基于Pearson特征选择的随机森林模型股票价格预测
2021-08-06闫政旭
闫政旭,秦 超,宋 刚
1.山东财经大学 金融学院,济南 250014
2.山东财经大学 计算机科学与技术学院,济南 250014
3.山东大学 数学学院,济南 250100
在股票市场中,股票价格的涨跌受价格指标、流通量指标以及活跃程度等多种因素的影响。在股票市场中,人们希望能够有效地预测出股票价格的走势,从而避免带来不必要的损失,并分析出影响股票价格波动的重要影响因子。但在股票市场中,股票价格的波动本身就是一种非线性、动态、不平稳的过程。其波动过程中本身就含有或大或小的噪声,从而对股票价格的走势造成重大的影响。所以,如何更加准确地在多维数据特征下准确地预测股票价格走向以及波动程度成为了国内外诸多学者关心的问题。
股票价格作为一种时序性的时间序列,对其预测的方法一直是人们关注的重点。机器学习是近年来流行起来对股票价格进行预测的一种新的方法,支持向量机(Support Vector Machine,SVM),BP 神经网络以及逻辑回归都曾先后用于股票的预测。彭燕等[1]用LSTM对股票进行了良好的预测,但LSTM因遗忘门的存在将先前的股票数据保留一部分对未来股票价格进行分析预测从而具有滞后性,使得预测结果整体后移,增加了实验误差。张晨希等[2]采用支持向量机的方法对股票建立了预测模型,但是其并未对支持向量机的参数进行优化。而在缺失数据的情况下,支持向量机会变得敏感,影响输出结果。在复杂的特征以及大量数据下这些单分类器模型并不能对股票预测取得良好的效果。集成学习是一种多分类器学习方法,在面对复杂的股票数据,单分类器因分类结果单一而导致误差更大。随机森林[3]作为一种分类和回归的集成学习算法在不同的领域中分别取得了不错的效果[4-9]。随机森林采取Bootstrap抽样法。通过多轮抽样,生成k个数据集并构成含有k棵决策树的随机森林。随机森林通过其随机性使得其不易陷入过拟合并降低敏感数据对实验预测结果的影响。曹正凤等[10]利用随机森林对优质股票进行选择,但没有考虑无关特征对选股的影响。根据文献[11-12]可知,在对股票进行回归预测时为了减少数据复杂度以及降低无关变量因素对实验预测的影响,首先需要建立初始指标体系进行相关性筛选,将筛选完成后的指标体系放入随机森林中进行训练得出结果。Nesselroade 等[13]对相关系数进行了详细的描述。相关系数是用来判断两个变量是否具有相关关系及其关系的密切程度。相关系数描述的变量是随机变量,且变量之间不必区分因变量和自变量。而回归系数则是研究因变量和自变量,并用该系数拟合一元或多元线性回归。相关分析是回归分析的基础,当相关关系很低时,则对两个变量进行分析是没有实际意义的。股票价格呈现非线性趋势波动,而股票的指标特征与股票价格预测存在相关关系的强弱,即股票指标特征对价格预测的贡献程度存在差异。特征方法选择主要有Pearson 系数、Spearman系数和Kendall 系数。但由于股票价格是定比数据变量。Spearman 系数和Kendall 系数都适合于定序变量或是间隔相同的时点数据,且Kendall 相关系数是用来对分类变量进行相关性的检验。Pearson系数是用来分析特征与响应变量相关关系程度的大小。股票价格的涨跌情况作为响应变量,且不具备等级相关程度,Cai等[14]利用Pearson 系数来衡量变量之间的线性相关关系,从而筛除影响因素。因此选择Pearson 系数对股票特征选择。
但随机森林中决策树的参数以及决策树的棵数将会直接影响特征重要性排序以及股票价格的预测结果。庄进发等[15]以及Genuer[16]对随机森林的最大特征数选取进行了实验,研究了最大特征数对随机森林的影响。网格搜索法通过对超参数范围的设定,将所有参数组合进行循环迭代组合,通过穷举法对所有参数进行评分从而寻得最优参数。网格搜索法不会遗漏掉任何参数组合,但在大量参数组合情况下,网格搜索法运算速度将会降低,因此本文在原有基础上对其进行改进,提高了参数寻优的速度。
因此,本文在原有的随机森林的回归算法基础上进行改进,将Pearson系数和改进网格搜索法相结合,提出了一种新的随机森林算法——基于Pearson相关系数的随机森林算法。首先,利用Pearson 进行第一次特征筛选,选择出与股票价格相关性强的因素,将无关因素删除。其次,利用改进网格搜索法找寻出决策树的最优参数并通过对随机森林的各项重要指标进行逐步测试,如决策树的棵数以及树节点的最大特征数并对特征进行重要性排序;然后,将剩余变量进行建模,组成改进的随机森林对股票价格的预测模型;最后,将改进的随机森林与其他模型在预测值的平均绝对误差(MAE)、均方误差(MSE)进行对比分析。
1 实验方法理论
1.1 Pearson系数结构原理
Pearson相关系数是用来衡量自变量与因变量之间的相关程度的大小,其值介于−1 和1 之间,其绝对值越大,相关性则越强。皮尔逊相关系数大于0 代表正相关,小于0代表负相关。其公式为:

其中,xi是自变量,yi是因变量。
1.2 决策树结构原理
决策树(Classification and Regression Tree,CART)是一种单分类回归器的归纳学习算法,由根节点、叶子节点以及非叶子节点组成。决策树通过对训练集进行回归分析,生成从根节点到叶子节点的路径并分析出路径规则。根据路径规则对新数据进行分类或预测。CART是基于信息熵,通过Gini系数最小原则指标来进行节点分裂,对训练集D={(x1,y1),(x2,y2),…,(xn,yn)}的输入空间划分区域,递归地将每个样本划入相应的区域并得出确定的输出值,其算法步骤如下:
(1)假设自变量特征为j,该特征的取值为s。假设取值s将特征j的空间划分两个区域,其式如下:

(2)依次遍历计算每个切分点(j,s) 的损失函数(Loss Function,LF),并选取损失函数最小的切分点。

其中,c1、c2分别为R1、R2区间内的输出平均值。
(3)将划分的两部分进行计算切点,依次进行,直到不能继续划分。
(4)将输入空间划分成M个部分R1,R2,…,RM生成最终的决策树为:

1.3 随机森林结构原理
随机森林是一种集成学习算法,由多个弱分类器组合成一个强分类器。随机森林利用bootstrap 对训练集采取随机有放回地抽取m个样本,并在bagging的基础上对每棵决策树进行随机特征的选择。将这m个样本建立m个决策树模型。最终,通过这m个决策树模型进行投票得出结果。随机森林具体算法步骤如下:
(1)输入训练集D。
(2)利用bootstrap抽样形成k个训练子集Dk。
(3)从原始特征中随机抽取m个特征。
(4)对训练子集Dk进行训练,将随机选择的m个特征做出最优切分,得出k棵决策树预测结果。
(5)根据k个预测结果进行投票得出票数最高的预测结果。
2 基于特征选择的随机森林模型
随机森林是一种容易受自身参数以及特征变量影响的机器学习算法。为提高随机森林的预测效果,本文将特征方法选择与改进网格搜索法相结合。先利用Pearson 特征选择删除无关数据特征,利用改进的网格搜索法对决策树的参数进行调优,通过优化后的k棵决策树所构成的随机森林来得到预测结果。其算法过程如图1所示。

图1 基于Pearson特征选择的随机森林模型Fig.1 Random forest model based on Pearson feature selection
2.1 相关性分析
利用Pearson 系数对所有解释变量进行划分,找出解释变量中的高度、中度、弱以及无关变量。(特征变量的Pearson系数大于0.8为高度相关,介于0.5到0.8之间为中度相关,在0.3与0.5之间为弱相关,小于0.3为几乎不相关。)
本文将前一天的OPEN、PP等指标因子作为解释变量,当天的收盘价作为被解释变量,利用Python 语言进行Pearson 相关性的检测,得到解释变量与被解释变量的相关性结果,然后根据Pearson 系数的大小来判定解释变量与被解释变量之间的相关性强弱,以今世缘为例,其系数结果如表1所示。

表1 今世缘Pearson相关系数Table 1 Pearson’s temporal correlation coefficient
根据相关性大小,BUYVOL和RF为几乎不相关变量,说明该两种解释变量与被解释变量收盘价没有直接或间接的必要联系。为了避免因指标太多从而使随机森林的计算时间增加且无关变量对实验精确度的影响。从指标变量中剔除与收盘价不相关的RF 和BUYVOL特征变量,将剩余变量作为模型的最终解释变量。
2.2 改进网格搜索法优化
网格搜索法是对指定的参数值进行穷举寻优,将指定参数通过交叉验证进行评估来得到最优参数的方法。在传统的网格搜索法的基础上,先对参数进行大范围的区间划分,选取出最优点,在最优点处进行小范围的参数调优,直至寻找出最优点。对决策树的深度,节点最小分割样本以及节点最小样本量进行参数调优,网格搜索法如图2所示。

图2 改进网格搜索法参数选择和模型评估Fig.2 Improved grid search method parameter selection and model evaluation
2.3 Pearson特征选择模型参数优化及分析
输入筛选后的解释变量,根据解释变量的数量,对决策树的max_depth、min_samples_split、min_samples_leaf三个参数进行取值范围设定并依次进行组合。
通过改进的网格搜索法先对参数进行大步长网格寻优,在评分最优点处再进行小步长划分网格寻优,重复此步骤直至寻找到最优参数组合。
利用改进网格搜索法,用损失函数评价出最优的参数。搜索出最佳参数组合并以此参数生成决策树。改进网格搜索法使运算速度提升,其运算时间对比如表2所示。

表2 搜索时间比较Table 2 Comparison of search times
在确定好决策树的最优参数之后,利用随机森林的袋外误差分数来进行来寻求随机森林最大的决策树棵数和树节点的最大特征数,并对剩余的特征进行重要性排序,以便于投资者后期根据不同的解释变量来进行股票投资。今世缘模型的随机森林的最大特征数和最佳棵数分别为如图3和图4所示。
通常情况下,当特征数数量为M时,max_features取值为在图3 中,最大特征数为4 时,OOB袋外分数最高,所以寻得最大特征数为4。通过实验,图像化地展示了袋外分数与n_estimators的关系。通过图4 可以观察出,在n_estimators 大于260 之后,随机森林的袋外分数逐渐趋于平稳且趋于0.75,误差逐渐降低且袋外分数较高。根据目前的学术研究来看,n_estimators大于100较为合适。根据本文的研究数据,当n_estimators取值为300时符合当前的研究,所以寻得决策树的数量为300棵对本实验来说较为合适。

图3 最大特征数Fig.3 Maximum characteristic number
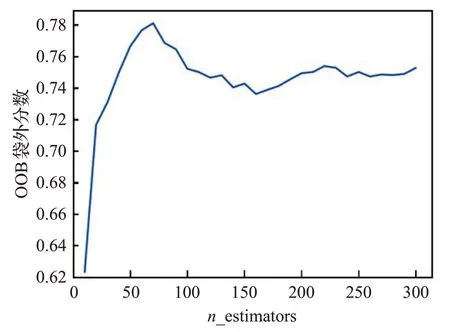
图4 决策树的最佳数量Fig.4 The best number of decision tree
根据决策树的max_depth、min_samples_split、min_samples_leaf的参数以及随机森林中决策树的棵数和最大特征数,将数据进行训练,得到今世缘股票特征重要性排序结果,如图5所示。

图5 特征重要性排序Fig.5 Feature importance ranking
3 实验结果
为更好地验证特征选择的随机森林模型对股票的预测。本文分别从白酒行业、保险行业以及房地产行业选取了今世缘、中国平安和上海临港三只股票进行预测。选取2019 年9 月1 日到2019 年9 月30 日的数据作为训练样本,2019年10月1日到2019年10月31日的数据作为预测样本。
3.1 今世缘预测
今世缘参数指标如表3所示,其实验结果如图6,绿色实线代表真实值,红色实线代表预测值。通过图6的预测结果显示,机器学习方法相比于传统的金融拟合方法要好。几何布朗运动对于股票的价格波动是不会随着时间的变化而变化的,而随机森林、支持向量机等监督类学习算法,能够良好地跟随股票的波动,受股票波动的影响较小。并且几何布朗运动的随机过程St在实际情况下并不符合正态分布,股票的真实收益具有更高的峰度,所以价格波动将会更大。支持向量机的模拟曲线较为良好的符合股票的实际趋向走势,但是具有一定程度上的误差性和滞后性。这是因为SVM对数据非常的敏感,在股票价格的分析特征中,部分特征对股票价格的预测产生不利影响,从而导致支持向量机的预测效果不如随机森林。而经过特征方法选择改进之后的随机森林模型在股票的模拟走势上因删除无关变量对实验预测的影响以及对随机森林的参数进行调优,使得缩小了误差。由于随机森林通过对股票特征重要性的排序并以前一天的数据作为训练集从而不受之前数据集的影响,使得滞后性减弱,更接近股票的真实走势。对时间序列的股票进行预测时,因可利用Pearson 系数对与时间序列无关的变量以及产生消极影响的变量删除的特点,因此Pearson 系数的随机森林更合适。经过改进的随机森林在价格波动上更小,可以使预测价格更好地接近于实际价格,使投资效用达到最大,投资风险降低相比单一的随机森林,改进后的随机森林能够在短时间内进行较好的预测,预测的结果具有较好的跟随能力。为了进一步比较改进后的随机森林和逻辑回归以及其他两种算法对模型拟合的准确性和有效性,分别选取均方误差(MSE)、平均绝对误差(MAE)来进行比较:

图6 今世缘各模型预测结果比较Fig.6 Comparison of prediction results of each model of King’s Luck

表3 今世缘参数指标Table 3 Parameter index of King’s Luck
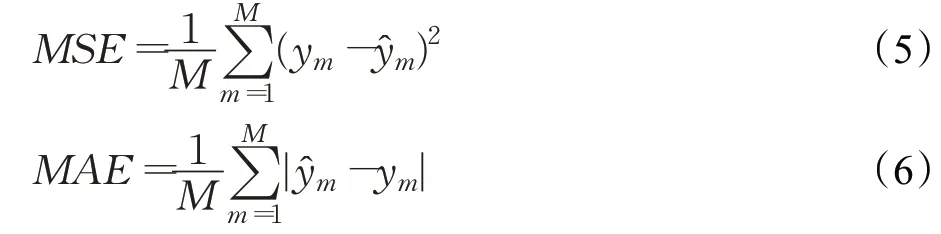
其中,ym是股票价格的真实值,是股票价格的预测值。
四个算法模型的MSE、MAE比较如表4所示。

表4 今世缘各模型预测指标对比Table 4 Comparison of prediction indexes of each model of King’s Luck
MSE 是用来评价股票价格的变化程度,即进一步反应股票的预测程度,MSE越小,则说明预测的精确度越高。MAE 则是更好地反映出预测值的误差程度,即进一步反应股票的预测价格与实际价格的误差,MAE越小,则说明股票价格的波动误差率越小。观察表4的预测指标对比结果和图7误差率对比结果发现,改进后的随机森林在MSE和MAE中都是最小的,即说明其在预测股票的涨跌中预测得最为精准且价格的波动误差率最小。而与传统的几何布朗运动相比,改进的随机森林算法的MSE 和MAE 值都有显著减小。与一般的机器学习相比,MSE 和MAE 也都有较好的改观。说明改进后的随机森林使得股票的预测效果相比传统的金融方法和一般的机器学习方法有了显著提高。改进后的随机森林的两项指标优于传统随机森林模型,但两者的差距并不明显,原因在于两者具有相同的基础单元结构——决策树,而改进后的随机森林的优势在于减少无关变量,降低其对股价预测的影响并通过网格搜索法实现决策树以及随机森林的最优调参,而且运行时间和预测结果都要好于随机森林。

图7 今世缘随机森林与Pearson-随机森林预测结果比较Fig.7 Comparison of prediction results between King’s Luck random forest and Pearson-random forest
3.2 中国平安预测
中国平安的参数指标如表5。各模型预测结果比较如图8所示,支持向量机在股票价格持续下跌或持续上涨时跟随性较好,而在股票价格发生大幅度变化时其跟随能力远不如随机森林和Pearson-随机森林。随机森林和Pearson-随机森林在股票的实际走势上基本一样,但改进后的随机森林在时间点上的误差要小于随机森林。随机森林的模型要优于几何布朗运动模型,逻辑回归模型以及SVM模型。但是在中国平安股票的预测模型中,Pearson-随机森林模型的预测效果最好,其预测值更好地逼近真实值。该股票的指标评价标准如表6 所示,Pearson-随机森林模型的评价指标结果均优于其他模型。

表5 中国平安参数指标Table 5 Parameters index of Ping An of China

图8 中国平安各模型预测结果比较Fig.8 Comparison of prediction results of each model of Ping An of China

表6 中国平安各模型预测指标对比Table 6 Comparison of prediction indexes of each model of Ping An of China
改进后的随机森林与随机森林的进一步比较如图9所示。
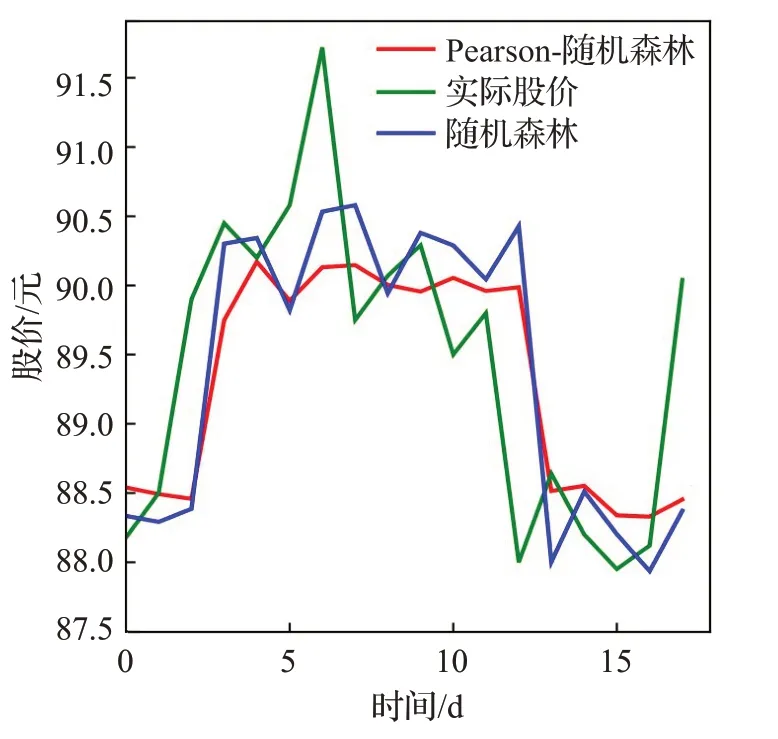
图9 中国平安随机森林与Pearson-随机森林预测结果比较Fig.9 Comparison of prediction results between China Ping An random forest and Pearson-random forest
3.3 上海临港预测
为进一步验证Pearson-随机森林对个股的实验效果,选取房地产业的上海临港进行实验,其参数指标如表7所示。

表7 上海临港参数指标Table 7 Parameters index of Shanghai Lin-Gang
实验结果如图10 所示,几何布朗运动在前期的跟随能力较好,而后期的跟随能力较差,对股票的预测走向也没有跌落的现象,出现了极大的预测偏差。支持向量机和逻辑回归在股票价格的拐点预测能力相相比随机森林要较差。原因在于SVM 对部分数据极为敏感,当碰到实际情况发生变故时,SVM 的预测能力便不如随机森林稳定。Pearson-随机森林使原始随机森林在拐点处价格的预测变得更加精准。相比于其他的预测模型,Pearson-随机森林在上海临港股票的预测中仍表现较好。该股票的评价指标如表8所示。Pearson-随机森林的MSE和MAE略好于传统随机森林,说明改进后的随机森林在预测误差上要优于传统随机森林。其进一步比较结果如图11所示。

图10 上海临港各模型预测结果比较Fig.10 Comparison of prediction results of each model in Shanghai Lin-Gang

图11 上海临港随机森林与Pearson-随机森林预测结果比较Fig.11 Comparison of prediction results between Shanghai Lin-Gang random forest and Pearson-random forest
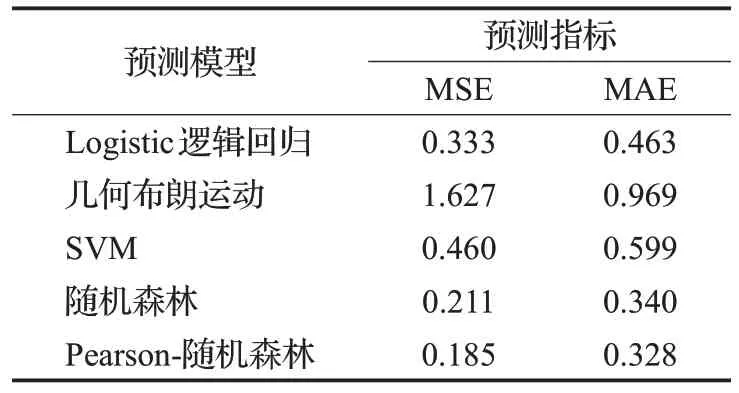
表8 上海临港各模型预测指标对比Table 8 Comparison of prediction indexes of each model of Shanghai Lin-Gang
3.4 上证指数预测
为了减少个体股所带来的偶然性和随机性,更好地验证特征选择的随机森林模型的优越性,本文选取上证指数对股票进行进一步预测。其参数指标如表9。

表9 上证指数参数指标Table 9 Shanghai Index parameters indicators
实验结果如图12 所示,几何布朗运动在前期预测方向与实际方向相反。原因在于上证指数是以上海证券交易所所有股票数为样本,通过计算样本股在基期和计算期的总市值,并按照指定常数将计算期总市值与基期值相比得出。支持向量机预测跟随力不如个股,这是因为指数价格较高,对数据的归一化处理以及其核函数无法良好的对高价格进行跟随预测。

图12 上证指数各模型预测结果比较Fig.12 Comparison of prediction results of each model of Shanghai Index
指数价格的评价指标如表10所示,Pearson-随机森林的指标要明显地优于其他预测模型。其与随机森林的比较如图13所示。

表10 上证指数各模型预测指标对比Table 10 Comparison of prediction indexes of each model of Shanghai Index

图13 上海指数随机森林与Pearson-随机森林预测结果比较Fig.13 Comparison of prediction results between Shanghai Index random forest and Pearson-random forest
3.5 沪深300预测
为了进一步减少实验带来的随机性与误差性,选取沪深300 指数来进一步验证基于Pearson 特征选择的随机森林模型的普遍适应性。参数指标如表11所示。实验结果如图14所示。

图14 沪深指数各模型预测结果比较Fig.14 Comparison of prediction results of each model of Shanghai and Shenzhen Index

表11 沪深指数参数指标Table 11 Shanghai and Shenzhen Index parameters indicators
几何布朗运动的后期预测较好,但前期预测走向与沪深300 指数的走向相反,这是由于沪深300 是选取的上交所以及深交所中重要的股票编制而成,反映的是上交所以及深交所大盘的整体走向,而支持向量机对其预测跟随更为平缓且跟随能力差。这是由于沪深300指数价格较高,且选取的不再是个股,支持向量机核函数导致其预测跟随能力远不如个股。而随机森林虽在前期产生了较大的误差,但其中期跟随能力较好。Pearson-随机森林使得后期价格的预测误差变小。沪深300 指数的价格评价指标如表12 所示。Pearson-随机森林的MSE和MAE指标要优于未改进的随机森林和其他的机器学习及传统金融模型。为更直观地观测Pearson-随机森林与随机森林的预测结果,其比较图如图15所示。

图15 沪深指数随机森林与Pearson-随机森林预测结果比较Fig.15 Comparison of prediction results between Shanghai and Shenzhen Index random forest and Pearson-random forest

表12 沪深指数各模型预测指标对比Table 12 Comparison of prediction indexes of each model of Shanghai and Shenzhen Index
3.6 实验数据对比
彭燕等[1]利用LSTM 神经网络对美国的苹果公司进行了股票价格的预测,宋刚等[17]通过基于粒子群的LSTM 对五粮液进行了股票的模拟走向。为了进一步增加实验的可行性,在原有三支股票的基础上选取A股的五粮液和美股的苹果进行Pearson-随机森林实验并与两篇文章利用LSTM 取得的实验结果进行数据对比。
Pearson-随机森林与彭燕等[1]在单层LSTM 网络模型下取得的效果相比指标数据得到良好的改进,预测精度远高于单层LSTM,原因在于LSTM 具有滞后性,从而导致预测结果向后偏差使得误差偏大。而与两层的LSTM 网络模型相比,Pearson-随机森林在MSE 上略优于LSTM,而在MAE 中所取得的效果不及两层LSTM网络模型的效果。相比MAE,MSE 更能反映价格波动的大小,其更能反映出价格的误差大小。其数据对比如表13所示。

表13 实验数据对比(苹果)Table 13 Comparison of experimental data(Apple)
Pearson-随机森林与宋刚[17]的原始LSTM 相比取得了较为良好的效果,也再一次证明了改进后的随机森林相比一般情况下的LSTM 网络模型来说是有更加良好的效果。其实验数据对比如表14所示。

表14 实验数据对比(五粮液)Table 14 Comparison of experimental data(Wuliangye)
4 结束语
本文使用Pearson系数相关性检验以及随机森林算法对股票价格的趋势进行实验研究。利用改进网格搜索法对决策树的参数进行调优并提高了调优速度。用随机森林的重要性排序筛选出了在市场上影响股票因素的重要市场因子。两种方法的结合以及对参数的优化使得预测效果得到提高。该组合算法在对股票的短期预测上具有良好的效果、精确度较高,能够达到让人满意的预期收入。此外,该方法还同样适用于其他的股票价格预测,从而验证了该方法在实际应用中具有一定的有效性和实用性。
在时代飞速发展的今天,行业的发展在不断地变化,黑天鹅事件的产生越来越多,一件小的黑天鹅事件将会产生巨大的影响。因此,在日后对股票的分析中,如何降低时间序列的噪声将是今后的研究重点,如何更好地及时预测黑天鹅事件对股票走向的影响将显得尤为重要。
