基于NAO机器人的BLSTM-CTC的声学模型研究
2021-08-09胡希颖王大东陈佳欣
胡希颖 王大东 陈佳欣

摘 要: 针对于NAO机器人自身语音识别准确率低的问题,提出一种基于NAO机器人的BLSTM-CTC的声学模型研究方法。基于BLSTM-CTC的声学模型进行建模,以BLSTM为声学模型和CTC为目标函数,以音素作为基本建模单元,建立中文语音识别端到端系统。实验结果证明,本文算法相较于NAO机器人自身,取得了良好识别效果。
关键词: 语音识别; BLSTM-CTC; NAO
文章编号: 2095-2163(2021)03-0076-05 中图分类号: N33 文献标志码:A
【Abstract】Aiming at the problem of low accuracy of NAO robot's own speech recognition, an acoustic model research method based on NAO robot BLSTM-CTC is proposed.Based on the acoustic model of BLSTM-CTC, an end-to-end system for Chinese speech recognition is established by taking BLSTM as the acoustic model and CTC as the objective function, and taking phonemes as the basic modeling unit.Experimental results show that compared with NAO robot itself, the proposed algorithm achieves good recognition performance.
【Key words】 speech recognition; BLSTM-CTC; NAO
0 引 言
语音识别是语音信号处理领域的一项重要研究内容,其中的基于深度学习的识别方法则在近年来引起了学界的广泛关注[1]。基于深度学习的识别方法是利用神经网络来构建模型、训练数据,并已取得了较好的识别效果,现正广泛应用于智能家居以及相关的学术研究等领域。作为备受学界瞩目的智能机器人,NAO本身自带语音识别模块,但却因受到自身处理速度和存储能力的限制,识别效果一般。考虑到NAO机器人自身的软硬件资源较为有限,只依靠NAO自身来提高语音识别准确率的难度较大。基于此,本文即提出以了BLSTM[2]为声学模型和CTC为目标函数,利用WFST进行解码,对模型结构进行训练和学习,并将其移植到NAO机器人上,从而获得更好的识别结果,提升机器人的学习能力。
1 模型结构
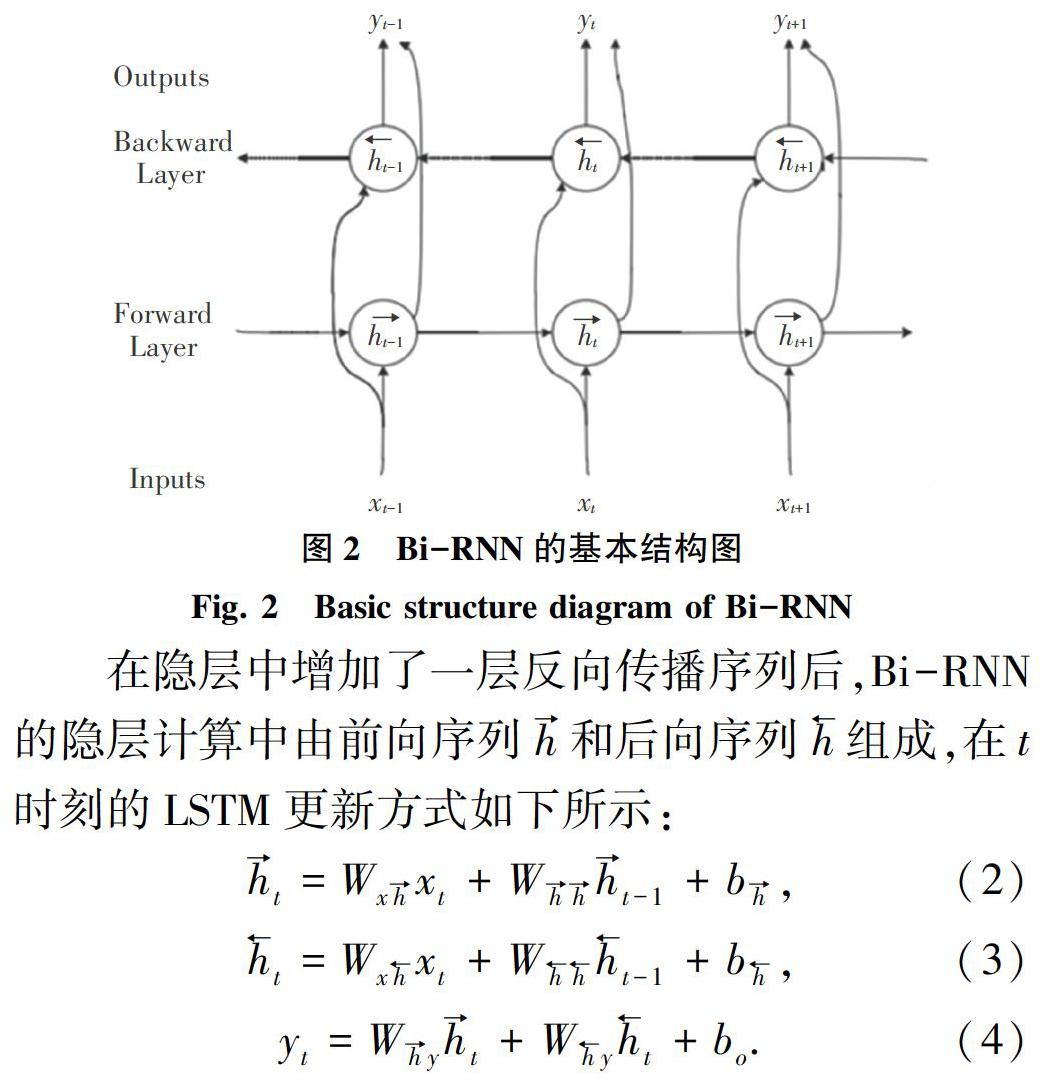
LSTM(Long Short-Term Memory)最早由Hochreiter & Schmidhuber在1977年提出[3],后经Alex Graves完善并获得广泛应用[4]。LSTM主要由2部分组成。一个是传统的外部RNN循环;一个是内部精致的“门”结构,包括sigmoid神经网络层和按位乘法操作。LSTM的“门”分别是输入门、输出门、遗忘门,3个门控单元控制和保护cell的信息到细胞状态[5]。LSTM基本结构如图1所示。
图1中,遗忘门f决定从细胞状态cell中遗弃哪些数据信息。其对应数学公式可写为:
细胞状态cell确定可存放信息数据,输入门it,确定信息的更新与否,并在tan h层创建新的候选向量t,如此则用新的主语来更新代替旧的细胞状态。
2 基于连接时序分类的语音识别系统
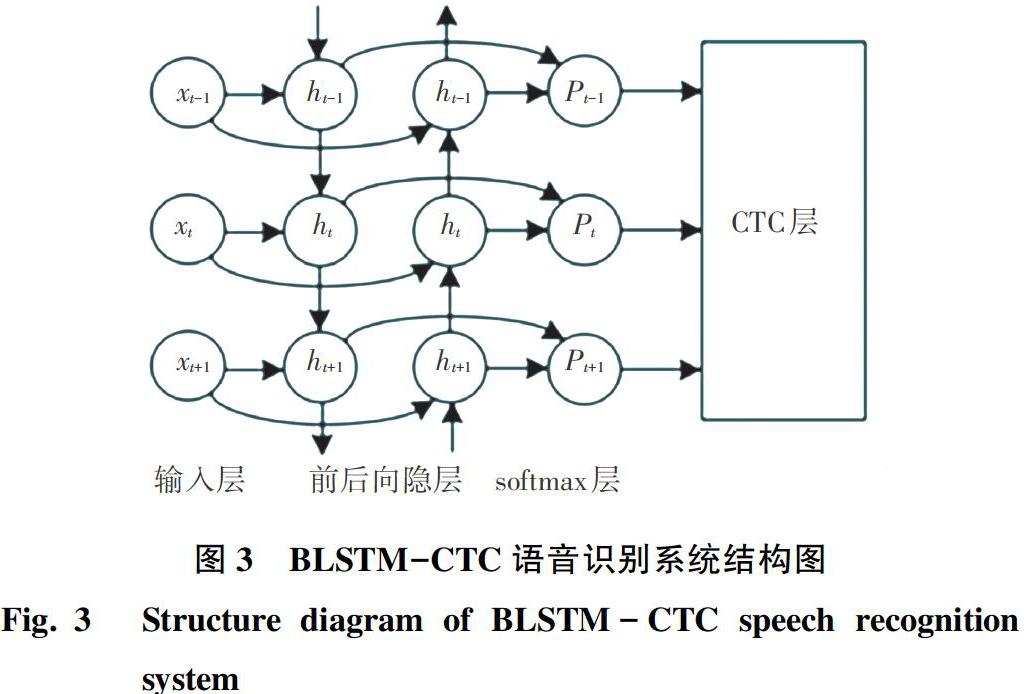
采用传统神经网络训练声学模型方法时,先是根据声学模型的基本单元进行建模,在训练时还需使用GMM与标签进行对齐,并将目标函数作为训练标准。本文用BLSTM-CTC系统在训练声学模型时采用端到端的训练方式,不同于传统的混合方法基于eesen框架的RNN使用基于交叉熵(CE)准则训练帧级标签,而是采用CTC函数学习帧与序列的对齐,并使用WFST进行解码[6],BLSTM-CTC系统结构如图3所示。
2.1 连接时序分类CTC技术
CTC(Connectionist Temporal Classification)技术作为目标函数无需强制预先对齐输入与输出帧级别信息,可直接对标签和语音特征之间的映射进行建模。RNN中softmax层的输出序列、即CTC层的输入,softmax层中的k个节点与CTC中训练数据的标签序列一一对应;对未输出的标签也需建模,在此基础上,增加一个单元(blank)。假定长度是T的输入序列x,输出向量yt,在t时刻softmax分类层输出音素或空白的概率k表示为:
CTC经过学习后得到由音素和blank组成的标注序列a的输出路径概率为:
由于标注的重复性和blank插入的影响,音频序列与转录后去掉空白标签的路径具有多重对应关系,因此,输入序列x对应的输出标签概率为:
其中,a→y的映射获取β,β的逆过程表示为β-1,映射过程把空白类去除的同時将重复序列合并得到y目标函数,即:
通过已知的输入序列找到最大概率的输出路径、即CTC网络解码的最佳路径为:
CTC路径求和随着输入序列的增加,计算复杂度越来越增大,为解决这一实际问题,在输出序列z的首尾及每对输出标签序列之间插入索引是“0”的blank标签,从而将得到的增广式扩充标签序列l=(l1,…,l2U+1)用于语音识别中前后向算法(Forward-backward Algorithm)计算路径似然估计[7]。
标签序列z的似然估计概率计算如下:
其中,t为1到T时刻中的任意一帧。CTC目标函数lnPr(z|X)对RNN网络输出yt求微分,则lnPr(z|X)相对于ykt的一阶导为:
由式(11)可见,目标函数可进行微分,所以bt、bi、bo、bf在求导过程中误差影响可以忽略,RNN在接收softmax层反向传播过程中即可更新参数。
2.2 WFST解碼
一般情况下,应用于CTC训练输出模型的解码方法均有些不足。一是不能把单词级语言模型进行有效的整合[8];二是只能在特定约束条件下进行集合[9],因此需要高效解码。本文基于发声特点将语言模型、词典和CTC输出用WFST进行编译,建立一个基于WFST的搜索图实现高效完整性的解码操作。WFST实质上是一个FSA(Finite-state Acceptor),相应的每个转换都包含输入符号、输出符号和权重[10]。
WFST解码由3个部分组成,分别是:标记(Token)、语法(Grammar)和词典(Lexicon)。对此拟做阐释分述如下。
(1)语法G:基于语言模型n-gram编码了符合语法的单词序列。初始节点用节点O表示,每个边的权重即当前对应字或词的概率。
(2)标记T:编码了语音CTC标签序列L到词典单元L的一对多的映射关系(l)。在词典单元中,帧级别标签序列进行WFST存在空白标签Φ和重复序列,例如处理五帧后的RNN可能存在的标记序列“AAAAA”、“ΦΦAAΦ”、“ΦAAΦΦ”,token的WFST可把上述三种序列均映射为一个“A”的词典单元。
(3)词典L:WFST将标签序列L的词序列映射到字序列进行编码。空的输入和输出用
3个独立的WFST在编译后,把语法G和词典L进行组合获得LG网络,再通过确定化和最小化算法针对LG网络进行处理,同时减少搜索图的占用和优化WFST网络,最终结合CTC标签生成完整的搜索图,也就是:
在搜索图S中。T、min、det分别表示组合、最小化和确定化操作[11]。S通过编码将获取的CTC标签映射到字序列,此方法较HMM模型CTC解码速度和性能均大幅度提高。
3 实验结果与分析
3.1 实验数据集
本节的基于NAO机器人的BLSTM-CTC声学模型研究是基于清华大学开源的THCHS-30中文数据集。该数据集是由50人录制的、共计时长为35 h的声音数据,数据中的采样率和量化位数分别为16 kHz和16 bit。其中,训练集占74.7%,共10 000句;开发集占6.7%,共893句;测试集则占18.6%,共2 495句,并且每个集合之间均不存在相同录制人。语言模型为3-gram模型。
3.2 实验设置
本次实验中的硬件配置是Ubuntu Linux操作系统和NAO机器人的麦克风;实验软件配置是搭建TensorFlow1.5框架结构和Python2.7编程语言。实验中搭建的基于BLSTM-CTC端到端语音识别系统,输入特征参数MFCC帧长为256,Mel频率倒谱系数为26,每个时间段有494个MFCC特征数,语音输入的窗函数选用汉明窗。
3.3 实验结果分析
端到端系统建模能力强于基线系统,但不同的网络隐藏层数对系统性能的影响也存在差异性。表1给出了不同的隐藏层数,即2层、3层和4层之间系统的WER值对比。
由表1可知,LSTM网络层数为3层时,相较于2层和4层,系统的WER值分别降低了1.01%和2.28%。当网络层由2层丰富到3层时,结构得到完善,性能获得提升;当网络层由3层增加到4层时,由于训练语料库的短缺,导致网络欠拟合,反而抑制系统准确率的提升。因此,3层的网络系统结构最优。
本实验的网络模型结构是由3层全连接层网络作为输入,每层包含1 024个节点,设置最佳学习率为0.001,共进行120次迭代,每次迭代共循环267次,每次取8。训练中选取句子字数相同、但循环次数不同的3组数据进行对比,分别是69、139和209,每次迭代训练后均对训练损失、错误率和训练时间进行输出。以音素为基本单元进行建模,输出层激活函数是softmax函数,其输出标签数为47,其中包含一个静音标签和blank标签以及45个音素。
文中选取前22次的迭代数据,分析3种不同循环次数进行对比,如图4所示。随着迭代次数的增加,在端到端语音识别系统中循环69次的正确率峰值最大;循环139次相较其他两者识别变化更加稳定;循环209次初始错误率最低。可见循环次数越多,错误率越小。
不同循环次数BLSTM-CTC语音识别损失对比如图5所示。由图5可知,端到端语音识别系统循环次数69次时,初始损失为304.81,较其他两者损失相比过大;当循环次数为209次时,初始损失则为292.24,当迭代数目增加时,损失均呈现逐渐下降趋势,不同次数间的损失数值变化区别不明显,可见循环次数越小损失变化越明显。综上可知,循环次数为209时,损失变动小,鲁棒性更强。
BLSTM-CTC语音识别WER和损失变化则如图6所示。由图6可知,随着迭代次数的变化,训练损失大幅度降低,错误率变化不稳定,但趋势处于降低状态,最终的识别准确率为74.4%。实现NAO机器人语音识别鲁棒性的有效提高。
NAO机器人、端到端系统对比见表2。表2中,针对NAO机器人自身和使用端到端系统二者进行对比,依据词错误率(Word Error Rate,WER)作为评判标准。与最初的NAO识别准确率相比, BLSTM-CTC系统将WER值降低6.57%。研究中发现WER值成功降低,但仍存在一些不足, BLSTM-CTC系统训练后不受外界附加条件影响和制约,但训练时间长。由此可见,两者鲁棒性均获得大幅度提高,但也都存在一定的弊端,因此,两者可相互弥补在不同的硬件配置条件下的不足,通过多种方案均可有效改善NAO机器人WER值。
4 结束语
本文使用基于BLSTM-CTC的声学模型进行建模,建立了中文语音识别端到端系统,应用于NAO机器人。实验结果证明,使用端到端系统比NAO机器人自身的WER有了进一步的改善,为NAO机器人的语音处理领域提供了更多的思路。
参考文献
[1] 戴礼荣,张仕良,黄智颖. 基于深度学习的语音识别技术现状与展望[J]. 数据采集与处理,2017,32(2):221-231.
[2] 姚煜. 基于BLSTM-CTC和WFST的端到端中文语音识别系统[J]. 计算机应用,2018(2):1-4.
[3] HOCHREITER S, SCHMIDHUBER J. Long short-term memory[J]. Neural computation, 1997, 9(8):1735-1780.
[4] SHERSTINSKY A. Fundamentals of Recurrent Neural Network (RNN) and Long Short-Term Memory (LSTM) network[J]. Physica D: Nonlinear Phenomena, 2020,404:132306.
[5] XU Y, MO T, FENG Q. Deep learning of feature representation with multiple instance learning for medical image analysis[C]//Proceedings of IEEE International Conference on Acoustics, Speech and Signal Processing( ICASSP). Washington DC: IEEE, 2014:1626-1630.
[6] FAHED A, GHALIA N. A multiple- hypothesis map-matching method suitable for weighted and box-shaped state estimation for location[J]. IEEE Transactions on Intelligent Transportation Systems, 2011,12(4):1495-1510.
[7] 郑晓琼,汪晓,江海升,等. 基于RNN和WFST译码的自动语音识别研究[J]. 信息技术,2019,43(6):115-120.
[8] PRICE M, GLASS J, CHANDRAKASAN A P. A low-power speech recognizer and voice activity detector using deep neural networks[J]. IEEE Journal of Solid-State Circuits, 2018,53(1):66 -75.
[9] 馮伟,易绵竹,马延周. 基于WFST的俄语字音转换算法研究[J]. 中文信息学报,2018,32(2): 87-93,101.
[10]ARMENI K, WILLEMS R M, FRANK S L. Probabilistic language models in cognitive neuroscience:Promises and pitfalls[J]. Neuroscience & Biobehavioral Reviews, 2017,83:579-588.
[11]JIANG B, CHAN W K. Input-based adaptive randomized test case prioritization: A local beam search approach[J]. Journal of Systems and Software, 2015,105: 91-106.
