基于预训练模型和特征融合的事件触发词抽取
2021-08-10耿小航俞海亮
张 震,谷 雨,耿小航,俞海亮
(杭州电子科技大学自动化学院,浙江 杭州 310018)
0 引 言
事件抽取是信息抽取领域的一个重要研究方向。事件抽取就是从自由文本中检测出事件的发生并提取出事件的要素,对人们认知世界有着深远的意义,是信息检索、知识图谱构建等实际应用的基础,广泛应用于检索、问答、推荐等应用系统[1]。一般将事件抽取分为2个子任务,即事件触发词抽取和事件元素抽取。事件触发词抽取是指检测事件句中的触发词位置并识别出其所属事件的类型,事件元素抽取则是识别出事件句中的事件组成元素及其所对应的元素角色类型。触发词是事件句中的核心词,是事件类型的决定性因素,事件触发词的抽取在事件抽取任务中起着关键作用。
目前,关于事件抽取的研究主要集中在机器学习领域,大致分为基于特征工程的方法和基于深度神经网络的方法。传统的事件抽取主要采用人工构建特征的方式。Ahn[2]利用词性、实体类别等特定特征进行事件抽取。Li等[3]不满足局部特征的构建,通过构建全局特征,建立事件抽取模型。McClosky等[4]借助词性标注、句法依存分析等自然语言处理工具来获取特征。文献[5-6]使用跨实体推理和跨篇章推理的方法进行触发词的抽取。随着深度学习的快速发展,基于海量公开文本数据的神经网络特征提取方法避免了人工构造特征的主观性,逐步应用于事件抽取领域。文献[7-8]将卷积神经网络模型(Convolutional Neural Networks, CNN)应用于事件抽取领域,文献[9]在CNN模型基础上,使用跳窗卷积神经网络(Skip-window Convolutional Neural Networks, S-CNNs)来构造事件的全局特征。此外,递归神经网络模型(Recurrent Neural Network, RNN)也逐渐应用到事件抽取领域[10],文献[11]采用RNN模型的变体长短式记忆模型(Long Short-Term Memory, LSTM)学习事件的特征,文献[12]结合CNN和双向LSTM模型挖掘词语间隐藏关系信息,提高了事件抽取效率。文献[13]在双向RNN基础上,引入动态注意力机制,捕捉更丰富的上下文信息。
事件触发词抽取任务主要存在两个问题,一是触发词一词多义,二是同一个句子中可能存在多个事件,特征提取的不充分导致抽取事件的缺失。为了解决上述问题,本文提出一种基于预训练模型和多特征融合的事件触发词抽取方法。首先,采用预训练语言模型双向Transformers偏码表示(Bidirectional Encoder Representation from Transformers, BERT)进行文本向量化;然后融合CNN提取的词汇特征和图卷积网络(Graph Convolutional Network, GCN)提取的句子特征,进行触发词标签预测,并在ACE2005数据集上进行测试,性能指标得到了提升。
1 基于预训练模型和特征融合的触发词抽取模型
与文本分类任务不同,本文将事件触发词抽取当成序列标注任务处理。序列标注的流程处理中,输入的是包含事件的句子,经过模型处理,输出的是句子序列标签。事件触发词抽取的标签示例如图1所示。

图1 触发词抽取标签示例
图1中,每一个词都有对应的标签作为预测结果。因为存在跨单词的触发词,本文采用“BIO”标注模式。其中,“O”代表非触发词,“B-Attack”代表类型为“Attack”的触发词开始位置,“I-Attack”代表类型为“Attack”的触发词的其他位置。
本文提出的事件触发词抽取模型的算法主要包括文本向量化、多特征提取及融合、输出层等3个部分,整体结构如图2所示。
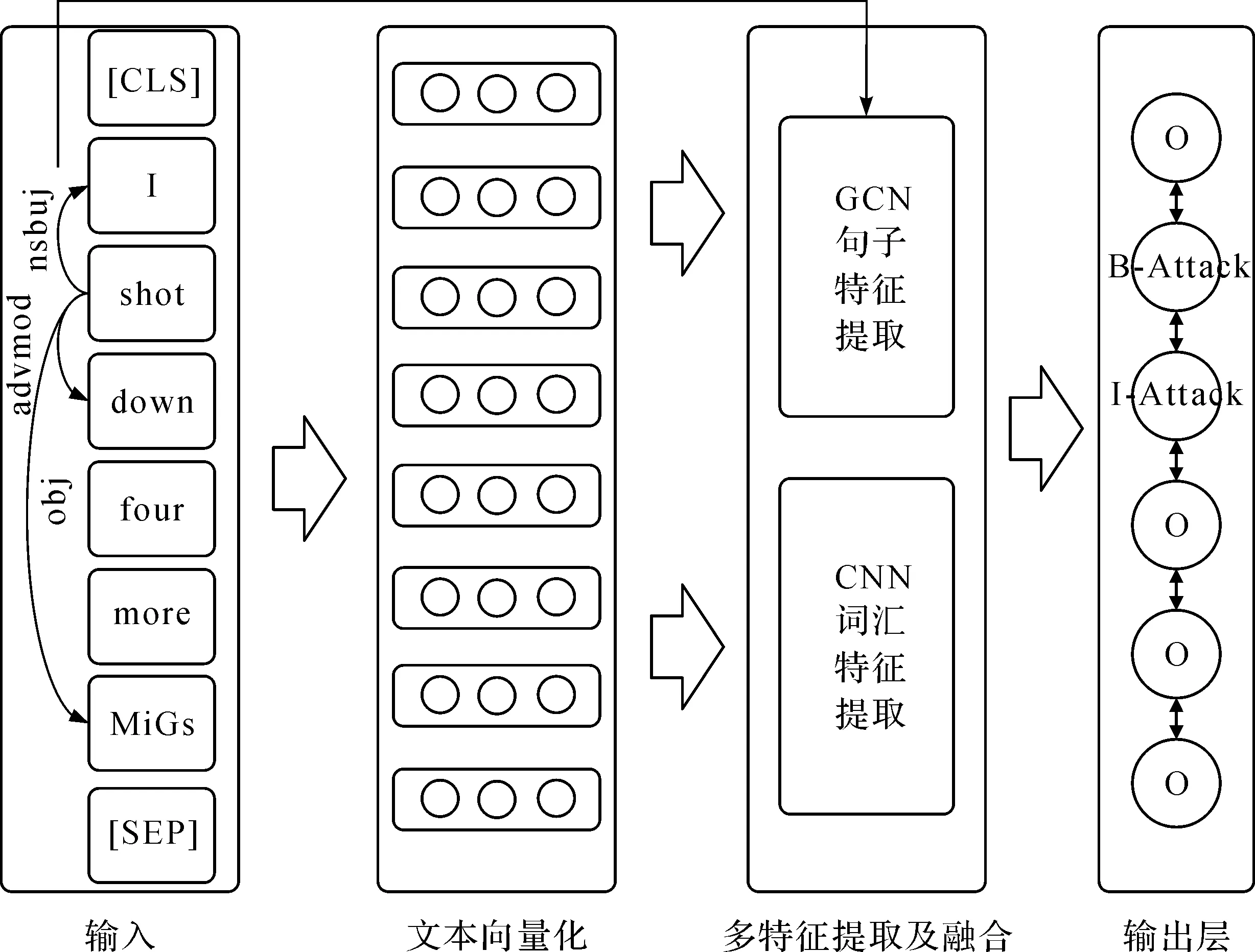
图2 触发词抽取模型整体结构图
目前文本向量化的主要方法包括One-hot编码、词袋模型(Bag-of-words Model, BOW)、N-gram模型、word2vec模型[14]以及GloVe模型[15]等。但这些方法编码得到的词向量均为静态词向量,即单词的词向量是固定不变的,无法解决触发词抽取任务中一词多义的问题。本文采用BERT预训练模型进行词向量编码,使用BERT模型的多层双向Transformer编码器,通过对单词上下文信息进行编码,得到动态变化的词向量,有效解决触发词抽取任务中一词多义的问题。
特征提取部分由两部分组成:(1)基于卷积网络的词汇级别特征提取;(2)基于图卷积网络的句子级别特征提取。通过卷积神经网络捕获词汇级别特征,利用卷积核在单词及其周围单词上下滑动来获取单词及其上下文特征。应用句法分析挖掘事件句中的隐藏信息,采用图卷积网络来编码句法依存关系从而增强事件的信息表示,以达到提高触发词抽取效果的目的。
CNN网络提取的词汇级别特征,仅能表示当前单词及其顺序结构上前后单词的信息;GCN网络通过对事件句的句法依存关系进行编码来表示当前单词以及和当前单词有依存关系的单词信息。将词汇级别特征和句子级别特征进行融合拼接,既能表示当前词汇的上下文信息,又能表示其关联信息,有效弥补了触发词抽取任务中特征提取不充分的问题。
输出层的作用是利用融合拼接后的特征进行触发词标签预测,实现触发词的抽取。与传统的分类方法不同,序列标注问题中,预测的标签序列之间具有强互相依赖关系。例如,预测触发词标签不允许在“B”标签和“I”标签之间出现“O”标签。本文应用条件随机场(Conditional Random Field, CRF)模型对序列标签进行约束,防止不合理标签的出现。
2 触发词抽取任务的实现
2.1 BERT词向量表示
BERT预训练模型是一种新型语言表示模型,可以获取单词的动态向量表示[16]。模型在双向Transformers编码器基础上,增加了掩码语言模型(Masked Language Model, MLM)和下一句预测任务(Next Sentence Prediction, NSP)。MLM通过随机遮盖语料中15%的信息,使模型最大程度获取深度的表征能力。具体做法是80%的遮盖词汇用[MASK]替代,10%随机替换为其他词,剩余10%保持不变。NSP任务利用语料中的句子对A和B训练一个二分类模型来表征句子关系特征。具体做法是将50%句子对中的B随机替换成其他句子,并标记为NotNext,剩余50%句子对的B保持不变,并标记为IsNext。
BERT的模型结构主要分为输入层、编码层和输出层。BERT的输入表示是词向量、分段向量和位置向量的和。词向量采用单词的WordPiece向量编码[17]。分段向量表示单词所在句子的位置编码。位置向量表示单词在句子中的位置编码。同时输入表示使用[CLS]和[SEP]作为开头和结尾的标志。
BERT编码层采用多层双向Transformer编码器,编码单元如图3所示。编码单元由多头注意力机制层和全连接前馈神经网络层组成。

图3 Transformer编码单元
为提取深层语义特征,增大模型空间表达能力,本文采用多头注意力机制层[18]进行编码:
式中,Q,K,V均为词向量矩阵,hi为单头注意力机制层,Wo为权重矩阵,WQ,WK,WV为投影矩阵。另外,模型中的注意力机制均采用缩放点积的方式:
(2)
式中,dk为向量维度。通过自注意力机制编码,对句中的词向量进行加权组合,可以获取句子中词与词的相互联系,从而捕获句子的结构特征。然后再对上一步的输出做残差连接和归一化操作。最后将处理后的信息输入到全连接前馈神经网络层,重复进行一次残差连接和归一化后输出结果。
对于给定的句子,通过BERT预训练模型得到句中每个单词的向量表示xi∈Rd,其中d表示词向量的维度。长度为n的句子表示为X∈Rn×d:
X=[x1,x2,…,xn]
(3)
2.2 基于卷积网络的词汇级别特征提取
词汇级别特征包括单词特征及其上下文特征。为了提取词汇级别特征信息,采用卷积神经网络进行处理。先将不同大小卷积核在句子序列上滑动以获取单词及其上下文特征,再将这些特征进行全局处理,以特征图的形式表现出来。
应用卷积核w∈Rh×d(窗口大小为h)在文本序列上滑动生成新的特征图:
ci=f(w·xi-h/2:i+h/2+b)
(4)
式中,xi-h/2:i+h/2表示词向量xi-h/2,xi-h/2+1,…,xi,…,xi+h/2-1,xi+h/2的组合,w∈Rh×d表示单个维度为h×d的卷积核,f为激活函数,b为常数项。对整个句子的所有单词进行卷积操作,得到整个句子序列的卷积图:
g=[c1,c2,…,cn]
(5)
假设使用m1个大小不同卷积核,得到特征图为:
C=[g1,g2,…,gm1]
(6)
式中,C∈Rn×m1表示句子中的n个单词经过卷积操作提取出的单词及其上下文特征。
传统的卷积神经网络一般通过对特征图进行池化层操作以获取显著特征,但池化层的操作会丢失事件句的序列信息。为了保留事件句的原始序列信息,本文不添加池化层操作。
2.3 基于图卷积网络的句子级别特征提取
图卷积神经网络是由Thomas等[19]提出并应用于图数据,为图结构数据处理提供了崭新思路,可以用于编码图数据信息。为了充分挖掘句子的隐藏信息,本文使用图卷积网络来提取句法依存关系特征,为事件触发词识别提供帮助。图卷积网络不仅能表示当前节点信息,而且能聚集更多邻居节点的特征信息,通过句法依存关系捕获到单词的句法上下文信息。
根据每一个事件句的句法依存关系,构成简单的图结构。使用自然语言处理工具Stanford CoreNLP生成的句法依存关系示例如图4所示。图4中,构造了一个以单词作为节点,单词之间的依存关系为边的有向图。

图4 利用Stanford CoreNLP生成的依存关系图
对于具有n个节点的图,用邻接矩阵A∈Rn×n表示图结构。当节点i和节点j存在边,则Aij=1。考虑到节点自身的影响,给邻接矩阵A添加自环操作,令Aij=1。最后,对邻接矩阵进行归一化处理:
(7)
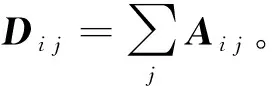
(8)
式中,H(l+1)为图卷积网络第l层的输出向量,Relu为激活函数,W(l)为权重矩阵,b(l)为偏置项。图结构中的每个节点通过卷积操作汇聚邻接节点的特征,并将其传入下一层的网络作为输入。使用文本向量化得到的词向量X∈Rn×d初始化第一层图卷积网络的输入H(0)。经过l层的卷积神经网络模型,得到句子级别的特征H(l+1)∈Rn×m2,其中m2表示句子级别特征向量的维度。
2.4 输出层
将卷积网络提取的单词级别特征C∈Rn×m1和图卷积网络提取的句子级别特征H(l+1)∈Rn×m2进行拼接,得到融合后的事件特征:
F=C⊕H(l+1)
(9)
式中,F∈Rn×(m1+m2)表示事件特征,特征维度为m1+m2,⊕为向量拼接运算。将融合后的事件特征F放入分类器进行触发词标签预测。在此过程中,需要考虑标签之间的依赖关系,避免出现标签不合理的情况,加入CRF对标签序列进行建模。
对于给定的句子序列x=(x1,x2,…,xn)和对应的标签序列y=(y1,y2,…,yn),CRF模型的计算如下:
(10)
式中,T为转移矩阵,Ti,j表示由标签i转移到j的概率。Pi,yi表示该词第yi个标签的分数。在给定原始句子序列x的条件下产生标签序列y的概率为:
(11)
式中,y′表示真实的标签值。在训练过程中,标签序列的对数似然函数为:
(12)
式中,YX表示所有可能的标签集合。预测时,由以下公式得到整体概率最大的一组序列。
(13)
3 实验结果及分析
3.1 数据集和评价指标
本文研究的是基于ACE评测语料的事件触发词抽取,采用英文ACE2005语料进行验证实验。ACE评测语料中定义了8种事件类型,33种子类型。为了对比实验的合理性,数据集的划分参照文献[2]的方法,选取529篇文档作为训练集,30篇作为验证集,剩下的40篇作为测试集。
触发词抽取实验同样采用和文献[2]相同的评价指标和性能指标。评价指标为:触发词抽取位置正确,则表示触发词识别正确;触发词抽取位置和类型都正确,则表示触发词的类型分类正确。实验性能指标为:准确率P(Precision)、召回率R(Recall)以及F1值(F1 scores)。
3.2 实验参数
实验选用的BERT模型是Google公司提供的BERT-Large。BERT-Large模型层数L=24,隐藏层维度H=1 024,采用多头自注意力机制头数A=16,总参数量个数约为3.4×108。卷积网络卷积核数目为30,图卷积层层数为2。损失函数使用交叉熵损失函数,优化器选用Adam算法[20],学习率为1E-5。最长序列长度为60,批处理大小为12,epoch为20。
3.3 实验结果及分析
本文提出基于预训练模型和多特征融合的事件触发词抽取模型,简称为BCGC模型。为了验证BCGC模型各模块在触发词抽取中的作用,在相同实验环境下,进行了对比实验,实验结果如表1所示。

表1 不同模型的实验结果 %
从表1可以看出,第4组实验融合CNN提取的词汇特征和GCN提取的句子特征进行触发词抽取,触发词分类阶段效果要优于第2组单独使用CNN提取特征和第3组单独使用GCN提取特征的实验结果。因为CNN能够编码单词顺序结构上下文信息,GCN网络可以编码单词非顺序结构上的关联信息,融合两种模型提取的特征能更充分地表示事件信息,提升触发词抽取任务的性能。
第4组实验与第1组实验对比,仅将实验1中使用的传统的300维word2vec词向量替换成BERT表示的词向量,触发词分类任务F1值提高了将近4个百分比。而且,所有使用BERT预训练模型词向量表示的模型,实验效果都要优于利用传统词向量表示的模型。结果表明,拥有双向Transformer编码的BERT模型具有很强的表征能力,在触发词抽取任务上表现更出色。
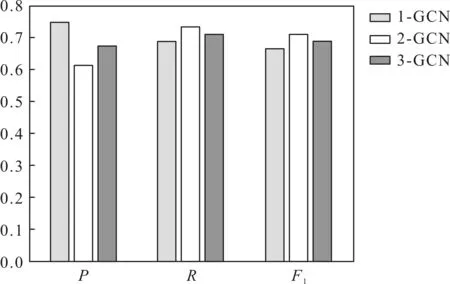
图5 不同层数的GCN网络的实验对比图
本文分别选取不同层数的GCN网络进行对比试验,触发词分类阶段的实验结果如图5所示。
由图5可知,在GCN层数为2时,触发词分类效果最好,F1值最高。当GCN层数为1时,准确率最高,但召回率和F1值不高。随着GCN层数的增加,P值下降,但R值和F1值回升,说明GCN网络提取依存关系特征是有效的,但随着GCN层数的增加,聚合节点特征过多可能会对触发词的抽取造成干扰。
为进一步验证本文提出方法的有效性,将基于BCGC模型的触发词抽取方法和其他方法进行对比实验。对比方法分为3组,分别为:
(1)传统组主要通过人工选择合适特征进行触发词抽取,例如文献[2]的MaxEnt方法和文献[3]的J-global方法。
(2)CNN组主要通过CNN网络提取事件特征。例如文献[8]的DMCNN方法利用候选触发词位置将事件句切分成两部分,并分别对每个部分进行动态多池化的卷积操作,从而实现对事件特征的提取;文献[9]的S-CNNs方法提出跳窗卷积神经网络提取事件全局特征,实现对事件的联合抽取。
(3)RNN组主要通过RNN网络提取事件特征。例如文献[10]的JRNN方法提出基于双向RNN网络的联合事件抽取,例如文献[12]的Conv-BiLSTM方法结合卷积神经网络和长短记忆网络进行触发词抽取。
BCGC事件触发词抽取方法与这些方法的对比结果如表2所示。
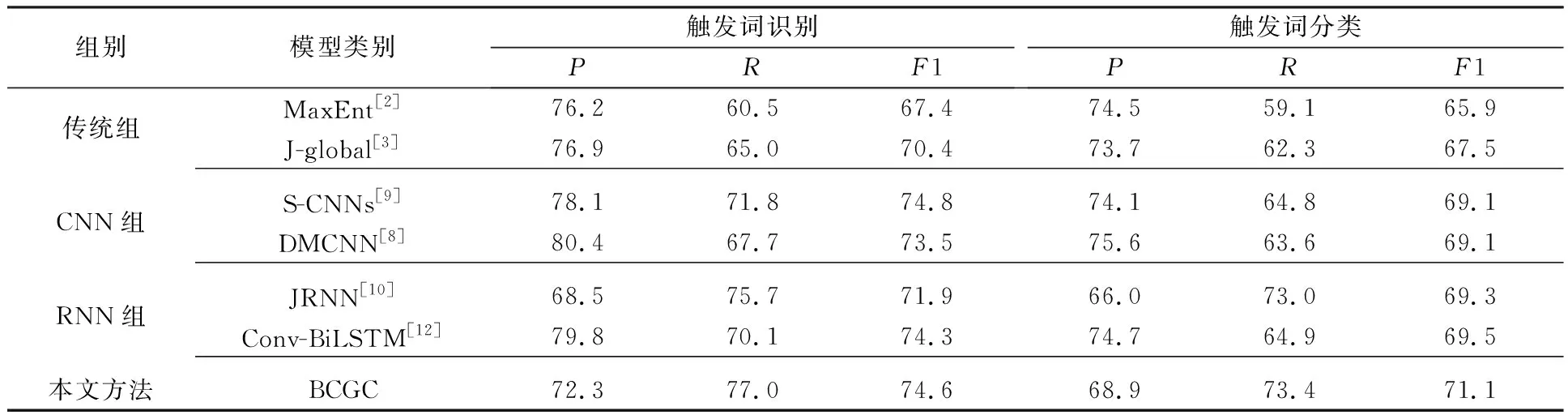
表2 不同方法对比实验结果 %
由表2可以看出,本文提出的BCGC方法比其他方法更出色,触发词分类阶段F1值最少提升了1.6%,召回率也相对较高,触发词识别阶段实验结果也较理想,说明本文提出的CNN提取词汇级别特征和GCN提取句子级别特征的融合能充分表示事件特征,促进事件触发词抽取任务性能的提升。对比CNN组和RNN组,BCGC方法在触发词分类上效果突出,但在触发词识别上优势并不明显,对比S-CNNs方法的F1值略有下降。S-CNNs方法进行事件的联合抽取,同时抽取事件触发词和事件元素,在触发词抽取阶段也利用上事件元素的特征信息,促进了触发词抽取性能的提升。对比传统组,其他3组基于深度学习的抽取方法在事件抽取各阶段实验效果更好,说明深度学习网络在特征提取方面比传统方法更具优势。
4 结束语
本文提出了一种基于预训练模型和多特征融合事件触发词抽取方法,使用BERT预训练模型表示词向量,通过融合CNN网络提取的词汇特征和GCN网络提取的句法特征,提高了触发词抽取的效果。本文方法的局限性在于没有充分利用事件元素的信息,没有探索后续任务中事件元素对触发词抽取任务的影响。下一步将考虑如何构建模型以实现多任务联合,进一步提高事件触发词抽取的实验性能。
