基于深层信息散度最大化的说话人确认方法
2021-08-16陈晨肜娅峰季超群陈德运何勇军
陈晨,肜娅峰,季超群,陈德运,何勇军
(1.哈尔滨理工大学计算机科学与技术学院,黑龙江 哈尔滨 150080;2.哈尔滨理工大学计算机科学与技术博士后流动站,黑龙江 哈尔滨 150080)
1 引言
近年来,以生物识别技术为基础的身份认证方式正在逐渐取代传统的静态身份认证手段。随着科技的发展,以指纹识别、人脸识别及说话人确认为代表的一系列生物识别技术已在多种认证场景中取得了较广泛的应用。其中,说话人确认技术能够根据说话人的声音特性来有效识别其身份。由于每个人在说话过程中所蕴含的语音特质与发音习惯几乎独一无二,因此说话人确认技术兼具生理特性与行为特性,从而使其相较于其他生物识别技术的仿冒难度更大、安全性更高[1]。与此同时,“无接触”的说话人确认技术能够有效阻断“人传人”的传播链条,为个人健康提供更可靠的保障。
说话人确认能够通过对说话人语音信号的分析处理,来充分结合知识、数据、算法与算力,是迈向第三代人工智能[2]的典型代表。如何从大量语音数据中凝练出准确的说话人身份信息,则是说话人确认任务中最值得关注的研究焦点。为此,需要深入研究能够直接代表说话人身份特性的特征表示问题,研究者也针对该问题提出了大量有效的说话人特征表示学习模型。其中,以身份−矢量(I-vector,identity-vector)[3]方法为基础的一系列特征空间学习方法应运而生,它们均能将具有不同时长的语音信号映射为固定维度的低秩I-vector 特征表示。在这类方法中,因子分析(FA,factor analysis)[4]、广义变化模型(GVM,generalized variability model)[5]、任务驱动多层结构(TDMF,task-driven multilevel framework)[6]等方法为典型代表。此外,为了去除语音信号中的会话差异性信息(如语音内容间的差异、噪声、信道畸变等),还需要对I-vector 特征进行会话补偿[7-8]等操作。
除此之外,随着深度神经网络在图像处理、音频处理等方面取得的突破进展,基于深度神经网络的特征表示方法也逐渐出现在说话人确认研究中。例如,D-vector 方法[9]采用深度神经网络(DNN,deep neural network)来提取说话人语音对应的嵌入(embedding)特征,为端到端(E2E,end-to-end)说话人确认方法的发展奠定了基础。X-vector 方法[10-11]则利用时延神经网络(TDNN,time-delay neural network)[12]、统计池化层与全连接层来提取表示说话人身份的X-vector 特征。由于X-vector 方法能够取得优良的性能,在此基础上又出现了基于分解TDNN(F-TDNN,factorized TDNN)[13]、扩展TDNN(E-TDNN,extended TDNN)[14]、聚合残差扩展TDNN(ARE-TDNN,aggregated residual extended TDNN)[15]以及稠密连接TDNN(DC-TDNN,densely connected TDNN)[16]的X-vector 特征提取方法。此外,视觉几何组−中等(VGG-M,visual geometry group-medium)[17]网络则通过多层的卷积层与池化层的叠加来进行说话人特征表示的学习。以上方法均通过构建不同的网络结构来学习说话人的特征表示,考虑到目标函数能够对网络描述能力的提升起到重要的指导作用,因此,设计出有的放矢的目标函数能够使所提取的特征更适用于当前任务。在这些目标函数中,一类目标函数以多分类为目标,例如softmax 损失、交叉熵损失(CE loss,cross entropy loss);另一类目标函数以度量特征表示之间的相似度为目标,例如对比损失(contrastive loss)[18]与三元组损失(triplet loss)[19-20]等。也有一些目标函数在多分类目标的基础上加入度量学习的限制,例如角 softmax(A-softmax,angular softmax)损失[21-22]、加性边沿softmax(AM-softmax,additive margin softmax)损失[23]与加性边沿质心(AM-centroid,additive margin centroid)损失[24]等。
由于目标函数是整个任务目标的最直观体现,它能直接影响网络参数的优化方向,因此一个优秀的目标函数将为网络的特征表示能力带来大幅提升。目前,说话人确认研究中所采用的目标函数均基于这一原则取得了卓有成效的成绩。然而,说话人的类别不胜枚举,并无法保证训练数据能够涵盖全部待识别语音的类别,因此采用以多分类为目标的目标函数往往会导致模型的泛化能力不强;反之,以度量学习为目标的目标函数则通过分别控制同类、异类说话人深层特征间的相关性,来驱使网络朝着提升类内相似性与类间差异性的方向优化,从而为网络带来更强的泛化性与普适性。目前,基于度量学习的目标函数大多仅通过简单的欧氏距离或余弦距离来衡量特征间的相关性,并无法准确捕获特征间复杂的非线性关系。而此非线性关系才是特征间相关性的真实写照,其对特征在特征空间的可区分性表示具有十分重要的指导性作用。因此,如何有效度量这种非线性关系是目前亟待解决的关键问题。
针对上述问题,考虑到非线性关系无法通过显性的表达式进行表示,但能够以计算特征所在分布之间相似度的方式进行隐性表示,因此本文将能够计算分布间相似度的信息散度(ID,information divergence)[25-26]引入目标函数的表示过程中,提出基于深层信息散度最大化的说话人确认方法。其将最大化特征之间的统计相关性作为优化目标,并以此来控制神经网络挖掘同类特征之间必然存在的相容性信息、提升异类特征在特征空间的差异性,最终有效提升深层特征空间的区分性。
2 深层信息散度理论
2.1 信息散度表示
在说话人确认任务中,目标函数的定义对区分性网络学习具有至关重要的作用。同时,由于说话人确认系统应具备开集测试的能力,因此定义基于同类、异类说话人间关系的目标函数能够为网络的学习提供普适性更强的下游任务目标。值得注意的是,传统基于距离的相似度度量方式无法有效表示特征间的非线性关系。为此,本文构建了一种基于深层信息散度的目标函数,其能够有效度量同类、异类说话人特征所在分布之间的差异性,从而更加准确地刻画深层特征间的抽象关系。在此目标函数的指导下,神经网络能够向着同类更紧凑、异类更分离的方向进行优化。
定义s表示随机采样的样本组,其由2 个深层特征组成。当样本组中的特征属于同类时,它们的联合分布为P(s)=P(za,zp);当属于异类时,它们的联合分布为Q(s)=Q(za,zn),其中za、zp、zn分别表示固定(anchor)样本、正例(positive)样本、负例(negative)样本。由于同类、异类样本分布间的差异应尽可能大,因此本文通过最大化P(s)与Q(s)间的ID 来达到提升同类、异类差异的目标,此信息散度可以表示为
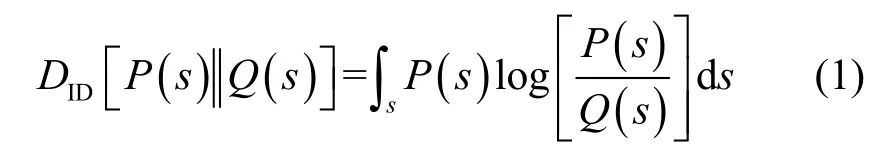
对式(1)进行等价变换,可以得到

定义f(x)=xl ogx,其中,则式(2)可以转换为

其中,函数f(x)可以由其共轭函数f*(t)进行表示,具体形式为
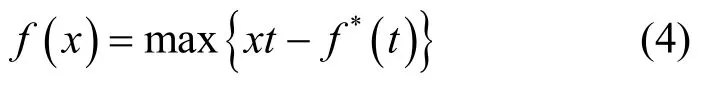
由式(4)可推导出,f(x)=xl ogx的共轭函数为f*(t)=et−1。由于每个x都有与其对应的t,因此t是关于x的函数,本文将其表示为t=d(x)。将f*(t)与d(x)同时代入式(4),可以得到
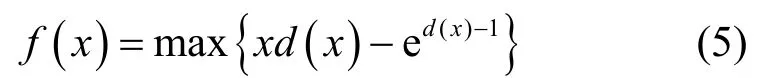
将式(5)代入式(3),则P(s)与Q(s)分布之间的信息散度可以进一步表示为
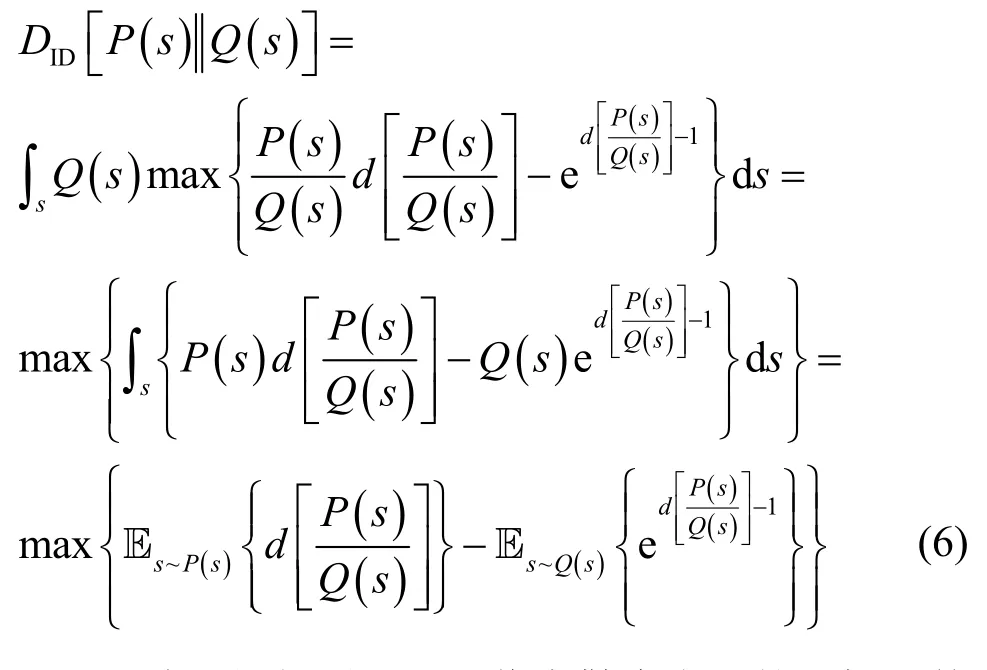
至此,便得到了基于信息散度表示的目标函数的一般形式。其中,P(s)Q(s)为正、负样本组的似然比,是说话人确认中最常见的评价指标之一,当函数d(⋅)作用于其上时,所得到的新形式仍可用于衡量2 个样本间相关性。
2.2 目标函数表示
本节将在第2.1 节的基础上,进一步展开讨论函数d(⋅)的具体形式。当s~P(s)时,s为正例样本组;当s~Q(s)时,s为负例样本组。因此Es~P(s)[d(⋅)]与 Es~Q(s){exp[d(⋅) −1]}分别对应了正、负例样本组的相关性。基于此,式(6)可以进一步表示为

为了使d(⋅)继承似然比的作用,其仍然应该具备相似度计算的功能。基于此,本文将其定义为余弦距离打分(CDS,cosine distance score)的形式
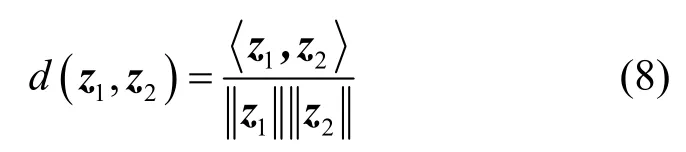
在网络结构设置方面,考虑到VGG-M 网络[17]作为说话人确认领域中的经典网络之一,能够取得良好的性能,且已经得到了很多研究者的实验验证,因此本文采用VGG-M 网络进行特征表示学习。网络输入采用语谱图特征,对输入特征进行随机的三元组采样,得到样本xa、xp、xn,它们经VGG-M得到的嵌入特征分别表示为、
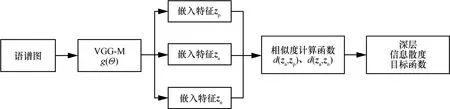
图1 基于深层信息散度最大化与VGG-M 网络的结构
3 实验分析
3.1 数据库与评价指标
本文实验采用VoxCeleb1 数据库[17]对不同方法的性能进行对比与分析,该数据库的全部音频选自YouTube 视频网站,是来自复杂场景下的真实语音,包含大量未知噪声。使用该数据库官方说话人确认任务的划分方案:将说话人中不以字母“E”开头的说话人语音作为开发集数据,其中包含1 211 位说话人、148 642 段语音;以字母“E”开头的说话人语音作为评估集数据,其中包含50 位说话人、4 874 段语音。测试时采用官方测试计划,总测试数为37 720 次,目标测试与非目标测试比为1:1。实验采用等错误率(EER,equal error rate)与最小检测代价函数(Min DCF,minimum detection cost function)来衡量系统的性能,其中Min DCF 的参数设置为Cmiss=1,Cfa=1,Ptarget= 0.01。
为了验证信息散度最大化目标函数的有效性,本文根据如上所述的数据库与实验设置,分别从性能对比与分析、收敛性分析、可视化分析3 个角度进行实验。
3.2 性能对比与分析
本节将所提方法(简记为ID-max VGG-M)与其他方法的识别性能进行对比。对比方法除了选择2 个经典的说话人确认方法,即高斯混合模型−通用背景模型(GMM-UBM,Gaussian mixture model-universal background model)[27]、基于因子分析的I-vector 方法[3]外,还选择了如下基于深度学习的方法:采用对比(contrastive)损失的孪生(siamese)VGG-M 网络[17]、采用三元组(triplet)损失[19]的VGG-M 网络与采用AM-softmax 损失[23]的VGG-M 网络。为了便于书写,本文将上述方法分别简记为GMM-UBM、I-vector+PLDA、Siamese VGG-M、Triplet VGG-M 与AM-softmax VGG-M。
在经典方法的实验中,先对各说话人语音进行语音活动检测处理[28],以去除语音中的静音部分,然后进行特征提取。前端特征采用梅尔倒谱系数(MFCC,Mel-frequency ceptral coefficient)特征,其维度为13 维,并计算其一阶、二阶差分,组成39 维的声学特征。通用背景模型(UBM,universal background model)的高斯混合分量个数为1 024,总变化空间维度为400 维,概率线性判别分析模型(PLDA,probabilistic linear discriminant analysis)的子空间维度为200 维。在识别阶段,GMM-UBM 通过计算测试语音在目标说话人GMM 上的似然概率密度来获得匹配得分;I-vector+PLDA 方法采用PLDA 模型作为后端分类器;Siamese VGG-M、Triplet VGG-M 与AM-softmax VGG-M 方法采用CDS 方法进行说话人确认匹配。
在深度学习方法的实验中,网络的输入为语谱图特征,为了保证实验对比的公平性与有效性,其参数设置与文献[17]一致,即滑动窗的窗长设置为25 ms,帧移为10 ms,快速傅里叶变换的点数为512 个。基于此,对于一段3 s 的语音,可以提取512×300 维的语谱图特征。对于VGG-M 网络,其结构同样采用文献[17]中的设置,最后一层全连接层的节点数为1 024 个,由此可得说话人深层特征表示的维度为1 024 维。训练VGG-M 网络的优化器采用随机梯度下降(SGD,stochastic gradient descent)算法,学习率与迭代次数则根据多次的参数调优来确定,最终选择性能最佳时对应的初始学习率、最终学习率与迭代次数,分别为0.001、0.000 1与80。根据上述实验设置,不同方法对应的系统性能情况如表1 所示。
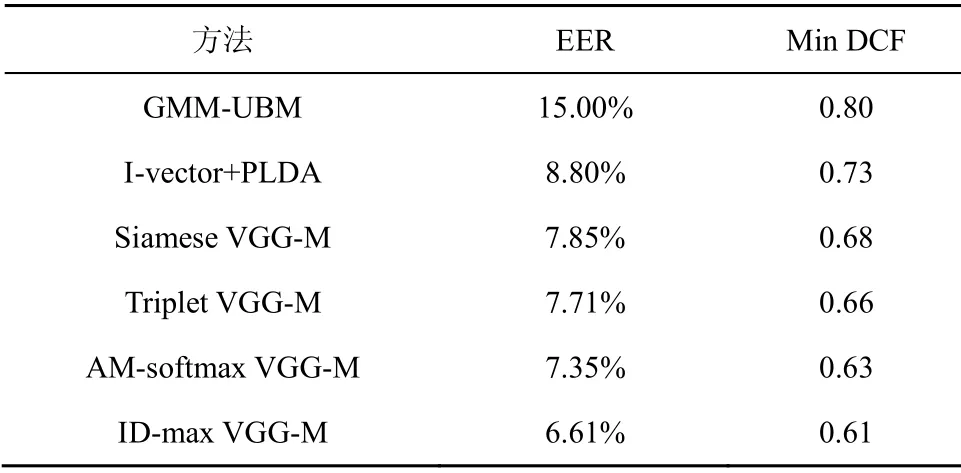
表1 不同方法的性能对比
由表1 的实验结果可以得出,相比于其他方法,本文提出的ID-max VGG-M 方法具有更低的EER。其与Siamese VGG-M 方法、Triplet VGG-M 方法、AM-softmax VGG-M 方法3 种方法相比,相对EER分别降低了10.1%、15.8%、14.3%。这也这也验证了本文所提出的ID-max 目标函数能够指导网络学习更具表示能力的说话人深层特征。
3.3 收敛性分析
本节将对ID-max VGG-M 方法的收敛性进行验证与分析,通过记录每次VGG-M 网络训练时在评估集数据上的EER,来绘制收敛性曲线。根据上述的实验设置,4 种方法的收敛性曲线如图2所示。
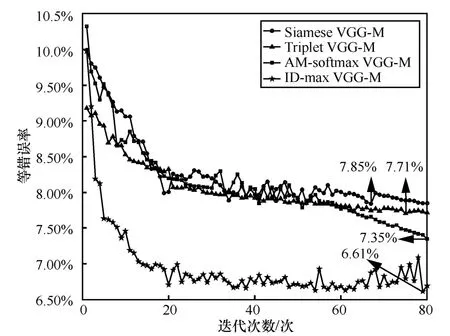
图2 收敛性曲线对比
从图2 中可得到以下结论。
1) 从整体上看,随着迭代次数的增加,这4 种方法对应的等错误率呈下降趋势,系统性能逐渐上升。相比于其他3 种方法,ID-max VGG-M 方法的等错误率更低。
2) 这4 种方法均能够在有限的迭代次数内达到收敛状态,其中ID-max VGG-M 方法在第79 次迭代时,等错误率达到最低,为6.61%,这是说话人确认系统最优的性能。
3.4 可视化分析
本节将采用t-SNE 方法[29]对提取的深层特征表示(embedding)进行2D 可视化处理,其中t-SNE初始降维的维度为30 维,困惑度为10。在评估集中随机选择5 位说话人,并从这5 位说话人的全部数据中随机选择80 段语音,各方法均采用以上设置进行数据选择。根据上述设置,不同方法对应的可视化图像如图3 所示,其中,不同灰度的点代表不同说话人。将所对比方法的说话人特征表示分别记为I-vector 特征、PLDA 说话人隐变量、Siamese VGG-M embedding 特征、Triplet VGG-M embedding特征、AM-softmax VGG-M embedding 特征与ID-max VGG-M embedding 特征。
由图3 中的实验结果可以得出以下结论。
1) 由图3(a)与图3(b)可知,相同类别的说话人特征能够在一定程度上聚集在一起,这是因为经典的I-vector 特征与PLDA 隐变量已具有一定的区分能力。但是同类数据仍然较分散,异类数据之间也有相互交叠。
2) 对比图3(c)、图3(d)与图3(f)可知,图3(f)中的同类特征点更加紧凑。矩形框1 内的这一现象尤其明显:图3(c)与图3(d)中的特征点分散在多个簇内,而图3(f)中的特征点则相对更加集中。
3) 由图3(e)与图3(f)可知,与ID-max 目标函数相比,当以AM-softmax 为目标函数提取说话人特征时,同类特征点在空间中仍然较分散,图3(e)矩形框2 中的特征点分散得尤其明显。

图3 说话人特征表示的可视化图像对比
由此可见,本文提出的基于深层信息散度最大化的目标函数能够使同类的说话人特征表示更加紧凑,异类的特征更加分散。由此得到的说话人特征表示的区分性更强,相应说话人确认系统的性能也能更优。
4 结束语
本文提出一种基于深层信息散度最大化的目标函数表示方法,其将最大化同类、异类说话人特征表示所在分布之间的信息散度作为优化目标,挖掘其中存在的非线性关联信息。并以此来控制神经网络挖掘同类样本之间相关性信息,从而有效提升不同说话人数据在特征空间的区分性。实验结果表明,与其他方法相比,所提方法能够有效改善说话人确认系统的性能。
