基于边云协同的流数据处理任务卸载优化研究
2021-08-19徐扬张萌萌
徐扬 张萌萌
(1.天津易华录信息技术有限公司,天津 300350;2.北方工业大学信息学院,北京 100144)
如今,伴随着科技的飞速发展,物联网和5G也不断发展,其设备产生大量的数据,带来的最直接的改变就是数据爆炸式增长,对于数据处理的问题也日益迫切。为了能够快速的处理日益膨胀的数据,云计算成为了处理数据的首选方式。云计算将全部数据都上传到云数据中心也会给网络带宽带来很大的压力,云计算已经不能满足一些对实时性比较敏感的应用,边缘计算[1]应运而生。边缘计算与云计算数据中心不同的是其资源相对匮乏,而云计算中心资源较为丰富,因此本文研究基于边云协同的大数据处理方式。
1 边云系统模型建模
在以云计算模型为核心的物联数据接入系统中,数据和计算任务都会传输到云中心上进行存储和执行,但会出现的问题是对于大规模的数据传输将会加剧时间延迟和网络带宽负载问题,最终导致物联系统中的计算需求无法及时满足,此时出现了边缘计算。边缘计算系统的架构大致可以划分为三个层:边缘设备层、边缘计算层和云中心层。如图1所示。

图1 边云协同模型Fig.1 Edge-cloud collaboration model
1.1 资源图建模
在介绍完边云协同的架构后,我们对其进行建模,将其抽象为DAG图,称之为资源图,表示为 (GresDevices∪=,Devices代表着一系列边缘设备, ζ代表的是云计算单元,包含着多个节点。我们将云节点聚合到一个逻辑节点中,在收集数据后,可以运行整个工作流程。Eres表示边缘设备和云之间的物理链接,Wres代表的是在边缘和云之间每秒钟传输的数据量,单位为Mb/s。
在资源图中,每一个服务器(包括边缘和云端)拥有受限的资源,在本文中将其表示为CPU速率,其单位为MIPS。其中MIPS全称为Million Instructions Per Second,表示的是每秒处理的百万级的机器语言指令数,是衡量CPU速度的一个指标。
1.2 流图建模
在大数据处理中,每一个数据处理的过程都可看做一个计算任务。对于每一个计算任务,在内部将其分解成为若干个子任务,将这些子任务之间的逻辑关系或顺序构建成有向无环图(Directed Acyclic Graph,DAG)结构,所以我们将数据的处理的过程抽象为一个DAG模型。在流处理引擎中,将流数据处理服务抽象为“流图”,是一个DAG模型。在流处理引擎中,DAG流图的生成需要指定数据来源。在本文中,将流图的概念细化为加权有向无环图,将其表示为,Vst表示的是操作算子集合,Est表示的是数据流的集合,Wst表示的是网络使用量,单位为Mb。
对于每一个操作算子,是指一个处理函数,包括一个输入、一个处理逻辑、一个输出,作用为完成数据的转换,且具有以下3个属性:(1)名称:用Name表示。常见的操作算子有Filter、Map等。(2)类型:用Type表示,取值为0或1。类型1代表的是能同时在边缘和云端执行的操作算子,类型0代表的是只可在云端执行的操作算子。对于操作算子分类的原因为:由于边缘设备的计算能力、内存、电池寿命有限,或者因为一些操作算子无法在边缘分析框架的执行,或者对于用户来说,担心在云中心处理可能会造成隐私的泄露,所以在这里将操作算子进行了分类。(3)复杂度:用Complexity表示,每一个处理函数的执行次数,其单位为MPIS。
2 边云任务卸载
提出了一种在资源约束下寻找DAG模型计算任务的卸载算法,使其在边缘和云端两部分运行时,从边缘设备传输至云端的总带宽与时延最小。首先采用标记的方式对无法在边缘计算的节点进行染色,而后然后采用深度优先遍历的方式将对已有染色节点有依赖的节点染色,之后使用FF算法将未染色的子图完成最小割的切分卸载,得到一种或多种切割方式。最后,对于多种切割方式得到的不同的边缘和云端任务子图,根据边云之间的资源进行筛选得到最佳的流图切割方式。
2.1 节点染色
类型为0的操作算子由于资源限制无法在边缘节点执行。而对于其他对此类有直接或间接依赖的节点也无法在边缘设备运行,否则增加大量的边云节点的数据传输和任务等待。这里提出了通过深度优先搜索的染色的方式将由于直接原因或间接原因无法在边缘运行的节点染色,以此方式确定我们最终可以在边缘设备进行执行的计算任务子图。
2.2 流图切分
本节是对于做完染色的DAG计算任务模型进行进一步的切分得到所有可以在边缘运行节点的子图。采用深度优先搜索的方式,从v1节点对图进行遍历,对于未被染色节点进行保存。如图2-(1)所示为染色后的DAG计算模型图,切割后如图2-(2)所示,包含有节点v1、v2、v3、v4、v7四个节点均可在边缘设备进行。但此时得到的DAG计算模型图不包含云端节点,需要进一步处理才能做边云任务的切分卸载。
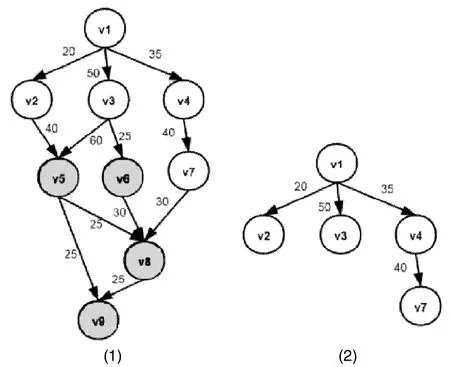
图2 流图切分示意图Fig.2 Schematic diagram of flow graph segmentation
2.3 任务卸载
在单纯的云计算场景下,任务采用的是根据云端节点的资源情况分配不同的计算任务即可,但是对于边云协同的计算方式,由于存在大量的边缘设备,边缘设备计算结果数据无法通过现有的边缘设备的带宽资源进行快速的传输,所以如何减少从边缘设备传输到云端节点的数据量为边云任务卸载的主要优化方向。
如上所述,在DAG图中,边代表的是每秒钟所传输的数据量。由于边云之间的带宽有限,减少边云之间传输的数据量可以有效地降低数据传输的时延,所以要使得切割边的权重之和最小。为了使得切割边的权重之和最小,在此使用FF最小割算法来达到目的,进而来分别提取边云的任务。
2.4 切割方式选择
在文献[2]中利用了最小割来进行任务的分割。但是其并没有结合边云之间的资源。由于FF最小割算法对于同一个图的切割可能会出现多个切割方式。当有多种切割方式时,对于每一个切割方式,得到不同的边缘任务子图和云端任务子图。对于每一种边缘任务子图个和云端任务子图,分别边缘任务和云端任务的每一个任务的complexity之和,最后计算其比例,计算方式为资源图中边缘节点的总算力与云端节点的总算力之比,。对于若干种切分方式,为了使得资源利用率更高,我们选择资源利用率最高的对应的任务的切分方式。预估使用率Est_Util计算方式为计算方式为
3 仿真实验分析
本文中,评价指标有传输数据量和时间延迟。在本文中,我们使用C++来实现我们的算法。为了使实验结果的信服力更强,我们使用Google cluster trace数据集作为我们的实验数据集。我们选择的对比算法为数据全部在云端执行,称其为CloudMethod。本文中所提出的算法命名为TaskOffload。对比效果如下:
如图3所示,对于边云之间数据量的传输,TaskOffload算法的效果要比CloudMethod算法更好。如图4所示,在边云之间,TaskOffload算法处理DAG模型的时延要比CloudMethod算法更低。
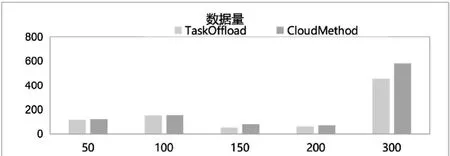
图3 数据量结果对比图Fig.3 Data volume result comparison chart
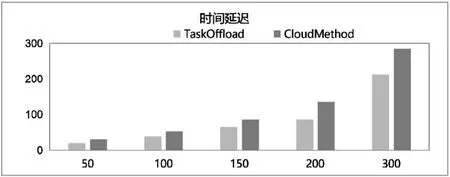
图4 时间延迟结果对比图Fig.4 Time delay result comparison chart
4 结语
本文提出了在资源约束的条件下,边云任务卸载的问题,一共包括四部分,分别为基于节点类型的节点染色、流图切分、任务卸载以及切割方式的选择等。在任务卸载部分利用了FF算法实现了边缘任务的提取,之后通过去重的方法完成了云端任务的提取,最终使得在资源约束的条件下从边缘节点传输至云端的数据量更少,提高了资源利用率,最后证明了本方法的有效性。
