颜色模型扰动的语义对抗样本生成方法
2021-08-06王舒雅刘强春陈云芳王福俊
王舒雅,刘强春,陈云芳,王福俊
1.南京邮电大学 通达学院,江苏 扬州 225127
2.南京邮电大学 计算机学院,南京 210023
3.南京航空航天大学 计算机科学与技术学院,南京 211106
大数据应用时代,人工智能技术[1]再次成为学术界和工业界关注的焦点。人工智能的实际应用离不开深度学习的发展。目前,深度学习采用的模型主要是神经网络模型,最先进的卷积神经网络对于图像中物体的分类正确率甚至超越了人眼的识别率,但是近些年也有研究表明,训练完好、泛化能力较强的的卷积神经网络易受对抗样本的干扰,致使其在分类预测阶段产生很大的分类偏差。这一有趣的现象首次被Szegedy 等人[2]发现,在干净的图片样本上加入人为设计的微小扰动向量时,便会使模型产生误分类。随着对该现象研究的不断深入,发现不仅卷积神经网络会遭受到对抗样本的影响,很多机器学习模型也会被对抗样本“攻破”。因此,对抗样本威胁了人工智能的落地应用。尤其是在计算机视觉领域,为了获得更好的表征学习能力,都会选用卷积神经网络作为基础特征提取模型,但却给攻击者留下了攻击空间。一方面,运用卷积神经网络提高了社会服务水平,帮助人类更好的生活;另一方面,卷积神经网络本身的脆弱性,使得对抗样本可能对模型产生攻击。为了解决这两者之间的矛盾,研究对抗样本的生成方法具有重要意义。
目前对抗攻击方法大部分局限于寻找基于梯度迭代的对抗扰动,以此最大化模型的预测损失,致使模型分类错误。但是此类对抗样本正被越来越多的防御策略“狙击”,模型的鲁棒性也在显著提升。针对这一问题,本文跳出传统构造扰动的对抗框架,提出一种基于图片语义信息的对抗样本生成方法。该方法利用人类视觉认知系统和卷积神经网络在物体识别过程中体现的形状偏差特性,将RGB 颜色模型下的图片扰动变换至CMY 或HSI 颜色模型下,该转变过程称之为对抗变换。经过对抗变换生成的对抗样本不会限制图像修改的像素数量,但是可以很好地保留图片的语义信息,不影响人眼的再次识别。该方法是一种黑盒攻击方法,其不需要目标模型的网络参数、损失函数或者相关的结构信息,在样本生成过程中,其仅依靠颜色模型的变换和颜色通道的随机扰动,避免了以往黑盒攻击存在的劣势。
1 研究背景
1.1 对抗样本的攻击
对抗样本(adversarial example)是指在原数据集中通过人工添加肉眼不可见或在经处理不影响整体的肉眼可见的细微扰动所形成的样本,这类样本会导致训练好的模型以高置信度给出与原样本不同的分类输出[3]。
对于对抗样本的生成,最直接的方法是通过解决约束优化问题迭代生成对抗扰动,从而最大化模型的预测误差。目前,学术界提出了多种对抗样本的生成方法,表1对比了六种常用的对抗样本生成方法。

表1 六种对抗样本生产方法的对比Table 1 Comparison of six adversarial examples production method
攻击的类型多种多样,从不同角度出发,对抗样本的攻击可以分为不同种类。
从对抗样本是否需要指定攻击的类目出发,攻击可分为:无目标攻击和目标攻击。(1)无目标攻击:不指定具体类目,只要能够让模型识别错误即可。(2)目标攻击:不仅需要模型能够识别错误,还要能够错误分类到指定类别。
从对抗样本是否知道模型的具体细节(例如网络结构、模型参数等)出发,攻击可分为白盒攻击和黑盒攻击。(1)白盒攻击:攻击者能够获取到模型的所有信息。(2)黑盒攻击:攻击者无法获取到模型的任何信息,只能参考模型对于图片的输出标签来生成对抗样本。
1.2 颜色模型
颜色模型是计算机科学解释和表示自然界色彩的方法。根据不同研究场景,确立了不同的模型标准。一般情况下,一种颜色模型用一个三维坐标系和一个子空间来表示,所有坐标值都限定在[0,1]之间,每种颜色是这个子空间的一个单点,颜色模型也称为彩色空间。
1.2.1 RGB颜色模型
在图像处理任务中,图像的颜色信息最开始都是用RGB 颜色模型表示的。红(Red)、绿(Green)、蓝(Blue)作为该颜色模型的三基色,可以将三基色按一定比例叠加产生新的颜色。
1.2.2 CMY颜色模型
CMY是另外一种颜色模型,其分别代表青色(Cyan)、品红(Magenta)、黄色(Yellow)三种油墨色。CMY 颜色模型与RGB 颜色模型之间可以通过简单的转换得到,假定所有的颜色值都已归一化到[0,1]范围,具体转换如下式:

1.2.3 HSI颜色模型
不同于RGB颜色模型,HSI颜色模型更符合人的视觉系统感知色彩的方式,以色调(Hue)、饱和度(Saturation)和亮度(Intensity)三种基本特征量来表示颜色。Hue 是色调,表示颜色在人视觉上的感受,如红色、绿色、蓝色等,它也可以表示一定范围的颜色,如暖色、冷色等。S是饱和度,表示颜色的纯度。I是亮度,对应颜色的明亮程度。
在HSI颜色模型的三个分量中,图像的彩色信息不受I分量影响,而H和S分量会影响人对于颜色的视觉感受。HSI 颜色模型和RGB 颜色模型只是同一物理量的不同表示方法,因而它们之间存在着转换关系,RGB转换为HSI的公式如下:


1.3 常见对抗样本生成方法
Szegedy 等人[2]首次提出了对抗样本现象并且设计了L-BFGS 方法,通过简单的最优化过程,对一个能够正确分类的输入图像作微小扰动。这种方法是通过优化遍历流行网络表示并在输入空间中发现对抗样本,然而对抗样本存在流行空间中的低概率区域,因此很难通过对输入点附近简单的随机采样获得。基于对抗样本现象,以限制扰动向量维度的攻击方法被逐渐提出,其中包括I-FGSM[9]、梯度下降映射法[10](Projected Gradient Descent,PGD)和C&W 攻击[11]。这些经典的对抗样本生成方法大都将扰动来源限制在损失函数或者目标函数的梯度上,这样可以增大模型对于样本的预测误差,实现有效地攻击。针对此类样本带来的威胁,研究者根据扰动向量生成的相关特性,提出了防御策略。Song等人[12]提出了输入重构方法,其利用PixelCN 网络将恶意的对抗样本数据转化为自然样本数据,使得对抗样本重新回到训练样本集的数据分布状态。Papernot等人[13]提出防御蒸馏型网络,首先通过训练集训练出一个基础网络,然后利用基础网络的预测输出作为样本标签训练第二个网络,最后利用两个网络进行综合预测。Huang等人[14]提出的对抗训练也能有效地提升模型的鲁棒性,降低对抗扰动对模型的干扰。除了上述的对抗攻击方法,Engstrom等人[15]提出对原始图片的对抗性平移和旋转可以愚弄卷积神经网络,但是旋转后的图片在人眼看来并不自然;Brown 等人[16]提出了对抗性补丁方法,该方法需要额外生成补丁,并将补丁打在干净图片上,导致原图的部分内容被遮挡,影响视觉效果。Zhao等人[17]利用生成对抗网络(Generative Adversarial Networks,GANs)来生成对抗样本,首先在数据集上训练WGAN,其中生成器部分用于对抗样本的生成,将高斯噪声图片输入到生成器中,在视觉上可以得到与目标图片相似的对抗样本。此外,还训练了一个转换模型,用来衡量对抗样本和目标图片之间的误差,并将误差传递给需要优化的生成模型。虽然,在视觉上利用模型生成的对抗样本更加自然,但是模型的设计和训练耗时较多,且需要大量的数据支撑。与此类似,Papernot 等人[18]为了提升对目标模型攻击的成功率,用相同的数据集训练可替代模型,并依据可替代模型的相关参数及结构信息构造对抗样本,最后完成对目标模型的攻击。这个过程同样也是耗时的,并且可替代模型只是做到了近似,和目标模型在决策边界上仍然存在很大差距。Brendel 等人[19]提出了一种基于边界的对抗样本生成方法,首先找到一个不限制阈值大小的对抗样本,然后依据一定的策略将该样本沿着原本的方向移动,直到该对抗样本离原样本最近,但依然保持对抗性。此过程需要不断地查询网络模型的类别输出,但在现实攻击环境中,这种查询手段会被限制,因此该攻击方式不具备通用性。
可见,现存的对抗攻击方法由于被防御策略“狙击”而限制了攻击能力;而攻击能力较强的方法会对原始图片做大幅修改,甚至出现了伪影和遮挡物,严重影响了视觉效果;利用模型产生的对抗样本需要花费大量精力做数据支持和模型训练。因此为了避免这些方法中的缺陷,本文不再利用目标模型的相关结构和参数信息,立足于图像色彩空间提出了基于图像语义信息的对抗样本生成方法。这种方法利用人眼视觉识别中的形状偏向特性,仅通过扰动图片在颜色模型下的色彩通道来生成对抗样本,该方法可以完好地保留图片的语义信息,在不影响感官识别的情况下对模型实现黑盒攻击。
下式定义了通过图像对抗变换生成语义对抗样本的问题:
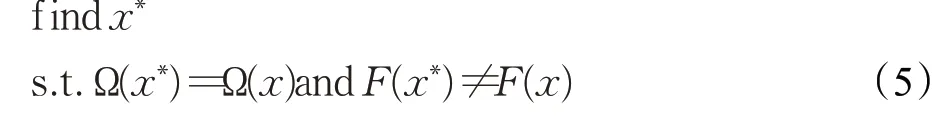
其中,Ω(⋅)表示人类视觉系统产生的视觉标签,F(⋅)表示模型给出的标签,生成的对抗样本需要保持原始语义信息不变。因此人眼能够准确识别出目标物体,但此类样本依然会导致目标模型产生误分类。此问题可以看做是在保持原始图像视觉标签的情况下,将任何一张给定的图像变换到致使模型错误分类但包含原始图像内容的自然图像空间。这种对抗转换在不知道目标模型内部细节参数的情况下可以完成有效的黑盒攻击,并且可以避开最先进的防御策略,对进一步提升模型的鲁棒性提供了参考。此外这种新的对抗样本生成思路有助于进一步揭示卷积模型和人类视觉系统的相似性,也有助于分析模型泛化性能的本质。
2 基于颜色模型的两种语义对抗方法
2.1 形状偏好特性的认知理论
人类视觉认知和卷积神经网络的识别过程都表现出了相同的特性——形状偏好特性。在所有影响人类视觉认知的因素中,研究发现物体的形状是最关键的因素。卷积网络在特征提取过程中,利用多层卷积不断地提取图像物体的边缘轮廓信息,最后综合提取出的卷积映射图给出最后的分类决策。显然,物体的形状包含了更多有助于识别的语义信息。
形状偏好现象是人类认知发展过程中一个重要的现象,其对人类的学习和思维能力的培养都产生着巨大的影响。研究者们分别在词汇学习任务、分类任务和归纳推理任务中研究了人类认知过程中的形状偏好现象。Landau 等人[20]通过实验说明了成人在分类任务中更偏向于将形状相似的物体归为一类,表现出形状偏好特性。
深度神经网络可以出色地完成一些诸如图像识别与分类、目标检测等复杂的实际任务,但是这些任务的完成需要依托复杂的模型结构,并且网络学习的解决方案也会变得更加不可解释。这样,网络既表现出在解决实际问题方面呈现出的性能优越性,又体现出了不可知性,整个网络是一个“黑箱”的状态。Ritter 等人[21]利用人类认知心理学的发展、研究和实验过程对神经网络的可解释性进行了探讨。认知心理学方面的研究表明,学习新单词时人们倾向于为形状相似的物体而不是颜色、质地和大小相似的物体分配相同的名称。由于深度神经网络在一些特定任务中的表现可以和人类媲美,两者之间的关联也变得越来越紧密,因此可以通过人类认知心理学的视角解读神经网络,从而发现网络中隐藏的计算特性。
2.2 基于CMY变换的语义对抗样本
卷积神经网络可以在图像分类任务中表现出超越人类的特性,但是已被证明其易受到对抗样本的干扰。虽然添加了对抗扰动的样本图片和原始图片保持着相同的视觉标签,但是卷积网络却会以很高的分类置信度将其错误分类。现有的基于目标函数梯度且以增大分类模型损失函数为目的的对抗样本生成方法正被越来越多的防御策略“狙击”。因此,为了生成更具威胁性的对抗样本,从人类和模型在物体识别方面表现出的形状偏好特性出发,依据CMY颜色模型与RGB颜色模型的关联性,通过扰动原像素通道实现对抗变换,保持图片中的目标物体不变,仅仅修改了色彩通道信息,因此可以保留图片本身的语义信息。
通常情况下,一张图像会以RGB颜色模式表示,利用对抗变换技术将图片从RGB模式转换为CMY模式,转换以后的图片依然能够保持完整的语义信息。从RGB 和CMY 颜色模型的转换公式可以看出,CMY 颜色模型下的各个通道相当于RGB的“负”向转换。那么给定一张原始的干净图片样本X,其中Xi,n∈[0,1]表示第n个颜色通道的第i个像素点,在RGB 颜色模型下,n为3 表示有三个通道,每个像素点都被归一化到区间[0,1]。因此,基于CMY变换的语义对抗样本可以定义为,在转换过程中,原像素较亮的地方会变得暗淡,较暗的地方会变得光亮。由于这种对抗变换对原始颜色通道做了大幅修改,因此转变过后的样本不需要增加额外的色彩偏移扰动就可以完成对抗攻击。
图1 展示了对抗转换过程,整个过程分三个阶段。首先分离RGB 颜色模型下的通道,然后将各自通道转换成CMY 颜色模型下的表示,最后进行通道合并。不同于以往对抗样本需要寻找到尽量小的对抗扰动,该方法更关注图片的语义表示。对抗变换会在原始图片上带来较大的颜色改变,但不影响人眼的识别。
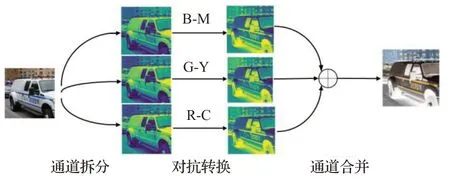
图1 CMY对抗样本生成框架Fig.1 CMY adversarial example generating framework
2.3 基于HSI变换的语义对抗样本
在众多颜色模型中,HSI颜色模型更容易被人类视觉所理解和感知,因此本文将在HSI颜色模型中进一步研究对抗变换方法。在该模型中色调与饱和度分量都能较大程度地影响图像的颜色,而亮度分量在模型中的作用是保持图像内容的完整性,即保持图片内物体的主要形状特性,因此将亮度分量从色调和饱和度分量中分离出来。为了生成符合人眼视觉语义理解的对抗样本,本文通过仅改变色调和饱和度信息的方式来改变图片的色彩,分别使用xH、xS和xI来表示一张图像的色调、饱和度和亮度分量。对于一张给定的图片,将其从RGB颜色模型变换到HSI模型,并且采用迭代的方式扰动色调和饱和度分量,扰动次数的增加会带来色彩偏移量的增加,并且修改了图像本身的像素信息。从卷积模型本身设计的局限性[22]可知,模型只拟合了图像空间的部分数据空间,而扰动使得对抗样本超出了模型对训练集数据分布的拟合范围。另外卷积模型只关注图片本身的数字统计特性[23],而没有真正学习到图片本身的语义概念,因此这两个分量的色彩偏移量使得它能够愚弄分类模型。基于HSI颜色变换的语义对抗样本定义如下:

在对抗样本生成过程中通过保持I分量不变来确定图片的语义信息,并且随机扰动色调和饱和度部分。这样修改后的图片虽然能成功愚弄分类模型,但是对抗样本却携带了大量的可视化噪声,使得人眼视觉不够平滑和自然。为了得到更加自然的对抗样本,将所有像素的色相和饱和度分量偏移相同的量。但是在显著增加饱和度分量时,对抗样本将过于色彩化,在显著降低饱和度分量时,对抗样本又会变成灰度图像。为了控制饱和度分量的变化,将对抗样本定义为解决如下问题:

其中,δH和δS都是标量,色调分量的变化呈现圆周式,即色调1 等于色调0。因此本文将色调分量对1 取模,将其映射到[0,1]之间,饱和度分量也会被裁剪限制在[0,1]之间。为了使扰动向量尽量微小且没有突出异常值,将从正态分布中产生δH和δS的随机扰动量。
算法1基于HSI颜色空间的对抗样本生成算法。

该算法已知一个待攻击目标分类模型F,干净的图片样本x和算法的迭代次数N。首先将处于RGB颜色模型下的干净图片转换到HSI颜色空间,并分别将色调(H)、饱和度(S)、亮度(I)分量赋值给xH、xS、xI。在每一次算法迭代过程中δH和δS均是可调参数,其中δH是从正态分布[0,1]中获得的扰动量,δS是从正态分布中获得的扰动量。根据获得的扰动量,在色调和饱和度分量上做相应的对抗变换,最后查询模型的输出是否改变了分类结果。若已经改变则返回对抗样本,若没有改变则进行下一次迭代直至达到迭代次数N。这种方法在攻击时不需要任何目标网络内部的参数或者结构信息,只需要查询样本的分类标签,因此该方法可以看做是黑盒攻击方法。
3 实验及结果分析
3.1 实验设置
数据集:采用CIFAR10数据集[24]作为攻击方法的测试集,由50 000张训练集图片和10 000张测试集图片构成。每张图片的大小是32×32×3,其包含三个颜色通道。具体地,CIFAR10 数据集含有10 个分类:飞机、轿车、鸟、猫、鹿、狗、青蛙、房子、船、卡车,每一种类别都是包括5 000 张训练图像和1 000 张测试图像。选取每个类别的测试集作为原始干净图像,通过本文提出的方法将这些图像变成具有攻击能力的对抗样本,随后在预训练模型上实施攻击,探测新方法的攻击能力。
模型:实验模型选用VGG16 网络作为目标攻击模型,其在CIFAR10数据集中得到了很好的预训练。如图2所示,网络共有5个卷积段,每个卷积段包含2至3个卷积层,每个卷积层都用3×3的小卷积来代替大卷积。这样在加深网络层数的同时可以尽量减少参数量,并且可以获得更大的感受野,提升模型特征提取能力。每个卷积段的结尾都会连接一个最大池化层来缩小图片尺寸,在模型的最后是3层全连接层,综合提取卷积层获得的特征,最后使用softmax 函数得到相应的类别标签。由于深度的增加和小卷积核的使用,VGG16网络可以在测试集上得到很好的泛化效果,实现很高的分类正确率。

图2 VGG16网络模型Fig.2 VGG16 network model
3.2 攻击能力评估
攻击分类模型并统计模型的分类正确率是测试对抗攻击的常用手段。因此,分别依据CMY 和HSI 颜色模型实施对抗变换,在CIFAR10测试集上生成相应的对抗样本,然后将对抗样本作为目标模型VGG16 网络的输入,探测模型的识别成功率。除此之外,还对基于对抗训练的VGG16模型的鲁棒效果进行了研究。本实验利用基于损失函数梯度扰动(FGSM)生成的对抗样本作为训练集参与模型训练,经过对抗训练的VGG16 网络对于该类扰动具备了很强的鲁棒效果。表2 直观地展示了VGG16预训练模型以及相应对抗训练模型在样本图片上的识别率,其识别率越低表示对抗样本具有更高的攻击成功率。

表2 模型分类识别率Table 2 Identification rate of model classification %
实验发现,Pretrained-VGG16网络在干净的测试集中获得了94.3%的识别率,同时经过对抗训练的Adversarial-VGG16网络也能获得90.7%的识别率,这表明基础模型是个训练得当的可测试模型,能保证一定的识别基准率。而当Pretrained-VGG16网络分别遭受CMY变换和HSI变换对抗样本的攻击时,其识别率大幅度下降,分别降至11.6%和5.4%。这说明经过良好训练并且在测试集上能获得较高识别率的模型并不能很好地泛化到语义对抗样本中。对抗样本在攻击拥有防御措施的Adversarial-VGG16 模型时,其识别率较干净测试图片也下降至12.3%和8.9%,可见这种防御策略给模型带来的鲁棒性只针对基于梯度的对抗扰动,而对于基于对抗变换生成的扰动策略,其没有防御能力。另外,本文还利用不同样本集对VGG16 模型进行迁移训练,图3 展示了模型在进行微调时,对抗样本量和模型识别率的关联性。
图3(a)展示了仅用CMY变换对抗样本对网络进行微调时模型的识别率。随着样本量的增加,模型对于CMY 变换对抗样本的识别率会显著增强,但是对于干净样本的识别率会有所降低,并且对于HSI-shifted的识别率基本保持不变。当仅用HSI-shifted对抗样本对模型进行微调时,图3(b)展现了相似的特性。图3(c)展示了使用CMY变换和HSI变换对模型进行微调后的结果,可以发现模型对两者的识别率均有提高,但是干净样本的识别率仍然会降低。当把两种类别的对抗样本和干净样本都用于模型的微调时,模型会在保持干净图片识别率的情况下提升对于对抗样本的识别率,如图3(d)所示。这表明网络模型只会对出现频率较高的样本空间做出更好的特征拟合,这无疑限制了模型的实际应用能力。

图3 CMY变换和HSI变换样本对网络进行微调Fig.3 CMY transform and HSI transform samples fine-tune network
3.3 迭代攻击次数N
扰动次数N在基于HSI变换的对抗样本生成中扮演重要角色,因此需要进一步研究扰动次数对攻击成功率的影响。实验仍然选用CIFAR10 的测试集作为干净样本,预训练的VGG16 作为待攻击的目标模型。由于实验测试集的原始图片尺寸为32×32×3,尺寸较小且待攻击模型是常见深度为16 层的卷积神经网络,因此实验中的最大扰动次数被设定为100次,在[0,100]的区间内观测对抗样本攻击成功率与迭代次数的关系。对抗变换在每一次扰动中,HSI 颜色模型下的H 和S 分量都会叠加随机扰动值并且保持I 分量不做变化,随机扰动值是来自正态分布产生的随机数,伴随着迭代次数的增加,图片的扰动量也会增加。在图4 中发现经过1 次扰动迭代后,数据测试集中将近15%的图片已经完成了对抗转换,成为了具有攻击能力的对抗样本,随着迭代次数的不断增加,对抗样本的攻击成功率也在稳步上升,直到迭代次数达到100时,对抗攻击成功率达到94.6%。可见,对抗样本的攻击成功率和实验的扰动次数关联很大,较多的迭代次数保证了较高的攻击成功率,但是随机扰动值的增加也会使得图像色彩的偏移性更大,而卷积模型在基于颜色通道扰动的对抗变换上也更容易表现出不鲁棒性。
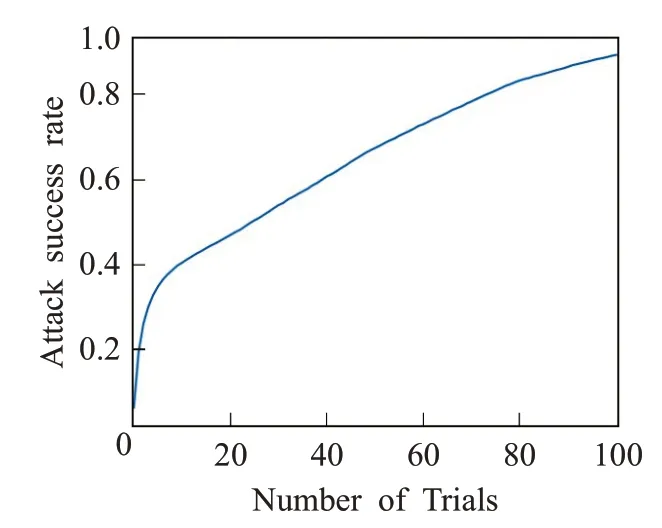
图4 迭代攻击成功率Fig.4 Iterative attack success rate
3.4 扰动因子δH 和δS
将图片转换到HSI颜色模型下,然后在H分量和S分量中不断增加扰动因子,扰动因子δH从正态分布[0,1]中取值,δS从正态分布中取值,其中N是算法总迭代步数,i是当前迭代值,用视觉效果展示扰动因子对于对抗样本的影响。从图5可以看出,原图片是一张船的图片,在H分量和S分量的叠加扰动下,原图经过不同的对抗变换生成不同的对抗样本。这些对抗样本虽然在感官上色彩不一,但仍然能识别出图片中船的模样,这说明经过对抗变换的图片仍然保留了语义信息。

图5 扰动因子对于对抗变换的影响Fig.5 Effect of perturbation factor on adversarial transformation
图片经过对抗变换,H分量和S分量的值变小时,图片会褪去鲜艳的色彩,对抗样本整体呈现出暗淡的黑白色;当两个分量的值越来越大时,对抗样本逐渐色彩鲜明化。另外,S分量的变化更受扰动因子δS影响,S分量的变化也更能影响人的视觉识别,因此在每次迭代扰动中,会将从正态分布获得的扰动值加在图片的每个像素值中,并且随着扰动次数i的递增,扰动值的获取区间也在不断增大,因此较容易得到偏移量更大的扰动值。扰动因子的这些限制使对抗样本不会出现较为突出的异常像素区域,在视觉上光滑的,且不影响人眼对图片物体的正常识别。
3.5 对抗样本视觉效果
图6 展示了利用对抗变换在CIFAR10 数据集上生成相应对抗样本的实例,图中的首行代表原始的干净样本,并配有相应的视觉标签,中间和末行代表利用CMY变换和HSI 变换方法生成的对抗样本。CIFAR10 数据集图片的大小是32×32,可视化分辨率较低,从图中可以发现基于颜色模型的对抗变换对于背景信息的修改相对较多,但是仍然较好地保留了图片中物体的形状特性,即保留了图片的语义信息,人眼在视觉上能够准确地识别出目标物。

图6 对抗样本视觉效果Fig.6 Adversarial sample visual effect
尽管卷积网络在干净样本上能获得较强的泛化性能,但面对语义对抗样本时却显得异常脆弱,表现出不鲁棒性。因此可以认为分类模型对于数据的学习过程是比较片面的,其只学习到了图像本身的数字统计特征,将数据的分布做了很好地拟合,但是并没有学到更加抽象的语义信息,在面对仍然保留了语义特征的对抗样本时就不能体现出泛化特性。其次和人类视觉认知过程类比,人类在进行识别时更多的关注语义之间的关联性,这有助于理解和识别物体,而卷积模型在识别过程中,通过卷积核提取图片的特征,然后将特征映射图进行叠加,这种映射叠加过程只考虑了数字层面的融合,并没有进一步考虑到特征图之间的语义关联性。
4 结论
本文利用对抗变换扰动颜色通道生成语义对抗样本,该对抗样本可以完成高效的黑盒攻击,卷积模型在本文的攻击策略上表现出不鲁棒性。通过攻击实验发现卷积模型在识别过程中不具备语义相关性弱点,因此模型只能学习到图片本身的数字特征和相关分布特性。语义模型的创新对于对抗样本的防御效果将是下一步的研究方向。另外,由于卷积网络不能很好地识别具有语义信息的图片,这也凸显出了网络本身的局限性。人类在对物体识别时会更加关注物体关键部位的信息,并根据其语义关联性做出综合判断,因此将进一步研究卷积模型在关键部位特征提取的能力和特征图高效利用方式来提升网络性能。研究新的网络结构不但有助于进一步解开网络模型的“黑箱”特性,还能够提升模型的鲁棒性,给模型的实际安全部署提供保障。
