基于随机森林模型的台区相序识别方法
2021-08-21蔡永智唐捷危阜胜李健郭文翀董志奎杨银
蔡永智 唐捷 危阜胜 李健 郭文翀 董志奎 杨银


摘要:低压台区拓扑关系识别是实现电网智能化的一个关键基础,相对于人工识别,从数据挖掘角度进行识别,具有成本低、准确率高、时效性好的优势。就其相序识别问题,提出了基于随机森林算法的低压台区相序关系自动识别方法。首先基于随机算法原理搭建了用于台区相序识别的随机森林算法模型,并提出采用 F1_score统计值作为识别模型的评价指标;然后将搭建好的模型应用到实际台区进行训练,训练方式设置了两类测试集:口袋内台区测试集与口袋外台区测试集;最后将训练好的算法模型对测试样本进行相序分许。实证结果证明,所提方法对台区的相序拓扑分析有較高准确性,为低压台区拓扑分析提供了一种技术思路和可行方法。
关键词:低压台区;相序识别;随机森林
中图分类号:TM71 文献标志码:A
文章编号:1009-9492(2021)12-0050-04
开放科学(资源服务)标识码(OSID):
Phase Sequence Recognition Method of Station Area Based on Random Forest Algorithm
Cai Yongzhi1,Tang Jie2,Wei Fusheng2,Li Jian1,Guo Wenchong1,Dong Zhikui3,Yang Yin3
(1. Metrology Center of Guangdong Power Grid Co., Ltd., Guangzhou 510060, China;
2. Guangdong Power Grid Corp, Guangzhou 510060, China;3. Guangzhou Power Electrical Technology Co., Ltd., Guangzhou 510700, China)
Abstract: The recognition of low-voltage station topology is a key foundation for the realization of intelligent power grid. Compared with manual recognition, recognition from the perspective of data mining has the advantages of low cost, high accuracy, and good timeliness. Regarding the phase sequence identification problem, an automatic identification method of the phase sequence relationship of low-voltage stations based on the random forest algorithm was proposed. First, based on the principle of random algorithm, a random forest algorithm model for phase sequence recognition of station area was built, and the F1_score statistical value was proposed as the evaluation index of the recognition model. Then the built model was applied to the actual station area for training. The training method was set with two types of test sets: the pocket inner station area test set and the pocket outer station area test set. Finally, the trained algorithm model was divided into the phase sequence of the test samples. The empirical results prove that the proposed method has high accuracy in the phase sequence topology analysis of the station area, then provides a technical idea and feasible method for the topology analysis of the low voltage station area. Key words: low-voltage station area; phase sequence recognition; random forest
0 引言
随着社会的发展,用户对更可靠更优质的电能供应、更优质更贴心的供电服务的要求日益提升[1-2]。而技术进步推进了智能配电网建设快速发展,给电网公司管理电网运行及提升服务提供了技术支撑。配电网的拓扑结构是配电网进行线损分析、故障诊断、潮流计算、三相平衡等应用功能的基础。随着智能电表的普及,终端用户用电数据的积累,这使得能够对台区数据进行挖掘,研究台区运行数据高频采集、户变、相序与线户关系识别算法研究变为可能。
相序识别问题是拓扑识别的一个子问题,目前从数据驱动角度来分析相序识别已有较多的研究成果,大概可分为显式规则分析和隐式规则分析两种技术路线,显式规则分析是首先研究台区供电网络中各用户的电气物理特征,得到同相线用户和异相线用户的电气关联规律,以此为理论依据设计算法,唐捷等[3]建立了用户时空特性模型,证明了了同相线用户的电气距离更近,然后采用电压相关性来描述电表的集群特性,基于此提出了电压相关性分类结合电流优化的相序识别算法。张丽强等[4]采用线性回归方式描述了单相用户和同相母线的电压具有更好的回归效果。一些学者基于电压聚类进行相序分析,在实验中都取得了不错的效果[5-8]。采用这种方法所建立的算法普适性较好,计算效率高,鲁棒性强,但其应用效果受数据质量影响,背后机理复杂,难以分析改进。为此,从隐式规则分析来尝试解决这些问题,借用机器学习善于处理高维、非线性的复杂映射问题的特点研究机器学习算法的相序识别模型成为可能。
目前关于隐式规则的机器学习算法的相序识别研究较少,谷海彤等[9] 针对载波技术对网络拓扑的关联,提出了基于CNN-LSTM深度学习神经网络的台区户变拓扑关系的识别模型,该方法对台区户变拓扑识别问题提出了深度学习方式解决思路,但没有就相序识别做分析。本文从机器学习视角分析了相序识别的可行性,结合随机森林算法,搭建了低压台区相序识别模型,通过对实际台区的数据样本进行训练和测试,结果表明本文所提模型具有较好的适应效果。
1随机森林算法
随机森林算法是集成学习领域的常用算法,是由美国学者LeoBreiman结合Bagging方法和随机属性子空间理论提出的一种集成学习方法[10] 。随机森林中的决策树通常选用分类回归树决策树算法(Classification And Re? gression Tree,CART)决策树。Cart 决策树算法有两个基本思想:(1)建树过程是通过对训练样本集D进行递归地划分自变量空间来训练决策树的生长;(2)剪枝过程则利用验证数据集V进行剪枝[11-12] 。
1.1 建树过程
假设数据集D中有m个不同的类别Ci。Ci, D是数据集 D中Ci类元组的集合, |D| 和|C | i, D 分别是D和Ci, D元组的个数,则CART决策树使基尼指数Gini(D),计算公式为:
式中:Pi为Ci类元组出现的频率。
假设存在属性A,其数值形式为离散型,A的二元划分将D划分为D1和D2,则在给定划分的条件下,D的基尼指数为:
基于属性A的二元划分使得不纯度降低量为:
CART 算法遍历每个属性,将能产生最大不纯度降低的属性作为划分点。
1.2 剪枝过程
为防止建樹过程过度适应数据问题,CART 算法常用的是事后剪枝进行模型修正,即在决策树已经完全长成后对其进行剪枝,剪枝以后会生成剪枝子树,再利用交叉验证法筛选效果最优的剪枝操作,具体算法如下。
假设任意一颗以t为根节点的决策树Tt,其损失函数定义为:
式中: C( Tt )为决策树训练过程中的损失函数,在 CART 回归树中是均方差,在 CART分类树中是基尼系数; α为正则化参数;Tt 为叶子数量,表示树的规模,可以用来衡量模型容量。
剪枝以后得到仅含有 t 节点的单节点决策树,其损失函数为:
Cα( t )= C( t )+α
当α=0或者很小,则有不等式:
Cα(Tt )< Cα( t )
当α增大到一定程度则有:
Cα(Tt )= Cα( t )
假设此时α为α1 ,可以推导得:
当α>α1 的时候,如果需要得到最优子树则必须进行剪枝。当得到α的区间,就对完整 Tt 的任意子树{Ti , i =1, 2, 3, … , m},计算Cα(Ti ),找到最小Cα(Ti )所对应的子树。
2 台区相户关系随机森林识别模型
2.1 算法模型
随机森林是由 B 棵 CART决策树作为弱学习器组成的集合:{T1(X), T2(X), …, TB(X)},在分类问题中,统计 B 棵 CART的决策结果的投票,取最大投票数的结果作为最后随机森林的输出结果。
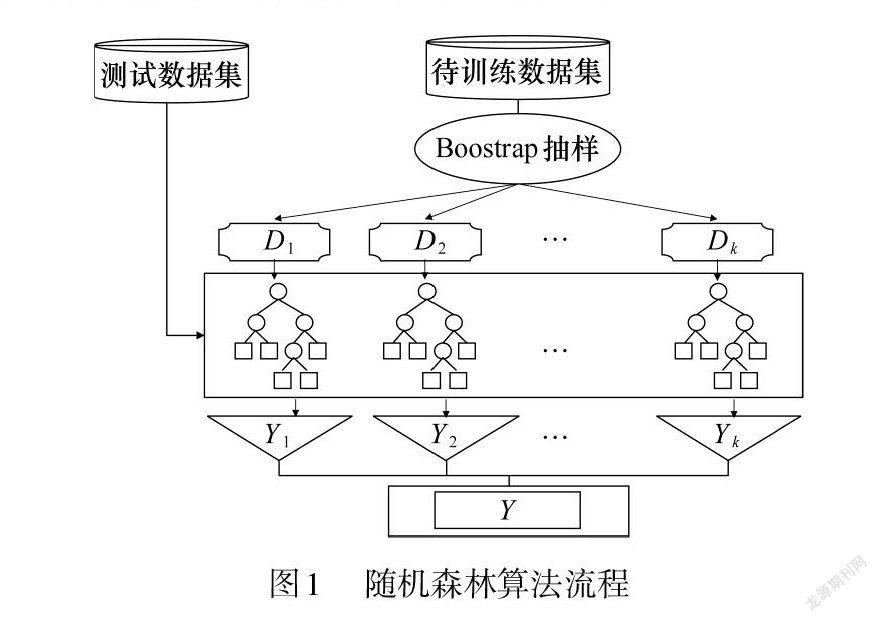
训练集样本数据,特征变量用 D ={(X1 , Y1), … , (XN , YN )}, Xi (i =1, … , N )来表示,而 Yi 指采用点的真实相序关系,其中 X 是具有 M 维的特征向量,表示为 X ={x1 , x2 , x3 , … , xM },是数据集 D 的一个训练样本,y 为样本标签,原始训练数据集有 N 个样本集, M 个特征变量,算法流程如图1所示。
随机森林相序识别模型的流程如下。
(1) 从数据集 D 中,采用 Bootstrap采样方法,进行有放回重抽样得到与原始数据集数量相同的数据集,重复上述操作 k 次构造训练样本集 Dtr ain ={D1 , D2 , …,Dk },其中每一个数据集 Di (i (2) 构建随机森林,随机森林是 W 棵 CART决策树经过训练构成的,树的个数 W 可人为设定。每颗决策树生长训练的过程是相互独立的,它们之间是无关联的,这样就进一步增加了随机性,提高模型的泛化能力。 (3) 计算随机森林的输出结果,随机森林的最终预测结果则是所有决策树结果的众数。 2.2 模型评价指标 相序识别分类属于多分类任务,本文将采用 F1_score以及准确率作为评价模型性能的指标。F1_score 用于多分类问题以及样本不平衡问题中,是查准率于查全率的综合。F1_score指标基于混淆矩阵计算得到。混淆矩阵结构如下: 其中真阳性记录与假阳性记录分别代表模型将阳性样本标记为阳,阴性样本标记为阳。假阴性记录与真阴性记录分别代表模型将阳性样本标记为阴,阴性样本标记为阴。为了引出 F1_score 概念,定义了查准率(recall)、查全率(precision)两个统计值: F1_score指标考虑了查准率与查全率的平衡,计算 公式如下: 3 算例分析 本文选用数据有两部分,一部分是东莞市某台区2019年12月份的台区智能电表的运行数据作为,另一部分是肇庆某台区2019年12月份的台区智能电表的运行数据。实证分析分为两部分,一部分是口袋内台区实证分析,即利用台区 A 的历史数据作为训练集,用台区 A 的某个时期的数据作为测试集;另一个口袋外台区实证分析,即利用台区 A 的历史数据作为训练集,用台区 B 的历史数据作为测试集。 采用随机森林算法得到口袋内台区和口袋外台区的 F1_score值结果如表1所示。 为了后续模型优化以及拓展建模思路,对模型分类中的错误样本进行画像分析对错误样本在结果信心分布、时间分布两个方面进行统计刻。随机森林相序识别模型分类信心指数分布如表2所示。从左到右本分别是随机森林相序识别模型对 A 相、B 相、C相的分类信心。 为了验证是否分类错误样本的模型信心指数是偏低的。统计分析如图2所示。 图2(a)中信心均值为0.56,可以看到绝大多数都在0.4~0.68之间,极少数为0.9以上。而且,有些样本的极大值居然比0.4小。图2(b)中信心均值为0.785,可以看到大多数正确分类样本的信息指数在0.65~1之間,很多是直接为1。 对于3分类而言,当信心分数很均衡的时候,0、1、2大部分应该在0.33之间,因此可知,错误分类的样本信心指数都不高。错误样本中有70%的信心小于0.64,可以推断造成错误的主要原因在于错误样本在当前特征集空间内,难以产生较大的信息不纯度下降,下一阶段应该着重优化特征集合,并增加训练样本所覆盖的台区量。 对错误样本的所发生的时间进行刻画,提取每个样本所属的日期,将星期一到星期日映射到(0,6)数值空间。统计结果如图3所示。由图可知,分类错误样本中周末的占比要远大于分类正确样本中周末占比,可以推断:(1)电压序列的特征分布存在周末与工作日的差异;(2)周末的分类难度较大;(3)由于周末于工作日存在差异,且周末样本少可能是造成难度较大的原因。上述分析有助于接下来对模型进行优化,理清思路。 4 结束语 本文在海量智能电表用电数据的基础上,针对以往低压台区人工相序识别准确率低,成本高等缺陷,提出了随机森林相序识别方法。区别于传统的数据分析方法,本文对训练样本设置了口袋内台区和口袋外台区,通过实证分析对两种样本的训练模型进行对比,结果表明,口袋外台区的相序识别效果和口袋内台区的相序识别效果相当,说明所提模型具有较好的泛化性和迁移能力。此外,对分类结果进行信心分布和时间分布统计,发现分类错误样本信心指数偏低,且在周末时段更容易发生分类错误,说明所提模型还需进一步优化特征集合的区分度,同时为了提高模型识别效果,样本可挑选工作日的用电数据进行相序分析。 参考文献: [1] 张勇军, 刘斯亮, 江金群, 等. 低压智能配电网技术研究综述 [J]. 广东电力, 2019, 32(1): 1-12. [2] 李西明,赵斌,杨一帆,等. 基于泛在电力物联网技术的配电网故障诊断方法优化[J].内蒙古电力技术,2020,38(1):63-65. [3] 唐捷,蔡永智,周来,等. 基于数据驱动的低压配电网线户关系识别方法[J]. 电力系统自动化, 2020, 44(11): 127-137. [4] 张丽强,丛伟,董罡,等.基于多元线性回归的单相电表相别判断方法[J].电力自动化设备,2020,40(5):144-156. [5] 徐晓东,吕干云,鲁涛,等. 基于智能电表数据与模糊C均值算法的台区识别[J].南京工程学院学报(自然科学版),2020,18(4): 1-7. [6] 连子宽,姚力,刘晟源,等.基于 t-SNE 降维和 BIRCH 聚类的单相用户相位及表箱辨识 [J].电力系统自动化,2020,44(8): 176-184. [7] 张然,孙晓璐,何仲潇,等.基于异常点检测和改进 K-means 算法的台区用户相别辨识方法[J].智慧电力,2020,48(1):91-96. [8] 耿俊成,张小斐,万迪明,等.基于电压曲线聚类分析的低压用户相序自动识别[J].电力大数据,2019,22(12):1-8. [9] 谷海彤,张远亮,卢翔智,等.基于深度学习的户变拓扑关系的识别方法研究[J].信息系统工程,2020(3):150-151. [10] 方匡南,吴见彬,朱建平,等.随机森林方法研究综述[J].统计与信息论坛,2011,26(3):32-38. [11] 李欣海.随机森林模型在分类与回归分析中的应用[J].应用昆虫学报,2013,50(4):1190-1197. [12] 姚登举,杨静,詹晓娟.基于随机森林的特征选择算法[J].吉林大学学报(工学版),2014,44(1):137-141. 第一作者简介:蔡永智(1984-),男,博士,工程师,研究领域为电能数据分析。 (编辑:王智圣)
