山西芝麻种质资源SSR遗传多样性及群体结构分析
2021-08-11韩俊梅任果香王若鹏刘文萍
吕 伟 韩俊梅 任果香 文 飞 王若鹏 刘文萍
(山西农业大学经济作物研究所,山西 太原 030031)
芝麻(SesamumindicumL. )隶属胡麻科(Pedaliaceaie)胡麻属(Sesamum)[1],是我国六大特色油料作物之一[2-5]。芝麻种子含油量达55%以上,亚油酸含量达40%以上,素有油中“皇后”之美誉,因含有丰富的营养物质,广泛应用于食品、医药、美容等领域[6-8]。此外,芝麻具有耐贫瘠、耐旱、适应性强等特性,在我国种植历史悠久,多数省份均有种植[9-10]。山西是我国西北地区芝麻主产省,但近年来芝麻种植面积逐年下降,单产低而不稳,严重影响山西芝麻产业的发展,其主要原因在于育成品种的亲本遗传基础狭窄、抗逆性较差。因此,分析和研究芝麻种质资源及其遗传多样性对有效利用种质资源,拓宽育种亲本的遗传基础,培育高产、优质、抗逆芝麻新品种具有重要意义。
种质资源遗传多样性的分析方法主要包括表型性状和分子标记,利用表型性状开展种质资源遗传多样性研究的方法最为普遍[11],具有简单、直观、易观察记载的特点[12],但由于表型性状易受环境因素影响,对种质资源鉴定具有一定的局限性[13]。随着分子生物学技术的发展,DNA分子标记已广泛应用于作物的遗传多样性研究。简单重复序列标记 (simple sequence repeat,SSR)具有多态性高、重复性好、呈共显性、分布广等优点[14-17],已成为理想的遗传标记技术。目前,国内外学者利用SSR分子标记已对玉米[18]、黑麦[19]、大豆[20]、水稻[21-22]、花生[23-24]、豌豆[25]、藜麦[26]、绿豆[27]、小麦[28]等多种作物进行了遗传多样性研究。在芝麻上,Kim等[29]利用14对SSR引物对来自韩国和其他国家的75份芝麻资源进行了遗传多样性分析;孙建等[30]利用SSR分子标记对我国20份黑芝麻进行遗传多样性分析;刘文萍等[9]研究发现山西芝麻种质资源与我国其他主产区种质资源的遗传关系较远。但利用SSR分子标记对山西芝麻种质资源遗传多样性的研究鲜见报道。因此,本研究以71份山西芝麻种质资源为研究材料,通过SSR分子标记对其进行遗传多样性分析及群体结构分析,以期探明山西芝麻种质资源的遗传变异特性,为山西芝麻育种亲本选择、品种改良和优异基因发掘提供理论依据。
1 材料与方法
1.1 供试材料
1.1.1 供试芝麻材料 山西芝麻种质资源共计71份(表1),由山西农业大学经济作物研究所提供。
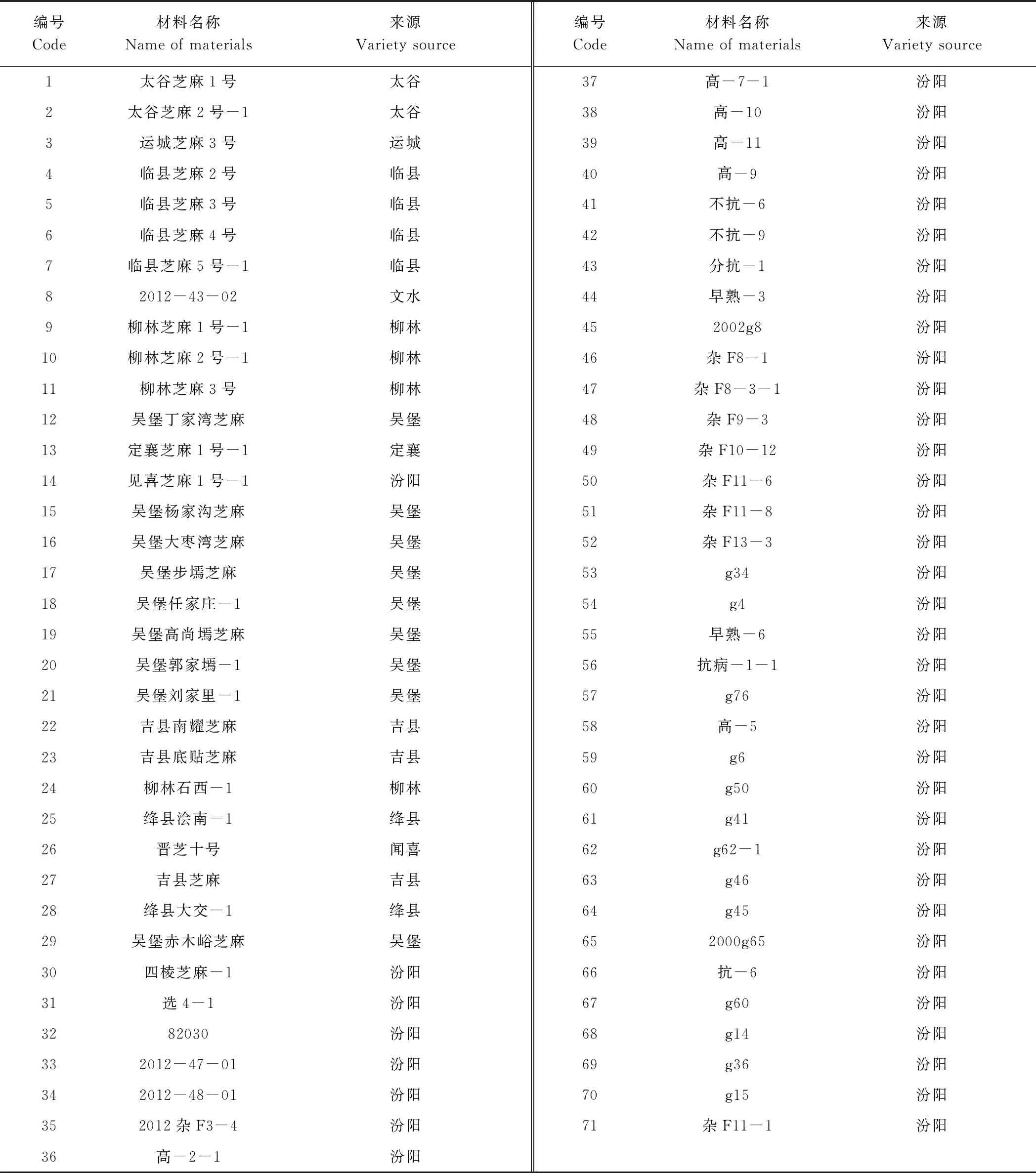
表1 参试芝麻种质资源名称及编号
1.1.2 SSR标记引物 30对多态性较好的SSR标记引物,由中国农业科学院油料作物研究所提供,引物序列信息见表2。
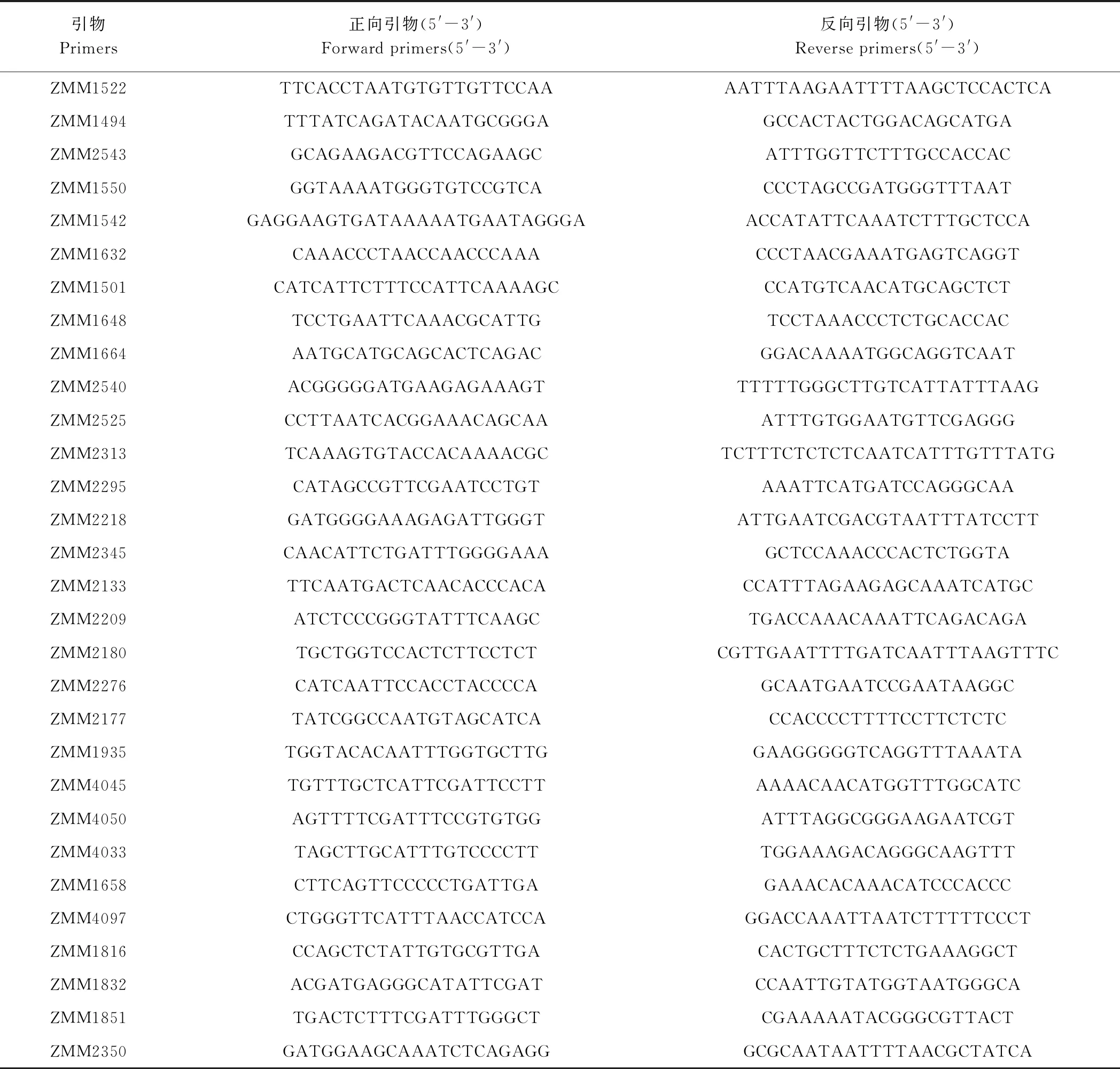
表2 30对SSR引物序列
1.2 试验方法
1.2.1 DNA的提取与质量检测 将参试芝麻材料在室内培养,取其幼嫩叶片,采用CTAB改良法[31]提取基因组DNA,利用NANODROP 2000紫外分光光度核酸测定仪(Thermo,美国)检测其质量和浓度,将其稀释至20 ng·μL-1,放置-20℃冰箱保存备用。
1.2.2 PCR扩增 PCR反应体系(10 μL): DNA 2.5 μL、10×buffer 1 μL、Taq DNA聚合酶0.16 μL、dNTP 0.2 μL、正反引物各0.16 μL、ddH2O 5.82 μL。PCR扩增反应程序:94℃预变性4 min;94℃变性40 s,55℃退火40 s,72℃延伸1 min,共32次循环;72℃延伸10 min,4℃保存。PCR扩增产物经6%聚丙烯酰胺凝胶电泳,银染显色后拍照记录。
1.3 SSR分子标记统计与数据分析
记录清晰的SSR扩增条带,有条带赋值为“1”,无条带赋值为“0”,利用Microsoft Office Excel 2010软件统计整理数据。利用POPGENE 1.31软件计算每对引物的等位基因数(Na)、有效等位基因数(Ne)、Shannon指数(Ⅰ)、Nei′s遗传多样性指数(H)。利用LITTLE PROGRAME软件计算每对引物的多态性信息含量(polymorphism information content,PIC)。利用NTSYS-pc 2.1软件按照非加权配对算术平均法(unweighted pair-group method with arithmetic means,UPGMA)对参试材料进行聚类分析。利用STRUCTURE 2.3.1软件对参试材料进行遗传结构分析,设置分析群体数K值范围为1~10,将MCMC(markor chain monte carlo)开始时的不作数迭代设为100 000次,再将不作数迭代后的MCMC设为100 000次,迭代次数设置为5。
2 结果与分析
2.1 SSR标记对芝麻种质资源的遗传多样性分析
利用多态性较好的30对SSR分子标记对71份山西芝麻种质资源进行遗传多样性分析(图1),由表3可知,30对SSR标记共检测到144个等位基因位数(Na),变幅为2~10个,平均每个SSR标记4.800 个等位基因,等位基因数在5~10之间的有15对,占参试的50.0%,其中ZMM1494引物检测到的等位基因数最多,为10个,其次为ZMM1832、ZMM1935引物,分别检测到8个等位基因数。有效等位基因数(Ne)在1.058 ~5.149 之间,平均2.805 个,其中ZMM1832引物引物检测到的有效等位基因数最多,为5.149 个,其次为ZMM1550,为5.128 个,ZMM1542、ZMM2313引物的有效等位基因数最少,均为1.058 个。
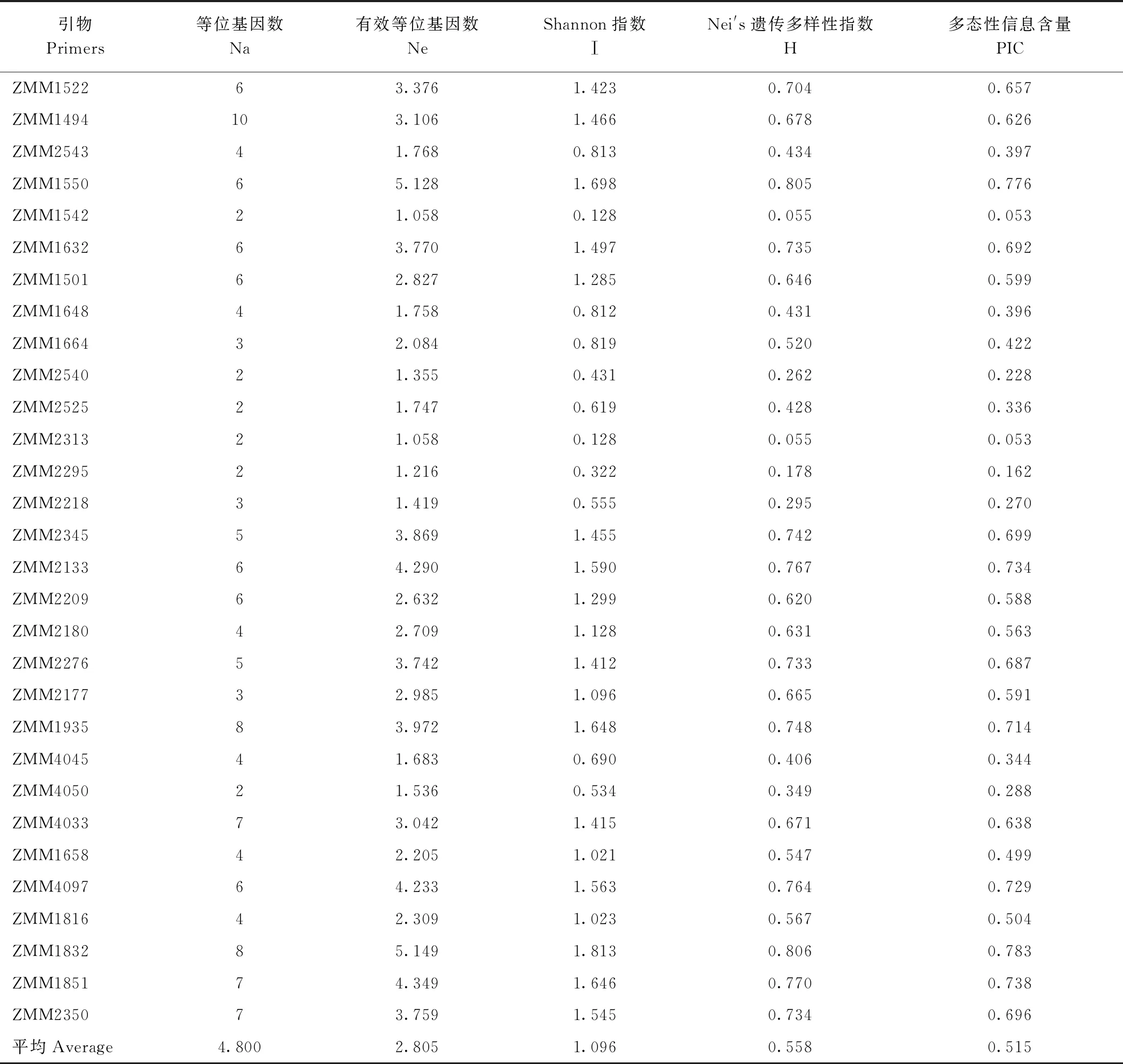
表3 30对SSR分子标记在71份芝麻种质检测到的遗传变异参数

图1 SSR引物ZMM2540和ZMM2313对编号1~12芝麻种质扩增产物的电泳图
30对SSR引物的Shannon指数(Ⅰ)变幅为0.128 ~1.813,平均为1.096,其中ZMM1832的Shannon指数最高,ZMM1542的Shannon指数最低,Shannon指数在1.5以上的有ZMM1550(1.698)、ZMM2133(1.590)、ZMM1935(1.648)、ZMM4097(1.563)、ZMM1832(1.813)、ZMM1851(1.646)、ZMM2350(1.545)。Nei′s遗传多样性指数(H)变幅为0.055 ~0.806,平均为0.558,其中ZMM1832的Nei′s遗传多样性指数最高,ZMM1550次之,ZMM1542和ZMM2313的Nei′s遗传多样性指数最低,Nei′s遗传多样性指数在0.7以上的有ZMM1522(0.704)、ZMM1550(0.805)、ZMM1632(0.735)、ZMM2345(0.742)、ZMM2133(0.767)、ZMM2276(0.733)、ZMM1935(0.748)、ZMM4097(0.764)、ZMM1832(0.806)、ZMM1851(0.770)、ZMM2350(0.734)。PIC变幅为0.053 ~0.783,平均为0.515,其中ZMM1832的PIC最高,ZMM1542和ZMM2313的PIC最低,PIC在0.7以上的有ZMM1550(0.776)、ZMM2133(0.734)、ZMM1935(0.714)、ZMM4097(0.729)、ZMM1832(0.783)、ZMM1851(0.738)。
2.2 SSR标记对芝麻种质资源的聚类分析
采用NTSYS-pc 2.1软件按照UPGMA法对参试材料进行聚类分析,并制作聚类树状图。由图2可知,71份山西芝麻种质资源的遗传相似系数范围为0.21~0.67,在遗传相似系数0.27处将参试材料分为六大类,第Ⅰ类包括2份芝麻种质,分别为太谷芝麻1号、运城芝麻3号;第Ⅱ类包括4份芝麻种质,分别为见喜芝麻1号-1、四棱芝麻-1、杂F11-6、绛县浍南-1;第Ⅲ类包括4份芝麻种质,分别为吴堡杨家沟芝麻、晋芝十号、吉县芝麻、绛县大交-1;第Ⅳ类包括51份芝麻种质,以遗传相似系数0.3为阈值,将第Ⅳ类分为Ⅳ-A、Ⅳ-B、Ⅳ-C三亚群,其中Ⅳ-A由5份芝麻种质组成(太谷芝麻2号-1、临县芝麻5号-1、柳林芝麻3号、吴堡郭家墕-1、早熟-3),Ⅳ-B由33份芝麻种质组成,基本为汾阳芝麻种质,Ⅳ-C由13份芝麻种质组成(临县芝麻2号、临县芝麻3号、临县芝麻4号、2012-43-02、柳林芝麻1号-1、吴堡丁家湾芝麻、定襄芝麻1号-1、吴堡大枣湾芝麻、吴堡高尚墕芝麻、吴堡刘家里-1、柳林石西-1、吴堡赤木峪芝麻、不抗-9);第Ⅴ类包括9份芝麻种质,分别为吴堡任家庄-1、2012杂F3-4、82030、2012-48-01、2012-47-01、吉县南耀芝麻、g14、吉县底贴芝麻、选4-1;第Ⅵ类包括1份芝麻种质,为柳林芝麻2号-1。在所有的参试材料中,63号(g46)、65号(2000g65)、71号(g15)这3份芝麻种质间的遗传相似性系数以及67号(g60)、70号(g67)这2份芝麻种质间的遗传相似性系数最高,均为0.67;1号(太谷芝麻1号)、27号(吉县芝麻)、10号(柳林芝麻2号-1)、28号(绛县大交-1)、3号(运城芝麻3号)这5份芝麻种质的遗传相似系数的平均值较低,分别为0.195、0.200、0.207、0.211、0.218。

图2 基于SSR标记山西芝麻种质聚类树状图
同时采用NTSYS-pc软件对71份芝麻种质进行二元主成分分析,构建主成分分析二维图(图3)。根据参试材料在图中的位置分布,将71份材料分成4部分,a区域主要为类群Ⅳ-B的部分材料,b区域主要为类群Ⅳ-A、Ⅵ材料及类群Ⅳ-B的部分材料,c区域主要为类群Ⅰ、Ⅱ、Ⅲ、Ⅴ材料,d区域主要为类群Ⅳ-C材料。主成分分析从不同的角度更直观地对71份山西芝麻种质资源进行了亲缘关系分析,山西芝麻种质资源在主成分分析二维图分布较为均匀,表明其遗传多样性较为丰富。
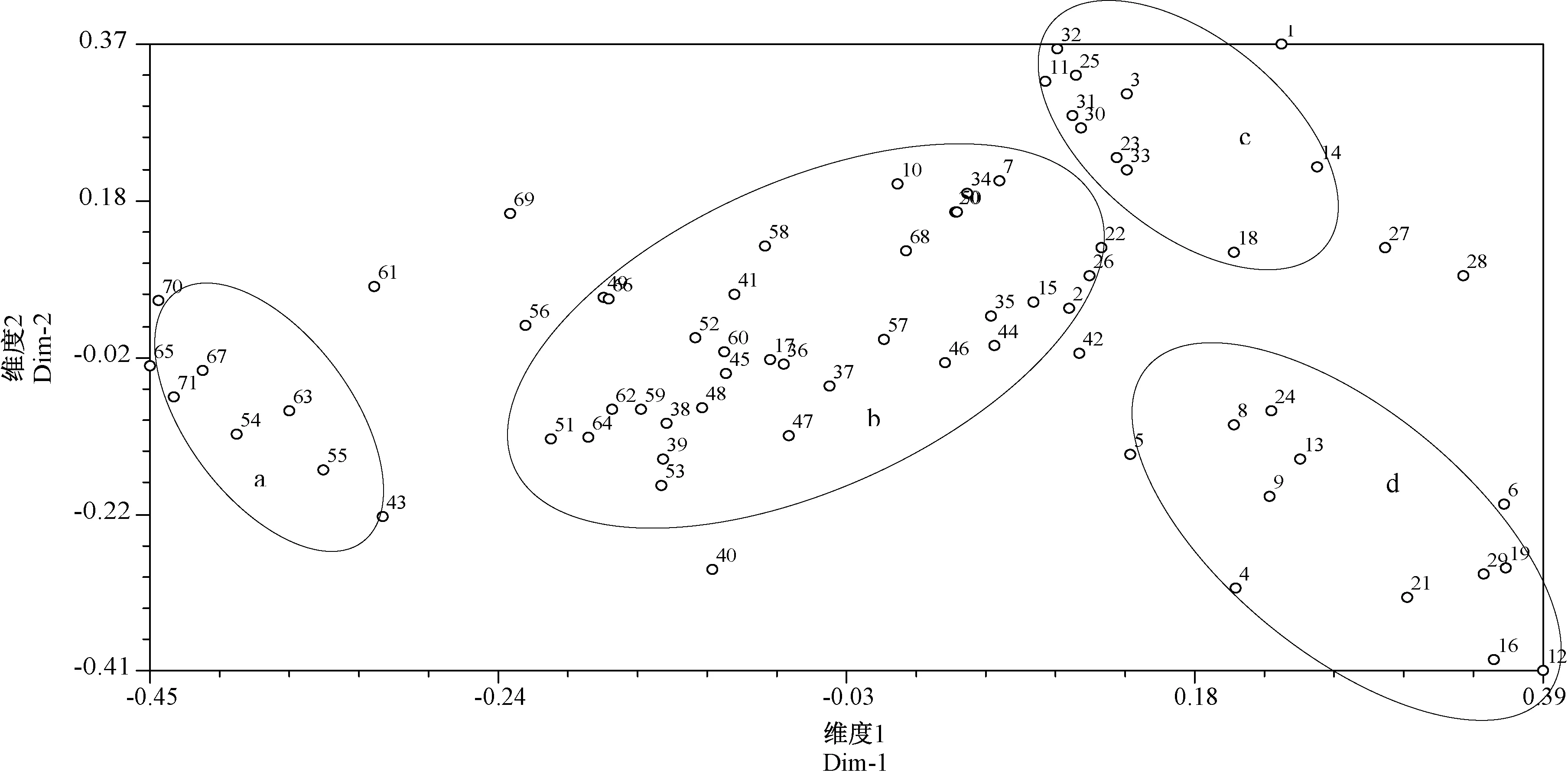
图3 71份芝麻种质资源二元主成分分析
根据DNA扩增结果,对山西11个不同地理来源芝麻亚群进行分析,获得11个亚群的遗传一致度和遗传距离结果。由表4可知,从遗传距离来看,11个亚群间的遗传距离介于0.050 ~0.325 之间,平均为0.164。从遗传一致度来看,11个亚群间的遗传一致度范围为0.722 ~0.951,平均为0.850,其中柳林芝麻亚群与吴堡芝麻亚群之间遗传距离最小,为0.050,遗传一致度最高,为0.951,说明它们之间的遗传交流频率相对较高;文水芝麻亚群与运城芝麻亚群遗传距离最大,为0.325,遗传一致度最低,为0.722,说明它们之间的遗传交流频率相对较低,亲缘关系较远。对山西11个不同地理来源芝麻亚群进行聚类分析,由图4可知,柳林、吴堡、临县、汾阳等山西西部地区芝麻种质间遗传距离较近,吉县、绛县、定襄、文水、闻喜、运城等山西中部地区、山西南部地区芝麻种质与山西西部地区芝麻种质的遗传距离较远。
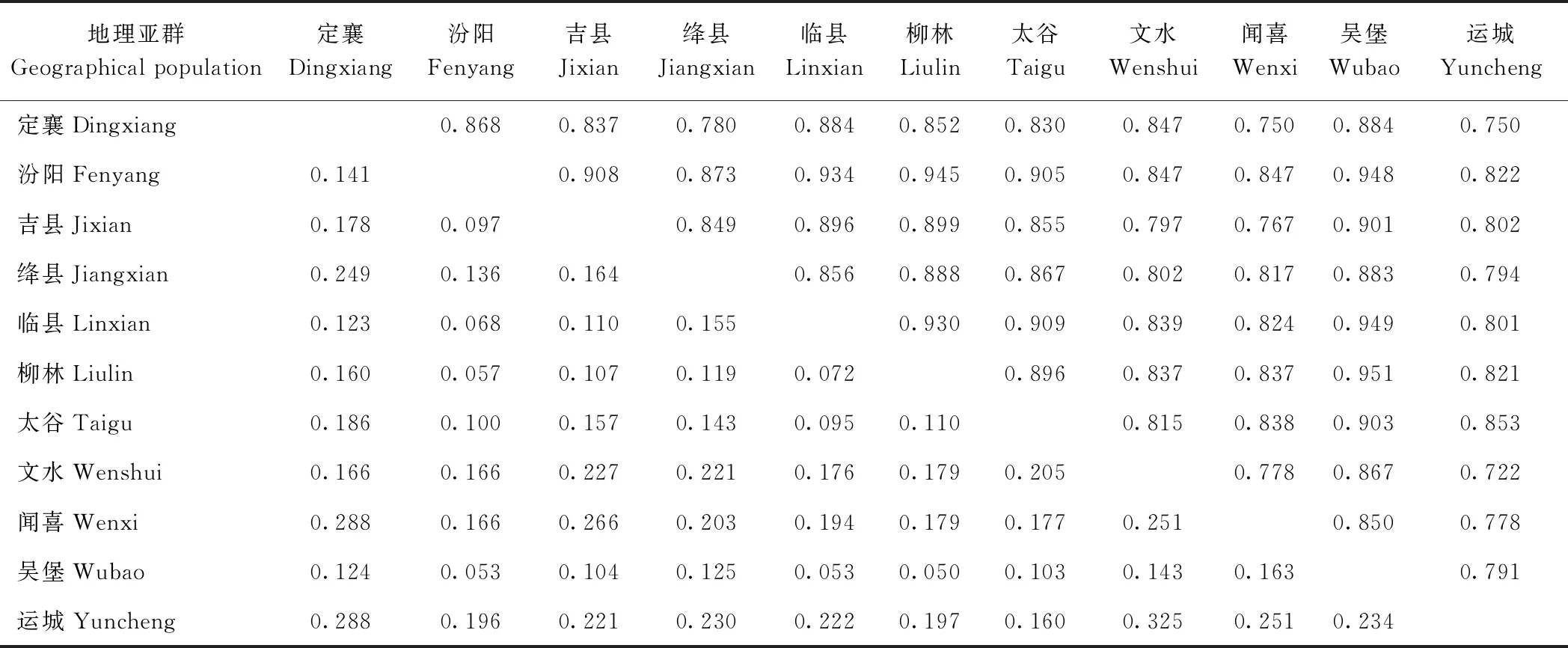
表4 山西11个芝麻亚群的遗传距离(左下角)和遗传一致度(右上角)
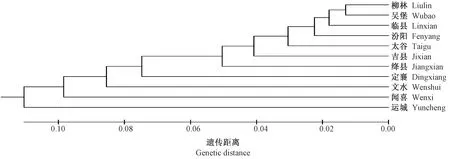
图4 山西11个芝麻亚群的UPGMA聚类分析
2.3 SSR标记对芝麻种质资源的群体结构分析
基于SSR分子标记检测结果,将分析得到的LnP(D)平均值绘制折线图(图5),结果表明,在K=5时LnP(D)似然值最大。因此,将71份参试材料划分为5个组群(图6)。
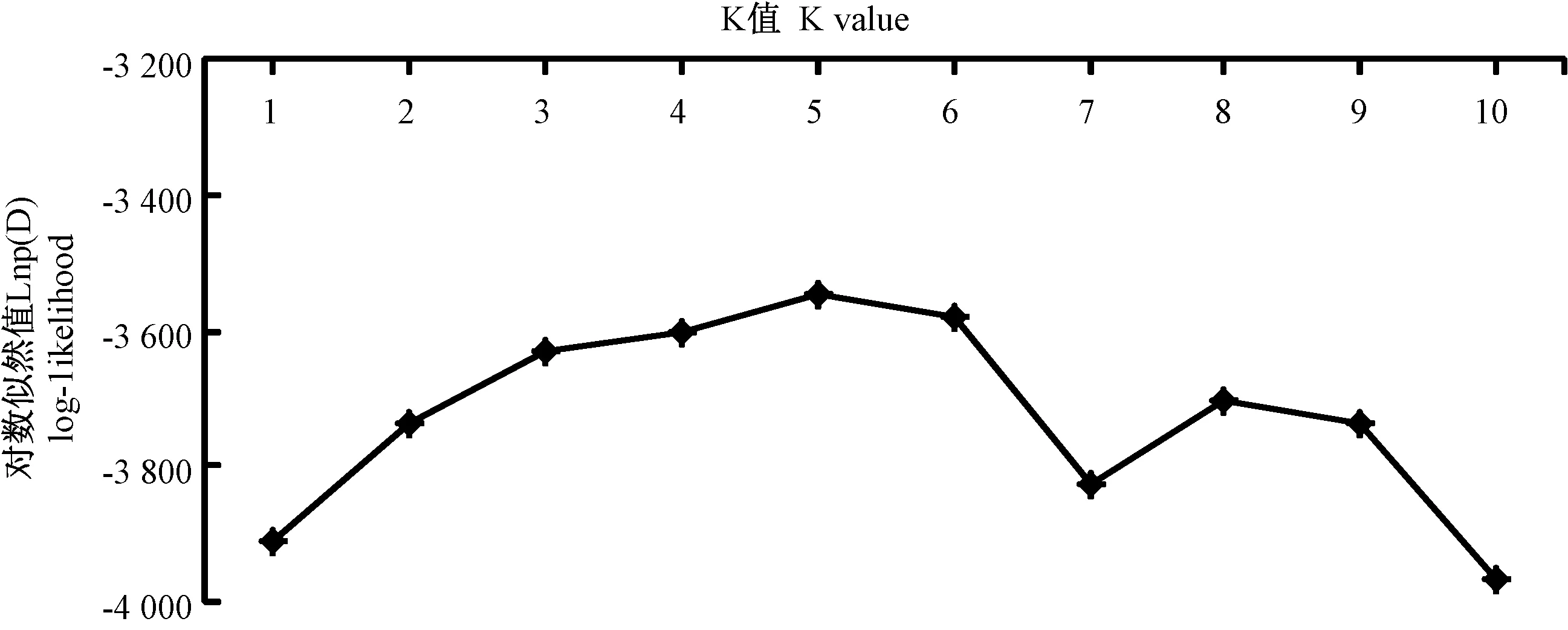
图5 对数似然函数值LnP(D)的变化曲线
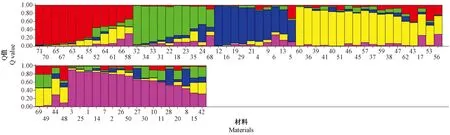
图6 基于SSR标记的山西芝麻种质遗传结构图
当某一材料在某个组群中的Q值≥0.6时,认为该材料遗传结构相对单一,某一材料在某个组群中的Q值<0.6时,则认为该材料拥有混合来源[32-33],因此,为了能够充分体现山西芝麻材料间的遗传结构成分,分析其在不同组群的Q值分布,将Q值大于或等于0.6的46份山西芝麻种质材料(占参试材料的64.8%)划归到相应的5个组群中,其余25份来源于汾阳、吴堡、柳林、临县、绛县、定襄、文水的芝麻种质材料(占参试材料的35.2%)遗传结构具有复杂的混合来源,无法明确其归属的组群,因此将其划归为混合组群中(表5)。由表5可知,组群1(图6红色组群)的芝麻材料有7份,占参试材料的9.9%,均为来源于汾阳,分布于二元主成分分析的a区域;组群2(图6绿色组群)的芝麻材料有7份,占参试材料的9.9%,来源于汾阳、吉县、吴堡,分布于二元主成分分析的b、c区域;组群3(图6蓝色组群)的芝麻材料有8份,占参试材料的11.3%,来源于吴堡、临县、柳林,分布于二元主成分分析的d区域;组群4(图6黄色组群)的芝麻材料有13份,占参试材料的18.3%,均为来源于汾阳,分布于二元主成分分析的b区域;组群5(图6粉色组群)的芝麻材料有11份,占参试材料的15.5%,来源于汾阳、太谷、吉县、绛县、闻喜、运城、柳林、临县,分布于二元主成分分析的b、c区域。该群体结构的组群划分不仅体现了参试芝麻种质间的亲缘关系,且与二元主成分分析结果大致吻合。
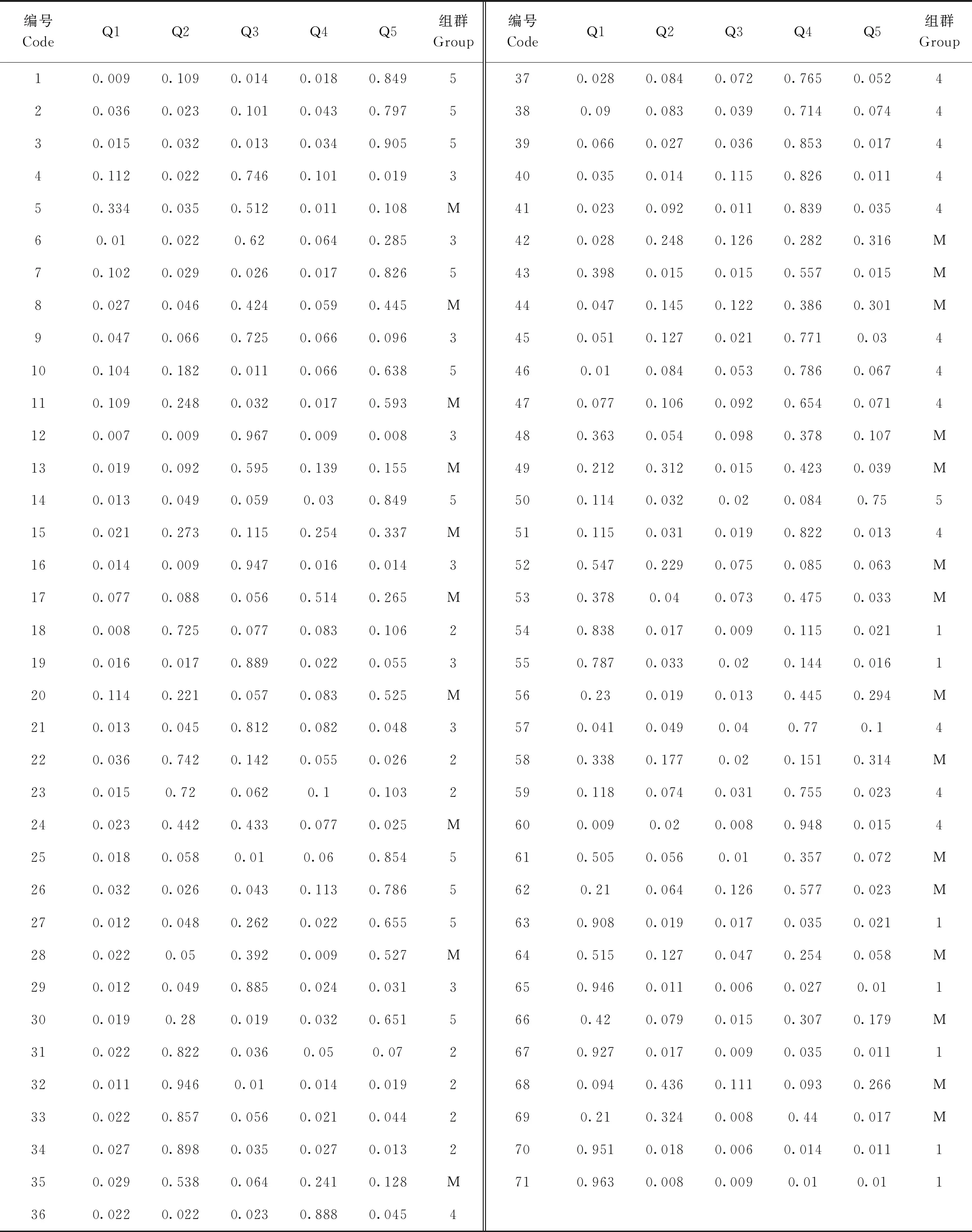
表5 71份芝麻种质在5个不同组群的Q值
由表6可知,从遗传距离来看,6个组群间的遗传距离介于0.033 ~0.168 之间,平均为0. 091;从遗传一致度来看,6个组群间的遗传一致度范围为0.846 ~0.968,平均为0.913。由图7可知,组群1与组群3之间遗传距离最大,为0.168,而遗传一致度最低,为0.846;组群4与组群M遗传距离最小,为0.033,而遗传一致度最高,为0.968。
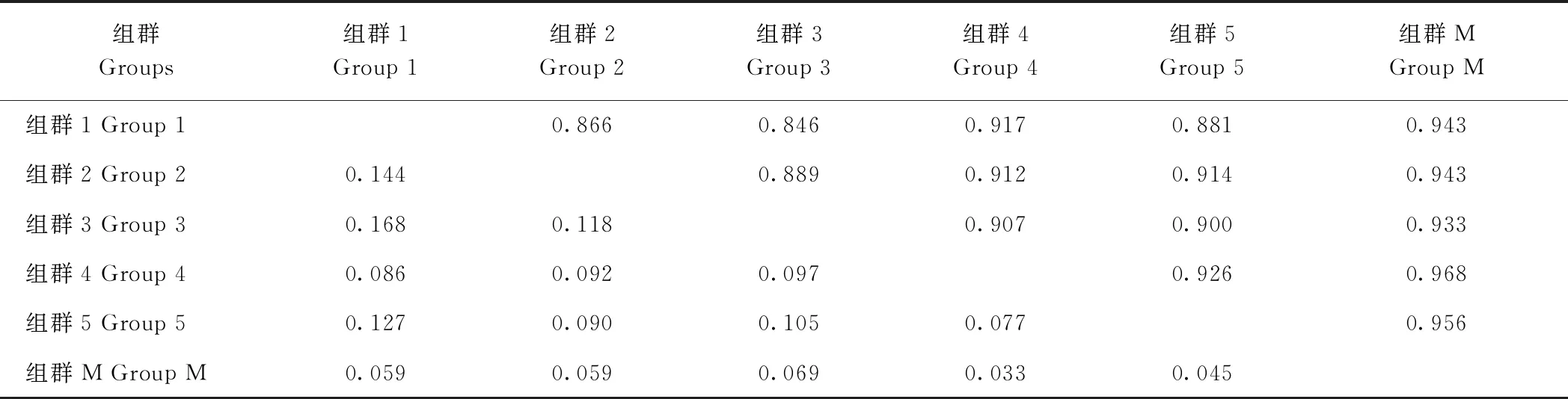
表6 6个芝麻组群的遗传距离(左下角)和遗传一致度(右上角)
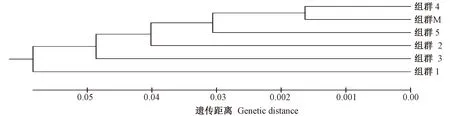
图7 6个芝麻组群的UPGMA聚类分析
3 讨论
芝麻品种的遗传改良主要取决于对芝麻种质资源的掌握与利用,只有掌握芝麻种质材料的遗传变异信息,才能更有针对性选择亲本材料,从而有助于培育出杂种优势较大的后代。DNA分子标记技术是分析植物遗传多样性和遗传基础的主要方法,大量研究表明,SSR标记以其稳定性高、易于操作、信息含量丰富等优点,成为研究芝麻种质间遗传差异、种属间亲缘关系最重要、发展最迅速的分子标记[30]。孙建等[30]利用23对SSR分子标记对我国20个芝麻品种进行遗传多样性分析,每对标记检测出3~6个等位基因位点,平均每对标记4.00个等位基因;张艳欣等[34]用20对SSR引物对216份芝麻核心种质进行检测,每对引物检测出2~8个等位基因位点,平均等位基因为3.95个;岳文娣等[35]利用42对SSR引物对国内外545份芝麻品种进行遗传多样性分析,引物的等位基因位点范围为3~9个, 平均每对引物等位基因为3.8个,PIC平均值为0.409 2;魏利斌等[36]用27对SSR多态引物对国内外36个芝麻材料进行遗传多样性分析,检测到的等位基因位点为2~7个,平均3.37个,PIC平均值为0.390。而本试验利用30对SSR标记对71份山西芝麻种质进行遗传多样性分析,每对标记检测出2~10个等位基因位点,平均每个SSR标记4.800 个等位基因,PIC平均值为0.515,均高于前人研究结果,说明本研究采用的SSR标记具有更高的多态性,参试的芝麻种质资源具有较高的遗传多样性。此外,PIC是核心引物筛选的重要指标,本研究中引物ZMM1494的等位基因数最多,为10个,PIC为0.626,ZMM1935、ZMM4097、ZMM2133、ZMM1851、ZMM1550、ZMM1832的等位基因数变幅为6~8个,少于ZMM1494,但其PIC较高,变幅在0.714 ~0.783 之间。这些具有较高多态性的SSR标记,不仅在分析芝麻种质亲缘关系方面发挥重要作用,也为芝麻遗传变异检测等其他分子生物学研究提供重要标记资源。
本研究利用NTSYS-pc软件对71份山西芝麻种质资源进行UPGMA法聚类分析和二元主成分分析,同时利用Structure软件对其进行遗传结构分析,这3种聚类分析方法对参试芝麻种质的聚类结果大致吻合,但略有差异,主要是由其聚类原理和方法决定的。UPGMA法聚类是假设各类群的进化速率相同,按照顺序依次将距离最小的两个材料聚在一起,直到所有的材料都聚到一个完整的系统发生树中[37]。而二元主成分分析则是利用降维的统计方法,把多个指标转化为几个综合指标,降低观测的空间维数来获取最主要的信息,通过直观图像距离获取材料间相关性的分析方法[38]。UPGMA法聚类分析和二元主成分分析基于参试材料的遗传相似系数和遗传距离对其进行群体划分,但这种群体聚类结果时常由于人为地将平面区域位置较近者划归为一类,使类群间相互渗透的材料不易划分,而群体结构分析基于哈代-温伯格平衡和贝叶斯模型算法,避免了人为因素对群体划分造成的偏差[32]。因此,本研究采用距离聚类与模型聚类相结合的方法分析种质资源,对充分掌握群体间和种质间的亲缘关系具有重要意义。
遗传相似系数可判断作物种质资源亲缘关系,在亲缘关系研究中,遗传相似系数越低则亲缘关系越远,说明材料之间遗传差异越大[37]。岳文娣等[35]利用SSR引物分析中国芝麻种质资源的遗传相似系数在0.546 2~0.981 1之间,其中东北、西北等区域的资源与黄淮、华中、华南等区域的资源亲缘关系较远;刘文萍等[9]分析98份芝麻种质资源的遗传相似系数在0.280 ~0.996 之间,其中山西芝麻种质与我国芝麻主产区芝麻种质遗传关系较远,其遗传相似系数集中在0.300 ~0.500 之间。本研究中,71份山西芝麻种质资源的遗传相似系数为0.21~0.67,说明山西芝麻种质资源遗传差异相对较高,遗传基础较广,具有丰富的遗传多样性,其中太谷芝麻1号、吉县芝麻、柳林芝麻2号-1、绛县大交-1、运城芝麻3号的遗传相似系数的平均值较低,表明这5份芝麻种质在整个群体的遗传距离相对较远,这为今后芝麻杂交育种及遗传改良提供了材料基础。
本研究对不同区域芝麻种质亚群进行聚类分析,从聚类结果发现柳林、吴堡、临县、汾阳等山西西部地区芝麻种质间遗传距离较近,这可能是因为其芝麻种质之间交流频繁或地理环境相近,从而导致其遗传基础较一致,而吉县、绛县、定襄、文水、闻喜、运城等山西中部地区、山西南部地区芝麻种质与山西西部地区芝麻种质的遗传距离较远。同时对遗传结构分析得到的6个组群进行了聚类分析,发现组群1、组群3与组群4间的遗传距离接近6个组群间的平均遗传距离(0.091),说明汾阳、吴堡、临县、柳林等山西西部地区芝麻种质间遗传距离较近,而组群1、组群3与组群5间的遗传距离较大,说明山西西部地区芝麻种质与山西中部、南部地区芝麻种质的遗传距离较远,这与不同区域芝麻种质亚群聚类分析结果相一致。因此,有必要加大对山西中部、南部地区芝麻种质资源的收集、发掘与利用,为今后芝麻改良育种提供理论和材料基础。
4 结论
本研究利用30对SSR标记对山西芝麻种质资源进行遗传多样性分析,结果表明,每个SSR标记平均4.800 个等位基因,多态性信息含量平均为0.515,同时发掘出ZMM1935、ZMM4097、ZMM2133、ZMM1851、ZMM1550、ZMM1832等多态性较高的SSR标记,该研究结果为今后芝麻品种遗传改良和功能分子标记开发提供了理论基础。基于SSR标记对参试材料进行UPGMA聚类分析,发现参试材料的遗传相似系数范围为0.21~0.67,在遗传相似系数0.27处将参试材料分为6个类群,同时对不同区域芝麻种质亚群进行聚类分析,发现山西西部地区芝麻种质与中部、南部地区芝麻种质的遗传距离较远。本研究不仅阐明了山西芝麻种质遗传多样性,还为今后山西芝麻种质资源的收集、发掘及利用提供了一定的理论和材料基础。
