基于单幅图像学习的生成对抗网络模型
2021-08-20朱海琦李定文
朱海琦,李 宏,李定文
(东北石油大学 电气信息工程学院,黑龙江 大庆,163000)
0 概述
生成对抗网络(Generative Adversarial Network,GAN)是一种解决图像生成问题的深度学习模型[1],其基本思想源自博弈论中的零和博弈[2],由生成器和判别器通过对抗学习最终达到纳什均衡[3]。近年来,生成对抗网络的各种变体被广泛应用于图像超分辨率重建[4-5]、图像到图像转换[6]、图像增强[7]、图像风格迁移[8-9]等视觉处理任务并取得众多成果,生成对抗网络已成为深度学习领域的研究热点之一。
原始GAN模型存在模型难以收敛、梯度消失、模型崩溃不可控等一系列问题。针对GAN生成器在生成过程中缺乏约束的问题,文献[10]在原始GAN的基础上增加约束条件形成CGAN 模型,有效控制了模型生成。2015年,RADFORD 等[11]将卷积神经网络(Convolutional Neural Network,CNN)引入GAN 模型得到DCGAN 模型,提高了生成样本的多样性和图像质量,并提升了训练的稳定性。文献[12]提出一种WGAN模型,采用EM距离代替JS 散度来衡量模型,解决了GAN 模型易崩塌和梯度消失的问题。文献[13]在WGAN 的基础上进行改进得到WGAN-GP 模型,去除了WGAN 采用的权重裁剪,引入梯度惩罚来满足Lipschitz 连续性条件,从而弥补WGAN 权重裁剪导致梯度爆炸或消失的不足。文献[14]将Self-attention 机制引入GAN 网络以处理图像中长范围与多层次的依赖关系,使生成的图像更逼真。文献[15]设计了一种BigGAN 模型,在生成器中将正交正则化和截断技巧相结合,很大程度上提升了生成图像的逼真度。文献[16]提出一种基于分段损失的生成对抗网络,使生成器在不同阶段采用不同损失函数,提高了模型训练的鲁棒性和运行效率。
针对卷积神经网络感受野较小、在图像特征提取过程中难以学习各个特征通道重要关系的问题,本文结合SinGAN 网络[17]提出一种基于单幅图像学习的生成对抗网络模型。将Inception V2[18]模块引入网络中提取多尺度信息扩大感受野,然后融入SENet 模块[19]学习特征通道的重要关系以减少不重要的特征,并与Bicubic和SinGAN模型生成的图像质量进行对比分析。
1 SinGAN 网络模型
2019 年,ROTT 等提出一种从单幅自然图像中学习的生成模型SinGAN,其结构如图1 所示。

图1 SinGAN 模型结构Fig.1 Structure of SinGAN model
SinGAN 模型由1 个金字塔结构的全卷积GAN组成,每个GAN 负责学习图像不同尺度的信息,这种具有层级结构的patch-GANs[20]模型包含金字塔结构生成器{G0,G1,…,GN}和训练样本金字塔x:{x0,x1,…,xN},其中xn为原始真实图像的下采样版本,采样因子为rn,r接近4/3。整个训练过程由下向上进行,每个生成器Gn的输入包括1 个随机噪声Zn和由上个尺度生成的图像经上采样到当前分辨率的图像,每个判别器Dn需区分对应生成器生成的图像和真实图像下采样所得图像xn,图像从最粗的尺度开始,按照自下而上的训练得到最终结果。生成器和判别器的结构相同,SinGAN 单尺度生成过程如图2 所示,在第n个尺度中(最粗的尺度除外),将上个尺度生成的图像上采样后连同噪声图像Zn一起送入5 个卷积层得到1 个残差图像,然后加上即得到生成器Gn的输出

图2 SinGAN 单尺度生成过程Fig.2 Single-scale generation process of SinGAN
2 SENet 和Inception V2 模块
SENet 和Inception V2 模块可分别通过关注特征通道和提取多尺度的空间信息来提升网络性能,在图像识别方面均具有较好的效果。
2.1 SENet 模块
为解决SinGAN 模型中卷积操作在提取图像特征过程中难以学习到各个特征通道依赖关系的问题,本文引入SENet 模块,其结构如图3 所示。
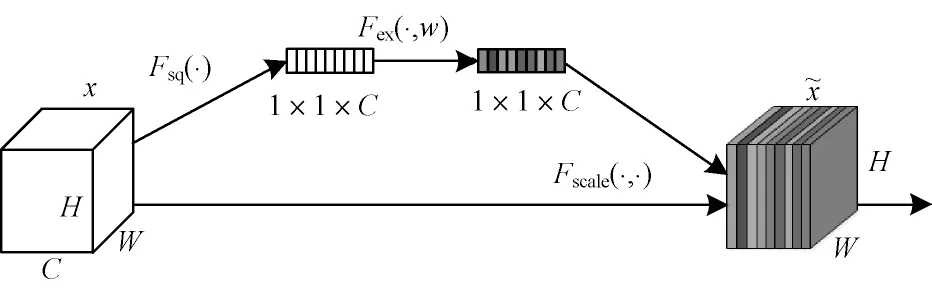
图3 SENet 模块结构Fig.3 Structure of SENet module
x∈ℝW×H×C是一个输入特征,先对其进行Squeeze 操作,计算公式如下:
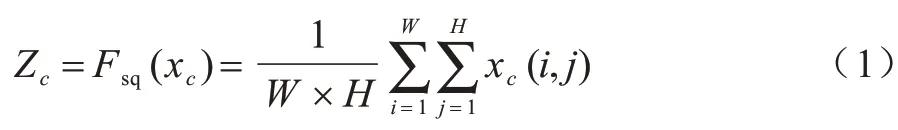
式(1)将W×H×C的输入变为1×1×C的输出,其中:W、H和C分别表示特征的宽度、高度和通道数,xc表示特征x的第C个大小为W×H的特征图,通过Squeeze 操作将每个二维通道变为1 个实数,然后进行Excitation 操作。相关计算公式如下:
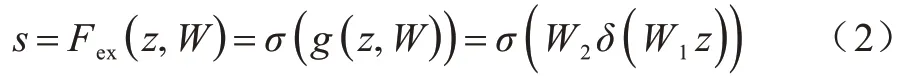

式(3)将Excitation 操作所得每个通道的权重系数对应乘到原始输入特征x的每个通道上,从而完成对原始特征的重新标定,以提升有用的特征并去除无用特征。
2.2 Inception V2 模块
Inception V2 模块通过多支路结构和使用不同大小的卷积核来获得不同感受野,然后进行特征融合,从而提取多尺度的空间信息,扩大感受野。Inception V2 模块结构如图4 所示。
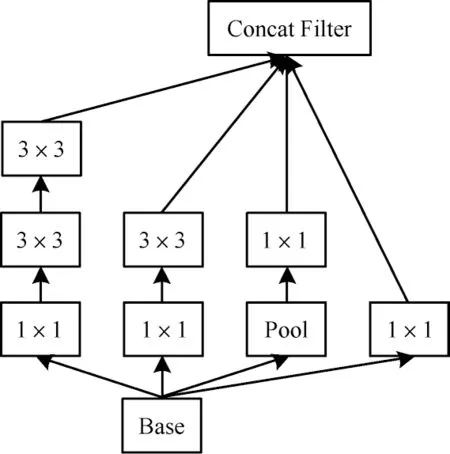
图4 Inception V2 模块结构Fig.4 Structure of Inception V2 module
3 基于SinGAN 改进的生成模型
3.1 改进的SinGAN 网络
SENet 模块专注于学习特征通道的依赖关系,以提升网络辨别能力,这一点与注意力机制类似。Inception V2 模型主要通过提取多尺度的空间信息来扩大感受野。本文结合两者优势设计出一种基于SinGAN 的生成模型,其单尺度生成结构如图5 所示。从左向右进行单尺度样本生成,将噪声图像Zn和上个尺度生成的图像经上采样后送入1 个由3×3 卷积的BN-LeakyReLU(α=0.2)组成的卷积层,然后通过1 个Inception V2 模块和1 个SENet模块,送入3 个和第1 个卷积层相同的卷积层,再经过1 个Inception V2 模块和1 个SENet 模块,最后经过1 个3×3 卷积层和Tanh 激活函数输出生成样本。在最粗的尺度上每个卷积层采用32 个卷积核,每经过4 个尺度,卷积核数量扩大2 倍。鉴别器的网络结构和生成器相比,除在每个尺度最后1 个卷积层不含批归一化(Batch Normalization,BN)层和Tanh 激活函数外,其他结构完全相同。

图5 本文单尺度生成模型结构Fig.5 Structure of the single-scale generation model proposed in this paper
本文在生成器和鉴别器的第1 个和第4 个卷积层后分别加入Inception V2 模块和SENet 模块。采用浅层网络提取低层次边缘特征对后续特征提取较重要。在第1 层后采用Inception V2 模块来融合多尺度的空间信息,可提高感受野并增强浅层网络的特征表达能力,然后通过SENet 模块对融合后的浅层特征进行特征重新标定,可获取全局信息,去除一些无用或用处不大的特征,很好地解决浅层网络特征提取能力不强的问题。在较深层网络后加入Inception V2 模块和SENet模块是为了让网络适应较深层特征的复杂性,提高较深层网络的函数表达能力,同时SENet 模块在较深层趋于具体化,对前面所提取特征有高度的类别响应,可提高不同层次图像的分辨率,使最后生成图像的细节更丰富,第4 节的实验结果验证了这一点。
在pytorch 框架下计算本文所提模型和SinGAN模型的时间复杂度与网络参数量。时间复杂度即模型运算次数,可用浮点运算次数(Flops)衡量,参数量则反映网络的空间复杂度。在输入图像大小为200×200 的条件下,本文模型和SinGAN 模型的生成器浮点运算次数分别为1.23×109和1.13×109,鉴别器的浮点运算次数分别为1.21×109和1.10×109。此外,本文模型和SinGAN模型的网络参数量分别为64.7×103和58.9×103。由上述可知,由于加入了SENet 模块和Inception V2 模块,本文模型在复杂度上相较SinGAN 模型略显复杂,但其增加的复杂度相对于网络性能的提升是可接受的。
3.2 训练过程
本文基于SinGAN 模型的训练思想,从最粗的尺度开始由下向上训练上述多尺度结构,每个尺度的GAN 训练完成后会被固定,直到训练结束。第n个GAN 的损失函数包括对抗损失函数Ladv和重建损失函数Lrec,相关计算公式如下:
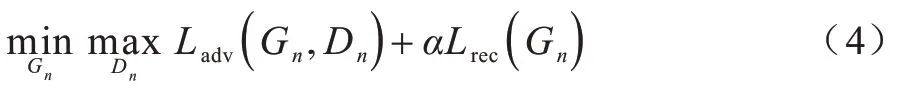
1)对抗损失函数。对抗损失函数Ladv用来衡量生成器生成的样本和真实图像xn分布的距离,其值越小越好。为增加训练稳定性,本文使用WGAN-GP 损失,最后判别分数取鉴别图谱上的平均值。
2)重建损失函数。重建损失函数Lrec是为了保证有一组噪声图能够产生原始图像xn。选择噪声图谱,用表示由上述噪声生成的第n尺度图像,当n 本文模型和SinGAN 模型一样,均可选择开始生成的尺度,但两者区别在于:当SinGAN 模型从最粗的尺度(n=N)开始生成时,会导致生成的图像较原始图像变化较大,当图像的全局结构非常重要时,将生成不真实的样本;当SinGAN 模型从较细的尺度(n=N-1)开始生成时,会保持完整的结构;本文模型在处理图像中存在互相依赖或全局结构非常重要的特征时(从n=N尺度开始生成时)可生成逼真的图像,如图6 所示。其中,图6(a)和图6(b)分别为SinGAN 从n=N和n=N-1尺度开始生成的随机样本,图6(c)是本文模型从n=N尺度开始生成的随机样本。 图6 从不同尺度开始生成的随机样本Fig.6 Random samples generated from different scales 将本文提出的模型应用于图像生成、图像超分辨率重建以及图像协调、图像编辑和动画。本文实验采用Intel®XeonTMGold 5218 处理器,GeForceR-TX2080Ti 显卡,在Pytorch 环境下进行。实验所用图像分别选自Places 数据集[21]、Set5 数据集、Set14 数据集和网络。 本文实验在每个尺度上进行2 000 次迭代,使用Adam 优化器,动量参数设置如下:beta1=0.500,beta2=0.999,生成器和判别器的学习率均为0.000 5(1 600 次迭代后减小1/10),重建损失权重α=10,WGAN-GP 损失的梯度惩罚权重为0.1。 分别采用本文模型和SinGAN 模型进行图像生成,生成的随机样本图像如图7 和图8 所示,其中第1 列为训练图像,后4 列是生成的随机样本图像。 图7 采用本文模型得到的随机样本图像Fig.7 Random sample images obtained by using the model proposed in this paper 图8 采用SinGAN 模型得到的随机样本图像Fig.8 Random sample images obtained by using SinGAN model 由图7 和图8 可见,本文模型和SinGAN 模型均可从单张自然图像内部学习并生成多样且保留了原图像视觉内容的随机样本图像,但本文模型生成的图像细节信息更丰富且更逼真,SinGAN 模型生成的图像变化较大,并含有伪影。从生成图像的局部放大图来看,本文模型生成的图像包含清晰的树叶轮廓、立体且细节丰富的云层,SinGAN 模型生成的树叶和云层图像含有横向的伪影。本文模型生成的图像较SinGAN 模型生成的图像含有更清晰的细节纹理,这是由于SinGAN 模型难以捕获特征之间的依赖关系和各特征通道之间的联系,因此未能较好地捕捉图像中的几何特征和细节信息,而本文模型通过融合多尺度信息和捕捉通道之间的重要关系可有效解决上述问题。此外,结合图6 可见,本文模型也避免了整体结构重要的图像从最粗尺度开始生成时,会得到夸张和不真实图像的问题。 近年来,弗雷歇初始距离(Fréchet Inception Distance,FID)被广泛用作GAN 图像生成质量的评价指标,由于本文是单图像模型,所以采用SinGAN模型提出的单幅图像弗雷歇初始距离(Single Image Fréchet Inception Distance,SIFID)作为衡量单图像生成质量的评价指标。 与FID 使用Inception V3 网络最后1 个池化层后的激活向量作为特征不同,SIFID 采用第2 个池化层前卷积层所输出深层特征的内部分布作为提取的单图像特征,其计算得到SIFID 值越小表明生成图像越逼真。本文分别从n=N和n=N-1 两种尺度开始的生成模式对比本文模型和SinGAN 模型生成图像的SIFID 值,先从Places 数据集选出50 张图像进行测试,再计算得到50 张图像的平均SIFID值,结果如表1 所示。由表1 可见,本文模型在n=N和n=N-1 两种尺度开始生成模式下的SIFID 值均较SinGAN 模型减少0.04 和0.01,这表明本文模型所得图像和真实图像更接近,其能有效捕捉图像中的细节信息和各个特征通道之间的依赖关系,生成高质量的图像。 表1 不同模型所得50 张图像的平均SIFID 值Table 1 Average SIFID values of 50 images obtained by different models 本文模型和SinGAN 模型均基于图像内部进行学习,在训练过程中仅生成与真实图像具有相同图像块分布的图像,因此,无需改变和优化本文模型框架就能处理多种图像任务,具体操作为:在n 4.3.1 图像超分辨率重建 在将输入图像的分辨率提高1 个因子s的过程中,先训练低分辨率图像,再加入1 个重建损失权重α=100 和1 个金字塔尺度因子由于图像的部分细节通常在训练低分辨率图像时在多个尺度上反复出现,因此测试时将低分辨率图像进行r倍上采样并连同噪声一起送入最后1 个生成器G0,然后重复k次得到高分辨率图像。 本文实验采用Set5 和Set14 作为基准数据集,然后分别放大3 倍和4 倍进行图像超分辨率重建,采用峰值信噪比(Peak Signal to Noise Ratio,PSNR)和结构相似性(Structural Similarity,SSIM)作为客观评价指标,将本文模型与SinGAN 模型以及传统的双三次插值模型(Bicubic)进行对比分析,结果如图9 和图10 所示。可以看出,本文模型重建后的图像较Bicubic模型更清晰,由于本文模型引入Inception V2 模块和SENet 模块,因此较SinGAN 模型生成更清晰的人眼轮廓和更丰富的纹理细节信息,更加符合真实图像。 图9 不同模型所得放大3 倍后的图像超分辨率重建结果对比Fig.9 Comparison of super-resolution reconstruction results of three times magnified images from different models 图10 不同模型所得放大4 倍后的图像超分辨率重建结果对比Fig.10 Comparison of super-resolution reconstruction results of four times magnified images from different models 上述3 种模型在不同测试集下的PSNR 值和SSIM 值如表2 所示。由表2 可见:与Bicubic 模型和SinGAN 模型相比,本文模型的PSNR 值和SSIM 值更高;在Set5 数据集上放大因子为4 的情况下,本文模型的PSNR 值和SSIM 值较Bicubic 模型分别提升3.15 dB 和0.056 6,本文模型的PSNR 值 和SSIM 值较SinGAN 模型分别提升1.67 dB 和0.038 7;在Set14数据集上放大因子为4 的情况下,本文模型的PSNR值和SSIM 值较Bicubic 模型分别提升1.52 dB 和0.008 5,本文模型的PSNR 值和SSIM 值较SinGAN模型分别提升1.83 dB 和0.057 0。上述结果表明本文模型在超分辨率重建上具有效性。 表2 3 种模型在不同测试集下的PSNR 值和SSIM 值Table 2 PSNR values and SSIM values of three models under different test sets 4.3.2 图像协调、图像编辑和图像到动画处理 将本文模型在图像协调、图像编辑和图像到动画方面进行应用,得到效果如图11 所示。图像协调是粘贴图像并将其与背景图融合,同时调整图像的外观和纹理,应用效果如图11(a)所示。图像编辑是将原始图像的一块区域复制粘贴到另一块区域,经过训练后重新生成无缝嵌入部分,从而保持真实观感,应用效果如图11(b)所示。图像到动画是对所输入图像进行训练,然后输出一段动画,应用效果如图11(c)所示。由于自然图像包含很多重复部位,这些重复部位像是一个动态对象在不同时间的姿态,本文模型可根据图像中物体的所有表象姿态合成动画。 图11 本文模型应用于图像协调、编辑和动画的效果图Fig.11 Effect images of the proposed model applied to image coordination,editing and animation 本文提出一种基于单幅图像学习的无条件生成模型。在SinGAN 网络的基础上,引入Inception V2模块和SENet 模块,从融合多尺度信息扩大感受野和学习不同特征通道之间重要关系两个层面提升网络性能,并分析在图像协调、编辑和图像到动画任务中的应用效果,对其有效性进行验证。实验结果表明,该模型所生成图像的SIFID 值较SinGAN 模型更低,其PSNR 值和SSIM 值较SinGAN 和bicubic 模型有显著提升。虽然该模型在语义方面受到限制,但可有效进行多种图像处理。后续将针对语义受限问题和提高真实场景中的图像质量进行研究,引入像素注意力机制进一步提高网络模型性能。

4 实验与结果分析
4.1 参数设置
4.2 图像生成结果



4.3 本文模型的应用




5 结束语
