基于自适应结构图的半监督语音情感特征选择
2021-08-09罗辉韩纪庆
罗辉 韩纪庆


摘 要: 本文研究了语音情感识别中的半监督特征选择问题,即如何利用未标记语音情感数据来帮助选择具有情感判别性的特征。为了解决这个问题,提出了一种新的基于图的半监督特征选择方法。其可以根据标签适应度和流形平滑度,在图上估计一个预测标签矩阵,从而有效地利用标记数据中的标签信息,以及标记数据和未标记数据中的流形结构信息。与现有的基于图的方法相比,该方法能同时进行特征选择和局部结构学习,从而自适应地确定图相似度矩阵。同时,还对图相似度矩阵进行了约束,使其包含更准确的数据结构信息,从而可以选择更有判别性的特征。此外,提出了一种有效的迭代算法来优化该问题。在典型语音情感数据集上的实验结果表明,本文提出的方法是有效的。
关键词: 语音情感识别; 半监督特征选择; 自适应结构图
文章编号: 2095-2163(2021)03-0001-08 中图分类号:TP391.41 文献标志码:A
【Abstract】This paper considers the problem of semi-supervised feature selection in speech emotion recognition, that is, how to use unlabeled speech emotion data to help select the features with emotion discriminability. To address this problem, the paper proposes a novel graph-based semi-supervised feature selection method. The proposed method can estimate a prediction label matrix on the graph with respect to the label fitness and the manifold smoothness, thus it can effectively utilize label information from labeled data as well as a manifold structure information from both labeled and unlabeled data. In comparison with the existing graph-based algorithms, the proposed approach can perform feature selection and local structure learning simultaneously, so the graph similarity matrix can be determined adaptively. At the same time, the paper constrains the similarity matrix to make it contain more accurate data structure information, therefore the proposed approach can select features that are more discriminative. Moreover, an efficient iterative algorithm is proposed to optimize the problem. Experimental results on typical speech emotion datasets show that the proposed method is effective.
【Key words】 speech emotion recognition; semi-supervised feature selection; adaptive structured graph
0 引 言
隨着电子技术和计算机技术的发展,人们需要具有情感识别能力的新型语音对话系统。然而,要实现这一目标,还需要克服许多困难。首先,在特征提取方面,尚不清楚哪些语音特征能有效区分语音情感[1]。其次,不同的句子、说话者、说话风格和语速等因素都会引起不同的声学变化,给语音情感识别增加了新的挑战[1-2]。
特征选择不仅可以突出情感所带来的可变性,还能减少情感之外其它因素的干扰,并能保留原始特征的可解释性[1]。根据标签信息的可用性,特征选择方法可分为有监督方法、无监督方法和半监督方法。其中,由于半监督特征选择能够通过同时使用标记和未标记数据来最大化数据的有效性,因此,可将其作为有监督方法和非监督方法之间一个很好的折衷方案[3-5]。
在目前的研究工作中,有许多不同的半监督特征选择方法,总地来说大致可分为3种类型,即:滤波式方法、封装式方法和嵌入式方法[6]。其中,由于嵌入式方法在许多方面都具有优势,因此受到了越来越多的关注[5,7-8]。在各种嵌入式特征选择方法中,基于图的半监督特征选择方法因其非参数性、判别性和直推性而受到了广大研究者的青睐[9]。由于局部流形结构在计算效率和表征能力上优于全局结构,因此大多数嵌入式方法都试图发掘数据内部的局部结构,并用其进行特征选择[10]。经典的基于图的半监督特征选择方法主要包含2个独立的步骤。首先,通过挖掘局部内部结构信息,来构造相似图矩阵。然后,利用稀疏约束来选择有价值的特征[11-12]。尽管如此,这些方法依然存在一些缺点。一方面,传统的基于图的特征选择方法将构造相似图矩阵和选择特征分成2个独立的步骤,其在原始数据中构造的相似图矩阵并不会随着后续的处理而改变。然而,实际数据中往往包含大量的噪声样本和特征,使得所构造的相似图矩阵不可靠[13],从而破坏数据的局部流形结构,最终导致特征选择的性能下降。另一方面,传统方法得到的相似图矩阵通常不能反映理想的邻域结构。根据局部连通性可知,最优相似图矩阵中的连通分量应与类别数保持一致,使得每个连通分量对应一个情感类别[14-15]。然而,简单地使用k最近邻准则进行邻域分配,很难得到理想的相似图。
为了解决上述问题,本文提出一种新的基于自适应结构图的半监督语音情感特征选择(Adaptive Structured Graph based Feature Selection,ASGFS)方法。该方法可以同时进行特征选择和局部结构学习,从而选择出更有判别性的语音情感特征。此外,使用基于图拉普拉斯的半监督学习,来更好地利用标记数据和无标记数据的特征选择和标签同时进行预测,在满足标签数据的标签适应度和整个数据结构的流形平滑度的前提下,同时进行特征选择和标签预测。在3个典型的语音情感数据上的实验表明,本文所提出的方法能够改善语音情感识别的性能。
之前的研究工作分别通过约束标签的适应度和流形的平滑度,介绍了利用局部和全局一致性(Local and global consistency, LGC)[16],以及高斯场和谐波函数(Gaussian fields and harmonic functions, GFHF)[17],在图上估计预测标签矩阵的方法。此外,许多方法利用流形正则来进行半监督扩展[18-19],例如岭回归(ridge regression)、支持向量机(Support Vector Machine, SVM)和线性判别分析(Linear Discriminant Analysis,LDA)。灵活流形嵌入(Flexible Manifold Embedding,FME)是一个半监督流形学习的统一框架[20],可表示为以下优化问题:
考虑到图拉普拉斯是半监督学习的基础,并且由于语音情感数据通常包含多种结构,可由流形正则进行刻画,因此就可将流形正则用于语音情感分析[21-22]。基于此,本文将提出一种基于图的半监督语音情感特征选择方法,其可在特征选择中自适应地学习局部流形结构。
2 基于自适应结构图的半监督特征选择
本节将详细介绍文中所提出的ASGFS模型,并针对其给出一种有效的优化求解算法。
3 实验与分析
3.1 数据集
本节将在3个典型的语音情感数据集上验证ASGFS方法的性能,包括Berlin[25]、eNTERFACE[26]和CASIA[27]。这些数据集记录了各种离散的情绪状态,例如愤怒、快乐、悲伤等。在语音情感特征提取方面,采用2010 副语言挑战赛的配置,并利用开源工具openSMILE 进行特征提取[28]。首先,为每个情感音频文件提取34个低阶特征(Low-level Descriptors,LLDs),例如音高、梅尔倒谱系数和响度等,并计算其一阶差分,得到68个低阶特征表示。然后,将19个统计函数部分或全部作用于每一个低阶特征上,得到超音段特征。此外,还为每个情感音频文件提取音高的起始时间以及会话的持续时间。最终,得到1 582 维的语音情感特征表示。在提取特征之后,采用说话人依赖的归一化策略,对数据进行独立的预处理,并将每个特征值标准化,使其均值为0,标准差为1。
3.2 实验设置
在数据库的划分方面,首先采用说话人依赖的策略,将各数据集中每个类的样本随机分为2部分。其中,一半作为训练数据,另一半作为测试数据。然后,分别将训练集中每个类5%、10% 和15%的样本作为半监督学习中的标注数据,其余的作为未标注数据。
为了验证特征选择方法的有效性,利用基于径向基(Radial Basis Function,RBF)核函数的支持向量机(Support Vector Machine,SVM)和随机森林(Random-Forest,RF)作为分类器来评价所选特征的分类性能,并采用是非加权平均召回率(Unweighted Average Recall,UAR) 作为性能评价指标。其计算公式如下:
本节使用全部原始特征的分类结果作为基线(记作All-fea)。除此之外,用于对比的特征选择方法主要包括:基于L2,1范数最小化的有监督特征选择(Feature Selection via L2,1-Norms Minimization,FSNM)方法[23]、局部敏感特征选择(Locality Sensitive Feature Selection,LSFS)方法[29]、以及结构化稀疏特征选择(Structural Feature Selection with Sparsity,SFSS)方法[11]。
在参数设置方面,对于所有采用正则技术的方法,各正则化参数的取值范围为{0.001,0.01,0.1,1,10,100,1 000}。对于所有需要构建邻接Laplacian图矩阵的方法,最近邻个数k固定取值为5。由于如何确定所选特征的最优数量仍然是特征选择研究中一个亟待解決的问题,因此本文采用在对数域的10,1 582区间内取20个数值作为所选特征的维数,并评估每个特征维数的性能。[JP2]此外,为了更好地反映各方法的性能,每个数据集均进行10 次独立的采样,以得到不同的训练集和测试集,并在其上验证各方法的性能,将10 次结果的均值作为最终的性能。[JP]
3.3 性能对比
图1~图3分别展示了不同特征维数时,SVM 和RF在5% 、10% 和15%标注数据上的分类结果。
从图1~图3中的结果可看出,当选择的特征数量较少时,所有特征选择方法的识别性能低于All-fea的性能。主要原因在于,这些特征丢失了大量对情感识别有用的信息。随着特征维数的增加,所有特征选择方法的性能整体呈现上升趋势。并且,在特征维数的较大变化范围内,都能取得明显优于All-fea的性能。这说明原始特征中包含不相关和冗余特征,导致对语音识别系统的性能产生负面影响。此外,在所有的特征选择方法中,ASGFS方法的整体性能最优。在特征维数相同时,其识别性能优于其它对比方法。而且,其能以最少的特征维数来获得与其它方法相近的性能。因此,本文所提出的方法可以选择更具判别性的语音情感特征。
根据图1~图3的结果,总结了各方法的最高精度参见表1、表2。
表1、表2中,粗体数字表示在所有方法中表现最优。从结果可以看出:
(1) 在2个分类器中,随着标记数据的增加,所有对比方法在各数据集上的识别性能都会提高。
(2) 所有特征选择方法在SVM和RF上的识别性能都优于基线系统,说明特征选择可以提高语音情感分类的性能。
(3) 对于Berlin数据集和eNTERFACE数据集,有监督特征选择方法FSNM优于半监督特征选择方法LSFS和SFSS,这说明在原始特征空间中所构造的相似图可能会对特征选择的性能产生负面影响。
(4) 对于CASIA数据集,在大多数情况下,LSFS和SFSS方法的性能都优于FSNM方法,这意味着在原始特征空间中所构造的相似图可以在一定程度上刻画该数据的内在结构信息。
(5) 在3种不同的标注数据量中, ASGFS方法在2种分类器上的性能都是最优的。相比于基线系统,该方法有着大约10%的性能提升;相比于 FSNM方法,有着2%的性能提升;相比于LSFS方法,有着4%的性能提升;相比于SFSS,有着3%的性能提升。主要因为,ASGFS方法能同时进行特征选择和局部结构学习,从而选择更具判别性的语音情感特征。
3.4 图相似度矩阵分析
本节将对ASGFS方法所得到的自适应结构图进行分析,并与传统的根据高斯函数构建的图[11]进行对比。图4~图6分别展示了Berlin、CASIA和eNTERFACE数据集的2种不同的图相似度矩阵。从结果可以看到,与传统的方法相比,ASGFS方法所得到的自适应结构图能够更清晰、更准确地刻画出数据内部的结构信息,从而可以利用其来帮助选择更具判别性的语音情感特征。这也进一步解释了ASGFS方法的性能优于其它对比方法的原因。
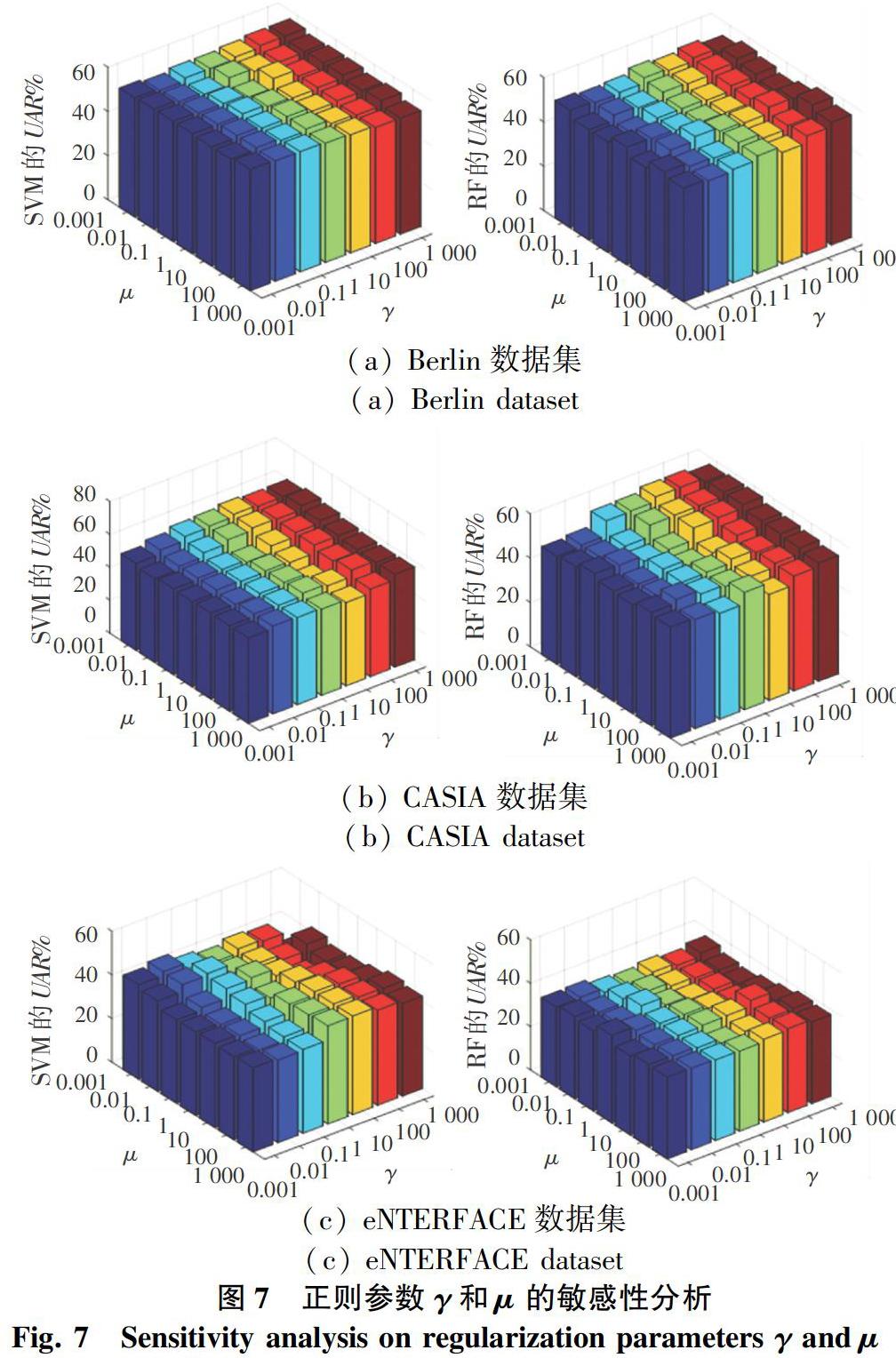
3.5 参数敏感性分析
本节将分析ASGFS方法对各参数的敏感性。该方法共包含2个正则参数:γ和μ,分别控制着组稀疏约束和分类损失函数对模型的影响程度。图7展示了ASGFS方法在各参数取不同值时,使用5%标记数据进行训练的语音情感识别模型的性能。从图7中的结果可以看出,不同的参数取值有着不同的识别性能。在Berlin数据集上,ASGFS方法对于参数γ和μ的不同取值有着较强的鲁棒性。在CASIA数据集上,当参数γ的取值大于μ时,ASGFS方法的识别性能更优。与之相反,在eNTERFACE数据集上,当参数γ的取值小于μ时,ASGFS方法能取得更好的性能。
3.6 收斂性分析
本节通过实验的方式来研究优化算法1的收敛性。在求解ASGFS的过程中,通过记录每次迭代后的目标函数值,得到算法的收敛曲线,如图8所示。由于算法1在不同数量的标注数据上的收敛性是一致的,为简洁起见,图8中只展示了5%标记数据的结果。从图8中可以看到,算法1是收敛的,且收敛速度非常快。一般来说,算法在10 次迭代之内就能收敛到一个稳定点。
4 结束语
本文提出了一种新的半监督语音情感特征选择方法。该方法将组稀疏约束、流形正则和直推式分类整合到一个联合特征选择模型中,并且能够同时进行特征选择和局部结构学习,从而得到自适应结构的图。在3个离散语音情感数据集上的实验表明,本文所提出的方法能够选择更具判别性的语音情感特征,从而改善语音情感识别系统的性能。
参考文献
[1] AYADI M E, KAMEL M S, KARRAY F. Survey on speech emotion recognition: Features, classification schemes, and databases[J]. Pattern Recognition, 2011, 44(3): 572-587.
[2] PARK J S, KIM J H, OH Y H. Feature vector classification based speech emotion recognition for service robots[J]. IEEE Transactions on Consumer Electronics, 2009, 55(3): 1590-1596.
[3] HAN Y, PARK K, LEE Y K. Confident wrapper-type semi-supervised feature selection using an ensemble classifier[C] // Proceedings of Artificial Intelligence, Management Science and Electronic Commerce. Deng Feng, China: IEEE, 2011: 4581-4586.
[4] LV S, JIANG H, ZHAO L. Manifold based fisher method for semi-supervised feature selection[C] // Proceedings of International Conference on Fuzzy Systems and Knowledge Discovery. Shenyang, China:IEEE, 2013: 664-668.
[5] WANG Jinyan, YAO Jin, SUN Yijun. Semi-supervised local-learning-based feature selection[C] // Proceedings of International Joint Conference on Neural Networks. Beijing, China: IEEE, 2014: 1942-1948.
[6] GUYON I, ELISSEEFF A. An introduction to variable and feature selection[J]. Journal of Machine Learning Research, 2003, 3(6): 1157-1182.
[7] XU Z, KING I, LYU M R, et al. Discriminative semi-supervised feature selection via manifold regularization[J]. IEEE Transactions on Neural Networks, 2010, 21(7): 1033-1047.
[8] ZENG Z, WANG X, ZHANG J, et al. Semi-supervised feature selection based on local discriminative information[J]. Neurocomputing, 2016,172(JANA15PTA1): 102-109.
[9] ZHU X. Semi-supervised learning literature survey[J]. Computer Science, 2008, 37(1): 63-77.
[10]SILVA V D, TENENBAUM J B. Global versus local methods in nonlinear dimensionality reduction[C] // Proceedings of Advances in Neural Information Processing Systems 15. Vancouver, British Columbia, Canada: Nips, 2002: 1959-1966.
[11]MA Z, NIE F, YANG Y, et al. Discriminating joint feature analysis for multimedia data understanding[J]. IEEE Transactions on Multimedia, 2012, 14(6): 1662-1672.
[12]SHI C, RUAN Q, AN G. Sparse feature selection based on graph Laplacian for web image annotation[J]. Image and Vision Computing, 2014, 32(3): 189-201.
[13]WANG D, NIE F, HUANG H. Feature selection via global redundancy minimization[J]. IEEE Transactions on Knowledge and Data Engineering, 2015, 27(10): 2743-2755.
[14]NIE F, WANG X, HUANG H. Clustering and projected clustering with adaptive neighbors[C] // Proceedings of ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York:ACM, 2014: 977-986.
[15]NIE F, ZHU W, LI X. Unsupervised feature selection with structured graph optimization[C]// Proceedings of Thirtieth AAAI Conference on Artificial Intelligence. Phoenix, Arizona, USA:AAAI, 2016: 1302-1308.
[16]ZHOU D Y, BOUSQUET O, LAL T N, et al. Learning with local and global consistency[M]// THRUN S, SAUL L, SCH-LOPF Proceedings of Advances in Neural Information Processing Systems16. Cambridge:MIT Press, 2004: 321-328.
[17]ZHU X, GHAHRAMANI Z B, LAFFERTY J D. Semi-supervised learning using gaussian fields and harmonic functions[C] // Proceedings of the Twentieth International Conference on Machine Learning.Washington DC:AAAI, 2003: 912-919.
[18]SINDHWANI V, NIYOGI P, BELKIN M, et al. Linear manifold regularization for large scale semi-supervised learning[C] // Proceedings of ICML Workshop on Learning with Partially Classified Training Data. Bonn, Germany:ICML, 2005:80-83.
[19]CAI D, HE X, HAN J. Semi-supervised discriminant analysis[C] // Proceedings of IEEE International Conference on Computer Vision. Rio de Janeiro,Brazil:IEEE, 2007: 1-7.
[20]NIE F, XU D, TSANG I W H, et al. Flexible manifold embedding: A framework for semi-supervised and unsupervised dimension reduction[J]. IEEE Transactions on Image Processing, 2010, 19(7): 1921-1932.
[21]YOU M, CHEN C, BU J, et al. Emotional speech analysis on nonlinear manifold[C] // Proceedings of International Conference on Pattern Recognition. Las Vegas,Nevada,USA:dblp, 2006: 91-94.
[22]KIM J, LEE S, NARAYANAN S S. An exploratory study of manifolds of emotional speech[C] // Proceedings of IEEE International Conference on Acoustics, Speech and Signal Processing. Dallas, Texas, USA:IEEE, 2010: 5142-5145.
[23]NIE F, HUANG H, CAI X, et al. Efficient and robust feature selection via joint L_2,1-norms minimization[C] // Proceedings of Advances in Neural Information Processing Systems 23. Vancouver, British Columbia,Canada:NIPS, 2010: 1813-1821.
[24]BOYD S, VANDENBERGHE L. Convex optimization[M]. New York, USA:Cambridge University Press, 2004.
[25]BURKHARDT F, PAESCHKE A, ROLFES M, et al. A database of German emotional speech[C] // Proceedings of Interspeech. Lisbon, Portugal: ISCA, 2005: 1517-1520.
[26]MARTIN O, KOTSIA I, MACQ B, et al. The enterface'05 audio-visual emotion database[C] // Proceedings of the 22nd International Conference on Data Engineering Workshops. ATLANTA, GA, USA:IEEE, 2006: 8.
[27]Chinese LDC. CASIA-Chinese emotional speech corpus[EB/OL]. [2015-02-24]. http://www.Chineseldc.Org/en/doc/cldc-spc-2005-010/intro.htm.
[28]SCHULLER B, STEIDL S, BATLINER A, et al. The Interspeech 2010 paralinguistic challenge[C] // Proceedings of Interspeech. Makuhari, Chiba, Japan:ISCA, 2010: 2794-2797.
[29]ZHAO Jidong, LU Ke, HE Xiaofei. Locality sensitive semi-supervised feature selection[J]. Neurocomputing, 2008, 71(10): 1842-1849.
