基于粒子群优化的全比较计算数据分发策略
2021-08-06李雷孝王永生
李雷孝,邓 丹,李 杰,王永生
1.内蒙古工业大学 数据科学与应用学院,呼和浩特 010080
2.内蒙古自治区基于大数据的软件服务工程技术研究中心,呼和浩特 010080
全比较计算[1]是一种典型的计算模式,用于解决两两数据文件相关联的一类计算。全比较计算作为一类特殊的计算模式在众多学科领域中频繁出现,如:生物信息学[2-5]、生物测定学[6-8]、传统机器学习领域[9]、自然语言处理领域[10]、交通大数据领域[11]。
国内外学者针对全比较计算一直在开展研究,全比较计算是研究的热点之一。在国外,有学者曾将全比较任务所需的全部数据在分布式集群中的各个计算节点均复制一份[12]。这种分发方式适用于小数据量的情况,在面对海量数据时将造成严重的网络拥堵与存储空间的浪费。有人曾使用Hadoop的分布式存储文件系统(Hadoop Distributed File System,HDFS)来存储执行全比较任务所需的数据[13]。HDFS采用分布式的副本存储方案,该组件默认采用副本数为3的存储方案。这种数据存储方式,虽然能够节约存储空间,但无法保证在执行比较任务时数据的完全本地化。Chaudhary等人在分析生物序列时搭建了一个异构计算平台。为了实现整个系统的负载均衡,他们根据节点的硬件配置来分配任务。在数据分配方面,他们将数据库进行分割,然后将其分发到各个节点上。尽管使用异构计算平台进行计算,但仍然无法避免从集群中的其他节点上请求数据[14]。对于通用的全比较数据分发方案,有学者提出了使用启发式的方案来进行全比较计算的数据分发与任务调度[1]。该方法使用枚举的方式来获取最优的数据分发方案,当遇到大数据集时,该方法将成为一个NP难问题。在这个研究的基础上,该学者又提出了使用模拟退火算法的思想构造元启发式的数据分发算法,该算法能够有效地降低分布式系统中存储空间的使用[15]。
在国内,有学者提出了使用图覆盖的方式来进行全比较任务的数据分配,并基于图覆盖理论提出了DAABGC算法[16]。DAABGC算法在文件个数与节点个数相同的条件下能够得到较好的数据分发方案,但不适用于数据文件个数与节点个数不同的场景。在之前的全比较计算研究中,采用了分支定界法求解的方法来完成全比较计算的数据分发[17],这种方法虽然能够获得最优化的数据分发方案,但需要牺牲一定的求解时间。
综上所述,目前全比较计算的数据分发研究成果还存在一些问题。本文对全比较计算的数据分发问题进一步展开理论分析,并将该问题与粒子群算法的思想相结合,构建了一个基于粒子群优化(Particle Swarm Optimization,PSO)的数据分发模型,提出了基于粒子群优化实现负载均衡的数据分发算法(Data Distribution Based on Particle Swarm Optimization for Load Balance,DDBPSOLB)和基于粒子群优化实现最优化存储的数据分发算法(Data Distribution Based on Particle Swarm Optimization for Best Storage,DDBPSOBS)。最后基于Matlab 验证了模型的可行性,并通过相关实验与Hadoop 框架数据分发策略作比较,验证了算法在分布式系统中各节点计算负载均衡、存储空间占用、数据本地化、算法运算速度方面的优势。
1 全比较计算相关研究
1.1 全比较计算
在全比较计算的数据集中,两两数据间必然且仅仅会发生一次比较计算。在一个具有m个数据文件的数据集和n个节点的分布式集群中,设具体的比较算法为C(i,j),其中i和j是数据集中的两个数据文件。全比较计算能够被形式化地描述为公式(1)。其中Mi,j是比较运算C(i,j)的计算结果。

1.2 全比较计算的数据分发模型构建
本文研究的是同构分布式系统下的数据分发工作,假定分布式系统中各个节点的软硬件配置一致。在核酸序列比对中[18],数据文件的大小是相同或近似相同的。假设数据集中有m个数据文件,每个数据文件的大小为si,i=1,2,…,m。那么数据文件的大小相同或近似相同的形式化描述如下:

全比较计算的数据分发工作要使得节点间的负载达到均衡,降低分布式系统总体的存储空间使用。同时要保证每个比较任务都能够使用具有本地化属性的数据,尽可能地减少每一台计算节点上的存储空间。
在进行两两数据文件的比较运算时,两个数据文件的大小之和与比较运算的计算量将成正比。令cij表示比较任务C(i,j)的计算量。则cij与数据文件i和数据文件j有如下关系:

根据公式(2)可知所有的cij的数值将相同或近似相同。假设为节点p上分配K个比较任务,每个任务的计算量为,i和j为分发到节点p上数据文件的编号,节点p上的任务量大小pc为:

令tcount为全比较计算中的总任务个数,一个比较任务与两个不同的数据文件有关,当数据集中有m个数据文件时,tcount为:

使用xkp来表示是否将比较任务k分配到节点p上,由公式(1)可知xkp具有唯一性,在进行任务分配时,每个比较任务能且必须分配到一个计算节点上。xkp的取值使用0 和1 来表示,1 表示将比较任务k分配到计算节点p上,0表示不进行分配。

用ck表示第k个任务的大小,那么公式(4)中节点p上的任务量大小pc能够被重新定义为:

在具有n个计算节点的分布式系统中,用ck表示任务k的大小,全比较计算的节点平均计算量cavg为:

由公式(7)、公式(8)可以得出节点p的计算量相对于cavg的偏离程度fp。

那么分布式系统的负载均衡能够被描述为:

令wq表示分发到节点p上的文件的总大小。假设分发到节点p上的文件数为m′(m′≤m),wp中文件i的大小为ri。则有:

令up(p=1,2,…,n)为节点p的存储空间上限,分发到节点p上的文件大小总和不能超过up。

以公式(10)作为求解目标,得到全比较计算在分布式系统中的负载均衡求解模型如下:

根据公式(13)进行全比较任务在分布式系统中的调度将使得各个计算节点之间实现负载均衡,并且能够保证每个比较任务所需的数据文件具有数据本地性。在这个基础上,对模型进行优化,期待找到一个最小化分布式系统中所需存储空间的数据分发方案。
数据文件与比较任务之间存在一个多对多的关系,即同一个数据文件与多个比较任务相关,一个比较任务需要两个数据文件。基于这种多对多关系进行任务分配的重组,调整执行比较任务k的计算节点,修改数据文件分发方案,得到一个数据分发方案与任务调度方案。
通过公式(13)能够得到负载均衡状态下每个节点的计算量,记为gi(i=1,2,…,n)。gi之间可能存在数值上的差异。在优化算法中,让每个计算节点上计算量都不超过gi的最大值。通过公式(7)对节点计算量的描述得到,某一时刻节点p上的任务分配情况与计算量的关系如下:

在具有n个计算节点的分布式系统中,将m个数据文件进行分发。每个文件在一台计算节点上最多只有一个备份,用yjp表示是否将第j个数据文件分发到第p个节点上,yjp取值为1 时表示将第j个数据文件分发到第p个节点上,yjp为0 时表示不分发。因此分布系统下全比较计算的数据分发策略对应的最优化存储的数据分发方案能够被描述成以下方程:

由公式(13)、公式(14)、公式(15),得出优化后的分布式系统下全比较计算数据分发模型如公式(16)所示:

根据公式(16)进行全比较计算的数据分发,得出的数据分发结果将降低分布式系统的存储空间,实现完全的数据本地化与负载均衡。
2 DDBPSO模型相关算法设计
粒子群算法是一种群启发式算法,该算法于1995年被美国社会心理学家Kenedy 和电气工程师Eberthart共同提出[19]。根据上文对全比较计算数据分发问题的理论分析可知,DDBPSO模型由两部分构成。第一部分为求出使得分布式系统达到负载均衡的数据分发方案与任务调度方案。基于第一部分的负载均衡结果进行优化求解,在保证负载均衡的前提下降低分布式系统中存储空间的使用。为了便于描述,将DDBPSO 模型的第一部分称为基于粒子群优化实现负载均衡的数据分发算法(DDBPSOLB),将DDBPSO 模型的第二部分称为基于粒子群优化实现最优化存储的数据分发算法(DDBPSOBS)。
2.1 DDBPSOLB算法设计
DDBPSOLB 算法将参照公式(13)进行设计,得出分布式系统下负载均衡状态的数据分发方案。其参数设置如表1所示。

表1 DDBPSOLB参数设置Table 1 Parameter setting of DDBPSOLB algorithm
考虑到数据文件数量增加后全比较问题的比较任务规模将增加,全比较计算与分布式系统中的节点数目有关,故动态调整粒子维度D。将单个粒子的维度指定为分布式系统中的节点数量与比较任务的数量tc的乘积。
惯性权重是粒子群算法中一个非常重要的控制参数,能够用来控制求解算法的开发与探索能力。DDBPSOLB算法在优化的过程当中,会逐代地获取到较好适应度值的可行解。因此希望在开始寻优时粒子较为活跃,即速度较快,随着优化的进行,粒子的运动状态逐渐趋于稳定,于是在DDBPSOLB 算法中采用线性递减权值策略[20]。
DDBPSOLB 算法中涉及到几个更新规则,包括惯性权重更新规则、粒子飞行速度更新规则以及粒子位置更新规则。
令w表示当前粒子的惯性权重,wmin与wmax分别表示惯性权重最小值和最大值,Tmax为最大迭代次数,t是DDBPSOLB算法当前迭代次数。则w能被形式化地表示为:

第t次迭代中粒子i第j维的飞行速度为vij(t),c1、c2为加速系数,RAND为0~1之间的随机数,xij(t)为中粒子i第j维的编码,pij(t)为粒子i的个体最佳位置,g(t)是第t次迭代得出的全局最佳位置。则第t+1次迭代中粒子i第j维的飞行速度vij(t+1) 为:

是否更新位置由概率q决定,令变量xij表示是否更新概率,xij取值为1时表示进行更新,xij取值为0时表示不进行更新。其形式化描述如公式(19)、公式(20)所示:

其中,vij为粒子i第j维的当前速度,r表示0~1之间的随机数。当xij=1 时,进行位置的更新。DDBPSOLB算法的适应度函数用于评价粒子编码对应的分布式系统的负载均衡程度,其数学原理遵循公式(9)。
DDBPSOLB算法的伪代码如算法1所示:
算法1DDBPSOLB算法

算法要求输入分布式系统的节数量n,节点存储上限ut和全比较计算所需的文件的大小列表s。输出参数为全比较计算的任务列表task,分布式系统中各节点的总计算量nodeLoads,全局最优位置gbest。这三个参数都被用作DDBPSOBS 算法的输入参数。第6 行对输入参数进行检验,比如判断计算节点是否有能力存储全比较计算所需的一份完整数据。第11行到第30行进行粒子群迭代寻优。第31 行将从全局最优解gbest中解析出各个节点的负载情况,并存储到nodeLoads中。
时间复杂度。DDBPSOLB算法的主要耗时操作在于迭代求解部分,该部分包含三个嵌套的for 循环。优化迭代次数为T,粒子群规模为N,粒子编码长度为D,则DDBPSOLB算法的时间复杂度为T1=O(TND),与离散粒子群算法的时间复杂度处于同一数量级。
收敛性。如算法1第18~25行所示,粒子在进化时,会随机选择两个节点上,并将其中一个节点上的某一个任务安排到另一个节点上,对可行解进行扰动。在扰动的过程中,如果新解优于当前粒子的最佳解则对该粒子的编码进行更新。这样的更新方式使得算法能够接受次优解,有效避免算法陷入局部最优解。在下一次迭代时第13、14 行会根据负载偏离程度对个体最优位置与全局最优位置进行更新,从而让负载偏离程度朝着缩小的方向收敛。
2.2 DDBPSOBS算法设计
DDBPSOBS算法用于在保证分布式系统中各个节点实现负载平衡的条件下,对分布式系统中各个节点需要提供的存储空间大小进行优化。在DDBPSOLB算法计算完毕之后,能够得出使得分布式系统实现负载均衡状态下的全比较计算任务调度方案,以及分布式系统中每个节点所需承担的计算量。从各个节点的计算量中选出节点计算量的最大值Cmax作为DDBPSOBS 算法中的一个约束条件。
DDBPSOBS 算法思想与DDBPSOLB 算法类似,相关的参数除粒子种群规模N外其余均与表1 保持一致。粒子种群规模N在DDBPSOBS算法中取值为10,这样做的目的是希望通过降低种群规模,提高算法的运算效率。
由于DDBPSOLB算法中获取到了使得系统实现负载均衡的粒子最佳位置,因此在DDBPSOBS 算法中的种群初始化工作中,只需要将编码复制N份,通过满足公式(14)来调整粒子的编码,实现初始种群的多样性。DDBPSOBS算法对应的适应度值为粒子当前的编码对应的分布式系统的存储空间大小。使用公式(16)来进行算法的开发,与粒子群优化的相关更新规则与DDBPSOLB算法基本保持一致,具体的位置更新规则有所改变。
算法2所示的是DDBPSOBS算法步骤描述:
算法2DDBPSOBS算法


算法要求输入的参数包括n、s、task、nodeLoads、以及DDBPSOLB算法的全局最优位置gbest1。输出结果为分布式系统下全比较计算的任务调度方案taskAssign和文件分发方案fileAssign。第6 行到第22 行将进行粒子群迭代寻优之前的初始化工作,这部分主要是给粒子群优化所需的参数信息做初始化。第24行到第50行进行迭代寻优,当满足位置更新规则时,使用第34行到第45行所定义的内容进行粒子位置的更新。第49行将每一次迭代所得到的最优位置所对应的适应度值记录下来,方便后期查看算法的适应度进化情况。在完成迭代寻优后,第51 行将从DDBPSOBS 算法的全局最优位置编码gbest中解析出taskAssign和fileAssign。
时间复杂度。DDBPSOBS算法的耗时操作同样发生在迭代求解部分,该算法同样是根据迭代次数T,粒子群规模N,粒子编码长度D构建了for循环。其时间复杂度为T2=O(TND),与DDBPSOLB 算法和离散粒子群算法的时间复杂度保持在同一个数量级。
收敛性。算法2第31~47行表示的是粒子的进化过程,通过概率q确定要修改粒子i的编码之后,将粒子i的位置编码x备份为y。随机挑选两个计算节点上的任务集合set1与set2。从set1中随机挑选一个任务task1,计算任务1 的大小ts1。计算set2中每个任务与task1的大小差异,挑选出差异最小的任务作为交换任务task2。在y上交换task1和task2的执行节点,如果两个节点上的任务量均在Cmax的范围内,则计算编码y对应的适应度值fit″。如果fit″的适应度值优于粒子i的个体最优值,则使用y更新x。与个体最优值做比较的这种方式,是为了避免算法陷入局部最优解。算法2第27、28 行会将每次迭代过程中的个体最优的位置与全局最优位置进行更新,从而让全局最优解朝着所需存储空间变小的方向收敛。
3 相关实验与结果分析
3.1 评价指标
本文将采用负载均衡、存储节约率、数据本地化率、模型计算时间4 个评价指标来对DDBPSO 模型进行分析与评价。
负载均衡。根据公式(9)能得到节点i的负载均衡偏离程度fi,全部fi组成的集合为F。负载均衡有三种状态:完全负载均衡STATE1、近似负载均衡STATE2、非负载均衡STATE3。负载均衡LB对应的数学描述如公式(21)所示,其中c是所有任务计算量的集合。
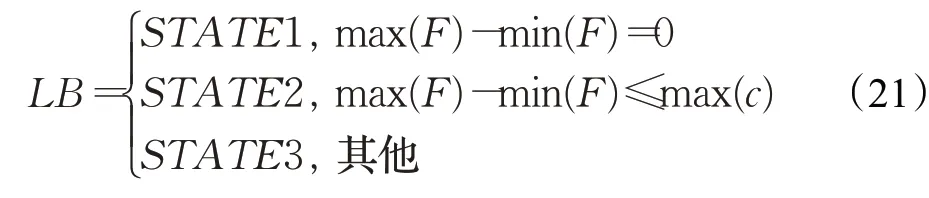
存储节约率。存储节约率的计算将把全比较计算所需的整份数据向分布式系统中每个节点分发一份时分布式系统所需的存储空间作为分母,分子为每个节点所需提供存储空间的总和。m个数据文件,n个节点,令hr为存储节约率,hr的计算公式如下:
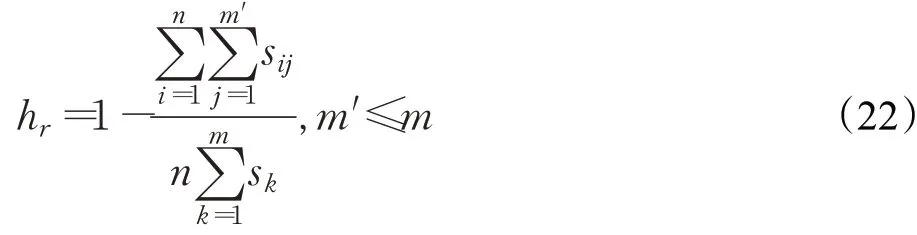
在公式(22)中,sk表示文件k的大小,sij是分发到i上的文件j的大小,m′表示分发到节点i上的文件数目。
3.2 实验方案设计
考虑文件大小是否完全相同和全比较计算的比较任务数量是否能够被分布式系统中的节点数所整除。对这两个条件的组合进行分析,可以得出如下四组实验方案。
(1)文件大小完全相同,比较任务数能够被节点数整除。
(2)文件大小完全相同,比较任务数不能被节点数整除。
(3)文件大小不完全相同,比较任务数能够被节点数整除。
(4)文件大小不完全相同,比较任务数不能被节点数整除。
实验数据。将从国家生物技术中心下载的一个基因序列文件进行切分处理。将基因序列文件切分成12个大小不完全相同的小文件,每次从中挑选出10 个数据文件进行实验。切分后的数据文件的大小分别为[9.7 MB,9.7 MB,9.7 MB,9.7 MB,9.7 MB,9.7 MB,9.7 MB,9.7 MB,9.7 MB,9.7 MB,8.1 MB,12.1 MB],以这些数据文件为例,进行实验方案设计。
使用Hadoop 进行数据分发工作时,具备较好的存储节约性能[15]。使用HDFS 组件和MapReduce 组件进行配合,能较好地完成全比较计算的数据分发工作。在进行DDBPSO 模型验证实验之前,首先使用Hadoop 执行四组数据分发实验,并编写MapReduce程序读取数据文件模拟序列比对中的文件加载操作。记录每一组实验中全比较计算的数据分发方案与任务调度情况,用于与DDBPSO 模型的实验结果做比较。四组实验的文件与节点信息如表2所示。表2所示的实验方案旨在覆盖可能出现的文件大小完全相同与否条件和比较任务数能否被节点均分的情况,对其他节点数量和文件大小列表具备普适性。

表2 实验方案设计Table 2 Design of experimental scheme
3.3 Hadoop数据分发实验
本文将使用Hadoop的数据分发结果与DDBPSO模型所得数据分发结果在负载均衡程度、存储节约情况和数据本地化情况这三个评价指标上做对比。Hadoop集群配置方案如下:
宿主机配置:Intel i7-8750CPU,16 GB RAM,1 TB SATA+256 GB SSD,Window10操作系统。虚拟化软件及版本:VMWareWorkStation10。
虚拟机配置:CPU 核心数为2,2 GB 内存,20 GB 磁盘空间,在5台虚拟机上安装Centos6.8并配置Hadoop2.7.2。
Hadoop 数据分发实验将在宿主机上进行一次全比较计算所需的数据从宿主机分发到HDFS 上,并通过Hadoop 提供的可视化界面对上传的每个数据进行所在位置统计。HDFS中的文件副本数不做修改,使用默认值3。
基于Hadoop 依次完成四组实验得到的Hadoop 的全比较计算数据分发方案与全比较计算任务执行情况如表3所示。数据分发方案的统计是基于Hadoop提供的Web界面获取到的,任务执行情况是根据模拟的全比较计算程序得出的。

表3 Hadoop实验结果Table 3 Results of Hadoop experiment
与将全比较计算所需的全部数据向所有节点都分发一次的数据分发方案相比较,能够得出Hadoop 集群的存储节约情况。四组实验的存储节约率如图1 所示。本次实验全程使用Hadoop默认的副本数3,实验2与实验4 的计算节点数量为4,分布式系统的存储节约率为25%;当计算节点数量为5时,实验1与实验3的分布式系统存储节约率为40%。

图1 Hadoop实验存储节约率Fig.1 Storage savings rate of Hadoop experiment
对表3的数据分发方案与任务执行情况进行分析,结合Hadoop 在向HDFS 请求数据时的数据发送特点:当客户端向HDFS 请求数据时,NameNode 会将满足条件的且离客户端最近的DataNode 上的数据发送给客户端。能够分析出在进行全比较计算时,各个比较任务请求到的数据是本地的还是其他节点的。四次实验中节点的数据本地率如图2 所示。从图中可以看出使用Hadoop 进行全比较计算,数据文件的副本数为3 时,分布式系统无法实现完全的数据本地化。

图2 Hadoop实验数据本地化情况Fig.2 Data localization for Hadoop experiment
3.4 DDBPSO模型实验
对3.2 节中设计的实验方案进行实验,分布式系统的存储节约率如图3所示,负载均衡情况如图4所示。

图3 DDBPSO模型存储节约率Fig.3 Storage savings for DDBPSO model

图4 DDBPSO模型负载均衡情况Fig.4 Load balancing of DDBPSO model
由图3可知,DDBPSO模型的存储节约率在大多数情况下都高于Hadoop的数据分发策略。尽管实验3的存储节约率不如Hadoop,但是DDBPSO 模型的数据本地化率在任何情况下都能实现全部节点的完全数据本地化,而Hadoop 的数据分发策略无法达到这种效果。对图4进行分析可知,DDBPSO模型能够使得分布式系统下的全比较计算实现完全负载均衡或近似负载均衡。使用分支定界法对同规模的数据进行求解时,往往需要20 h 的求解时间[17],而DDBPSO 模型在20~40 s 内便可完成计算。从效率角度来看,DDBPSO模型具备显著的优势。
4 结束语
本文研究了全比较计算的数据分发问题,提出了基于粒子群优化算法的数据分发模型DDBPSO 及相关算法,对DDBPSO 模型和相关算法进行了实验。实验结果表明,DDBPSO模型给出的数据分发方案可以实现任务所需数据文件的完全本地化,能够降低分布式系统中存储空间的使用。在负载均衡方面,DDBPSO模型给出的任务调度方案基本能够实现分布式系统中各个节点间的负载均衡。在计算时间方面,DDBPSO 模型能够以较快速度求出数据分发方案与任务调度方案,可以较好地完成分布式系统下全比较计算数据分发工作。DDBPSO 模型有效地解决了大规模全比较计算的数据分发问题,对生物信息学、自然语言处理等领域研究进展将产生较好的推动作用。
