一种基于Q-Learning的蜂窝网络中D2D通信资源分配策略
2021-08-10谢经纬许艺瀚
谢经纬,许艺瀚,花 敏
(南京林业大学 信息科学技术学院,南京 210037)
设备到设备(device-to-device,D2D)技术是指通信网络中近邻设备之间直接交换信息的技术[1].D2D的优势在于能够实现数据的直连传输,无需依赖基站或中继设备的参与,从而降低通信网络的数据传输压力,提高频谱利用率和吞吐量,使通信系统更加灵活、智能和高效地运行,给爆炸式增长的智能设备和日趋紧张的频谱资源之间的矛盾提供了新的解决办法[2].
目前,标准化组织3GPP已将D2D技术列为新一代移动通信系统的发展移动通信系统的发展框架中,并成为第五代移动通信(5 Generation,5G)的关键技术之一.在LTE蜂窝网络中,由于D2D通信的引入,系统的资源分配方式将发生变化.为了避免D2D通信与传统蜂窝网络之间的干扰所造成的用户服务质量(quality of servic,QoS)的降低,利用功率控制和信道分配来降低干扰极具研究价值[3].当一个信道被多个用户复用时,由于链路之间的相互干扰,通过功率控制的方法来最大化通信速率可被转化为一个非凸问题.强化学习是探索与反馈相结合的算法,在利用强化学习之前往往需要将问题转化为马尔可夫决策过程(Markov decision process,MDP),再利用动态规划算法求解[4].文献[5-6]中均采用机器学习的方法解决模型求解问题,并提出了基于博弈论的方法求解D2D接入传统蜂窝网络的方案.文献[7]在保证蜂窝用户的QoS的情况下,通过资源分配可以提高系统的吞吐量,文献[8]提出一种优化Q-强化学习的自适应谈判算法,提高主体的学习能力,考虑对手的行为,提高智能化程度.文献[9]采用增强学习算法的扩展版本来控制直连通信用户设备传输功率,以减少由资源共享引起的干扰.文献[10]利用匹配理论为D2D集群分配通道,并采用顺序凸规划将优化目标转化为凸问题,然后再通过遗传算法对其进行求解.文献[11]提出了一种基于D2D通信模式选择的资源分配算法,提高5G了网络中移动终端分布密集的场景下资源的有效分配.文献[12]提出一种基于预定信噪比(signal interference plus noise ratio,SINR)阈值的模式选择方法,通过限制底层D2D用户所产生的干扰,得出满足预定要求的最小和最大功率.文献[13] 提出了一种新颖的带有小区划分的强化学习(reinforcement learning,RL)方法,以解决基站未知的先验流量信息时启用了D2D的蜂窝网络的信道和功率分配问题.文献[14] 提出了在室内D2D通信网络中基于增强学习的延迟控制D2D连接(RL-LCDC)算法及其Q学习方法,以最小的延迟实现强大的5G连接.文献[15] 提出了一种基于长期演进高级(LTE-A)网络D2D通信的动态资源分配算法,其中强化学习用于信道分配.文献[16]基于图着色理论在D2D用户之间创建干扰图,并在保证蜂窝用户需求的同时构造D2D用户的色表有效提高用户公平性和满意度的新方案.
为了保证用户的QoS,文中以SINR为门限值判断D2D用户是否接入蜂窝系统,结合马尔可夫决策进行频谱资源的分配.假设D2D通信复用蜂窝网络的上行链路,并据此推导出系统吞吐量目标函数作为衡量标准,并进行仿真验证.
1 系统模型
文中研究场景是在单个传统蜂窝小区中加入D2D通信模式,从而达到增强系统吞吐量和提高频谱利用率的功能.在复用网络频谱资源的选择上,选择复用利用率较低的上行链路,并利用基站具有较强的抗干扰能力.假设D2D用户对不互相交换信息与协作,并且预先没有无线信道的相关信息.
1.1 场景描述
假设在单个小区中,可利用的频谱是有限的且被分成K等分,可表示为:RB={rb1,rb2,rb3,…,rbk}.每个蜂窝用户只能占用至多一个资源块,频谱资源相互正交,蜂窝用户之间没有干扰.在网络拓扑中,基站位于小区的中心,N个蜂窝用户和M对D2D对用户均匀分布在小区内.为了保证蜂窝用户的QoS,文中假设系统的资源块数量和蜂窝用户的数量相等,即N=K.为了可以高效地利用频谱资源,假设一个频谱资源块能够同时被多个D2D对复用.对于第∀m∈M个D2D对,构建一个在时刻t的二进制K维向量βm(t)表示复用选择结果,βm(t)={β1(t),β2(t),β3(t),…,βk(t)}.因此,对由于单个D2D对有且仅能复用一个频谱资源块,可得:

(1)

∀m,j∈M,∀k∈K

类似地,可以得到在时刻t时复用频谱资源块k的第n个蜂窝用户的信噪比为:
(2)
∀m∈M,∀n∈N,∀k∈K

场景模型如图1.

图1 系统模型Fig.1 System model
1.2 目标问题
当D2D用户对复用蜂窝用户的频谱资源时,蜂窝用户和D2D用户间会产生相互的干扰,从而大大影响小区内移动用户的通信质量.所以在小区内引入D2D通信时,首先要确保蜂窝用户和D2D对用户的通信质量,在此前提下研究如何提高系统的性能.文中以小区内用户的QoS为约束条件,以最大化系统吞吐量为目标.结合香农定理,给出目标函数为:
(3)
式中:B为小区内可分配的带宽;τC,τD分别为蜂窝用户和D2D用户的最小信噪比;T为系统的吞吐量.
2 马尔可夫决策求解信道分配问题
文中的D2D用户与蜂窝用户所共享的频谱资源为非正交频谱资源,因此将系统建模为马尔可夫决策过程,算法使用强化学习中的Q-Learning算法,将目标函数T作为代价函数,并结合博弈论的方法,求解该最优化问题.
2.1 马尔可夫决策过程
通常来说,一个典型的马尔可夫决策过程可以由一个四元组构成:<状态(State),动作(Action),转移概率(Transition Probability),即时奖励(Immediate Reward)>[7].智能体Agent从环境中获得周边需要用到的状态si,随时根据周边环境对状态si进行更迭,并根据得到的状态si制定当前的学习策略,根据策略选择最优的动作ai执行,此后,Agent的状态从si转变为si+1,同时返回即时奖励ri.以此类推,不断在学习过程中获得最优的动作,从而得到奖励函数的最优化.图2 为马尔可夫决策过程.
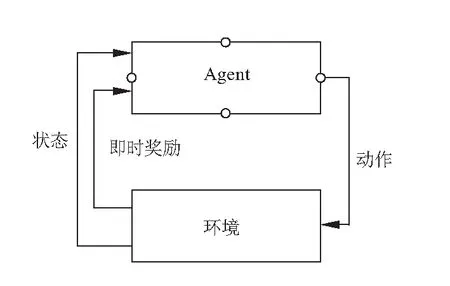
图2 马尔可夫决策过程Fig.2 Markov decision process
2.2 问题映射
采用Q-Learning算法不断优化学习过程中的行为序列优化马尔可夫环境下的动作.Q-Learning中的Q值,定义为状态动作函数Q=(s,a),表示对奖励的预测和估计.因此,在Q-Learning中的最优策略为针对当前状态si时,选择动作ai使得Q值最大.
将每个D2D对定义为一个智能体.动作、状态、奖励函数以及策略对应如下:
(1)动作(Action)
智能体所执行的动作为选择进行复用的频谱资源,在同一时刻一个智能体至多只能复用一个资源块进行复用,由二进制的K维向量βm(t)构成,因此在时刻t智能体m的动作可以表示为:
am(t)={βm(t)∈{0,1},∑βm(t)≤1}
(4)
系统中除智能体m外的所有其他动作所构成的动作集合为A-m.
(2)状态(State)
智能体可观测到的状态信息为某时刻系统中蜂窝用户与D2D用户是否达到通信标准,在时刻t智能体的状态sm(t)为:
sm(t)={d1,k(t),d2,k(t),…,dm,k(t)}
(5)
∀m∈M,∀k∈K
式中:dm,k(t)为在时刻t智能体观察到的占用频谱资源块k的D2D的信道信息,如式(6):
(6)
(3)即时奖励(Reward)
学习的结果由奖励来体现,在文本中,学习的结果是为了最大化系统的吞吐量,所以智能体的奖励信号为系统的总吞吐量rm(t)为:
rm(t)=T=

∀n∈N,∀m∈M,∀k∈K
(7)
(4)策略(Policy)
策略是智能体根据当前状态确定下一个动作的策略,使用Bellman方程作为策略方程:
v(s)=E[rt+γv(St+1|St=s)]
(8)
式中:E为期望,γ为折扣因子,St为t时刻的状态.系统模型中,结合Q值进行重写方程,得到:
Qπ(s,a)=E[rt+γQπ(st+1,at+1|st,at)]
(9)
其中最优的Q可用Q*表示为:
Q*(s,a)=E[rt+γmaxat+1Qπ(st+1,at+1|st,at)]
(10)
因此,提出基于Q-Learning的资源分配算法.

算法1.基于Q-Learning的资源分配算法初始化 对于任意s∈S,a∈A(s)动作状态值q(s,a)←任意值初始化 学习率α和折扣因子γforepisode=1toMdo初始化 网络场景和初始化状态s1(系统中蜂窝用户与D2D用户是否达到通信标准)根据动作状态值q(s,a),在状态s1下选择动作a(复用向量βm(t))执行动作a,获得即时奖励r和下一时间的状态s′根据状态s′选择动作a′qk+1(sk,ak)←qk(sk,ak)+αrk(sk,ak)+γmaxqk(sk,ak+1)-qk(sk,ak)[],更新动作状态值s←s′,记录状态endfor输出动作状态值q(s,a)
3 仿真与结果分析
仿真环境设置为一个半径为500 m的圆形区域.每个D2D对之间的距离为30 m.在基站的覆盖范围内均匀分布着10个D2D对和20个蜂窝用户.为了保证用户的QoS,蜂窝用户的SINR下限值设为0.5dB,D2D用户的SINR下限值设为3dB,初始学习率为0.4,折扣因子为0.8其他参数如表1.

表1 仿真参数设置Table 1 Simulation parameters setting
从多个维度进行分析,将所提出的算法与随机算法和遗传算法(genetic algorithm,GA)进行对比.首先,研究算法中关键参数学习率对小区吞吐量的影响,从图3中可以看出,当设置学习率α分别为0.4和0.7时,吞吐量的收敛速度不同,但最终都收敛于相同的吞吐量.这是因为在强化学习中学习率越高,收敛速度也越快,迭代次数也会相对较少;学习率降低,收敛速度也会降低,迭代次数则会增多.收敛于同一个Q值,是因为仿真设置中,资源的数量只有20个频谱资源包,在所有的D2D资源全部接入到小区网络后,系统的吞吐量达到峰值,即得到最优的Q值表,频谱的利用率达到最大化.

图3 不同学习率对小区吞吐量的影响Fig.3 Influence on throughput under different learning rate
图4给出了小区接入D2D数量与小区吞吐量的关系,并将不同的分配算法进行了对比.从图4中可以明显地发现:采用随机接入算法时,D2D对的数量对于提升系统吞吐量的影响很小,原因在于在此算法中,基站随机选择是否允许D2D对接入,SINR作为判断D2D对用户是否复频谱资源用的影响很小;而D2D对以文中所提出的算法和GA算法接入蜂窝小区.GA算法中交叉概率为0.8,突变概率为0.1;随机算法采用正太分布的概率接入,满足SINR则保留,不满足则继续寻优.则算法则依靠SINR门限值来筛选D2D对是否复用小区频谱资源,对小区吞吐量有显著地提高.
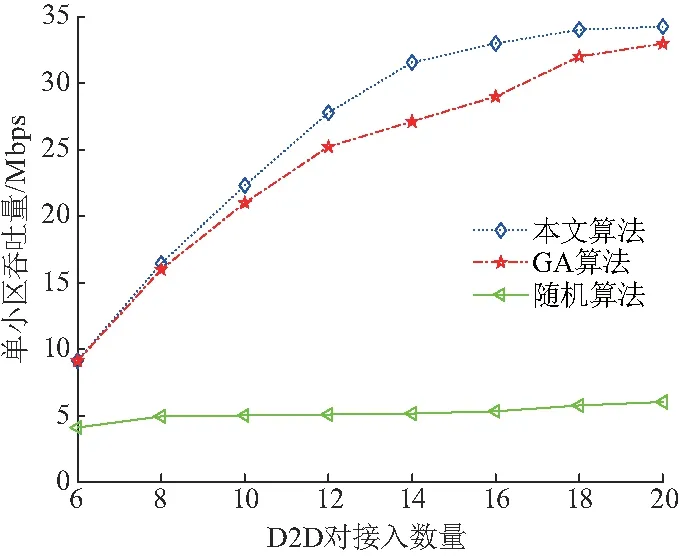
图4 D2D对接入数量与小区吞吐量的关系Fig.4 Relationship between the number of D2D pairs and system throughpu
4 结论
针对单一小区通信场景模型中引入D2D通信模式是否能够提高系统吞吐量进行了研究.得出以下结论:
(1)与GA算法和随机算法对比情况下,文中提出的基于Q_Learing算法有更大的吞吐量.
(2)在α=0.7时,吞吐量的收敛速度加快,更快的收敛到最大吞吐量处.
