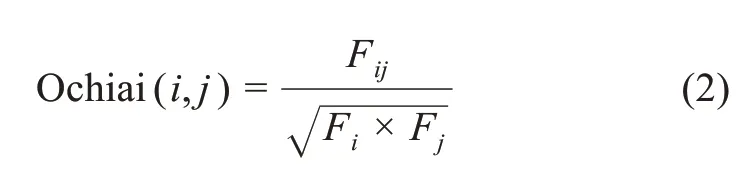
其中,Fij表示特征词i与特征词j在文本中共同出现的频数;Fi表示特征词i出现的频数;Fj表示特征词j出现的频数。原始Ochiai系数在计算语词文本相似度时过于强调公共词条的词频情况,然而公共词频数的高低并不能准确反映该词在文本中的作用程度,存在一定的局限性。因此,本文综合各词条在文本中的重要度,提出一种改进Ochiai系数的语词文本相似度计算方法,即
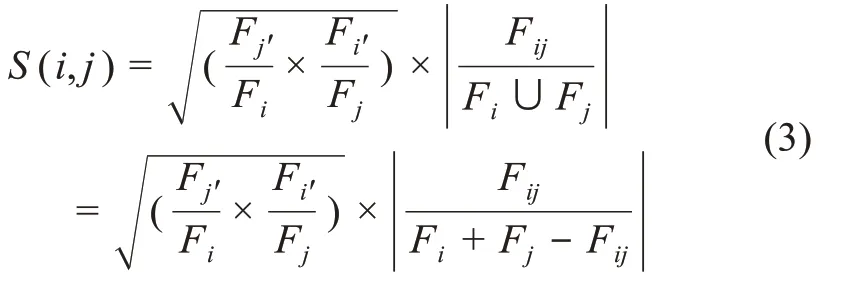
其中,Fj′/Fi与Fi′/F分别表示j词条对于i的重要度以及i词条对于j的重要度。
3.2 密度峰值聚类算法
密度峰值聚类是一种基于数据点密度属性进行数据分析的聚类算法,该算法于2014年发表于Sci‐ence杂志[35]。密度峰值聚类算法能够高效快速发现数据样本的密度分布,不局限于单一类型数据样本的聚类分析,相较于传统基于划分,基于层次等聚类算法,具有明显的优势。该算法主要遵循以下两个重要基本原则:①任意数据样本点均存在局部密度,而聚类中心则处于局部密度较低的近邻点中间;②针对余下数据点中存在局部密度较高的样本,聚类中心与该点的距离相对更大。
首先,算法计算数据点i与数据点j的欧几里得距离,即

其次,针对任意数据点i的局部密度,存在
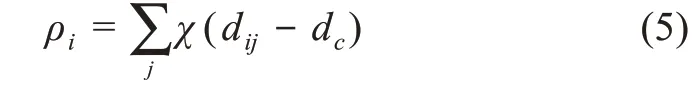
最后,在算法对数据样本点进行聚类分析时,还需计算距离变量:
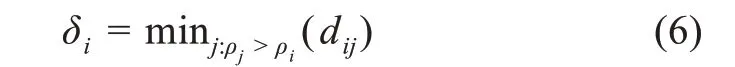
其中,δi表示数据点i与密度较高的样本点之间的最小距离。
3.3 信息交互度计量模型
本文认为,一个话题信息在用户的接收和再传播过程中,原始信息由于形成了与用户之间的交互关系,进而产生了以用户情感为载体的附加价值。信息的附加价值实际上就是由于交互过程中,用户基于自身的文化背景、性格以及喜好等因素所产生对话题信息的不同解读视角,并以不同情感倾向作为信息反馈所得的信息价值。因此,对于本文所论述的信息交互度概念主要有如下定义。
定义1:信息具备自身的内在价值以及面向对象的使用价值[36],根据马捷等[6]所提出信息交互行为的相关概念,可以认为用户在信息交互过程中,针对话题信息所表达的情感宣泄展现了该信息的使用价值。因此,信息交互度是指社交网络用户在获取热点话题信息使用价值的过程中,针对所获取的信息使用价值形成自身情感反馈,并以此情感反馈衡量话题热议程度以及监测舆情演化趋势的量化概念。
由上文定义可知,当社交网络话题信息交互度越高时,话题所具备的信息量越大,话题的热议程度则越高;反之,则话题的热议程度越低。综合上述内容,通过借鉴已有学者关于信息价值的度量研究[36],构建出本文所研究的信息交互度计量模型,基本思路如图2所示。
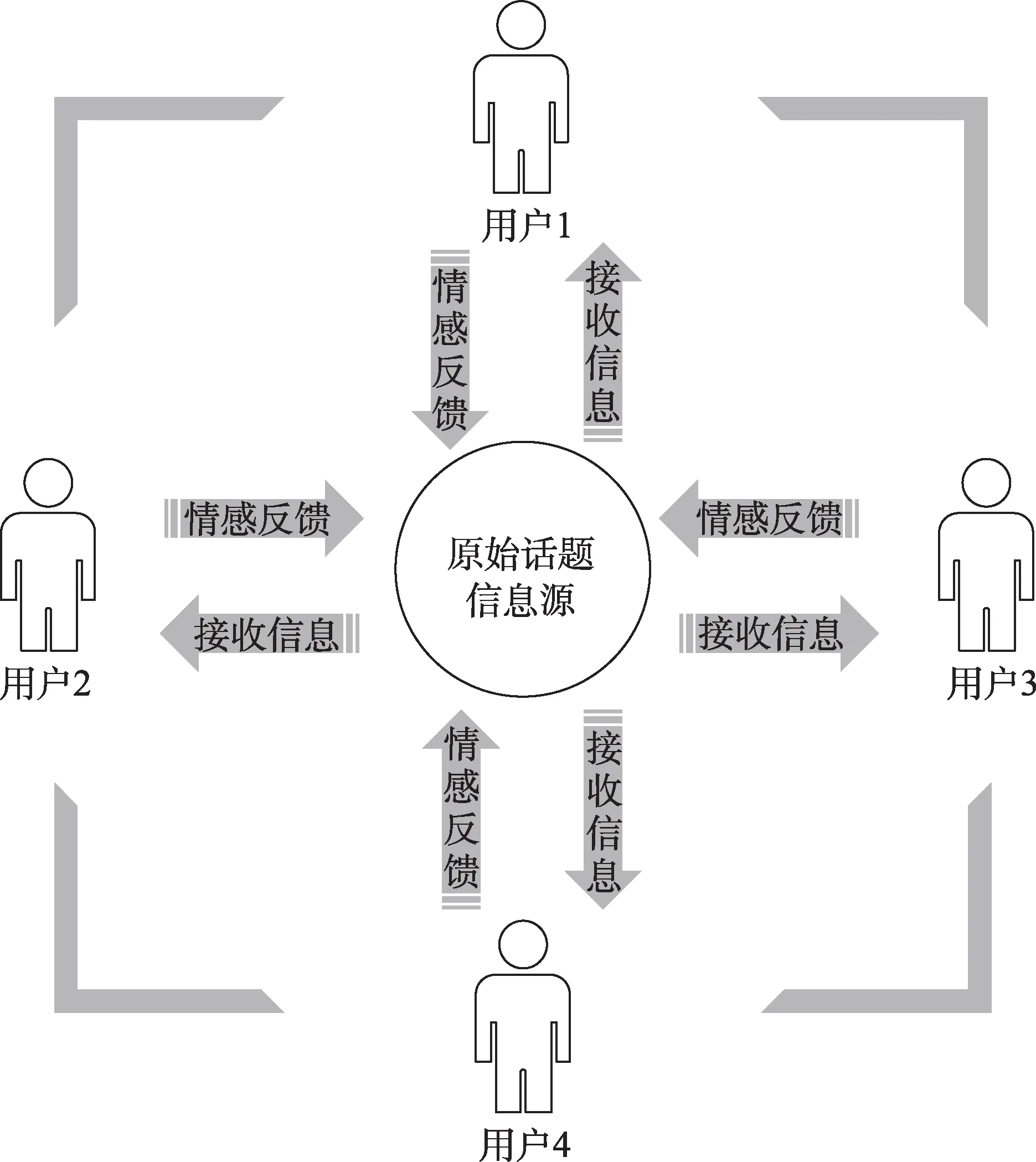
图2 信息交互度计量模型思路图
受徐健等[21]进行情感分歧度算法研究的启发,本文引入方差加权信息熵的策略进行信息交互度的量化研究。方差作为衡量随机变量与期望值之间的离散程度,在文章中用来反映不同情感极性值与平均情感之间的波动情况,当方差越大时,说明该话题下社交网络用户的情感反馈差别越大,因此,更容易对舆情的发展产生不良的导向影响。信息熵是用来度量话题信息所包含的信息量大小,对于社交网络话题而言,该话题的信息熵越高,话题所蕴含的信息量越大,更容易引起社交网络用户交互行为的产生。因此,本文将方差加权信息熵理论作为信息交互度计算的基本思想,信息熵的基本概念模型为
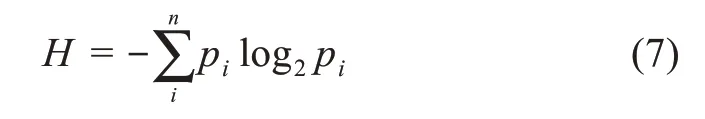
其中,H表示信息熵;pi表示某一个随机事件的概率分布。对于本文所提基于方差加权信息熵的信息交互度计量模型具体表示为
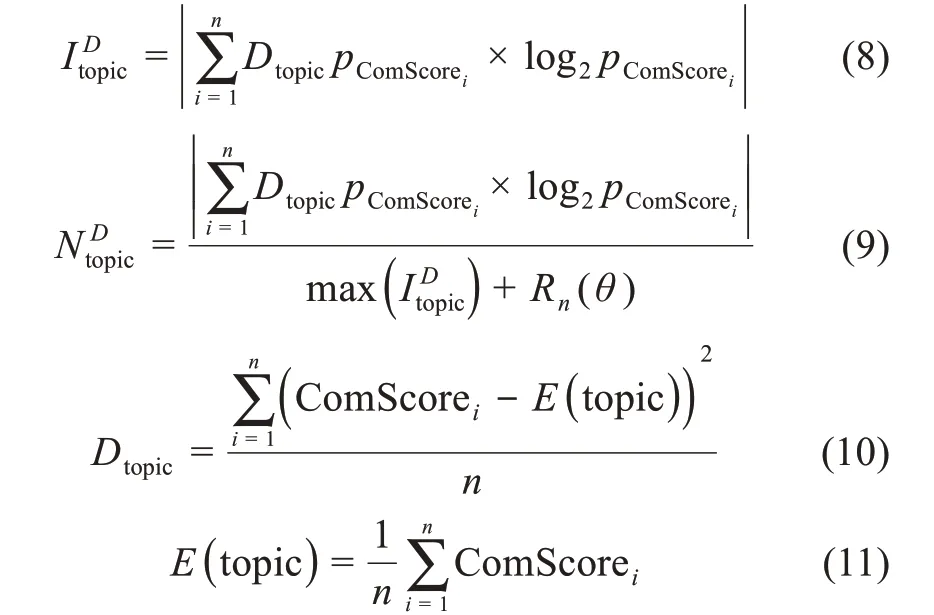
其中,PComScorei表示第i条评论的情感极性值出现的概率;n表示不同情感极性值的个数;Dtopic表示该话题所有评论的情感极性值的方差。max(ItDopic)表示所计算的方差加权信息熵的最大值;Rn(θ)表示一个影响因子余项,余项的作用是将所有信息交互度计算结果归一化到(0,1)区间。ComScorei表示第i条评论的情感极性数值;E(topic)表示该话题所有评论的情感极性值的期望值。
由上述公式可知,当NtDopic越大时,话题的信息交互度越高,则反映话题能引起的热议程度越高;反之,则话题能引起的热议程度越低。这恰好符合实际情况中对交互概念的理解,用户信息的交互度越高,说明用户所获取话题信息的使用价值实现增值,即用户更容易产生情感反馈进行情感宣泄。因此,本文所提信息交互度的概念正好可以用来说明话题信息的热议程度。
4 实证分析
为验证所提信息交互度概念在量化分析热点话题受热议程度以及舆情演化趋势方面的有效性,本文通过选取新浪微博热搜话题的真实用户评论作为实验数据,采用上文所述信息交互度计量模型计算该社交网络话题的信息交互度,并对实验结果进行对比分析。
4.1 数据来源
2020年7月5日,“杭州来女士神秘失踪”案件发生后,该案件引起了网络用户的持续关注,一时间“来女士去哪儿了”成为了微博热搜话题。本文选取头条新闻、央视新闻、澎湃新闻、新浪新闻等官方微博发布的相关话题内容的用户真实评论作为实验数据源,并利用爬虫工具从该话题用户评论内容中爬取7月18日—7月25日共计26932条评论数据,爬取的内容字包括用户ID、评论内容和点赞数等,实验数据统计如表1所示。
通常情况下孕妇的生产方式有两种:自然分娩和剖腹产分娩,分娩过程中会产生出血现象,一般我们认为难治性妇产科大出血是指自然分娩出血超过500ml,剖腹产分娩出血超过1000ml的情况。其中自然分娩的产妇分娩后的出血症状比较不易被察觉,因为顺产过程中胎儿通过产道产出以后,产妇会产生子宫收缩乏力的情况,这时胎盘的血窦不能及时闭合,就会有大出血的现象发生。若产妇分娩后阴道血流量达到200ml,该产妇患此病的几率将大大增加,由于在收集或实测的过程中,会造成产妇流失不必要的血流,一般状况下产妇的估测失血量仅占实际失血量的二分之一,所以很容易发生分娩后出血的状况,所以通常情况下没有引起重视。
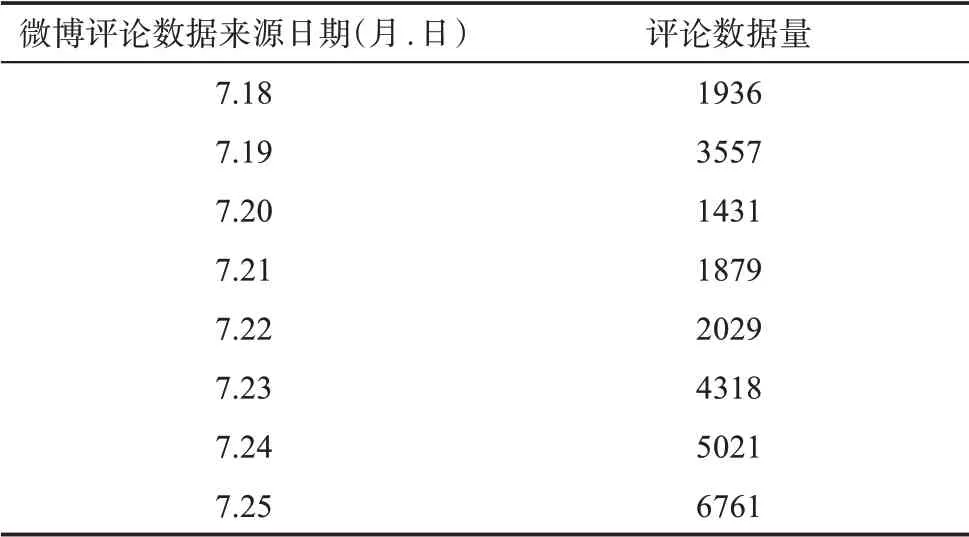
表1 实验数据统计表
4.2 话题解读视角确定
4.2.1 文本特征词权重计算
为将微博用户的文字评论内容进行聚类分析处理,本文采用了TF-IDF算法对实验内容进行了特征权重的计算。所获取的评论字段中存在一些与该话题内容相关性较低的文本数据,比如,微博ID为7152678733发布的符号评论,微博ID为5643869270发布的广告评论等,针对这些与需求信息不相关的内容字段,本文将进行筛选过滤处理。通过筛选之后的剩余数据样本为22163条,对预处理后的文本内容再进行分词处理以及去停用词处理,得出情感词、否定词以及程度副词等,再利用TF-IDF算法计算出分词之后的TF*IDF值。将计算所得的TF*IDF值权重集合通过第3.1.2节中所提出的改进文本语词相似度计算方法以形成相似度矩阵,进而进行密度峰值算法的聚类分析。
4.2.2 基于密度峰值算法的聚类分析
本文利用MATLAB软件进行聚类分析,在计算得出相似度矩阵后,将矩阵代入到密度峰值聚类算法中作为实验输入。针对实验样本数据,聚类中心选取的决策图如图3所示,根据上文所论述的密度峰值聚类算法原理,通过判断γ值大小,选取具有局部密度值和距离均相对较大的数据样本点作为聚类中心点,γ值的计算公式为
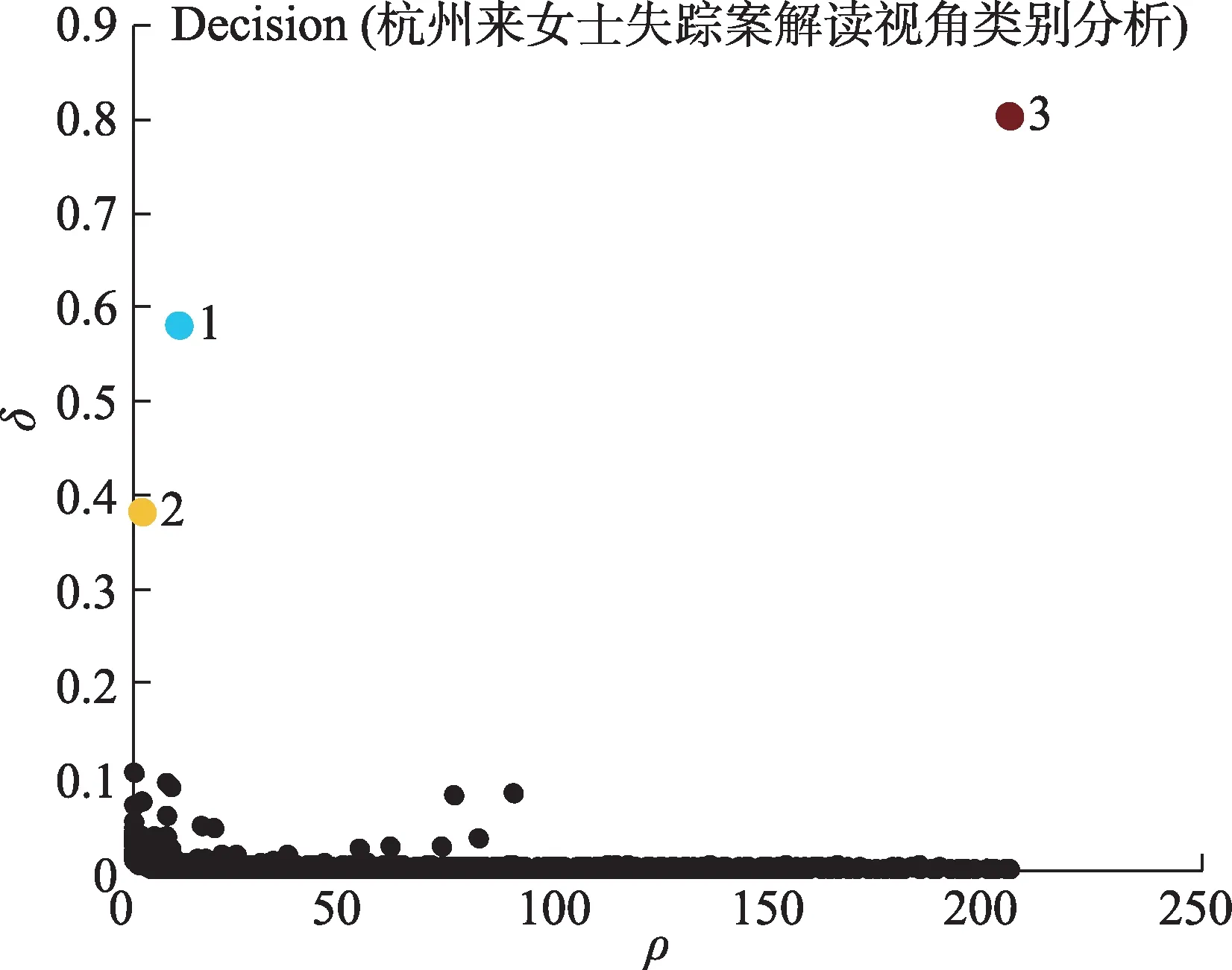
图3 数据样本聚类中心决策图

γ值越大,该点成为聚类中点的可能性就越大;同时,根据图4可知,非聚类中心点的γ值处于平缓趋势。
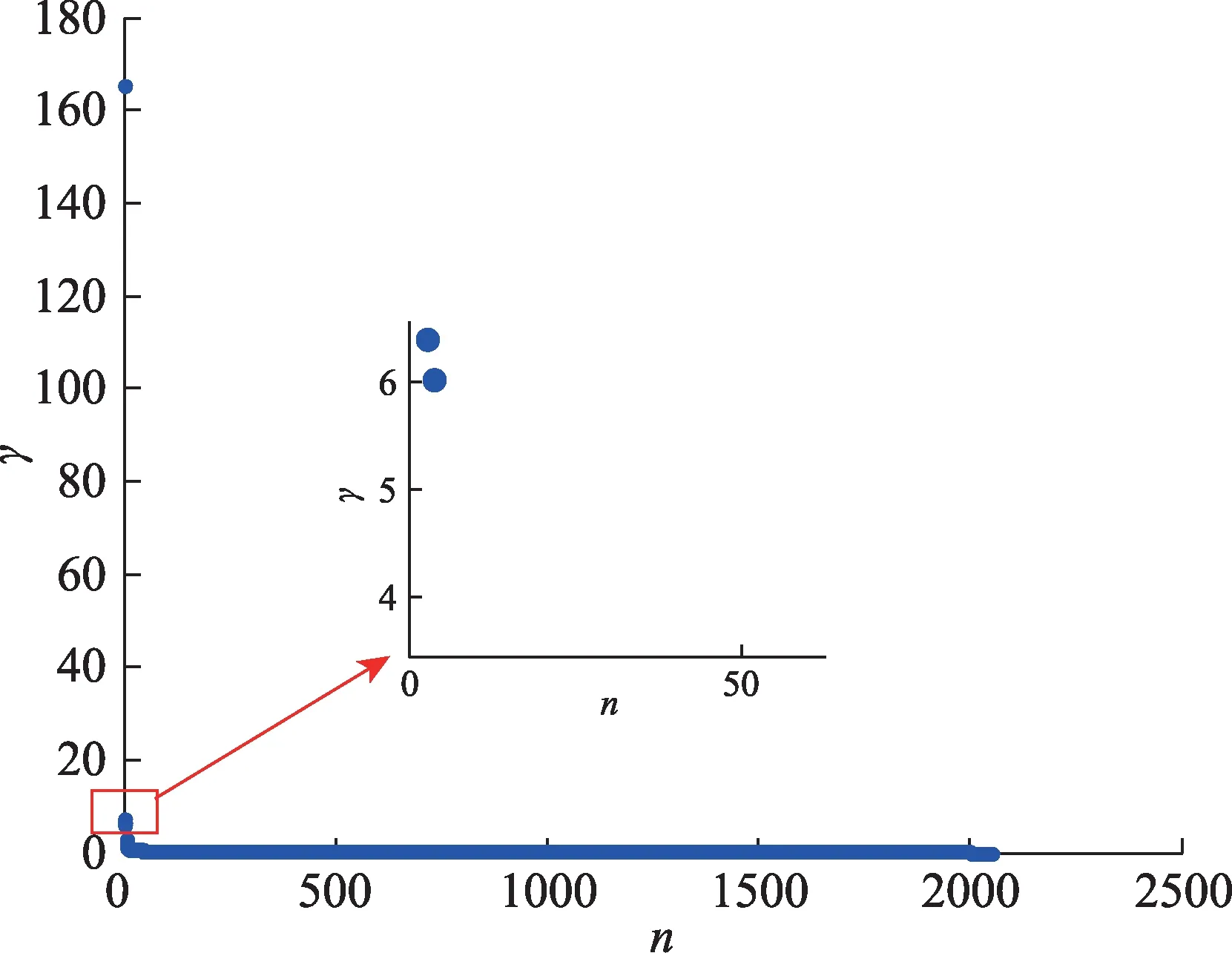
图4 γ数值变化趋势图
结合上文对解读视角的聚类分析可知,对于评论数据,社交网络用户所进行的解读视角或话题的主体对象主要分为3类:“丈夫”“来女士”和“警察”,所有评论内容基本围绕这3类对象展开,根据每一类对象的高频词进行可视化分析,具体如图5所示。

图5 3类主体对象可视化展示图
4.3 信息交互度计算
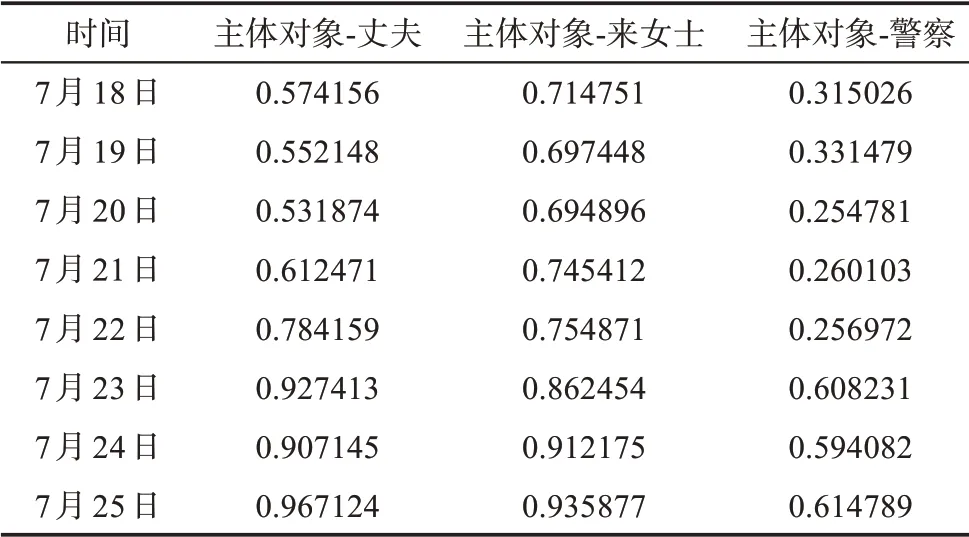
表2 7月18日—7月25日各主体对象信息交互度计算结果
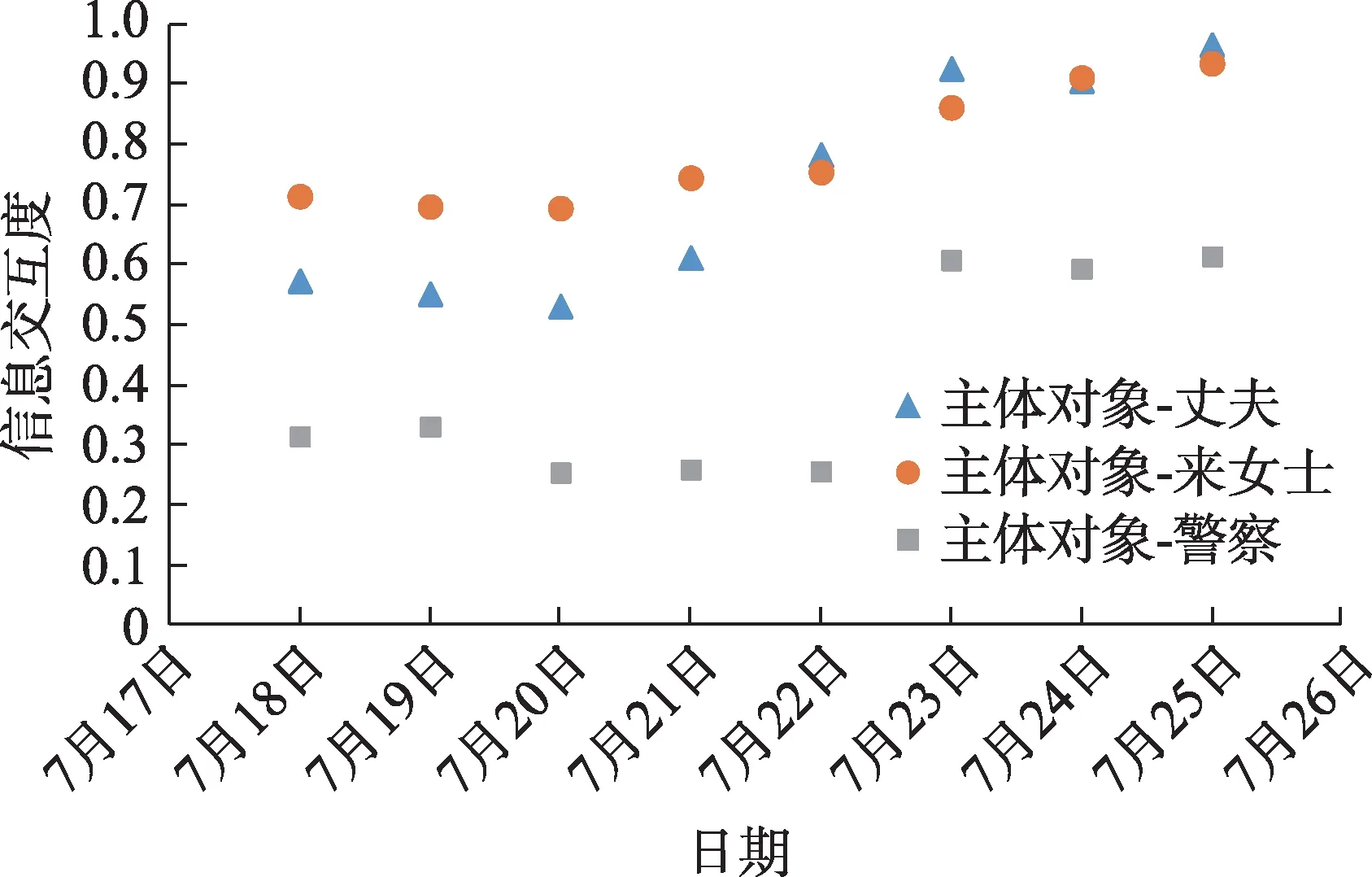
图6 各主体对象信息交互度可视化展示图
4.4 结果分析
本文融合情感元素提出信息交互度概念旨在实现舆情的量化分析,通过具象的数值变化反应社交网络舆情的演化趋势,为互联网相关部门提供一种新的舆情评判视角。从图6可以明显看出,3类主体对象中,“警察”主体的信息交互度最低,一方面,是因为在事件的起始阶段,社交网络用户的注意焦点更多的聚集于案件的当事人,即失踪的来女士身上,而警察作为案件的侦查人员及通报人员,用户认为相关调查行为均为警察自身任务所在,因此不会过多聚焦于警察主体。另一方面,由于案件进展相对缓慢,结合图5的词云可视化也可以得出,用户对警察更多持以怀疑、不理解的情感认知,因此,与警察相关的语词文本是“犹豫”“浪费警力”“迟疑”“效率低下”等。
对于“丈夫”主体而言,结合图5的词云可视化,网络用户对于这一主体的情感倾向由怀疑向指责发展,与此同时,由于众多网络用户始终认为来女士的神秘失踪与丈夫有关,因此,“丈夫”主体的信息交互度均相对较高。此外,根据图6可知7月18日—7月21日“丈夫”主体信息交互度低于“来女士”主体信息交互度;而7月22日—7月25日“丈夫”主体信息交互度又反超“来女士”主体信息交互度,这是因为在起始阶段,来女士的踪迹更能聚焦用户的关注点,而随着时间的推移,越来越多的证据显示是丈夫杀害了来女士,网络用户则开始更多的聚焦于“丈夫”这一主体对象,结合图5的词云可视化也可以发现与丈夫相关的文本更多出现“恶魔”“魔鬼”“有问题”“虚伪”等关键词。
对于“来女士”主体,从表2和图6中可以看出,7月18日—7月21日的3类主体对象中,“来女士”信息交互度最高,因为在案件初期,网络用户对于“来女士如何突然消失”“来女士到底去哪儿了”这一类的话题充满兴趣,用户进行信息交互的焦点是“来女士”这一主体,这就使得前期的信息交互一直处于较高的程度。然而,随着案件的深入调查,来女士的神秘失踪终于揭开了谜底,网络用户在关注这一主体的同时,附带的情感倾向也是由开始的好奇向最终的惋惜和同情发展,结合情感分析和图5的词云可视化也可以得知,与“来女士”相关的关键词文本多为“遗憾”“可怜”“惋惜”等关键词。
就该话题整体而言,社交网络用户以自身情感反馈作为该话题的交互结果,并将情感值融入信息交互度的概念中,通过信息交互度的变化分析话题的舆情演化趋势,本文为验证所提概念的有效性,将话题整体的信息交互度变化趋势与该话题的百度指数搜索趋势进行比较分析,如图7和图8所示。根据图示内容可以知,在7月18日—7月25日该话题生命周期区间内,话题整体的信息交互度变化趋势与百度指数的搜索趋势总体吻合,这就意味着信息交互度在一定程度上能够反映社交网络热点话题的舆情演化趋势。结合该案件真实进展,7月23日警方确认来女士已经遇害,并且嫌疑人为来女士丈夫,这一消息更是聚焦了大量网络用户的注意力,信息交互度与搜索指数在7月23日均呈现大幅度的上升。与此同时,该话题的信息量更大,网络用户更能产生较强的交互行为,而这就为谣言的传播或者网络争端事件的发生提供了可乘之机。综合实际情况也可以得知,7月23日警方也对多数网络谣言进行了辟谣。
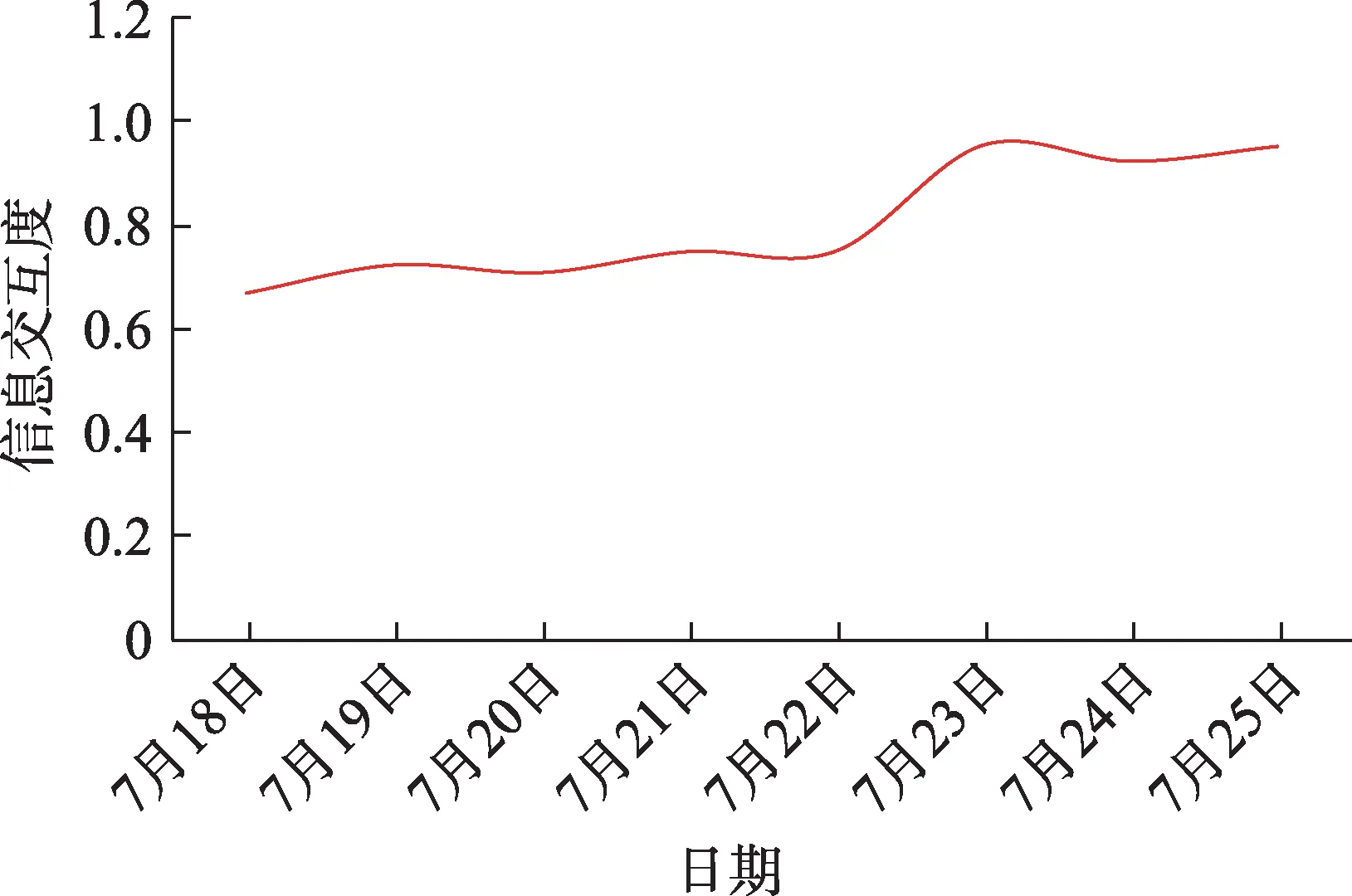
图7 话题整体信息交互度可视化展示图
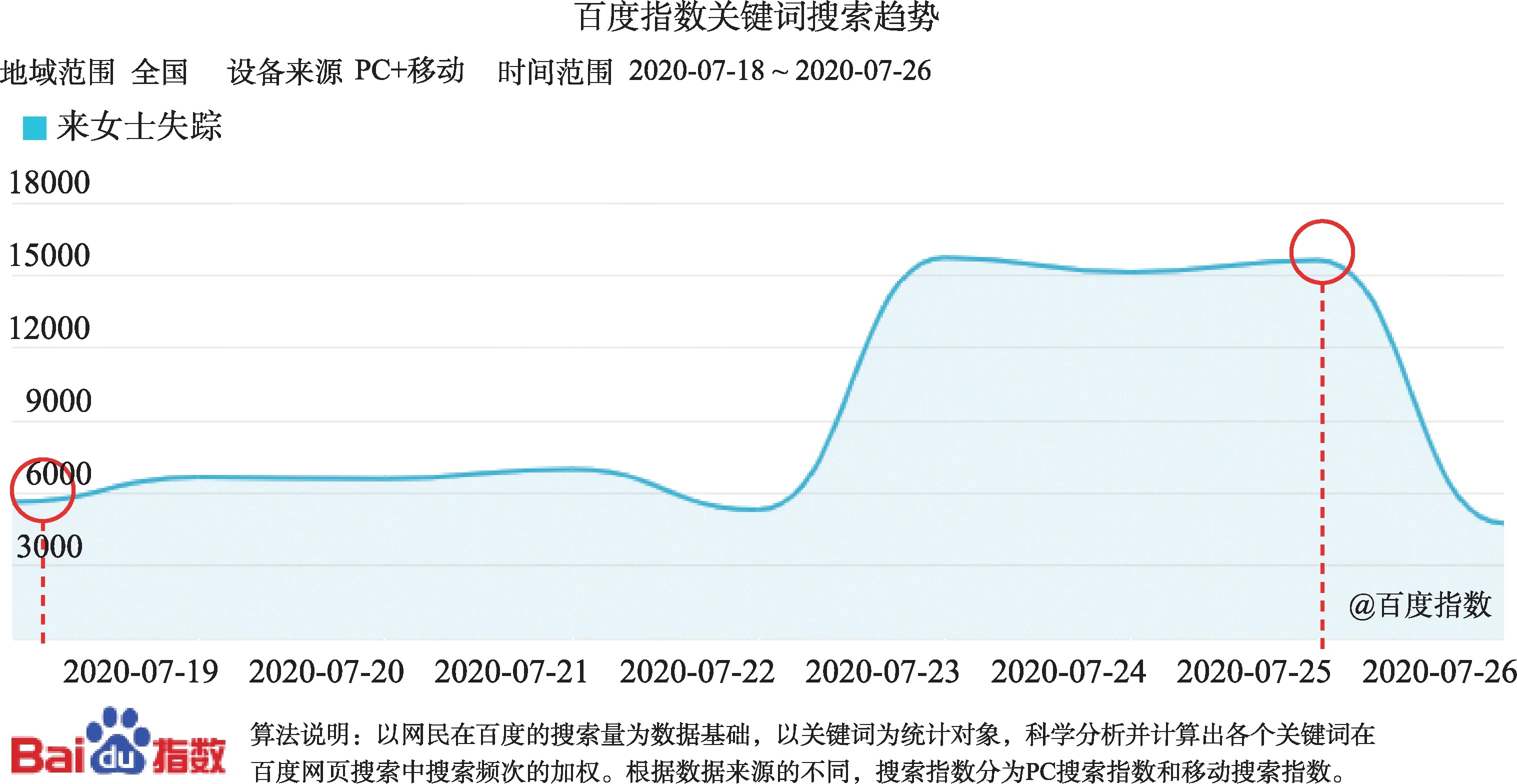
图8 话题信息百度指数趋势图
综合来看,通过分析基于用户情感视角所构建的社交网络热点话题信息交互度能够反映该话题的舆情演化趋势,同时,量化的数值变化更能具象化呈现舆情的走势发展,根据不同阶段社交网络信息交互度的具体数值,有利于网络监管人员对舆论导向的精准把控以及谣言散布时机的有效预警,进而为互联网监管部门以及网络的健康文明发展提供行之有效的度量参考。
5 结语
本文以社交网络用户的交互与信息行为作为基本研究出发点。在理论层面上,为对文本数据进行特征词提取,结合了TF-IDF特征词权重计算算法,同时,为将共现矩阵更好地转化为相似性矩阵,本文针对原始Ochiai系数存在的局限性,提出了一种改进的相关系数计算方法。为实现对文本数据样本的聚类分析,一方面,本文引入密度峰值聚类算法,将计算所得的相似性矩阵输入到密度峰值聚类算法中,得出该样本数据的聚类决策图和γ数值变化图,进而确定该数据样本的聚类中心以及最终的聚类数目[37-38]。另一方面,为将交互与信息行为研究从量化的角度进行分析,本文融合情感元素,定义了信息交互度的基本理念,并引入方差加权信息熵的策略思想构建了信息交互度的概念模型[39]。在实践层面上,本文选取“杭州女子失踪”这一微博话题,通过对微博用户的评论内容进行信息交互度模型的实例研究,结合百度指数关键词搜索趋势对信息交互度模型所得的结果走势进行佐证,旨在证明该模型的理论可行性和有效性。本文所进行的研究,在舆情分析过程中突出信息自身的直接效应和主导作用,规避了以单一情感类别和情感值分布作为舆情分析评判指标容易产生的误导性,深度契合了以信息本身为直接目标对象的舆情监测过程,对加强相关网络部门的网络信息监管,通过信息的量化趋势精准把控话题信息的舆情走向,促进互联网的健康文明发展,具有重要的现实意义。
当然,本文也存在一定的局限性。第一,本文采用的TF-IDF算法更注重词条在文本中的频数,对特征词条内部潜在的语义关系无法更好的体现出来;第二,在将特征词权重集合的共现矩阵进行相似性矩阵转化时,本文采用的改进相似性计算方法仍存在一定的局限性,这对后续聚类分析的结果精确性会产生一定的影响;第三,本文的初衷是希望通过对比百度指数话题趋势线的整体走势,印证信息交互度在舆情分析中所具有理论可行性与实践有效性。另外,百度指数所呈现的是话题关键字的搜索量,属于搜索过程的频数反馈,强调的是一种数量上的趋势研究,而本文所提信息交互度量化模型是以信息量大小映射信息价值,衡量话题热议程度,承载了人主体(用户)的情感认知反馈,信息量不等于关键字的搜索量,两者从本质上还是存在区别的。再者,考虑到百度指数所具有的企业特殊性和技术限制性,本文无法在有限的篇幅内对两者进行深入合理的对比分析。这些将会在下一步研究中继续进行完善与改进。
