基于联合序列标注深度学习的层级信息抽取
2021-08-12王旭强田雨婷
王 扬 郑 阳 杨 青 王旭强 田雨婷
(国网天津市电力公司信息通信公司 天津 300310)
0 引 言
随着互联网技术的飞速发展,各个行业都产生并累积了丰富的数据资源。其中作为语言载体的文本数据占据了很大的比重,这些数据普遍存在于各行各业中,包含着大量的有用信息。然而,文本信息一般是以非结构化或者半结构化文本的形式呈现的,无法使用统计分析工具对其中蕴含的信息进行分析和挖掘,人工筛选又花费大量的时间[1]。因此,如何高效准确地从众多的文本数据中进行信息抽取(Informat-ion Extraction)是一个值得研究的问题。信息抽取主要是指从一个给定的文本中识别并提取出具有一定现实意义的或者感兴趣的子序列结构化的内容,是很多自然语言处理任务中基础但又很重要的一环[2]。
信息抽取技术的发展也使得很多文本、Web系统等应用程序从中受益,例如使用基于Web的信息抽取系统来抽取多种多样的信息如招聘信息、新闻信息和技术成果信息等[3-5]。除此之外,信息抽取技术在一些重要的应用领域中也得到了充分的应用。骆轶姝等[6]使用信息抽取方法来处理非结构化的甲状腺病史文档,实现了对甲状腺病史的结构化,并将结构化的结果通过RDF格式进行了存储,对该疾病的诊断有着重要的意义;丁晟春等[7]使用信息抽取技术来实现对动物卫生事件舆情信息中时间、地点、疫病名称、动物数量和应对措施等内容的抽取,提高了动物卫生领域舆情监测的效率;李艳[8]基于信息抽取技术来提取案件描述文本中的有用信息,有效节约了相关人员对过往案件的查阅过程中花费的时间和精力。
现有的信息抽取工作多是对于处在同级语义的信息抽取,如在新闻文章中抽取其中存在的命名实体,如人名(PER)、地名(LOC)、组织机构名(ORG)等[9],被抽取出的信息通常用三元组
然而,在许多实际问题中,文本内容具有层次嵌套的逻辑结构。如图1所示,其中:(a)是无层次结构的信息抽取问题;(b)则包含了嵌套的层次信息。

图1 带层次结构与无层次结构信息抽取示例
现有的信息抽取算法只能识别到文本中存在的某一层的信息而丢弃其他层级存在的有用信息,进而丧失了使用价值。对于该问题,一个普遍的做法是依次使用多个标注模型,将由一个标注模型得到的结果送入下一个标注模型来进行下一层的信息抽取,但这种方法无疑会导致误差的传播[10],上一层标注的错误结果传入下一层往往会导致更为严重的错误。
基于上述问题以及相关研究工作,本文以具有两层语义结构的货运航运邮件文本数据为研究对象,结合其层次性的特点,构建基于联合标注的层级信息抽取方法。同时对高层的盘块信息和底层的基本信息进行建模,并基于联合学习方法融合不同层级的标注结果,实现对层级信息的抽取,有效地避免了依次使用多个标注模型来处理层级信息所导致的误差传递的问题。经过实验验证,本文方法在该任务上具有更好的有效性。
1 相关工作
信息抽取是自然语言处理领域内一个重要的子领域,迄今为止相关领域的学者们已经进行了很多研究。在这些研究工作中,信息抽取的方法大致可以分为基于规则的方法、基于统计学习的方法和基于深度学习的方法三大类。
1.1 基于规则的信息抽取方法
基于规则的信息抽取技术是目前应用较为广泛和发展比较成熟的技术,其主要分为基于词典和基于指定规则两个类别。
基于词典的方法首先构建了一个模式词典,从而使用该词典来从未标注的新文本中抽取需要的信息。比较出名的CRYSTAL系统[11]便是基于这种方法。这种方法也被叫做基于模板的方法,其核心在于如何学习出可用于识别文本中相关信息的模式字典。
不同于基于词典的方法, 基于指定规则的方法使用一些通用规则而不是词典来从文本中提取信息。其中一种比较常用的方法是学习要提取的信息边界的句法或者语法规则,如判别出信息周围可能存在的特殊词组等作为界定。霍娜等[12]对巴西泥石流、俄罗斯客轮沉没、印尼火山爆发等三种灾难追踪事件报道进行了相关研究,并构建了54条文本抽取规则来进行灾难事件的信息抽取。丁君军等[13]通过大量的阅读、分析,归纳出了对应的规则来完成了对《情报学报》中学术概念的抽取。
基于规则模板的方法同样存在很大的缺陷,不仅需要依靠大量的专家来编写规则或模板,覆盖的领域范围有限,而且很难适应数据变化的新需求。
1.2 基于统计学习的信息抽取方法
由于基于规则方法的缺点,一些经典的机器学习模型如支持向量机[14]、隐马尔可夫模型[15]、条件随机场[16]和决策树[17]、最大熵模型[18]等逐渐被提出用于信息抽取。Mayfield等[14]利用支持向量机在手动提取的数据集特征上进行训练,在英文命名实体识别数据集上得到了84.67%的F1值,超越了之前的方法。Zhou等[15]提出一个基于HMM的命名实体识别系统,融合了大小写、数字等简单单词特征以及句子内部语义特征等,在MUC-6和MUC-7的英语实体识别数据集上分别得到了96.6%和94.1%的F1值。Lafferty等[16]提出了CRFs模型,具有将过去和未来的特征相结合、基于动态规划的高效训练和解码等优点。
1.3 基于深度学习的信息抽取方法
基于统计学习模型的信息抽取方法取得了较好的表现,但是严重依赖于人工提取的特征。而近些年来出现的神经网络算法具有较强的学习能力以及自动抽取特征的能力,很适合用到信息抽取的任务中。
Collobert等[19]使用CNN作为特征提取器,对词向量表示序列进行建模,最终用CRF模型预测序列的标签。Huang等[20]首次将BiLSTM-CRF模型应用到信息抽取中,双向LSTM即BiLSTM能够有效利用过去和将来的输入特征,CRF能够建模句子级别的标签信息,并与LSTM、BiLSTM和LSTM-CRF等退化模型结构作对比,在词性标注、组块分析和实体识别中取得了较好的结果。进一步地,Ma等[21]提出了BiLSTM-CNN-CRF模型,首先使用CNN建模字符信息,将CNN建模得到的字符级别特征与预先训练的词向量相结合,之后送入BiLSTM-CRF中,取得了更好的实验效果,且提出的模型是完全端到端的,不需要任何的特征工程和数据预处理手段。
2 基于联合标注的层级信息抽取方法
2.1 问题定义
在层次级信息抽取任务中,对任意文档d可以将其按句分割为d={s1,s2,…,sT},T代表该文档所包含的句子的个数。d中的任意句子si={wi1,wi2,…,wiN},N为该句中的单词数。该任务首先对句子级信息进行建模,得到句子级的高层标签TAG_HIGH,然后结合句子级标签TAG_HIGH来对单词级的信息进行建模,得到单词级的低层标签TAG_LOW,进而抽取出层级的语义信息四元组:
2.2 整体框架
考虑到层级语义数据所具有的特点,本文提出基于联合序列建模的层级信息抽取方法。首先,使用卷积神经网络模型来建模每一个单词的字符表示ci。然后拼接预训练好的单词的词嵌入向量ei作为单词级的向量表示wi。再将单词的向量表示wi以句子为单位送入双向LSTM中进行编码得到编码后的单词级表示向量ht,并结合注意力机制得到句子级的特征表示si。最终使用CRF模型完成对单词级和句子级的信息的标注,结合两层的标注结果进而抽取出文档中的关键信息。本文模型结构如图2所示。

图2 基于联合学习的层级信息抽取方法
接下来本文将沿着自下而上的方向详细介绍模型的具体结构。
2.3 基于CNN的字符特征提取
卷积神经网络(CNN)是近些年来逐步兴起的一种人工神经网络模型,具有很强的特征提取能力,在自然语言处理和图像识别任务中得到了广泛的应用。在近几年的研究工作[22-23]中更是证明了CNN模型能够有效地从单词的字符中提取出形态学特征,如一个单词的前缀、后缀等,因此本文选用CNN模型提取单词的字符特征。其结构如图3所示。

图3 基于CNN的字符特征提取模型
其中每一个单词wi可由一个字符表示矩阵表示,矩阵的每一行为字符的嵌入表示,矩阵的行数为该单词具有的字符的个数。对该矩阵进行卷积和最大池化操作后便得到了该单词对应的字符表示向量ci,接下来拼接预训练的GloVe[24]词向量ei作为该单词的向量表示:
wi=[ei;ci]
(1)
2.4 基于BiLSTM的时序特征建模
在完成字符级的特征提取后,得到了由字符级特征和预训练词向量拼接的单词的向量表示wi,接下来则需要对句子中的时序关系进行建模。而在时序关系的建模上,循环神经网络模型(RNN)及其变体模型(LSTM、GRU等)通常具有很大的优势。循环神经网络通常可以按照时间步来展开,其基本结构如图4所示。

图4 循环神经网络的基本结构
其中:xt为t时刻的输入向量;Ot为t时刻的输出向量,ot=softmax(Vst)为t时刻的输出,表示预测标签的概率分布。ht时刻的隐藏层状态。ht可以通过上一时刻的状态ht-1以及当前时刻的输入xt来计算:
ht=f(Uxt+Wst-1)
(2)
式中:f()为tanh函数;W、U、V为网络模型学习的参数。
在实际应用中,循环神经网络通常会存在梯度消失和梯度爆炸的问题,长短期记忆网络(LSTM)则可以有效缓解该问题,因此一般会选择使用LSTM网络来进行对时序关系的建模。LSTM依靠三个部分来完成对细胞状态的保护和处理,分别为输入门、遗忘门和输出门,其中的门结构均是通过Sigmoid函数以及按位乘运算操作来实现的。在时间序列的第t个时间段,长短期记忆网络的各个部分的计算方法如下:
ft=σ(Wf·[ht-1;xt]+bf)
(3)
it=σ(Wi·[ht-1;xt]+bi)
(4)
(5)
(6)
ot=σ(Wo·[ht-1;xt]+bo)
(7)
ht=ot⊙tanh(Ct)
(8)

双向LSTM即是在原来从左往右的模型基础上再加一个从右到左的LSTM,但是输入是共享的,输出也是由前向隐藏状态和后向隐藏状态共同决定的。双向LSTM之所以被提出来是因为在序列建模中,当前的输出不仅与前面的信息有关系,也与后面的信息有关系,使用LSTM时隐藏层状态ht只能从过去的输入中获得信息,无法获得该输入之后的信息。在实体识别、组块分析等信息抽取任务上使用双向模型的效果要比单向的要好。
因此,本文选用BiLSTM来对单词级的特征进行建模,对任意句子s中的单词表示w1,w2,…,wN送入BiLSTM模型中:
(9)
(10)
(11)

2.5 基于注意力机制的句子级特征建模
注意力机制由人的视觉注意力启发而来,通常人的眼睛在观察事物的时候会集中注意力在一些比较重要的部分而忽略掉一些没有用的细节,在理解一篇文章时总是能够抓住最为重要的段落、句子或词语,这就是注意力机制[25]。该机制可以用于建模长句中的语义关系,在自然语言处理任务中得到了广泛的应用。
在经过BiLSTM层之后,每个词wi都被表示为隐藏状态ht,融合了句子内部的上下文语义信息。为了获得文档的高层语义信息,需要建模句子级的特征表示并对其进行标注。对任意句子s,有s={h1,h2,…,hN},其中ht为单词向量经BiLSTM编码后的结果。若将各单词的特征表示进行简单的拼接,则会忽视多个单词对句子语义的影响程度大小,可能会引入一定的噪声,影响句子级特征表示的结果。因此本文引入了注意力机制,对当前单词ht与句子中的所有词进行对齐模型计算,最终按权重加权求和,得到富含相关语义信息的单词的新表示zt:
(12)
式中:αi,t表达的是ht与hi的相关程度。
(13)
(14)
式中:M为权重,是注意力模型要学习的参数。通过上文所计算的注意力值,得到了具有不同权重的新的单词表示zt,以其均值作为句子的特征表示:
(15)
式中:T为句子中单词的个数。在以上的部分中得到了单词级的特征表示hi以及句子级的特征表示si,在下面的部分中使用CRF模型分别进行句子级和单词级的标注。
2.6 基于条件随机场的标签推断
在序列标注以及广泛的结构化预测任务中,对一个给定的输入单词序列,考虑其相邻的单词的标签关系并解码出全局最优的标签序列是很有必要的,而条件随机场(CRF,Conditional Random Field)能很好地捕获序列的局部结构并进行最优的全局解码,因此被广泛应用到序列标注的任务中。
对于给定的输入序列x={x1,x2,…,xn},其中xi为第i个单词的向量表示,y={y1,y2,…,yn}为输入序列x对应的标签,链式CRF定义了对于给定的输入序列x其标签序列y的概率:
(16)
式中:Y(x)为所有可能的标签序列的集合;ψi(y′,y,x)为势函数。ψi(y′,y,x)定义为:
(17)


(18)
本文分别使用CRF模型完成对句子级和单词级的标注,其中对句子级标注模型,使用句子级特征表示si作为输入特征,单词级标注使用单词级特征表示hi并拼接其所在句子的特征向量si作为表示特征,以引入句子的语义信息。
(19)
(20)
式中:LH为对句子序列进行标注得到的损失;LL为对单词级的序列进行标注得到的损失;WH、WL、bL和bH为待学习权重矩阵和偏置向量。
由此,可以得到联合标注模型的总损失函数:
L=LH+λLL
(21)
式中:λ为超参数,用于调节联合模型在训练时优先侧重的倾向。在本任务中,对高层标签的标注相对而言较为重要,实验时设定λ值为0.7。
3 实 验
3.1 数据简介
为了验证本文模型的有效性,本文使用具有两层结构的货运航运邮件来进行实验。数据层次级结构如图5所示。

图5 数据的层级结构
数据集共包含3 917个邮件文本,每个邮件文本中包含一个或多个盘块信息,需要抽取出来的盘块信息有船盘、货盘、期租盘三种,每个盘块占据邮件的一行或者多行。三类盘块中包含了多类字段信息,如:船盘内包含了船名、载重量、航速、建造船厂和控船方等;货盘中主要字段有货种、货量、租家和受载时间等;期租盘包含的主要字段有租家名称、交船时间/地点和租期等。三类盘块一共涵盖了118类信息,其中34类信息在多类盘块中重复出现。
3.2 对比方法
为验证所提出方法的性能,本文将该模型与其他几种方法的实验效果进行对比,所用的对比算法如下:
(1) 层级BiLSTM-CNN-CRF。使用两层单独的BiLSTM-CNN-CRF模型进行层级信息抽取,第一层提取盘块级信息,然后使用不同的BiLSTM-CNN-CRF模型对不同类别的盘块内的数据进行抽取。
(2) BiLSTM-CNN-CRF。在本文实验中,使用高层标签与低层标签拼接的方法得到包含了层次信息的标签,如船盘中的船名被标记为“B-船盘|B-船名”,使用BiLSTM-CNN-CRF模型进行标注。
(3) BiLSTM-CRF。标签方式同上,不使用CNN来提取字符级特征信息,使用BiLSTM直接对预训练的单词向量进行编码。
(4) LSTM-CNN-CRF。标签方式同上,使用单向LSTM来建模特征表示,其他设定与BiLSTM-CNN-CRF模型一致。
本文的方法独立地进行高层和低层的信息抽取,并使用联合学习方法进行信息交互促进两层标注任务的相互影响,最终拼接两层的标签来提取层级信息。
3.3 实验设置

3.4 实验结果分析
基于3.3节的实验参数设定,本文在货运航运数据集上进行层级信息抽取对比实验,并使用精确率、召回率、F1值作为评价指标,其值的计算方式如表1所示,评价准则均是越大越好。

表1 评价指标
在层级信息抽取问题中,可以通过真实的四元组与模型预测出的四元组进行比对,进而求出TP、FP、TN、FN等值。其中:TP代表真实存在该四元组,模型也预测出了该四元组的个数;FN代表真实存在该四元组,但模型没有预测出来的个数;其他两类类推。
为测试预训练词向量对模型性能的影响,本文首先使用不同的词向量表示进行实验,以9 ∶1的比例划分训练集和测试集,评价指标使用F1值,实验结果如表2所示。
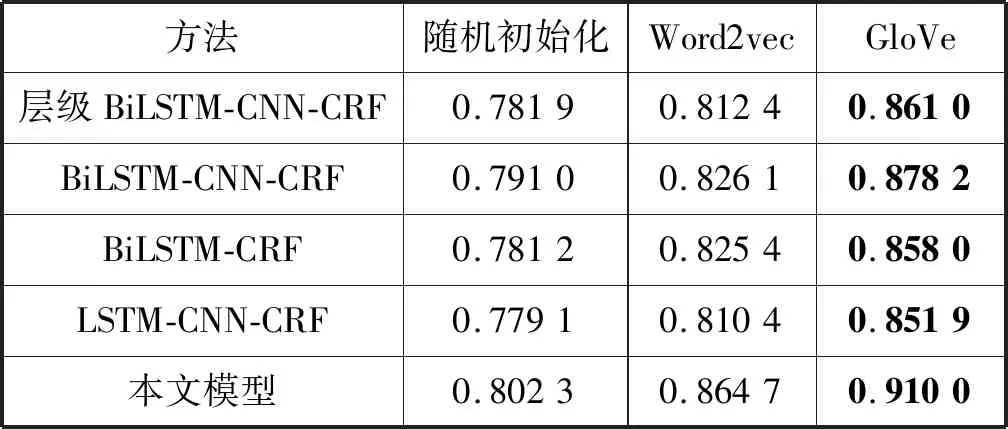
表2 不同词向量表示的实验结果
可以看出,GloVe词向量表示方法相对随机初始化词向量和Word2vec词向量有着更好的性能提升,因此本文选用了GloVe词向量进行后续的实验,以9 ∶1的比例划分训练集和测试集,并综合使用精确率、召回率和F1值作为评价指标,实验结果如表3所示。

表3 货运航运数据集层级信息抽取结果
可以看出,本文模型具有优于其他对比方法的性能,验证了其有效性。
本文分别以0.1、0.3、0.5、0.7和0.9等比例划分训练集和测试集,以此来分别检验在不同训练集比例下测试模型的效果,评价指标使用F1值,实验结果如表4所示。

表4 不同比例划分数据集实验结果
可以看出,无论是在何种比例划分的测试集上,本文模型都具有优于其他对比方法的效果,在使用较小的训练集的情况下,本文方法依然具有较高的F1值,能有效应对实际应用中训练数据较少的情况。
除上述实验外,本文还进一步分析了模型对参数的敏感程度。在本文方法中使用了CNN模型来提取出字符级的语义表示,然后再拼接预训练词向量作为其他模块的输入,其字符级特征的提取在本文方法中扮演着重要的角色。因此这里主要研究了用于提取字符级特征的CNN模型的参数对于模型效果的影响。图6展示了CNN的卷积核个数从16变化到512的过程中模型在该数据集上信息抽取性能F1值的变化情况。
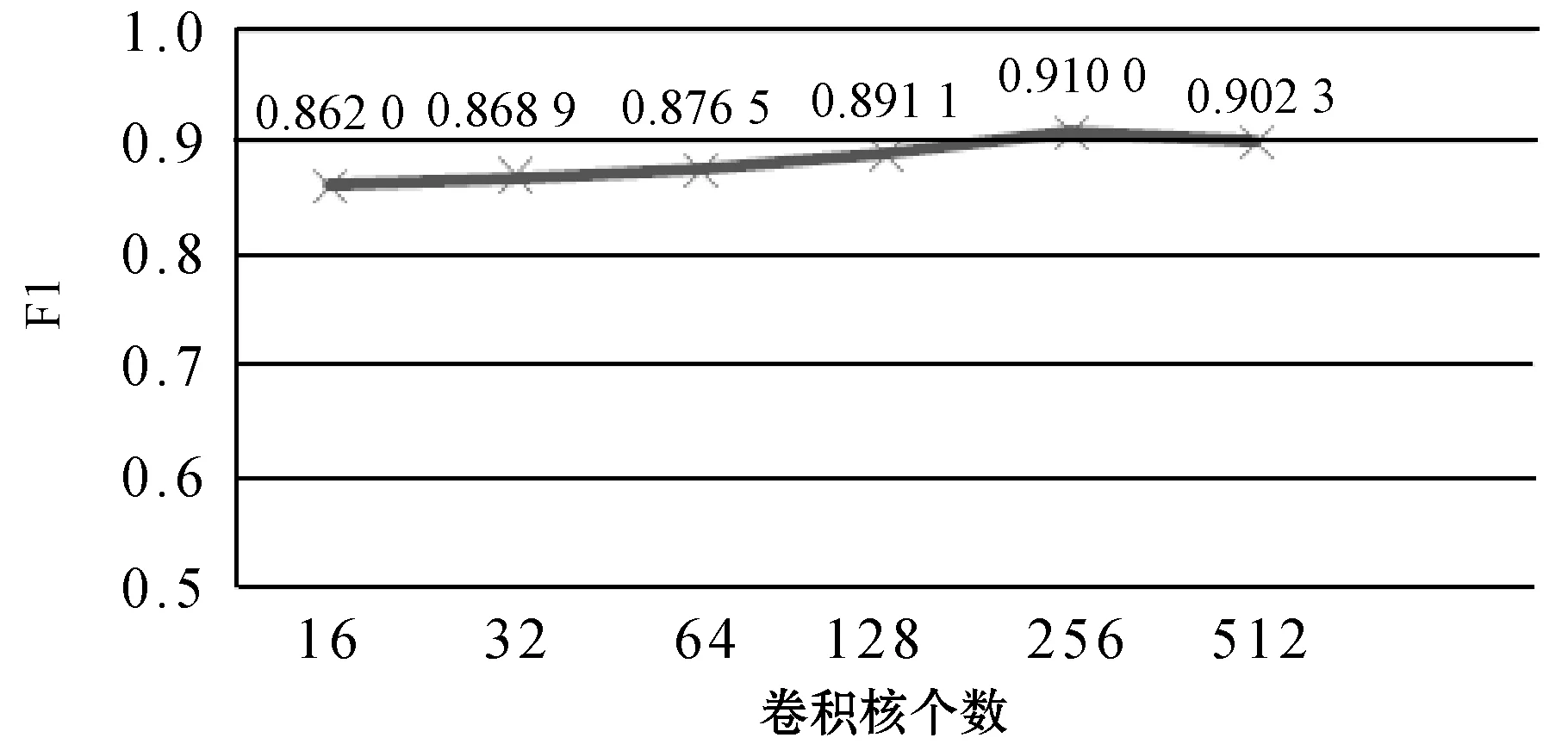
图6 分类性能随卷积核个数变化情况
可以看出,当卷积神经网络的卷积核的个数增加时,模型的分类性能在整体趋势上有所上升,但当卷积神经网络的卷积核的个数过多时,模型的性能反而会略微下降。原因是卷积核的个数过多,神经网络模型过于复杂,很容易处于过拟合的状态,不能很好地完成预测任务。因而在本文实验中使用256个卷积核进行句子级特征的提取,以达到最佳分类效果。
为分析本文模型的实际效果同样进行了信息抽取的实例展示,使用本文模型与相对其他方法效果更好的BiLSTM-CNN-CRF对图7所示的邮件文本进行信息抽取。

图7 用于信息抽取的文本示例
该示例文本由四行组成,其中:第一行为无用信息;第二行、第三行为一个货物盘块;第四行为一个船只盘块,其具体真实标签与模型预测结果如图8所示。

图8 示例邮件文本信息抽取结果
可以看出,本文模型相对于BiLSTM-CNN-CRF模型能更好地结合高层级和低层级的语义信息,进而做出更为正确的预测,有效地提升了层级信息抽取的正确率。
4 结 语
在大数据的背景下,针对层级文本数据的信息抽取问题在很多研究课题与实际应用中都占据十分重要的地位,具有很重要的现实意义。本文以货运航运数据为研究对象,构建基于联合标注的层级信息抽取方法,对不同层级的信息独立进行抽取,并结合多任务学习的方法进行联合训练。最后对实验结果进行了细致的分析与对比,证明了本文模型的有效性。本文提出的联合标注的层级信息抽取方法为面向层级文本数据的信息抽取任务提供了一定的思路,通过大量的实验以及结果分析为后续的研究工作提供了理论依据和实践基础。
随着深度学习理论的发展,深度神经网络方法在众多任务中均展现出较好的实验效果。目前本文所使用的模型均为浅层的神经网络模型,并没有涉及到过于复杂的网络结构,可能无法达到最优的推断性能。因此在后续的研究工作中将对该框架做进一步的改进,使用更为优秀的神经网络模型,如使用Transformer模型等,以期达到更好的推断效果。
