基于K-means和高斯混合模型聚类的齿轮箱故障识别研究*
2021-08-07刘胜兰
王 浩,刘胜兰,刘 晨
(中国舰船研究院,北京 100192)
0 引 言
齿轮箱的构件主要包含轴承、齿轮、转轴等,它是机械装置中应用最广泛的传动设备。
在轴承和齿轮的运行过程中,其承受的力均为周期性的冲击,往往容易造成点蚀或局部缺陷,长期运行会造成齿轮箱构件的疲劳失效,因此,其故障率往往很高[1-3]。齿轮箱轴承或齿轮一旦失效,会导致整个传动系统瘫痪。虽然很多企业已经安装了齿轮箱在线状态监测系统,但目前在用的状态监测系统中的报警阈值均是根据齿轮箱构件损伤的极限状态设置的,监测准确率不高;而且从故障预警到分析确定故障源需要花费大量时间,对振动信号进行处理和分析。
因此,通过构造齿轮箱各运行状态的从属概率模型,从而快速地识别齿轮箱齿轮和轴承构件的故障,可以提升齿轮箱的故障诊断效率。
近年来,国内外学者基于齿轮箱的振动机理,开展了大量针对齿轮箱故障诊断的研究,这些技术已在齿轮箱故障诊断领域被广泛应用。例如,通过包络解调分析技术提取轴承故障特征[4]。但随着轴承故障诊断研究的深入,人们发现,包络分析的难点在于确定信号解调频带,大多时候采取反复试凑的方式,这在实际应用中非常不方便。因此,后来出现了信号分解技术与包络分析相结合的轴承故障分析方法。例如:蔡艳平等[5]结合经验模态分解和包络分析,提取了滚动轴承内圈缺陷故障特征,进行了轴承的故障分析。岳应娟[6]提出了结合变分模态分解和包络分析的轴承故障特征提取方法。潘海洋[7]提出了结合系数带宽模态分解与包络分析的轴承故障特征提取方法。
随着齿轮箱使用场合的复杂化,及其在工业领域重要性的不断提升,对齿轮箱故障诊断提出了更高的要求。传统基于振动信号分析的齿轮箱机械故障诊断方法,需要花费大量的时间进行信号处理,无法快速、有效地分析得出诊断齿轮箱中存在的故障,增加了设备停机时间或带病运行的时间。
针对上述问题,秦波等[8]通过Hilbert变换,提取了滚动轴承信号的特征值,利用支持向量机实现了对滚动轴承各类故障的分类。WIDODO A等[9]提出了基于相关支持向量机的多分类方法,实现了对低速状态下运行的轴承的故障识别。
在聚类算法分析方面,王书涛等[10]提出了基于威布尔和模糊C均值聚类的故障识别方法。姜万录等[11]结合变分模态分解和核模糊C均值聚类,实现了对轴承故障的识别。张淑清等[12]基于RQA参数和GG聚类方法,实现了对轴承故障的识别。
在预测模型和神经网络模型的故障识别算法方面,张元强等[13]结合变分模态分解和Volterra预测模型,实现了对轴承的故障识别。PATIL A B等[14]利用离散小波变换,得到了振动信号的特征参数,并通过构件前馈BP神经网络实现了对轴承故障的分类。
同样,很多学者利用模式识别和机器学习算法进行了齿轮故障的快速识别。陈法法等[15]通过局部切空间排列算法,对构建的特征集进行了降维,利用多核支持向量机训练降维特征,实现了对齿轮箱故障的识别,但该方法对齿轮的某些故障的识别准确率依然不高。邓世杰等[16]采用邻域自适应增量式PCA-LPP流行学习算法,在对齿轮箱振动信号特征进行降维处理后,进行了故障识别。
综上可以看出,在齿轮箱故障的自动识别技术研究当中,识别准确率有待进一步提高,以便于齿轮箱故障自动识别方法的推广应用。
本文结合K-means算法和高斯混合模型聚类,针对齿轮箱最常见的轴承和齿轮故障,提出基于模型的故障识别方法,并通过与模糊c均值聚类方法的比较,以验证本文提出的方法故障识别率更高,对齿轮箱故障识别有实际意义。
1 经验模态分解及分析
经验模态分解是一种能将信号按低频到高频进行分解的方法。相比短时傅里叶变换及小波变换,经验模态分解无须人工选择基函数,可以根据信号特点产生基函数,分解信号时域和频域精度高,能够很好地展现信号的局部特征。
首先,笔者将信号分解为一系列表征信号特征时间尺度的固有模态函数。原始信号可由若干个IMF分量和一项残差构成[17],即:
(1)
式中:ci(t)—固有模式分量,主要包含信号的局部信息,m/s2;Rn(t)—信号残余分量,m/s2。
经验模态分解得到的各个分量能够表征信号的局部信息,可利用相关分析法选取IMF分量,从而实现信号特征的提取。
两个序列相关系数的计算公式如下:
(2)
式中:cov(x,y)—x,y的协方差;D(x)—x的方差;D(y)—y的方差。
ρxy值越接近1,x,y的相关性越大;ρxy越接近0,x,y相关性越小。IMF分量和原始信号的相关系数反映了IMF分量包含原始信号局部特征的信息量,该系数越大,表明IMF分量包含的原始信号局部特征信息越全面。
2 聚类方法
2.1 K-means聚类
K-means聚类是一种经典的无监督学习算法,通过迭代将数据划分到各个区域,使得数据点到各区域中心的距离之和最小。
K-means的目标函数及优化如下[18]:
(3)
迭代优化中,聚类中心μk和指示矩阵rnk,这是一个NP问题,直接进行优化太难,需要迭代优化这两个变量,从而得到一个最优解。具体的迭代步骤如下:
(1)固定聚类中心μk,优化指示矩阵rnk:若第n个样本距离第k个中心最近,则赋值rnk=1;否则,rnk=0;
(2)固定指示矩阵rnk,优化聚类中心μk,由式(3)对中心μk求导可得:
(4)
令式(4)等于0,可以得到聚类中心μk:
(5)
通过迭代,最终达到最小化距离总和的目标,如下式所示:
(6)
经过上述迭代,最终可得到k个区域的类中心。
2.2 高斯混合模型聚类
高斯混合模型是基于高斯函数的一种聚类方法,它是一种软聚类。此处首先对数据类别和数据的分布进行假设[19]:
zi~Multinomial(φ)
(7)
p(x(i)|z(i))~N(μj,∑j)
(8)
式(7,8)分别是类别数和样本数据的假设分布类型—多项式分布和高斯分布。由式(7,8)可以得到x和z的联合分布函数:
p(x(i),z(i))=p(x(i)|z(i))*p(z(i))
(9)
根据似然函数可得到假设分布的3个参数:
(10)
式中:φ—包含隐含变量z服从的概率分布;μ—混合高斯分布的均值;∑—混合高斯分布的协方差。
笔者通过最大期望算法EM实现了参数估计,通过对式(10)进行拉格朗日替换和对3个参数求偏导,得到了3个参数的迭代式。具体的算法流程如下[20]:
(1)对于每一个i,j,重复下列运算,直到收敛:
(11)

(2)参数更新:
(12)
(13)
(14)
根据贝叶斯公式可以得到:
p(z(i)=j|x(i);φ,μ,∑)=
(15)
(3)不断地迭代步骤(1,2),更新3个参数,直到|P(X|φ)-P′(X|φ)|<ε,即前后两次迭代得到的结果变化小于设定误差,则终止迭代。
3 齿轮箱故障识别实验及分析
3.1 数据样本特征集构造
笔者设置齿轮箱正常、轴承内外圈磨损、齿轮磨损、缺齿、断齿等情况下的实验,实验台如图1所示。

图1 齿轮箱实验台
图1中,实验台所用传感器为JM411加速度传感器,数据采集设备是美国NI公司生产的NI9234采集卡。采集齿轮箱振动信号,由振动信号的均方根值构成全局特征参数,由最佳IMF分量的均方根值作为信号的局部特征参数,共同构成振动数据样本的特征集。
齿轮箱正常状态、齿轮断齿故障、齿轮磨损故障、缺齿故障、轴承内圈磨损故障、轴承外圈磨损故障等状态下,振动信号的原始波形如图2所示。

图2 原始振动加速度信号波形图
由图2中的振动信号波形形态可以看出:轴承和齿轮在正常、各类故障状态下,振动信号波形均有差异,但需要将定性分析转变为定量的特征。
IMF分量的均方根值能够反映信号的局部特征,其计算公式如下:
(16)
式中:xi—信号序列,m/s2;N—信号点数。
在齿轮箱各状态下,根据各IMF分量与原始数据的相关分析结果,笔者从振动信号中选取相对最佳IMF分量,最佳分量的波形如图3所示。
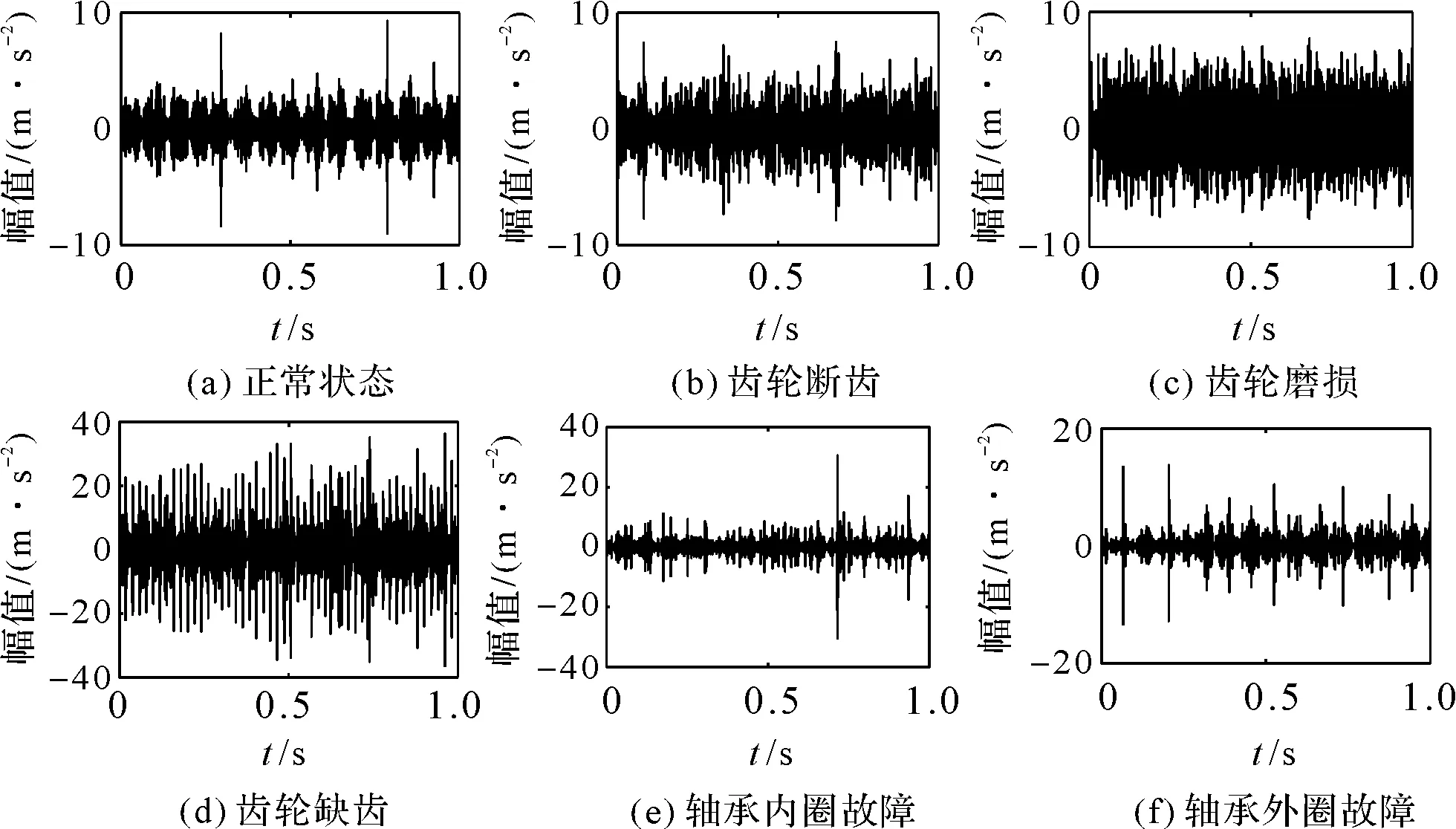
图3 齿轮箱各状态下最佳IMF分量
由图3可以看出:除齿轮磨损信号外,轴承和齿轮正常、各类故障状态下,最佳IMF分量信波形中的冲击信号更加明显;经验模态分解获取的最佳IMF分量一定程度上能够去除原始信号中的冗余信息和干扰信号。
考虑到经验模态分解会造成信号的全局特征信息丢失,要通过计算原始信号的均方根值表征信号的全局特征。因此,此处整个特征集由局部特征和全局特征构成。
3.2 训练样本特征分析
齿轮箱正常、故障等6种状态下的实验中,电机转速为1 500 r/min,6种状态下振动信号的IMF分量均方根值和原始信号均方根值各50组,构成样本特征集。笔者通过K-means聚类算法对上述构造的特征集进行评判,为后续建立故障识别模型奠定基础。
3.2.1 K-means聚类分析
笔者利用K-means算法,通过不断遍历指定分类范围内不同类别数K值下,分类结果中样本点到各自聚类中心距离的平方误差,从而确定样本数据类别数。
误差的计算公式如下:
(17)
当分类数等于总样本数时,平方误差等于0,因此可以得出,平方误差值随着K值的增加单调递减,不断接近于0;当K值接近于数据最佳类别数的地方时,平方误差SSE会出现一个拐点,平方误差的变化趋于缓慢,此时的K值即为最佳类别数。
不同K值下,距离误差总合SSE的变化趋势如图4所示。
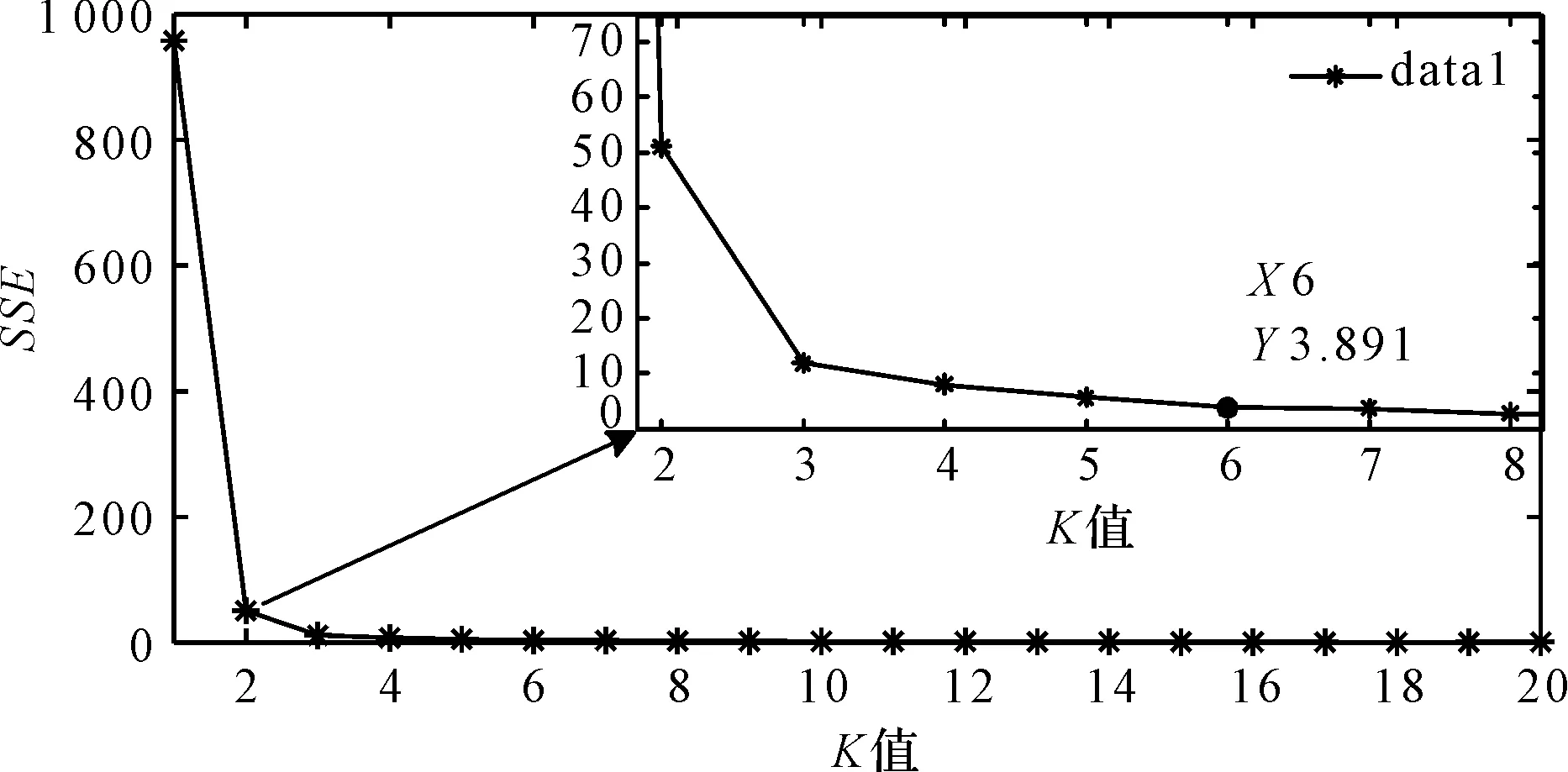
图4 不同K值下K-means聚类结果
图4中,随着K值的增加,平方误差SSE逐渐变小,并逐渐收敛于0。
不同K值下,平方误差SSE及其差值如表1所示。

表1 不同K值下k-means聚类误差
由表1可以看出:当K=6时,K=5与K=6的平方误差SSE的差值降为0.1;K>6时,平方误差SSE开始缓慢变化,可以判定样本数据为6类,与实际特征集类别数相符,证明了特征集的有效性。
利用K-means算法可以快速、准确地确定出样本数据的类别数,从而实现对样本特征集效果的评价,K值越靠近理论类别值,说明各类间特征的区分度越高,构造的样本特征集越好。
3.2.2 高斯混合模型聚类分析
笔者利用高斯混合模型方法对齿轮箱振动数据的特征进行聚类分析,利用齿轮箱6种状态下的振动特征数据建立高斯混合模型。
由高斯混合模型得到的6类数据的二维高斯分布图如图5所示。

图5 齿轮箱6种状态下二维高斯分布
图5中,横坐标是由振动信号IMF分量信号的均方根值构成的局部特征,纵坐标是由原始振动信号的均方根值构成的全局特征。由图5可以看出:齿轮箱6种状态下二维高斯分布云图形态均有差异,能够将齿轮箱6种状态区分开。
6种状态下二维高斯分布函数的参数如表2所示。

表2 6种状态二维高斯分布函数参数
多维高斯分布函数的计算公式为:

(18)
式中:x—样本数据,m/s2;d—数据维度;α—权重系数,由高斯混合模型训练得到的每类数据的概率;u—样本均值,m/s2;∑—样本协方差。
笔者利用高斯混合模型聚类方法建立齿轮箱状态识别模型。
该模型的故障识别流程如图6所示。
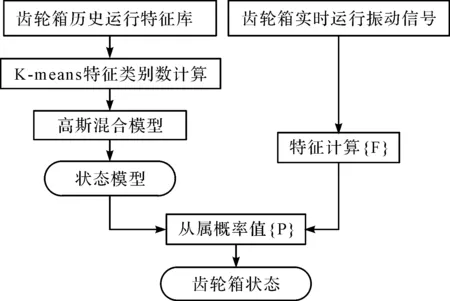
图6 基于高斯混合聚类的齿轮箱故障识别流程
图6中,笔者首先利用K-means算法间接评价了齿轮箱状态特征库特征集的效果,确定了高斯混合模型各类数据的多维高斯分布模型,根据实时采集的齿轮箱振动信号,得到了齿轮箱振动数据的特征值,将该特征值输入到各状态模型中,从而得到了该特征值在各个分布函数中的从属概率,由从属概率的大小最终确定了齿轮箱的运行状态;
然后笔者利用齿轮箱实验数据对上述方法进行验证,将齿轮箱各状态下实时运行数据输入到齿轮箱状态匹配模型中,得到了实时运行数据的从属状态。
齿轮箱各状态下的特征值输入到二维高斯状态模型,得到的从属概率值如图7所示。
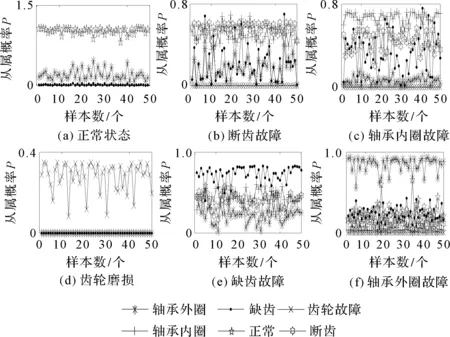
图7 齿轮箱各运行状态下模型从属概率
从图7中可以看出:(1)6个状态模型给出从属概率值越大,齿轮箱越倾向于该运行状态;(2)正常状态模型、轴承内圈磨损故障模型、齿轮磨损故障模型、齿轮缺齿故障模型和轴承外圈磨损故障模型,均能够准确判断出齿轮箱正常运行状态;(3)齿轮箱齿轮断齿故障模型确定的齿轮箱断齿和轴承内圈故障的从属概率值有重合,但从平均概率可以判定为齿轮断齿故障。
同时,笔者将本文提出方法的故障识别准确率与模糊c均值聚类方法进行对比。
基于模糊c均值聚类的齿轮箱故障识别流程如图8所示。

图8 基于模糊c均值聚类的齿轮箱故障识别流程
本文定义的齿轮箱各状态下故障识别准确率如下式所示:
(19)
式中:Ci—该类样本分类正确的样本数;Li—该类实际样本数。
两种方法对相同齿轮箱运行状态的故障识别准确率如表3所示。
由表3两种方法的对比可以发现:
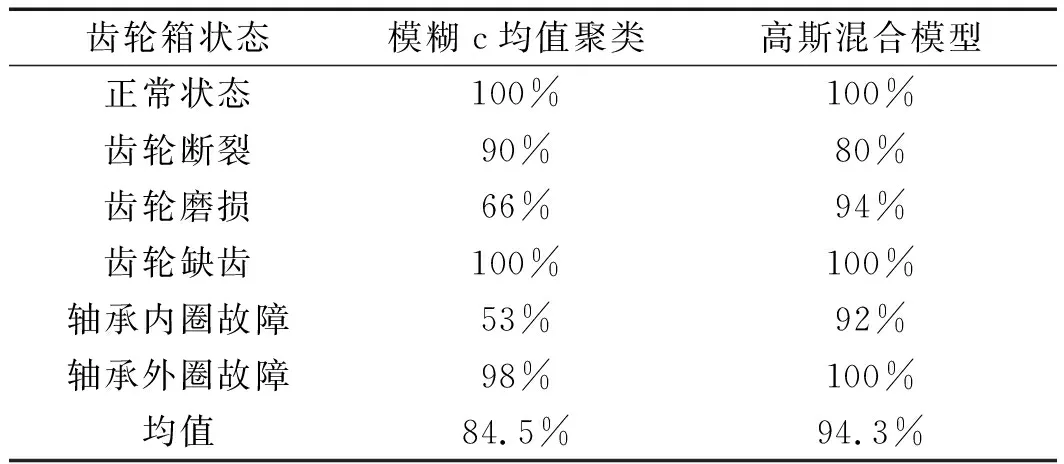
表3 两种故障识别方法识别正确率
(1)两种方法均能准确识别齿轮箱的正常状态及齿轮缺齿状态,准确率达到100%;(2)模糊c均值聚类方法对齿轮箱齿轮磨损故障和轴承内圈磨损故障诊断准确率过低,分别为66%和53%;(3)从整体上看,基于高斯混合模型的故障识别率比基于模糊c均值聚类方法的故障识别率更高。
4 结束语
本文通过齿轮箱振动信号均方根值和IMF分量的均方根值构造了振动信号全局特征和局部特征,利用K-means对特征集的分类数进行了确定,验证了特征集的构造效果;然后通过构造各运行状态的高斯混合模型,得到了各类数据的多维高斯分布模型,根据各运行状态的多维高斯分布模型计算得到了齿轮箱当前运行数据的从属概率;并根据从属概率最大原则,得出了齿轮箱的运行状态。实验结果表明,本文提出的方法能够识别齿轮箱各类物理仿真状态。
根据研究结果可得出以下结论:
(1)基于K-means和高斯混合模型聚类的齿轮箱故障识别方法,能够准确识别试验环境下齿轮箱轴承和齿轮的典型故障;
(2)基于高斯混合模型聚类的齿轮箱状态识别方法,能够准确识别齿轮箱齿轮磨损、缺齿及轴承内、外圈故障,但对于齿轮断齿故障识别的准确率还需进一步提升。
笔者后续将根据该方法的实际应用效果,不断优化故障识别方法,进一步提升齿轮箱轴承和齿轮故障识别准确率。
