噪声环境下多特征融合的语音端点检测方法
2021-08-09罗思洋邵玉斌杜庆治
罗思洋,龙 华,邵玉斌,杜庆治
(昆明理工大学 信息工程与自动化学院,云南 昆明 650500)
语音信号中的语音段是由清音段和浊音段构成的[9],只有同时兼顾语音段中清音与浊音的追踪能力,并且提升端点检测方法在不同信噪比和不同噪声环境下的鲁棒性,才能进一步提升端点检测方法的性能.结合上述分析,本文提出了一种多特征融合的语音端点检测方法.通过研究发现,Gammatone频率倒谱系数的第一维系数GFCC0在噪声环境下对语音段中的清音和浊音都有较好的追踪能力,子带谱熵特征对语音段中的浊音追踪能力较好,而结合MFCC 系数和Fisher 线性判别的投影特征[10]对语音段中的清音有较好的追踪能力.因此考虑将GFCC0作为多特征融合的首要特征,结合子带谱熵特征和投影特征进一步提升对语音段的追踪能力,通过自适应加权融合的方法得到用于端点检测的融合特征.仿真实验证明,本文方法在-5~5 dB信噪比的white 噪声和-5~15 dB 信噪比的babble、
噪声环境下的语音端点检测就是从带有背景噪声的语音信号中区分出语音段和噪声段,从而提高语音信号的利用率[1].随着智能语音技术的发展,语音端点检测已经广泛应用到了语音识别、语音增强和音频分类技术的前端.例如端点检测可以简化语音识别过程中的冗余数据,加快语音识别系统的速度[2].
在漫长的发展历程中出现了上百种语音端点检测方法,可以将这些方法归结为基于模式识别和基于特征的方法[3].基于模式识别的方法主要有Zhang 等[4]提出的结合深度置信网络和10 类语音特征的端点检测方法,Thomas 等[5]提出的基于卷积神经网络的端点检测方法.这类方法使用语音信号的特征构建训练数据,通过大量训练达到区分语音段和噪声段的目的,训练过程需要大量数据,导致计算量较大,难以保证端点检测的实时性.基于特征的方法主要通过特征的提取和阈值的设定实现端点检测,常用的特征包括短时能量、谱熵[6]、子带谱熵[7]等.但是单一特征对噪声的鲁棒性较差,因此多特征融合的端点检测方法越来越受到关注.hfchannel、factory1、m109、pink、volvo噪声环境下具有比3 种对比算法更高的端点检测准确率,特别是在volvo 噪声环境下的端点检测准确率可以达到94.5%以上.
1 特征参数提取
特征提取是语音端点检测的关键问题.在基于特征的方法中,选择合理的特征融合构造适合端点检测的新特征,可以弥补单一特征对语音段追踪能力不足及噪声环境下鲁棒性较差的问题,有效提升端点检测的准确率.
1.1 子带谱熵特征提取子带谱熵特征是Wu 等[7]在谱熵特征的基础上改进得到的,相比于谱熵,子带谱熵的优点在于对每帧信号划分子带后减小了噪声对谱线幅值的影响.语音信号分帧后,对第i帧信号进行快速傅里叶变换得到Xi(k),该帧信号第k条谱线频率分量fk的能量谱Ei(k) 表示为

若每帧信号划分为Nb个子带,每个子带包含4 条谱线,那么第x个子带的能量为

Jia 等[11]在公式(3)的基础上引入了一个正常量K,计算得到新的子带能量概率为

1.2 MFCC 特征提取MFCC 特征作为语音信号处理最常用的特征之一,已被广泛应用于语音端点检测任务[12].MFCC 特征的提取是基于Mel 滤波器实现的,首先需要对语音信号进行预处理(包括预加重、分帧和加窗),然后对每帧信号进行快速傅里叶变换得到Xi(k),接着对Xi(k) 取平方后得到谱线能量Ei(k),Ei(k) 的表达式同公式(1).将每帧信号的谱线能量通过Mel 滤波器组,即使用谱线能量与Mel 滤波器的频率响应相乘,表达式如下:

其中,Hm(k)为Mel 滤波器频率响应,M为滤波器个数,m为滤波器的序号.将通过Mel 滤波器的能量取对数后进行离散余弦变换,可以计算得到MFCC 特征为

其中,M(i,n) 表示第i帧信息的第n维MFCC 特征.本文在提取MFCC 特征时,仅提取MFCC 系数,不提取MFCC 差分系数,所以信号首尾各两帧数据不用舍弃,最终得到每一帧信号的l维MFCC 特征记为Mi∈Rl×1,i表示帧序号,l表示所提MFCC特征的总维数.由于MFCC 特征通常取12 维及以上[13],在特征融合时参数量过多,并且该参数易受噪声影响.因此本文方法不将MFCC 特征直接用于特征融合,而是将该特征与Fisher 线性判别法相结合[10],提取对于端点检测任务更为有效的投影特征.
1.3 投影特征提取投影特征的提取是基于语音信号的MFCC 特征和Fisher 线性判别法实现的[10].本文在测试数据随机外截取一段清音段作为清音样本,分帧后得到N1帧信号,提取每帧清音样本的l维MFCC 特征记为Qi∈Rl×1,其中i表示帧序号即1≤i≤N1.对待提取投影特征的语音信号,取前N2帧作为噪声样本,提取每帧噪声样本的l维MFCC 特征记为Zi∈Rl×1,其中,1≤i≤N2.所提特征的均值向量为

其中,u1表示清音样本MFCC 特征的均值向量,u2表示噪声样本MFCC 特征的均值向量,u0表示u1和u2合并后的均值向量.设定一个与所提MFCC 特征维数相同的投影向量w,则可定义类间散度为

投影的目的在于使特征中SSW值最小,且SSB值最大[10,14].对语音信号分帧后,提取每一帧信号的l维MFCC 特征Mi,根据最佳方向投影后得到投影特征

1.4 GFCC0 特征提取相比于MFCC 特征,语音信号的GFCC 特征具有更好的抗噪性能[15].文献[3]将MFCC 的第一维系数MFCC0用于语音端点检测,取得了不错的效果.但通过研究发现,GFCC的第一维系数GFCC0具有比MFCC0更强的抗噪性能和语音追踪能力,特别是可以同时兼顾到语音段中浊音和清音的追踪,因此本文将GFCC0特征引入到端点检测任务中.图1(a)为一段纯净语音信号的归一化幅值;图1(b)为该段语音信号的清浊音标注结果,其中噪声段标注为0,语音段中的浊音标注为2,清音标注为1;图1(c)为该段语音信号的归一化MFCC0特征曲线,根据语音信号波形将该信号前10 帧视为纯噪声帧,虚线为前10 帧信号MFCC0特征的平均值,将虚线作为MFCC0参考线;图1(d)为该段语音信号的归一化GFCC0特征曲线,虚线为前10 帧信号GFCC0特征的平均值,将虚线作为GFCC0参考线.从图中可以看出,信号浊音段的MFCC0特征高于MFCC0参考线,而清音段的MFCC0特征却低于MFCC0参考线,该特征难以同时兼顾语音段中浊音和清音的追踪,同时部分噪声段的MFCC0特征也高于MFCC0参考线,上述两方面都会影响到MFCC0特征对语音段的追踪能力;而信号浊音段和清音段的GFCC0特征均高于GFCC0参考线,所以GFCC0特征可以同时兼顾到语音段中浊音和清音的追踪,同时信号噪声段的GFCC0特征在GFCC0参考线附近.因此在端点检测任务中GFCC0对语音段的追踪能力强于MFCC0.
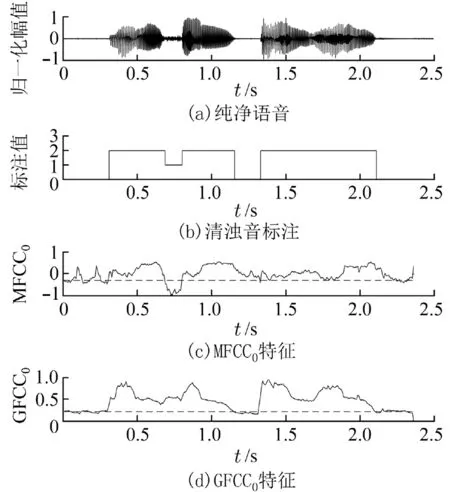
图1 语音信号GFCC0 和MFCC0 特征对比Fig.1 Comparison of GFCC0 and MFCC0 of speech signal
GFCC 特征的提取是基于Gammatone 滤波器组实现的.与MFCC 特征提取相同的是,在GFCC特征提取前需要对语音信号进行预处理,得到谱线能量Ei(k).与MFCC 特征提取不同的是,在GFCC特征提取过程中,谱线能量通过滤波器后不再使用对数压缩的方式,而是采用指数压缩的方式

其中Hm(k)为Gammatone 滤波器频率响应,M为滤波器个数,m为滤波器的序号,a为指数压缩值,本文取指数压缩后的能量经过离散余弦变换后得到GFCC 特征:

其中G(i,n) 表示第i帧信息的第n维GFCC 特征.通过式(19)计算得到每一帧信号的GFCC 特征,取该特征的第一维系数就可以得到特征融合所需的新 特征GFCC0,记为Gi.
2 多特征融合的语音端点检测
特征提取得到语音信号的子带谱熵特征Hi、GFCC0特征Gi和投影特征ri后,还需要对3 类特征自适应加权融合,多特征融合旨在得到对语音段追 踪能力更强的融合特征.
2.1 多特征融合多特征融合前,首先对语音信号的3 类特征进行对比分析.图2 所示为一段语音信号的特征对比图,其中图2(c)为中值滤波平滑处理后的子带谱熵特征值Hi;图2(d)为平滑处理后的投影特征值ri;图2(e)为归一化GFCC0特征值Gi.

图2 语音信号特征对比Fig.2 Comparison of speech signal features
端点检测目的在于区分出语音信号中的语音段和噪声段,其中语音段是由浊音段和清音段共同构成的.在多特征融合前,结合图2 对3 类特征的特点进行分析:①浊音段的子带谱熵特征远小于噪声段,但是清音段和噪声段的子带谱熵特征却很接近,因此子带谱熵特征可以有效区分语音信号中的浊音段和噪声段;②清音段的投影特征大于噪声段的投影特征,而浊音段和噪声段的投影特征却很接近,因此投影特征主要针对的是清音段和噪声段的区分;③从语音信号的归一化GFCC0特征可以看出,浊音段和清音段的GFCC0特征大于噪声段的GFCC0特征,图1(d)中与参考线的对比更加突出了该特点,因此GFCC0特征可以同时兼顾语音段中浊音和清音的追踪.同时GFCC 特征具有较好的抗噪性能[15],通过实验发现GFCC0特征在噪声环境下对语音段中的浊音和清音同样具有较好的追踪能力.因此考虑加权融合这3 类特征,得到适用于端点检测的新特征.多特征融合的流程如图3 所示.
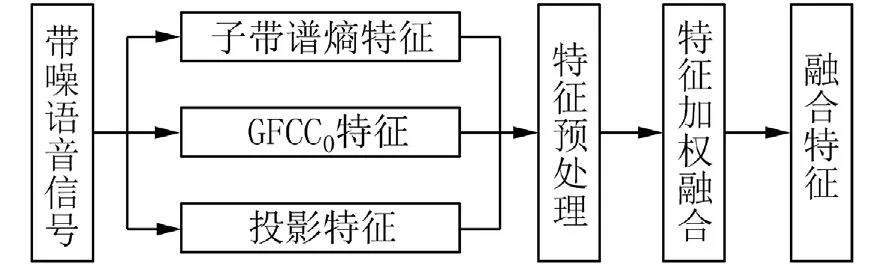
图3 多特征融合流程图Fig.3 Flow chart of multi-feature fusion
特征预处理首先使用中值滤波分别对3 类特征进行平滑处理,然后对3 类特征的幅度平移调整后取绝对值,计算方法如下:

投影特征的预处理还包含数据的归一化,归一化投影特征如下:

权重系数的求解是基于3 种特征平移调整后的平均值自适应计算得到的,权重系数的计算如下:
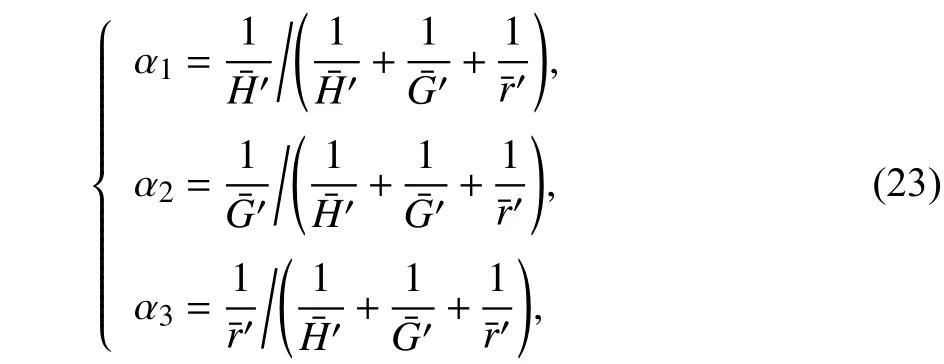
其中,α1表示特征融合时子带谱熵的权重系数,α2表示特征融合时GFCC0的权重系数,α3表示特征融合时投影特征的权重系数.得到自适应估计的参数权重后,进行特征融合:
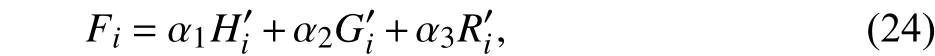
其中表示预处理后的子带谱熵特征,表示预处理后的GFCC0特征,表示预处理后的投影特征.对式(24)结果归一化后得到端点检测的融合特征值为

图4 所示为纯净语音和带噪语音(含SNR=5dB 的pink 噪声)波形及其融合特征值.
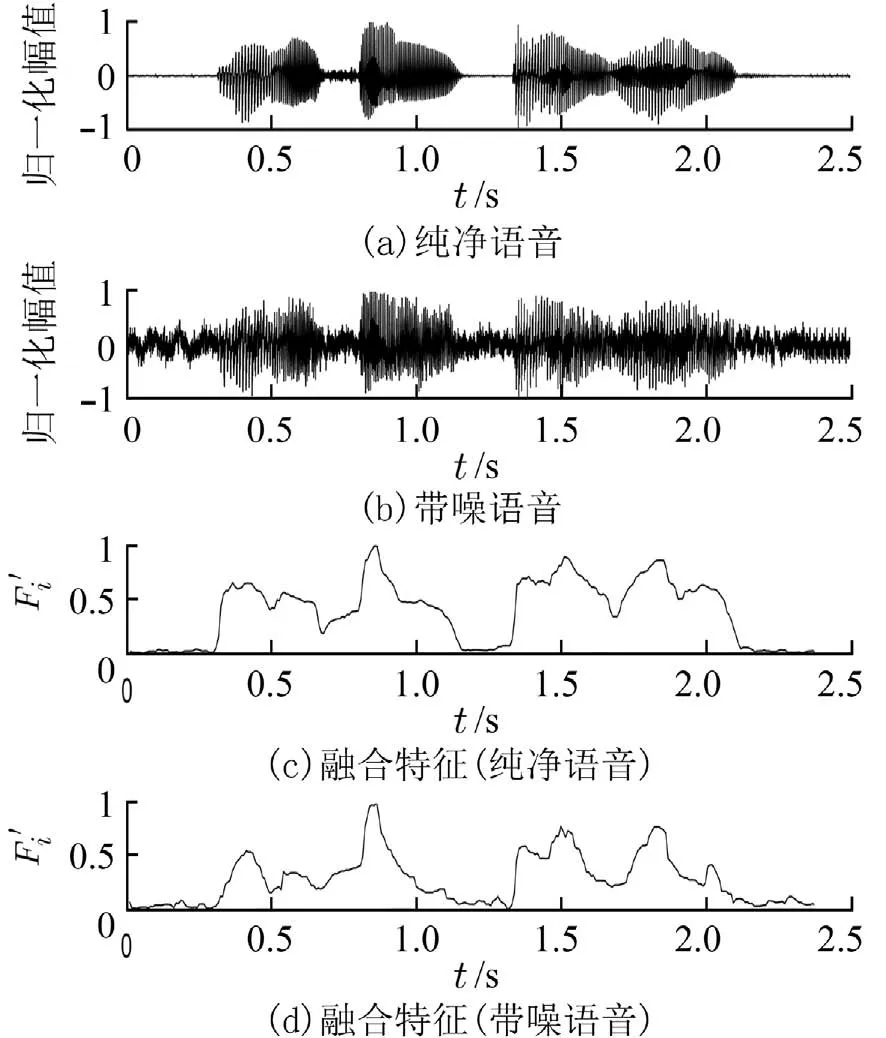
图4 语音信号的融合特征Fig.4 Fusion features of speech signal
将图4(c)与图2 对比可以看出,多特征融合将3 类特征的优点相结合,得到对语音追踪能力更强的融合特征,其中语音段的融合特征往往大于噪声段的融合特征,体现了融合特征对语音段的追踪能力.在5 dB 信噪比的pink 噪声环境下,语音段的融合特征同样大于噪声段的融合特征,体现了融合特征的抗噪性能.
2.2 自适应门限估计与端点检测本文针对多种噪声环境下的语音信号进行端点检测,在得到用于端点检测的融合特征后,首先使用模糊C 均值聚类法对每一条语音的门限值进行自适应估计,然后通过双门限法实现语音信号的端点检测.模糊C均值聚类的损失函数如下[16]:

其中,xi为样本,i为样本序号,N为样本总数,mj为聚类中心,j为聚类中心序号,C为聚类中心的总数,b>1为模糊常数,µj(xi) 为隶属度函数,同时满足
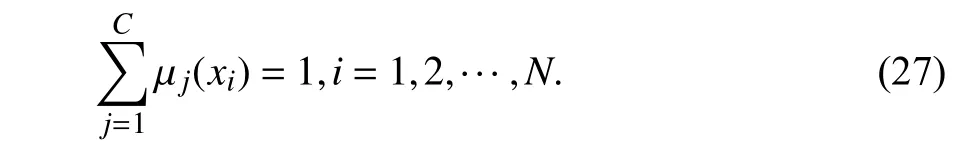
目标是使式(26)最小,通过求mj和µj(xi) 的偏导数并令偏导数为0,可得
妊娠期高血压是一种常见的妊娠期疾病类型,会对孕妇及胎儿产生极大的影响,容易导致胎儿宫内窘迫和产后出血等多种不良后果[4]。临床对妊娠期高血压产妇进行剖宫产术治疗之后,存在一定的产后出血风险,严重威胁产妇健康和安全。为此,临床需要积极做好相应的预防措施[5]。
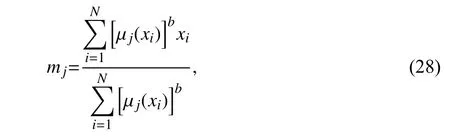

其中,本文使用的样本xi是语音信号的融合特征,样本序列i是输入语音的帧序号,样本总数N是输入语音的总帧数.j=1,2,···,C表示聚类中心的序号,本文针对噪声环境下的语音端点检测,实质上是使用融合特征实现语音帧和噪声帧的二分类,因此聚类中心个数取C=2.
自适应门限估计和端点检测的步骤如下:
步骤1根据式(25)计算语音信号的融合特征;
步骤2设定聚类中心个数C=2,计算得到融合特征的自适应聚类中心 {m11,m12},其中

其中,Th为双门限的高门限值,Tl为低门限值,β1和 β2为经验常数;
步骤4根据自适应聚类中心与 β1、β2,结合式(31)自适应估计双门限法的门限值,得到端点检测的结果.
3 实验设计与结果分析
实验的纯净语音数据来自TIMIT 数据库,噪声数据来自NOISEX-92 数据库.从TIMIT 数据库中随机选取男女说话人各50 条纯净语音,并在这100 条纯净语音外随机截取一段0.11 s 的清音段作为清音样本.为了验证算法在多种噪声环境下的性能,将纯净语音分别与NOISEX-92 数据库中的white、babble、hfchannel、factory1、m109、pink 和volvo7 种噪声按照-5、0、5、10、15 dB 的信噪比合成带噪语音.合成的3 500 条带噪语音作为实验的测试数据,均统一为8 kHz 采样率、16 bit 量化精度的单声道音频文件.
在实验前使用传统双门限法对纯净语音进行标记,并对传统双门限法标记错误的帧进行人工修正,以修正后的标记结果作为本次实验仿真的参考标准.由于语音信号在10~30 ms 内具有短时平稳性,所以实验仿真取帧长16 ms(128 个采样点),帧移8 ms(64 个采样点).本文在提取子带谱熵时引入的正常量K=0.5;在构造投影特征时提取的MFCC 特征维数l=12,提取的噪声样本长度为N2=10帧;β1和β2的设定流程如图5 所示,即随机设定 β1和β2的初始值,根据目标分类准确率迭代调整,直至获得满足目标分类准确率的值作为最终取值,得到

图5 β1和β2 设定流程图Fig.5 Flow chart of β1 and β2 setting
在端点检测过程中,会出现语音帧的漏检和噪声帧的误检,综合考虑后使用语音端点检测的准确率作为最终评价指标,定义如下[3]:

其中,L1表示语音帧漏检为噪声帧的帧数,L2表示噪声帧误检为语音帧的帧数,L表示语音信号的总帧数.
为了验证本文算法的性能,选取传统算法中结合短时能量与过零率的传统双门限法和子带谱熵法作为对比算法,此外还使用了文献[3]中基于谱熵梅尔积的端点检测算法作为对比算法.合成的3 500 条带噪语音分别使用本文算法和3 种对比算法进行端点检测,并使用公式(32)计算准确率.
3.2 实验结果分析图6~8 分别展示了本文方法在volvo 噪声(SNR=-5 dB)、white 噪声(SNR=0 dB)和factory1 噪声(SNR=5 dB)环境下的端点检测结果.图6~8 中的子图(c)为实验前标注的语音端点检测结果的参考标准,语音段(包含浊音段和清音段)标注为1,噪声段标注为0;图6~8 中的子图(a)和(d)均标注了本文方法的检测结果,其中子图(d)为本文方法在融合特征值上的检测结果,竖实线处表示语音段开始,竖虚线处表示语音段结束.通过对比本文方法的检测结果和标注的参考标准可以看出,本文提出的融合特征可以区分出带噪语音信号的语音段和噪声段,将该特征应用到端点检测任务中可以较好的找到语音段的开始位置和结束位置.

图6 volvo 噪声环境下的检测结果(SNR=-5 dB)Fig.6 Detection results in volvo noise environment (SNR=-5 dB)
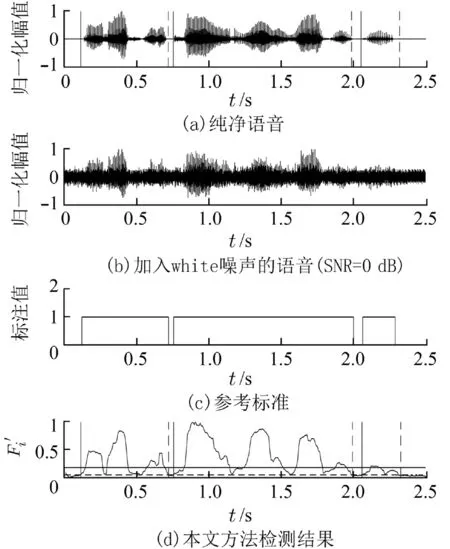
图7 white 噪声环境下的检测结果(SNR=0 dB)Fig.7 Detection results in white noise environment (SNR=0 dB)
根据式(32)计算得到本文算法和3 种对比算法在不同噪声和不同信噪比环境下的语音端点检测准确率.本文将准确率低于50%的端点检测定义为失效,最终结果如表1 所示.
从表1 可知,在进行实验仿真的7 种噪声环境下,传统双门限法在信噪比低于0 dB 时检测准确率往往不足50%,造成检测方法的失效;当信噪比达到10 dB 后,传统双门限法性能得以提升,随着信噪比的增加,准确率也逐渐增加.造成传统双门限法在低信噪比环境下准确率较低的原因是,低信噪比环境下语音信号的过零率会增大,而过零率作为实现传统双门限法的主要特征,会影响到双门限法的第二级判决,从而影响到端点检测的准确率.基于子带谱熵的语音端点检测方法在-5 dB 信噪比环境下可以达到55%以上的准确率,不会出现端点检测的失效;检测准确率同样会随着信噪比的增加而增加,但是在10 dB 和15 dB 信噪比下的表现不如双门限法.子带谱熵法的实验结果体现了单一特征往往难以在噪声环境下达到令人满意的检测效果,因此多特征融合的方法成为了近年来语音端点检测的研究重点.相比于传统双门限法和子带谱熵法,文献[3]中结合谱熵特征和MFCC0的方法在低信噪比环境下取得了更好的端点检测效果,并且在10 dB 和15 dB 的white 噪声环境下取得了最高的端点检测准确率.通过实验发现,在10 dB和15 dB 的white 噪声环境下,本文所提的融合特征在端点检测时出现了比文献[3]方法更多的误检帧数,导致准确率略低于文献[3]的方法.但是本文提出的多特征融合的端点检测方法比文献[3]所提方法具有更好的抗噪性能,在信噪比为-5、0和5 dB 的white 噪声环境下取得了比文献[3]方法更高的端点检测准确率;同时本文提出的多特征融合的端点检测方法在babble、hfchannel、factory1、m109、pink 和volvo 6 种噪声的不同信噪比环境下,都取得了比3 种对比算法更好的端点检测效果.
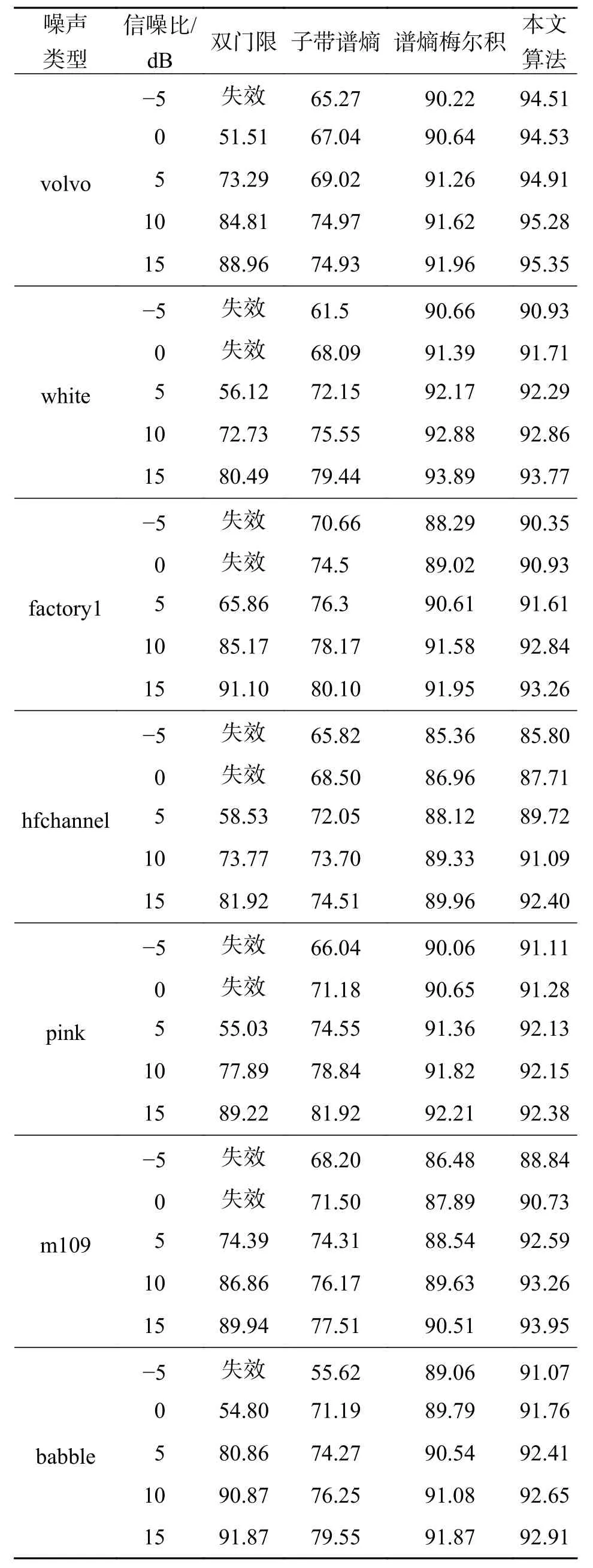
表1 不同方法端点检测准确率对比Tab.1 Comparison of detection accuracy of different methods %
4 结论
本文将GFCC0特征应用到语音端点检测任务中,将该特征与子带谱熵特征、投影特征自适应融合构造适用于端点检测的新特征,然后使用模糊C 均值聚类算法自适应估计门限阈值,最后通过双门限法实现端点检测.相比于3 种对比算法,本文提出的端点检测方法在多种噪声的不同信噪比环境下均提升了端点检测的准确率.这主要归功于本文方法使用对语音段追踪能力较强的3 种特征自适应融合,进一步提升了对语音段的追踪能力.在未来工作中,需要继续对多特征融合的方法和门限估计的方法进行研究,减少语音帧的漏检和噪声帧的误检,进一步提升语音端点检测的准确率.
