基于结合词典的CNN-BiGRU-CRF网络中文分词研究
2021-08-20郭振鹏张起贵
郭振鹏,张起贵
(太原理工大学信息与计算机学院,山西晋中 030600)
中文是一种复杂的语言,中文文本中没有自然可识别的分隔符,词语间的划分较为模糊,由此学者们掀起了中文分词的研究热潮。例如,文献[1]提出了一种利用膨胀卷积神经网络DCNN(Dilated Convolutional Neural Network)进行中文分词的方法,解决了模型计算速度慢、输入特征不丰富等问题。文献[2]提出使用长短时记忆神经网络(Long Short-Term Memory,LSTM)学习中文分词的字符表示,使用CRF(Conditional Random Field)联合解码标签的方法。文献[3]提出了一种改进双向LSTM-CRF 网络的分词方法,解决了原分词模型在编码过程的记忆压缩问题。文献[4]提出了改进卷积神经网络CNN(Convolutional Neural Networks)的中文分词模型,克服了过于依赖人工处理特征的缺点,简化了模型结构,提高了分词准确率。文献[5]提出一种基于样本迁移学习的中文分词方法,增强了分词模型的领域自适应能力。然而这些基于神经网络的方法通常依赖于大量的标记句来训练模型,对于训练数据中稀缺或缺失的单词,这些方法很难正确地分割出包含该单词的句子。幸运的是,这些词中有许多在现有的中文词典中得到了很好的定义。因此,中文字典有可能提高基于神经网络的中文分词方法的性能,减少对标记数据[6]的依赖。
1 相关理论
1.1 字嵌入
在对文本进行处理时,字嵌入是较为关键的一步,通常采用将词或字表示为分布式向量。如果采用One-hot 编码,即将在该词对应位置上记为数字1,其他位置上记为数字0,这会导致生成的词向量过于稀疏,浪费不必要的内存,并且字词的语义和句法信息也不能体现出来;随后Google 提出一种高效率的词向量训练工具——Word2vec[7],它可以将句子中词映射为低维度的实数向量,常常应用于神经网络来进行分词任务,常见的模型有CBOW (Continuous Bag-of-Words)和Skip-Gram。与CBOW 模型相比较,Skip-Gram 模型更适合处理大型语料库。
1.2 GRU单元
GRU(Gated Recurrent Unit)单元[8]是LSTM 单元的一个变体,它改变了LSTM 的内部结构,将遗忘门和输入门合并到更新门中,输出门成为重置门,同时合并了细胞状态与输出状态,使其拓扑结构更加简单,具有内部计算复杂度较低、训练时间短等优点,缓解了训练误差的梯度衰减和发散问题。GRU 单元的内部结构如图1 所示。
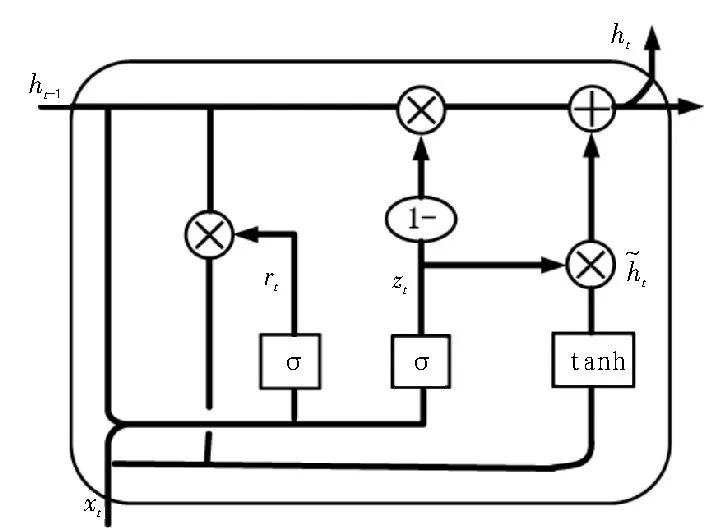
图1 GRU 单元的内部结构
在t时刻GRU 单元按以下方式更新:
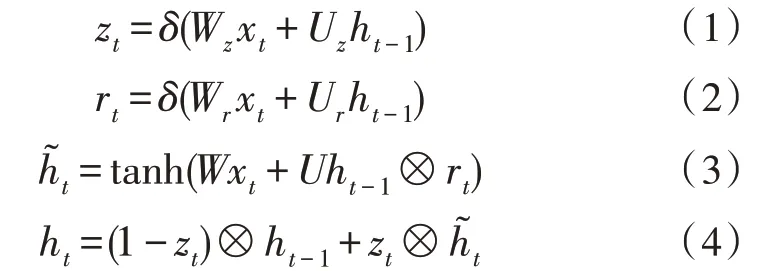
其中,zt为t时刻的更新门,它决定着单元记忆当前信息和遗忘历史信息的程度[9],表示当前时刻的候选激活值,ht-1表示前一隐藏节点的激活值,rt为t时刻的重置门,它决定是否放弃先前的ht-1。若重置门rt≈0,则表示模型可以舍去一部分与未来无关的信息,ht表示在t时刻的隐藏节点的激活值。
2 基于CNN-BiGRU-CRF的中文分词模型
文中的CNN-BiGRU-CRF 模型由主要CNN、BiGRU 网络和CRF 层组成,模型如图2 所示。
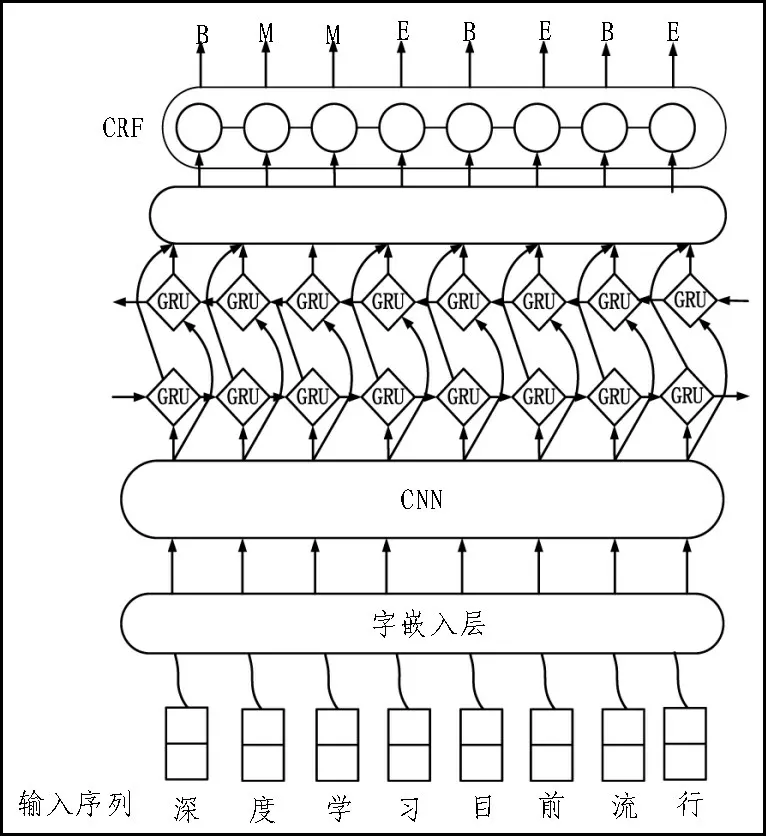
图2 CNN-BiGRU-CRF模型图
2.1 CNN层
该文利用CNN 提取局部短语特征,其模型由以下几部分组成。
1)输入层。把嵌入层的输出矩阵当作输入,句子的第i个词向量为xi∈Rk×d,其中k和d分别表示文本句子的长度及词向量的维度。
2)卷积层。通过设置滤波器的大小提取输入文本的局部特征,即对输入层的矩阵C∈Rk×d进行卷积运算操作,卷积之后的特征可表示为:
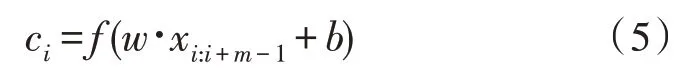
其中,ci表示为第i个局部特征值。m是卷积核的尺寸大小,b和w分别为卷积核的偏置和权重,xi:i+m-1表示从第i个词到第i+m-1 个词组成的句子向量,ƒ表示激活函数。
3)池化层。对卷积层操作后的句子局部特征进行采样,可以得到局部值的最优解Hi,池化方法有两种方法,一种是平均池化,另一种是最大池化。
4)全连接层和输出层。将池化层后的向量Hi通过全连接层连接成特征矩阵T=[H1,H2,…,Hn],该特征向量经过最后输出层得到对应类别的概率序列。
2.2 BiGRU(Bidirectional GRU)网络层
当对文本中的一些句子进行分词时,如“天晴了”、“天气真好”、“天天都要加班”等,对于单向的GRU 网络,只能将上述的例句,切分为一样的结果,为了避免此缺点并获得正确的分割结果,因此利用BiGRU 网络[10]来捕获未来和过去的文本信息,即使用一个GRU 神经网络来计算过去的信息,并同时使用另一个相同且方向相反的GRU 来计算未来的信息[11]。BiGRU 网络结构如图3 所示。
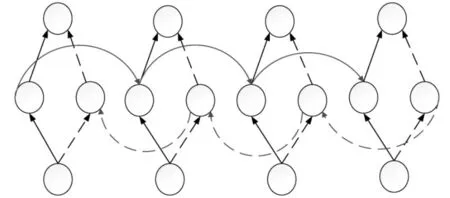
图3 BiGRU 网络结构图
在双向GRU 网络中,设前向GRU(表示未来信息的网络)的隐藏状态为,后向GRU(表示过去信息的网络)的隐藏状态为,BiGRU 输出的隐藏状态为ht。具体的计算公式如下;
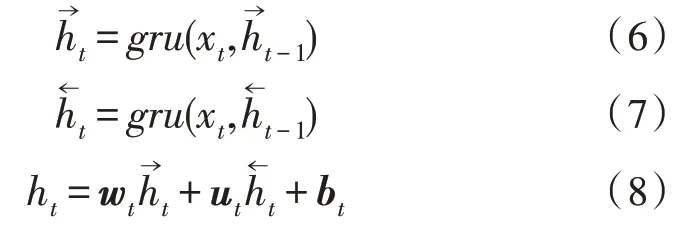
其中,wt、ut分别表示前向、后向隐层状态的权值矩阵;xt为t时刻的GRU 输入;bt为偏置向量。
2.3 CRF层
条件随机域(CRF)[12]是近年来自然语言处理领域中比较流行的算法之一,是一种条件概率模型,可用于求解序列概率最大化的条件。
设BiRGU 神经网络层处理后的序列为M={M1,M2,M3,M4,…,Mn},其中Mi为第i个输入字符向量。设标签序列为Y={Y1,Y2,Y3,…,Yn}。其中Y(M)为M的可能标记序列集,定义的CRF模型[13]条件概率P(Y|M)为:


其中,N为训练的标记句数,Yi为第i个句子的真实标签序列。
3 融合字典信息的方法
3.1 伪标记数据生成
将字典信息融合到神经网络模型训练的一种方法是基于伪标记数据的生成。更具体地说,给定一本中文字典,里面有一串中文单词,随机抽取其中的K个词,用它们组成一个伪句子。例如,假设有3 个词“流行”、“目前”和“深度学习”被取样,然后可以生成一个伪句子“很火最近人工智能”,由于这些单词的绑定表已经知道,因此可以自动推断生成的伪语句的标记序列。例如,在BMES 标签方案下,上述伪语句的标签序列为“B/E/B/E/B/M/M/E”。然后重复此过程,直到生成Np个伪标记句子,把这些伪标记的句子添加到标记的数据集中,增强了网络模型的训练。
由于伪标记的句子可能与人工标注的句子具有不同的信息量,分别对这两种训练数据的损失赋予不同的权重,最终损失函数表示为:

3.2 多任务学习
基于多任务学习将字典信息合并到神经网络分词模型训练中,在原基础上增加了一项新任务,即词的分类,这意味着分类序列的中文字符是否可以是一个中文词语。例如,一个字符序列“深度学习”可以被归类为是一个正确的词,而“深度学昕”会被归类为一种错误类型组合,即不是一个正确的词。这些阳性样本是从一本中文字典中获得的,阴性样本是通过从词典中随机抽取一个词来获得的,然后这个词中的每个字符将被以一个概率为p的字符重新随机放置。多次重复此步骤,直到获得预定数目的阴性样本,采用一种神经方法来进行单词分类任务,它的架构与神经网络CNN-CRF 架构[14]类似,只是将CRF 层替换为max-pooling 层和sigmoid 层来进行二元分类。单词分类任务的丢失函数表示为:
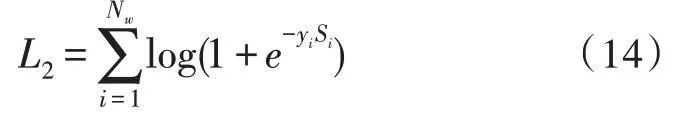
其中,Nw为分类训练样本的数目,Si为第i个样本的预测得分,yi为词的分类标签值(其中yi为1 代表正确,yi为-1 代表错误)。
在多任务学习的驱动下,提出了一个统一的框架来联合训练中文分词与词分类的多任务模型,如图4所示。
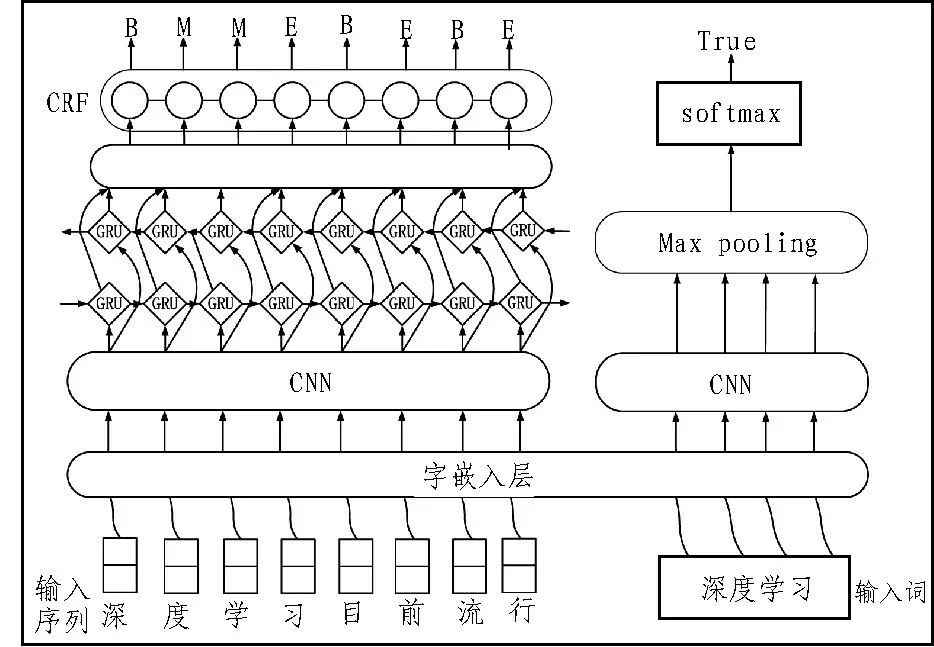
图4 基于多任务学习的模型图
在上述的框架中,神经网络分词模型和词分类模型具有相同的嵌入层和CNN 层。这样,这两个层次可以通过与词分类任务的联合训练,更好地捕捉汉语词典中的词信息,从而提高汉语词典的性能。在模型训练中,分别为这两个任务的损失设定不同的权重,最终的损失函数为:
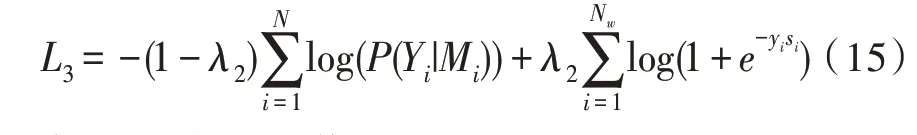
其中,系数λ2取值范围为(0,1)。
3.3 方法的融合
上述介绍了两种将字典信息引入神经网络训练的方法,一种方法是基于伪标记数据生成,另一种方法是基于多任务学习。这两种方法利用词典信息的方式不同,可以结合起来更好地利用词典知识。最终的损失函数为:
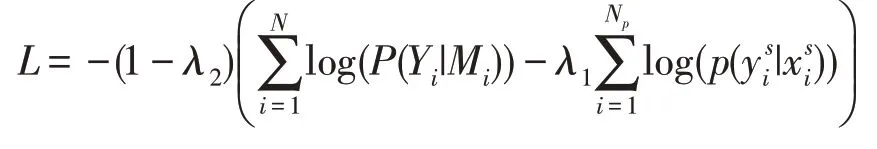
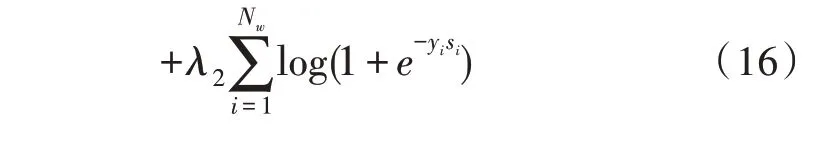
4 实 验
4.1 实验环境及实验数据
该文实验的硬件平台:Intel(R)core(TM)i5-4210 CPU@2.4GHz,CPU卡为NVIDIA GeForce GTX 1080ti;内存为8G,操作系统为Ubantu 14.04;软件参数为Python3.6,使用Tensorflow 1.12 和Kears 2.2.4 构建神经网络分词模型。
该文实验采用数据集分别是MSRA corpus 和PKU corpus,通常在MSRA 和PKU 中随机选取90%作为训练集,10%作为测试集。为了公正地评估模型的分词性能,实验采用了SIGHAN 规定的标准评估指标,其评价指标有准确率P,召回率R以及F1值。
4.2 实验超参数设置
在CNN-BiGRU-CRF 模型中,字符嵌入是利用Word2vec 在搜狗新闻语料库上预先训练获得的,实验中使用字典是中文搜狗字典,字嵌入向量维度设为200,最大句子长度设为40,在CNN层使用了600个过滤器,内核大小为3,采用Adam 优化算法作为神经网路的训练算法,初始的学习率设为0.01,隐藏层节点数设为128 个单元,dropout 率设为0.3,将每个实验重复5 次,并输出平均结果。
4.3 实验结果与分析
实验一结果如表1 所示,与Bi-LSTM-CRF 模型进行对比,Bi-GRU-CRF 神经网络模型在MSRA 和PKU 语料库中的平均迭代时间分别减少了12.6%、14.6%。与CNN-BiLSTM-CRF 模型相比,CNNBiGRU-CRF 模型在MSRA 和PKU 语料库中的平均迭代时间分别减少了11.6%,12.4%,由此可以表明,GRU 模型在训练时间方面明显优于LSTM 模型,故采用GRU 来代替LSTM 不仅可降低训练模型的复杂度,而且可以进一步提高分词算法的效率。

表1 模型训练的平均时间(单位:s/epoch)
实验二分别以LSTM-CRF、CNN-CRF、CNNBiGRU-CRF 网络模型在数据集MSRA 和PKU 上进行实验。实验结果分别如表2 和表3 所示,在上述的3 种分词模型对汉语分词任务的准确率都达到了90%以上,其中LSTM-CRF 和CNN-CRF 模型的分词效果相对较差,与CNN-BiGRU-CRF 模型相比,在MSRA 和PKU 两个数据集中,后者模型的F1 值比LSTM-CRF 模型的F1 值分别高2.4%、4.1%,比CNNCRF 模型的F1 值分别高1.6%、2.8%,说明双向的神经网络模型能够克服单向网络在关联上下文信息方面的局限性,进而实现更加精准的分词。
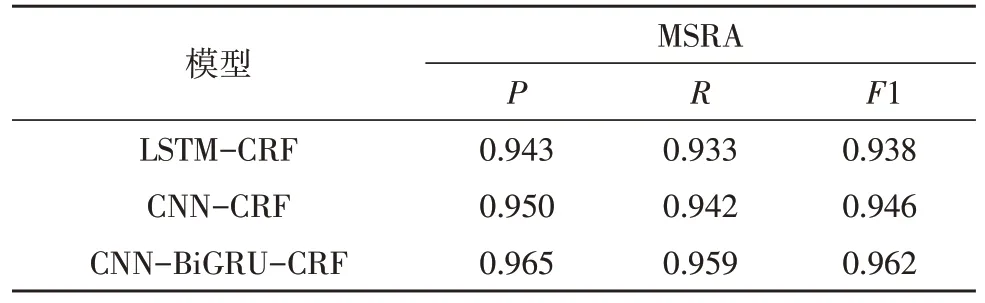
表2 模型在MSRA数据集上的分词性能
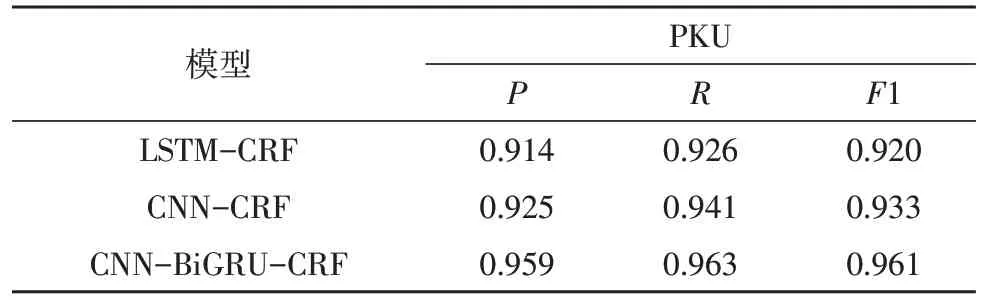
表3 模型在PKU数据集上的分词性能
实验三将字典信息有效地加入到CNN-BiGRUCRF 神经模型中,从而达到更好的分词效果,将该文提出的方法与最近其他的先进分词方法在MSRA 和PKU 数据集上的P,R,F1 等性能上进行了比较,其结果如表4 所示。其中Method I 和Method II 分别是采用伪标记数据生成方法和多任务学习方法将字典信息加入到CNN-BiGRU-CRF 神经模型中,Method I+Method II 是将两种方法融合将字典信息加入其神经网络中;由表4 可以看出,该文提出的Method I+Method II 方法在MSRA 和PKU 数据集上的整体性能优于其他先进分词方法,在MSRA 数据集上的P,R和F1 的值分别达到了97.8%,97.2%,97.5%;在PKU 数据集上的P,R和F1 的值分别达到了97.6%,97.3%,97.4%;其整体分词性能优于未利用字典信息的CNN-BiGRU-CRF 模型,与文献[1]提出模型相比较,其F1 值在MSRA 和PKU 数据集上分别提高了1.14%、1.35%,并且Method I+Method II 方法的F1 值高于单独使用Method I 和Method II 方法的F1 值,说明将伪标记数据生成方法和多任务学习方法进行融合可以更有效地利用词典的信息,可以进一步提高分词的准确率。
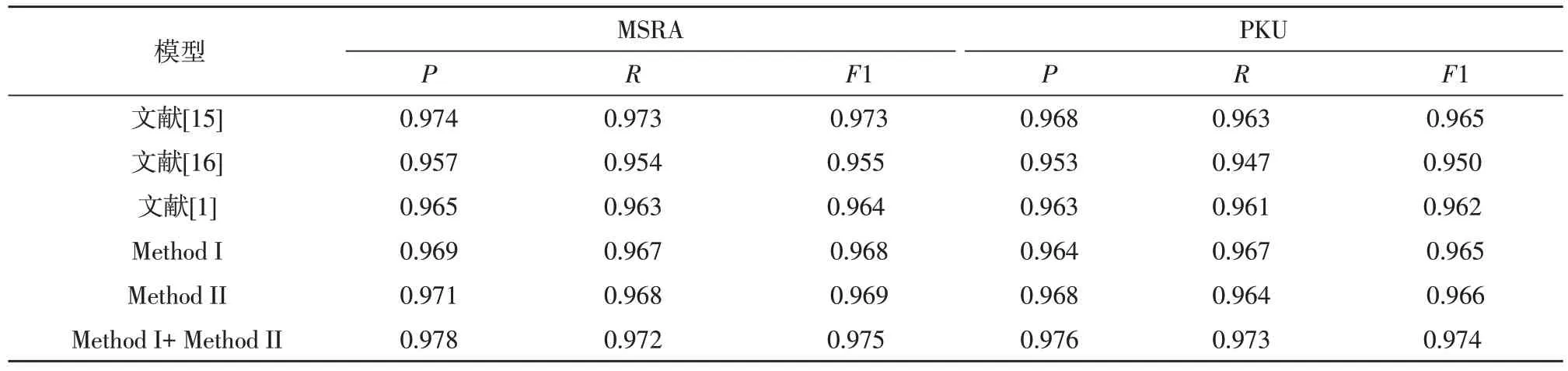
表4 与最近其他先进分词方法在MSRA和PKU数据集上的分词性能比较
实验四随机取MSRA 10%的训练数据和PKU 25%的训练数据,来验证伪句子数量和人工标记句子数量对实验的影响。如图5 所示,这两个比率的趋势是相同的,随着伪句子数量的增加,F1 值先提高后降低。这是因为当生成的伪句子数量很少的时候,字典信息并没有得到充分的利用,随着伪数据数量的增加,该方法可以更好地利用字典知识。当伪标记数据过多时,模型会过度放大伪标记数据信息,而忽略了人工标记生成的数据,从而导致性能下降,因此适度大小的伪标记数据是最好的。
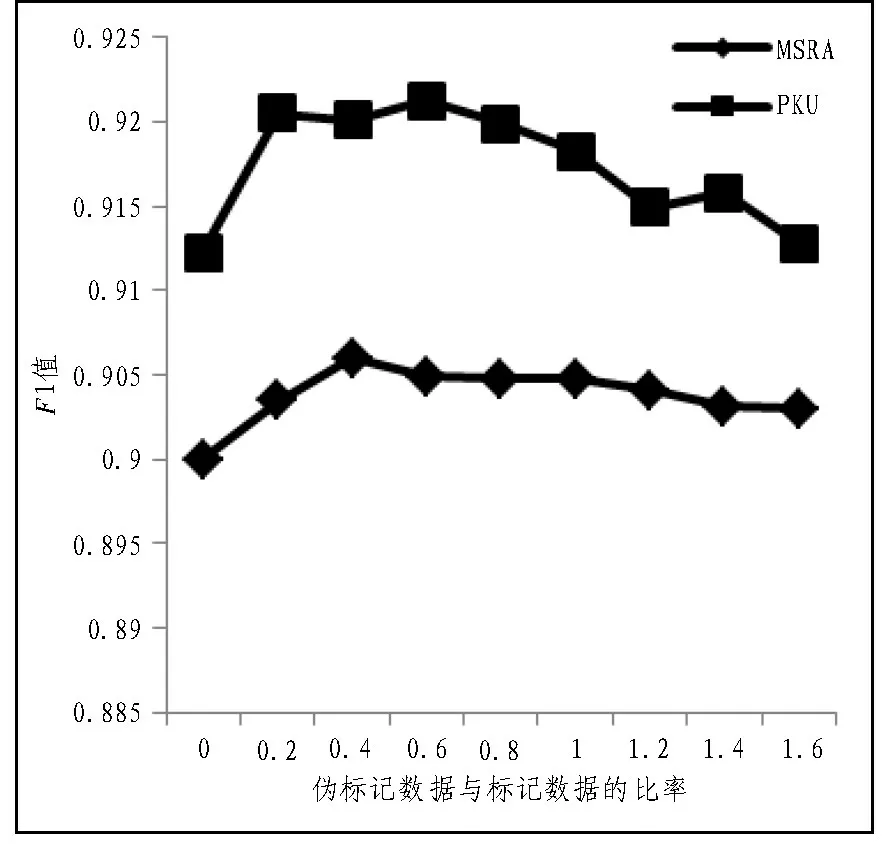
图5 伪标记数据大小对实验的影响
在多任务学习方法中,随机生成中文序列作为单词分类任务的样本,分词任务的性能可能会受到随机生成样本数量的影响。图6 显示了多任务学习方法的性能随所构造的词分类样本数量与字典大小之比的变化。当分类样本个数较小时,分类性能随样本个数的增加而提高,而当样本数量过大时,性能会变差,原因类似于伪标记数据方法,随着分类样本个数的增加,该方法逐渐将字典知识融入到分词模型中,而当分类样本过多时,模型可能会过分强调分类任务而忽略分词任务。因此,适当数量的单词分类样本最适合该方法。
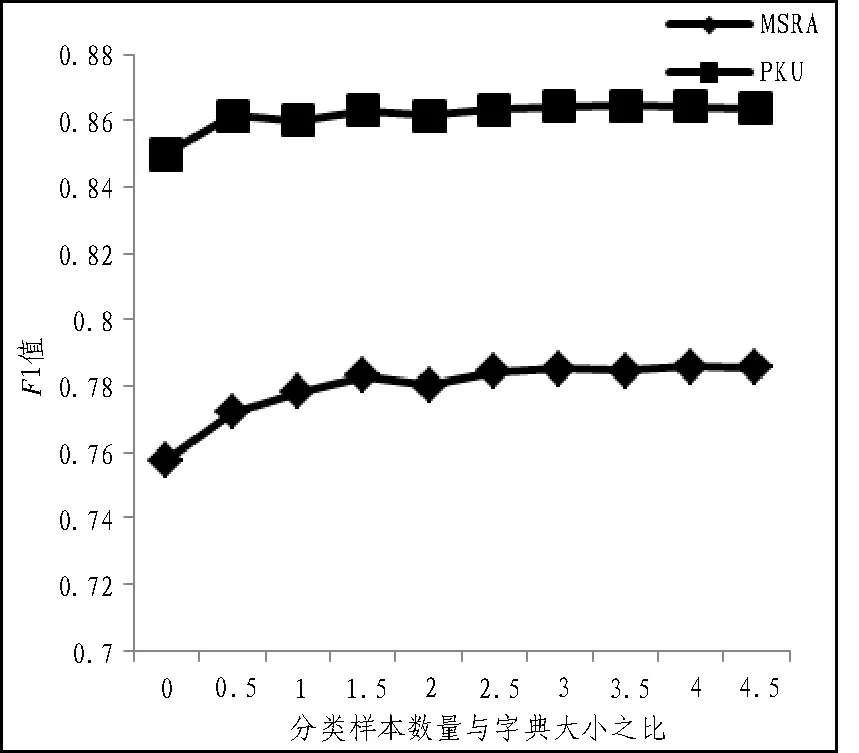
图6 词分类样本大小对实验的影响
5 结束语
该文提出了一种结合字典信息的CNN-BiGRUCRF 网络的分词模型,利用字典信息的一种方法是基于伪标注的数据生成,从中文字典中随机抽取词来构成伪标记句子;另一种是基于多任务学习,在这种方法中引入了另一项任务,即中文词类分类,根据汉字是否能构成一个词,对汉字序列进行分类),并通过共享神经网络的参数与CNN-BiGRU-CRF 网络模型共同训练该任务。实验结果表明,使用GRU 代替了传统LSTM,可降低了模型复杂程度,提高分词模型训练的效率,使用将伪标记数据生成和多任务学习方法进行融合可以更好利用字典信息,克服了需要大量带标记的句子进行模型训练,并提高了模型分词的准确率。虽然伪标记数据的生成方法是有效的,但是生成伪标记数据的方法非常简单,可能会给分词模型带来一些噪声,因此需要探索更精确的方式来构造伪数据,以便在特征中更高效地利用字典信息。
